Modificare la trasformazione riga nel flusso di dati di mapping
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
I flussi di dati sono disponibili nelle pipeline sia di Azure Data Factory che di Azure Synapse. Questo articolo si applica ai flussi di dati per mapping. Se non si ha esperienza con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati con un flusso di dati per mapping.
Utilizzare la trasformazione Alter Row per impostare criteri di inserimento, eliminazione, aggiornamento e upsert per le righe. È possibile aggiungere condizioni uno-a-molti come espressioni. È necessario specificare queste condizioni in ordine di priorità, poiché ogni riga viene contrassegnata con il criterio corrispondente alla prima espressione associata. Tutte queste condizioni possono provocare l'inserimento, l'aggiornamento, l'eliminazione o l'upsert di una o più righe. Alter Row può produrre azioni DDL e DML sul database.
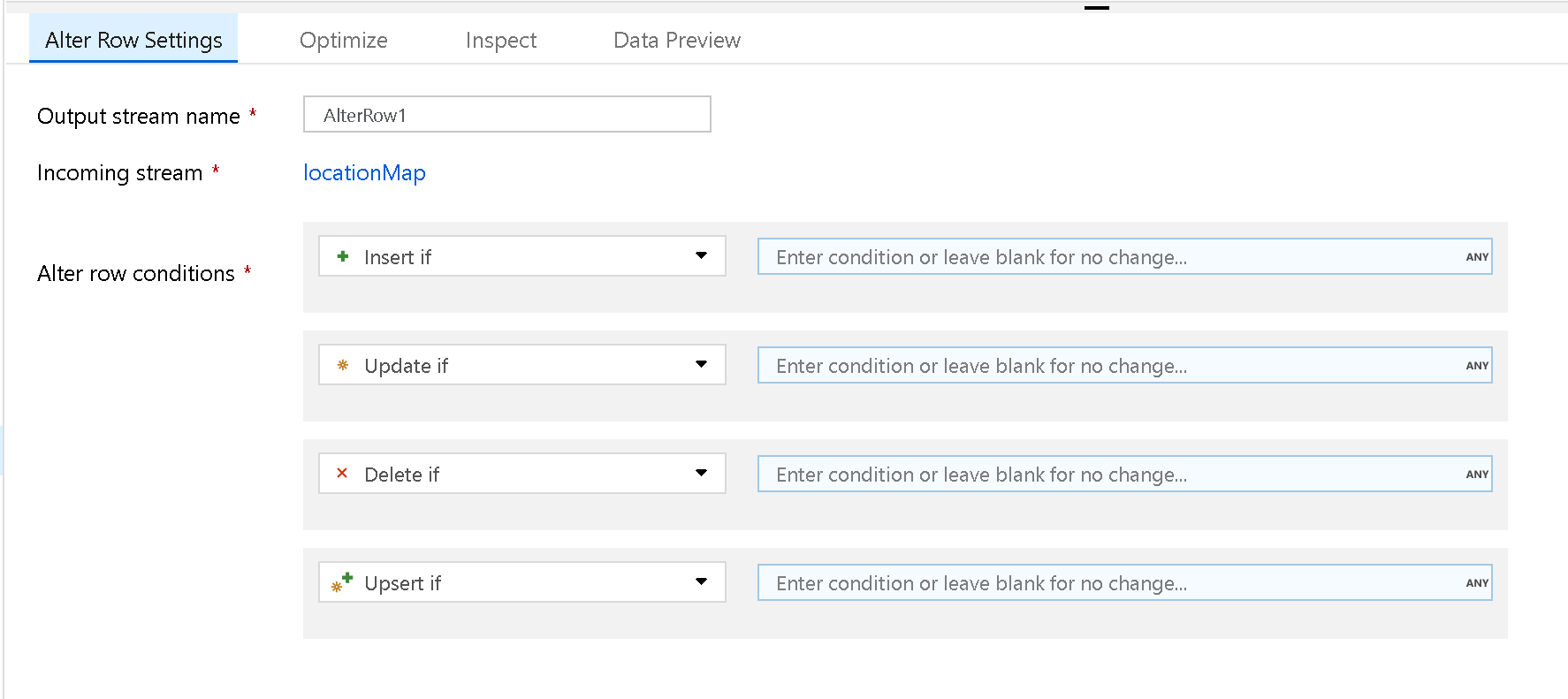
Le trasformazioni Alter Row operano solo su sink di database, REST o Azure Cosmos DB nel flusso di dati. Le azioni assegnate alle righe (inserimento, aggiornamento, eliminazione, upsert) non vengono eseguite durante le sessioni di debug. Per applicare i criteri di modifica delle righe nelle tabelle di database, eseguire un'attività Esegui flusso di dati in una pipeline.
Nota
Non è necessaria una trasformazione Alter Row per i flussi di dati Change Data Capture che usano origini CDC native come SQL Server o SAP. In questi casi, ADF rileverà automaticamente il marcatore di riga in modo che i criteri Alter Row non siano necessari.
Specificare un criterio di riga predefinito
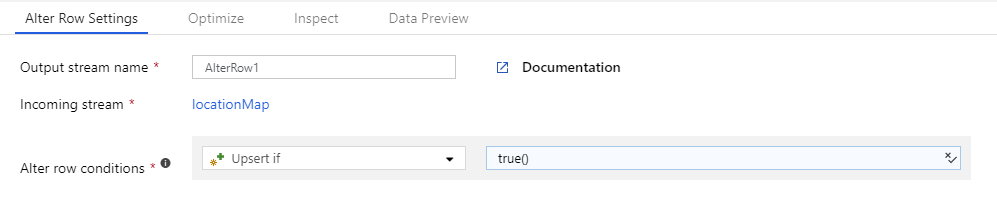
Creare una trasformazione Alter Row e specificare un criterio di riga con una condizione di true(). Ogni riga che non corrisponde a nessuna delle espressioni definite in precedenza è contrassegnata per i criteri di riga specificati. Per impostazione predefinita, ogni riga che non corrisponde ad alcuna espressione condizionale è contrassegnata per Insert.
Nota
Per contrassegnare tutte le righe con un criterio, è possibile creare una condizione per tale criterio e specificare la condizione come true().
Visualizzare i criteri nell'anteprima dei dati
Usare la modalità di debug per visualizzare i risultati dei criteri di modifica delle righe nel riquadro di anteprima dei dati. Un'anteprima dei dati di una trasformazione alter row non produce azioni DDL o DML sulla destinazione.
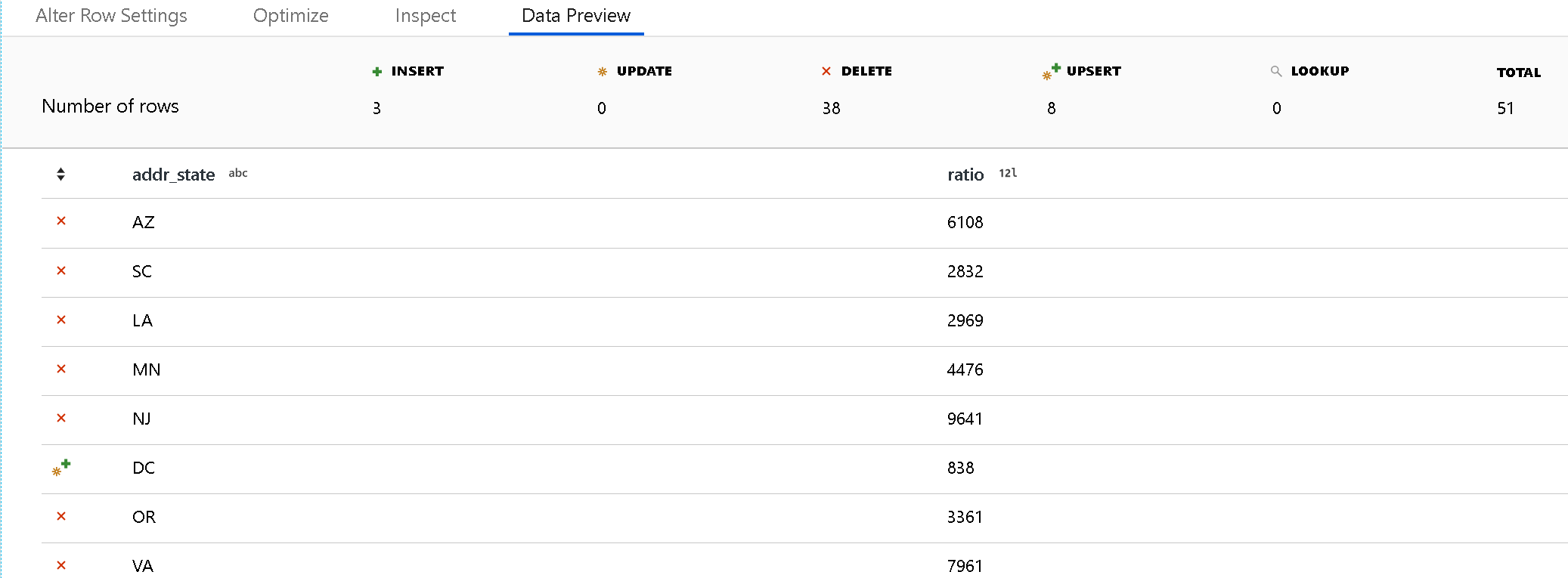
Un'icona per ogni criterio di modifica riga indica se si verifica un'azione di inserimento, aggiornamento, upsert o eliminazione. L'intestazione superiore mostra il numero di righe interessate da ogni criterio nell'anteprima.
Consenti modifica criteri di riga nel sink
Per il funzionamento dei criteri di modifica delle righe, il flusso di dati deve scrivere in un database o in un sink di Azure Cosmos DB. Nella scheda impostazioni nel sink abilitare i criteri di modifica delle righe consentiti per tale sink.
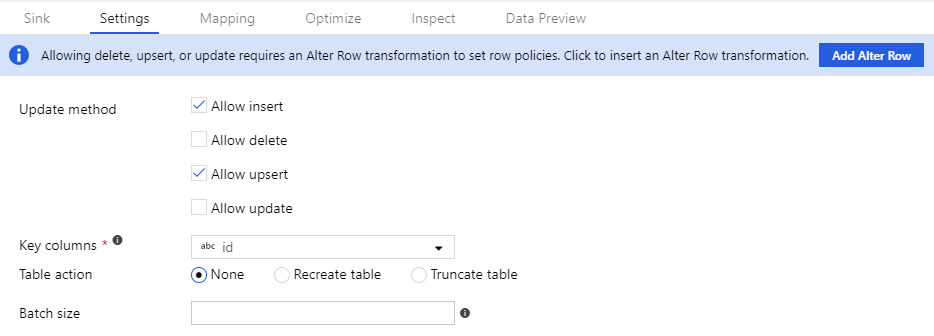
Il comportamento predefinito consiste nel consentire solo gli inserimenti. Per consentire aggiornamenti, upsert o eliminazioni, selezionare la casella nel sink corrispondente a tale condizione. Se gli aggiornamenti, gli upsert o le eliminazioni sono abilitati, è necessario specificare le colonne chiave nel sink su cui trovare la corrispondenza.
Nota
Se gli inserimenti, gli aggiornamenti o gli upsert modificano lo schema della tabella di destinazione nel sink, il flusso di dati avrà esito negativo. Per modificare lo schema di destinazione nel database, scegliere Ricrea tabella come azione di tabella. Verrà eliminata e ricreata la tabella con la nuova definizione dello schema.
La trasformazione sink richiede una singola chiave o una serie di chiavi per l'identificazione di riga univoca nel database di destinazione. Per i sink SQL, impostare le chiavi nella scheda impostazioni sink. Per Azure Cosmos DB, impostare la chiave di partizione nelle impostazioni e impostare anche il campo di sistema di Azure Cosmos DB "ID" nel mapping del sink. Per Azure Cosmos DB, è obbligatorio includere la colonna di sistema "ID" per gli aggiornamenti, gli upsert e le eliminazioni.
Unisce e upsert con il database SQL di Azure e Azure Synapse
I flussi di dati supportano i merge nel database SQL di Azure e nel pool di database di Azure Synapse (data warehouse) con l'opzione upsert.
Tuttavia, è possibile eseguire scenari in cui lo schema del database di destinazione ha utilizzato la proprietà Identity delle colonne chiave. Il servizio richiede di identificare le chiavi usate per trovare le corrispondenze con i valori di riga per gli aggiornamenti e gli upsert. Tuttavia, se la colonna di destinazione ha la proprietà Identity impostata e si usano i criteri upsert, il database di destinazione non consente di scrivere nella colonna. È anche possibile che si verifichino degli errori quando si tenta di eseguire l'upsert sulla colonna di distribuzione di una tabella distribuita.
Ecco alcuni modi per risolvere questo problema:
Passare a Impostazioni trasformazione Sink e impostare "Ignora scrittura colonne chiave". Ciò indica al servizio di non scrivere la colonna selezionata come valore della chiave per il mapping.
Se la colonna chiave non è la colonna che causa il problema per le colonne Identity, è possibile usare l'opzione SQL di pre-elaborazione della trasformazione Sink:
SET IDENTITY_INSERT tbl_content ON. Disattivarla quindi con la proprietà SQL post-elaborazione:SET IDENTITY_INSERT tbl_content OFF.Sia per il caso identity che per la colonna di distribuzione, è possibile passare dalla logica upsert all'uso di una condizione di aggiornamento separata e di una condizione di inserimento separata tramite una trasformazione Suddivisione condizionale. In questo modo, è possibile impostare il mapping nel percorso di aggiornamento per ignorare il mapping delle colonne chiave.
Script del flusso di dati
Sintassi
<incomingStream>
alterRow(
insertIf(<condition>?),
updateIf(<condition>?),
deleteIf(<condition>?),
upsertIf(<condition>?),
) ~> <alterRowTransformationName>
Esempio
L'esempio seguente è una trasformazione alter row denominata CleanData che accetta un flusso in ingresso SpecifyUpsertConditions e crea tre condizioni di modifica riga. Nella trasformazione precedente viene calcolata una colonna denominata alterRowCondition che determina se una riga viene inserita, aggiornata o eliminata nel database. Se il valore della colonna ha un valore stringa che corrisponde alla regola di modifica riga, viene assegnato tale criterio.
Nell'interfaccia utente questa trasformazione è simile all'immagine seguente:
Lo script del flusso di dati per questa trasformazione si trova nel frammento di codice seguente:
SpecifyUpsertConditions alterRow(insertIf(alterRowCondition == 'insert'),
updateIf(alterRowCondition == 'update'),
deleteIf(alterRowCondition == 'delete')) ~> AlterRow
Contenuto correlato
Dopo la trasformazione Alter Row, è possibile eseguire il sink dei dati in un archivio dati di destinazione.