Copiare dati da Azure Data Lake Storage Gen1 a Gen2 con Azure Data Factory
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Azure Data Lake Storage Gen2 è un set di funzionalità dedicate all'analisi dei Big Data integrata nell'archiviazione BLOB di Azure. Consente di interagire con i dati approfittando dei paradigmi sia del file system che dell'archiviazione di oggetti.
Se attualmente si usa Azure Data Lake Storage Gen1, è possibile valutare Azure Data Lake Storage Gen2 copiando i dati da Data Lake Storage Gen1 a Gen2 usando Azure Data Factory.
Azure Data Factory è un servizio di integrazione dei dati completamente gestito e basato sul cloud. È possibile usare il servizio per popolare il lake con i dati di un set completo di archivi dati locali e basati sul cloud e risparmiare tempo durante la compilazione delle soluzioni di analisi. Per un elenco dei connettori supportati, vedere la tabella degli archivi dati supportati.
Azure Data Factory offre una soluzione di spostamento dei dati gestita e scale-out. A causa dell'architettura con scalabilità orizzontale di Data Factory, può inserire dati a una velocità effettiva elevata. Per altre informazioni, vedere attività Copy prestazioni.
Questo articolo illustra come usare lo strumento di copia dei dati di Data Factory per copiare dati da Azure Data Lake Storage Gen1 in Azure Data Lake Storage Gen2. È possibile seguire una procedura simile a quella usata per copiare dati da altri tipi di archivi dati.
Prerequisiti
- Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
- Account Data Lake Storage Gen1 contenente dati.
- Archiviazione di Azure account con Data Lake Storage Gen2 abilitato. Se non si ha un account di archiviazione, creare un account.
Creare una data factory
Se non è ancora stato creato il data factory, seguire la procedura descritta in Avvio rapido: creare un data factory usando il portale di Azure e Azure Data Factory Studio per crearne uno. Dopo averlo creato, passare alla data factory nel portale di Azure.

Selezionare Apri nel riquadro Apri Azure Data Factory Studio per avviare l'applicazione Integrazione dei dati in una scheda separata.
Caricare i dati in Azure Data Lake Storage Gen2
Nella home page selezionare il riquadro Inserimento per avviare lo strumento copia dati.
Nella pagina Proprietà scegliere Attività di copia predefinita in Tipo di attività e scegliere Esegui una volta ora in Frequenza attività o pianificazione attività, quindi selezionare Avanti.
Nella pagina Archivio dati di origine selezionare + Nuova connessione.
Selezionare Azure Data Lake Storage Gen1 dalla raccolta di connettori e selezionare Continue (Continua).
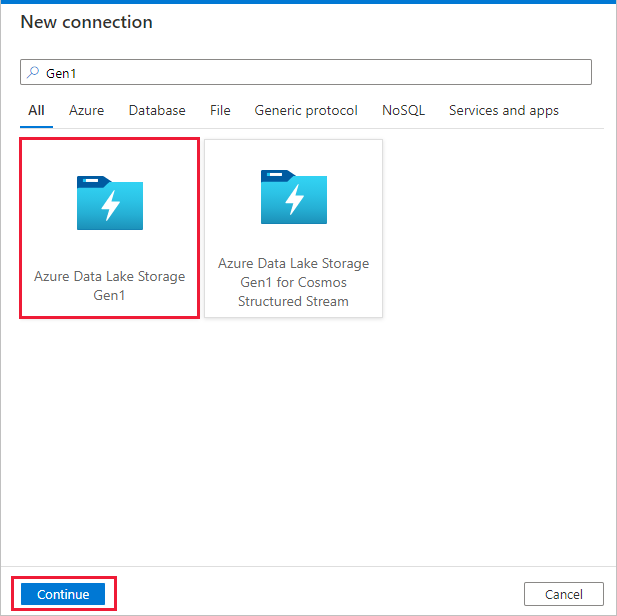
Nella pagina Nuova connessione (Azure Data Lake Storage Gen1) seguire questa procedura:
- Selezionare la propria istanza di Data Lake Storage Gen1 per il nome dell'account e specificare o convalidare il Tenant.
- Selezionare Test connessione per convalidare le impostazioni. Selezionare Crea.
Importante
In questa procedura dettagliata si usa un'identità gestita per le risorse di Azure per autenticare Azure Data Lake Storage Gen1. Per concedere all'identità gestita le autorizzazioni appropriate in Azure Data Lake Storage Gen1, seguire queste istruzioni.
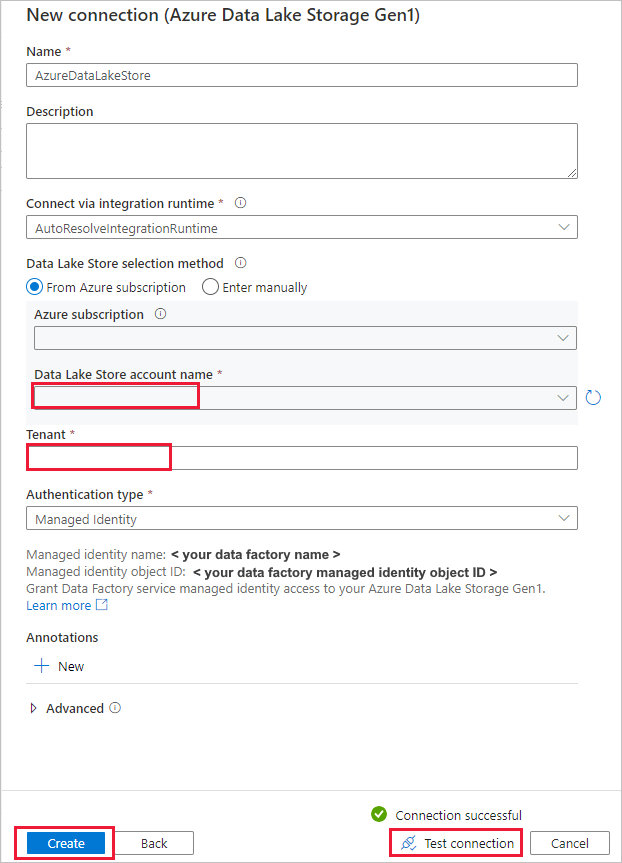
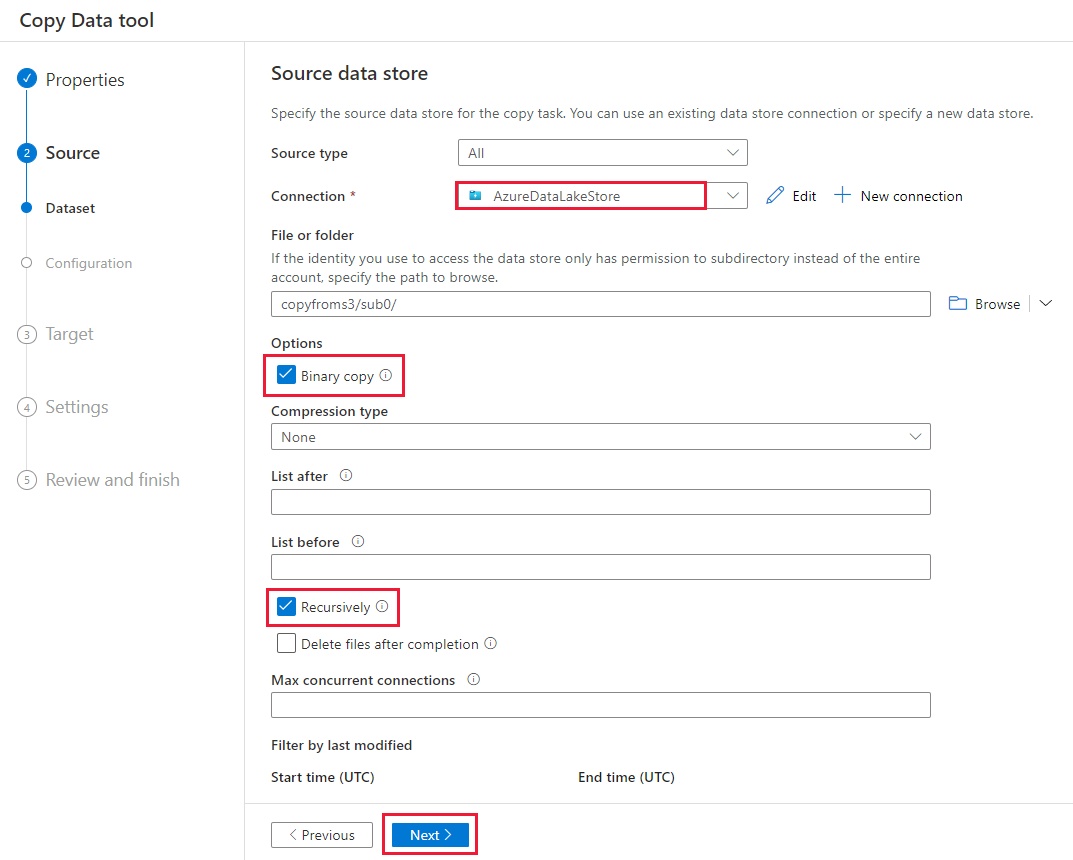
Nella pagina Archivio dati di origine completare la procedura seguente.
- Selezionare la connessione appena creata nella sezione Connessione .
- In File o cartella passare alla cartella e al file da copiare. Selezionare la cartella o il file e selezionare OK.
- Specificare il comportamento di copia selezionando le opzioni Copia ricorsiva e Binaria . Selezionare Avanti.
Nella pagina Archivio dati di destinazione selezionare + Nuova connessione>Azure Data Lake Storage Gen2>Continue (Continua).
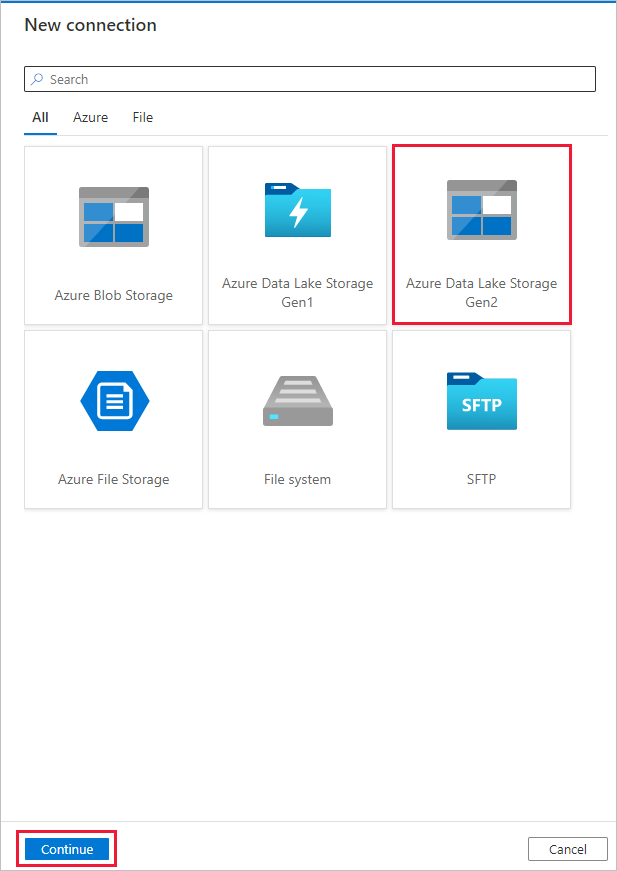
Nella pagina Nuova connessione (Azure Data Lake Storage Gen2) seguire questa procedura:
- Selezionare l'account con supporto per Data Lake Storage Gen2 dall'elenco a discesa Nome account di archiviazione.
- Seleziona Crea per creare la connessione.
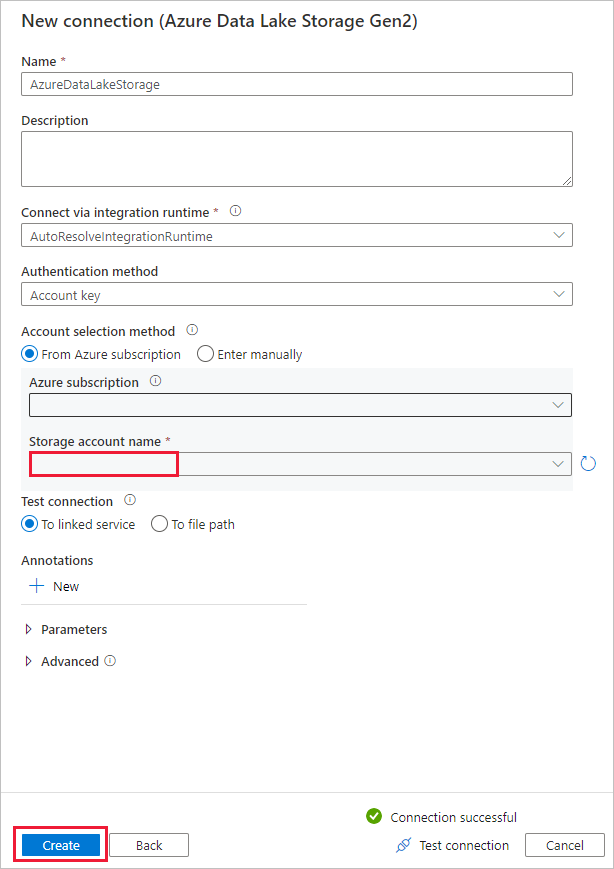
Nella pagina Archivio dati di destinazione completare la procedura seguente.
- Selezionare la connessione appena creata nel blocco Connessione .
- In Percorso cartella immettere copyfromadlsgen1 come nome della cartella di output e selezionare Avanti. Data Factory crea il file system e le sottocartelle di Azure Data Lake Storage Gen2 corrispondenti durante la copia, se non esistono.
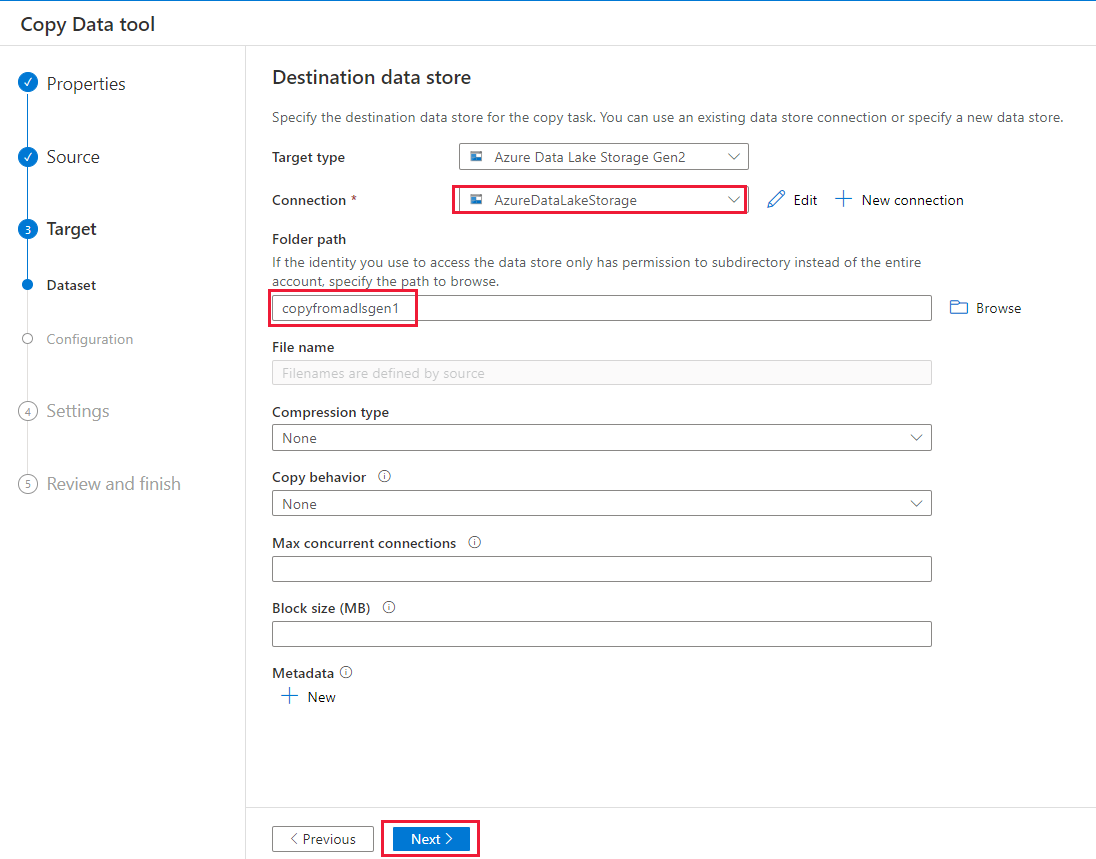
Nella pagina Impostazioni specificare CopyFromADLSGen1ToGen2 per il campo Nome attività, quindi selezionare Avanti per usare le impostazioni predefinite.
Nella pagina Riepilogo esaminare le impostazioni e selezionare Avanti.
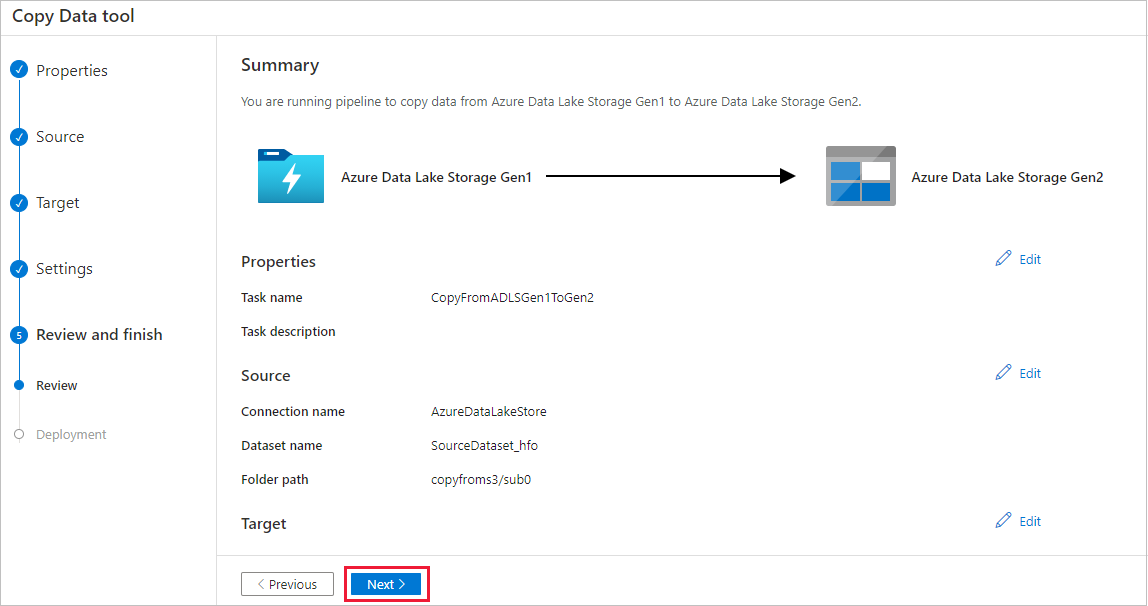
Nella pagina Distribuzione selezionare Monitoraggio per monitorare la pipeline.
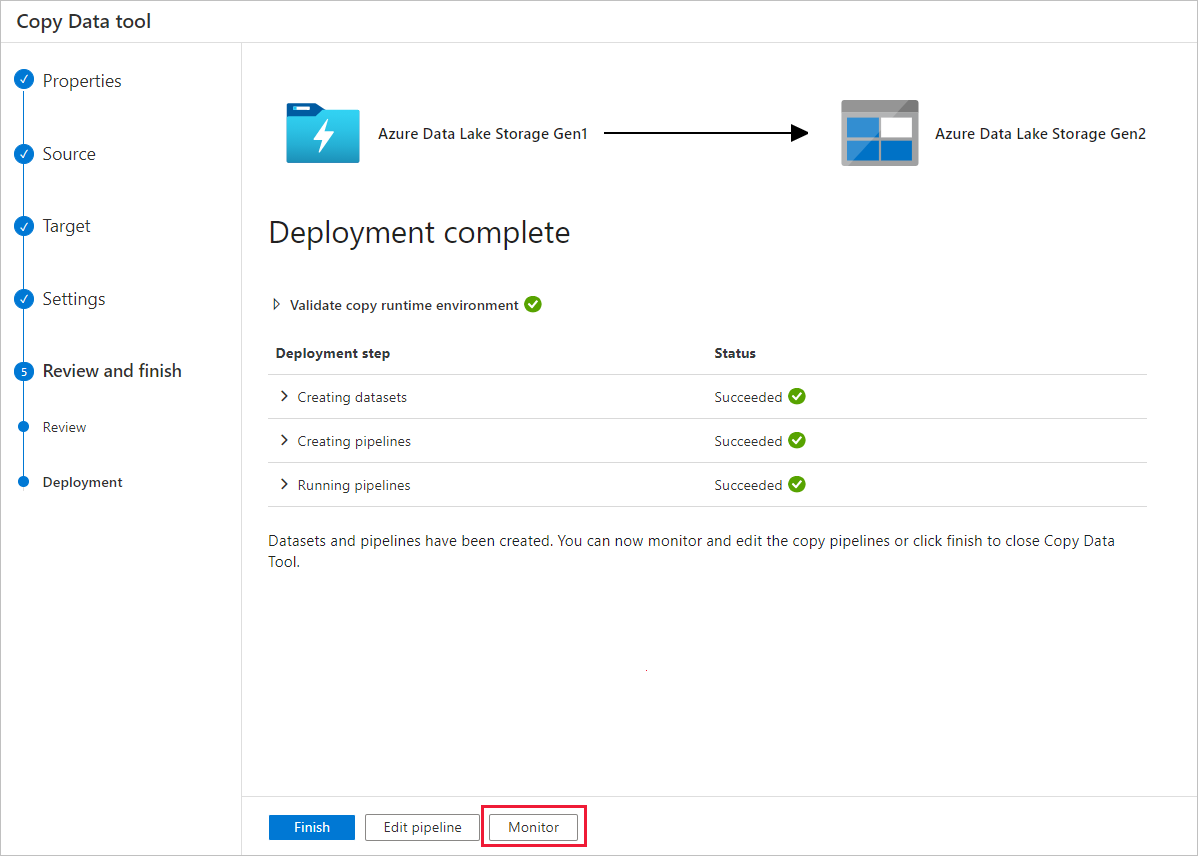
Si noti che la scheda Monitoraggio a sinistra è selezionata automaticamente. La colonna Nome pipeline include collegamenti per visualizzare i dettagli dell'esecuzione dell'attività e per rieseguire la pipeline.
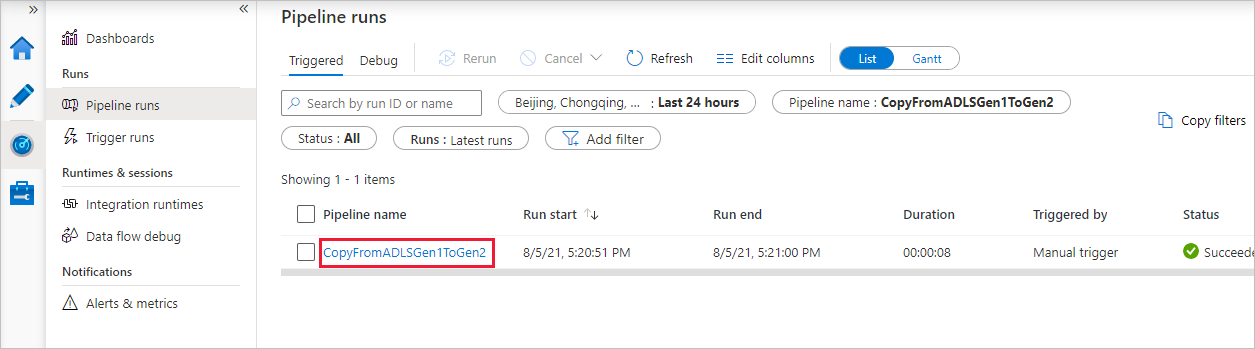
Per visualizzare le esecuzioni di attività associate all'esecuzione della pipeline, selezionare il collegamento nella colonna Nome pipeline. Dato che la pipeline contiene una sola attività (attività di copia), viene visualizzata una sola voce. Per tornare alla visualizzazione esecuzioni della pipeline, selezionare il collegamento Tutte le esecuzioni della pipeline nel menu di navigazione nella parte superiore. Selezionare Aggiorna per aggiornare l'elenco.
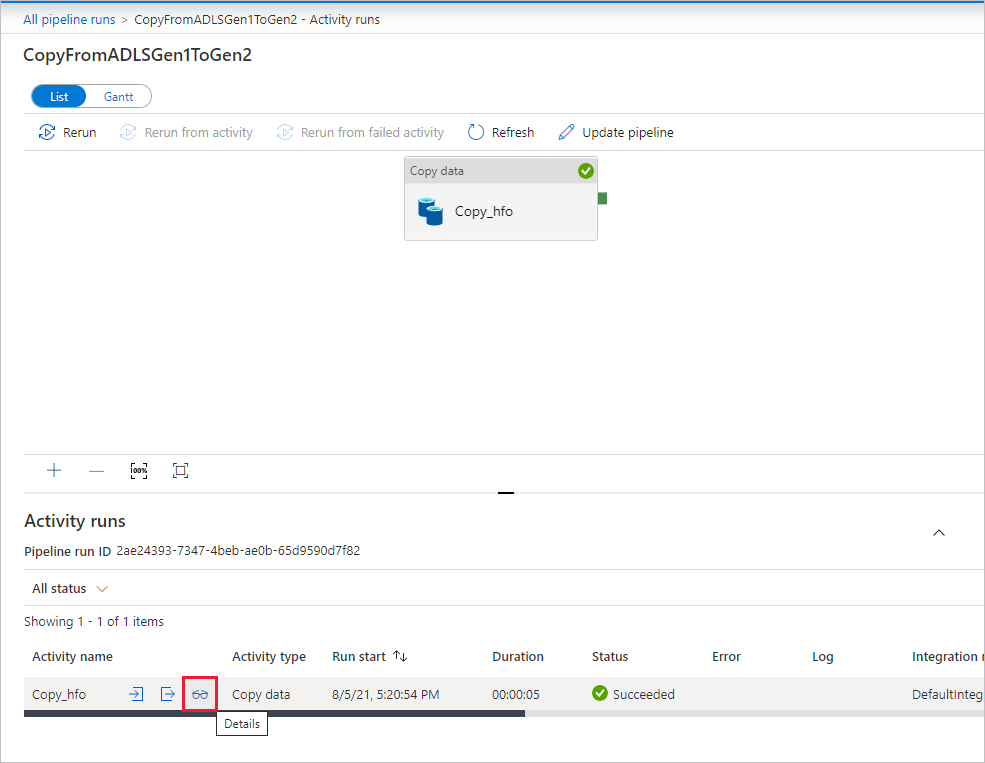
Per monitorare i dettagli di esecuzione per ogni attività di copia, selezionare il collegamento Dettagli (immagine degli occhiali) nella colonna Nome attività nella visualizzazione monitoraggio attività. È possibile monitorare dettagli come il volume dei dati copiati dall'origine al sink, la velocità effettiva dei dati, i passaggi di esecuzione con la durata corrispondente e le configurazioni usate.
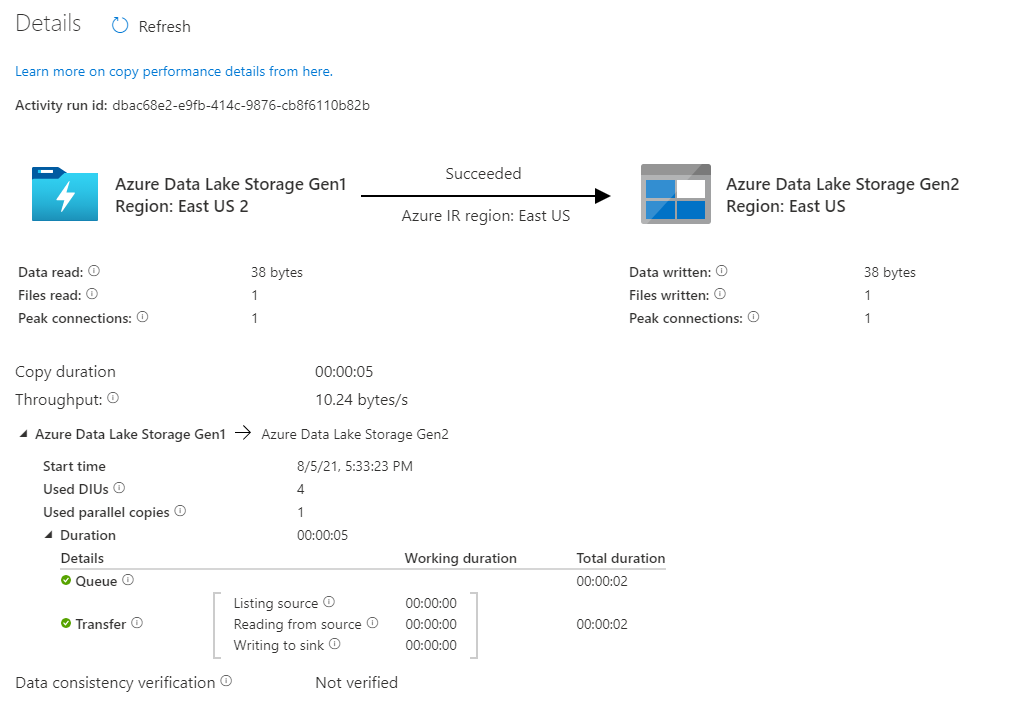
Verificare che i dati vengano copiati nell'account Azure Data Lake Storage Gen2.
Procedure consigliate
Per valutare l'aggiornamento da Azure Data Lake Storage Gen1 ad Azure Data Lake Storage Gen2 in generale, vedere Aggiornare le soluzioni di analisi dei Big Data da Azure Data Lake Storage Gen1 ad Azure Data Lake Storage Gen2. Le sezioni seguenti illustrano le procedure consigliate per l'uso di Data Factory per un aggiornamento dei dati da Data Lake Storage Gen1 a Data Lake Storage Gen2.
Migrazione iniziale dei dati dello snapshot
Prestazioni
ADF offre un'architettura serverless che consente il parallelismo a livelli diversi, consentendo agli sviluppatori di compilare pipeline per sfruttare al meglio la larghezza di banda di rete, nonché le operazioni di I/O al secondo di archiviazione e la larghezza di banda per ottimizzare la velocità effettiva di spostamento dei dati per l'ambiente.
I clienti hanno eseguito correttamente la migrazione di petabyte di dati costituiti da centinaia di milioni di file da Data Lake Storage Gen1 a Gen2, con una velocità effettiva sostenuta di 2 GBps e superiore.
È possibile ottenere una maggiore velocità di spostamento dei dati applicando diversi livelli di parallelismo:
- Una singola attività di copia può sfruttare i vantaggi delle risorse di calcolo scalabili: quando si usa Azure Integration Runtime, è possibile specificare fino a 256 unità di integrazione dati per ogni attività di copia in modo serverless. Quando si usa il runtime di integrazione self-hosted, è possibile aumentare manualmente il numero di istanze del computer o aumentare il numero di istanze in più computer ( fino a 4 nodi), e una singola attività di copia partizionerà il relativo set di file in tutti i nodi.
- Una singola attività di copia legge da e scrive nell'archivio dati usando più thread.
- Il flusso di controllo ADF può avviare più attività di copia in parallelo, ad esempio usando il ciclo For Each.
Partizioni di dati
Se le dimensioni totali dei dati in Data Lake Storage Gen1 sono inferiori a 10 TB e il numero di file è inferiore a 1 milione, è possibile copiare tutti i dati in una singola esecuzione dell'attività di copia. Se si dispone di una quantità maggiore di dati da copiare o si vuole avere la flessibilità necessaria per gestire la migrazione dei dati in batch e renderli completi entro un intervallo di tempo specifico, partizionare i dati. Il partizionamento riduce anche il rischio di eventuali problemi imprevisti.
Il modo per partizionare i file consiste nell'usare il nome range- listAfter/listBefore nella proprietà dell'attività di copia. Ogni attività di copia può essere configurata per copiare una partizione alla volta, in modo che più attività di copia possano copiare dati da un singolo account Data Lake Storage Gen1 contemporaneamente.
Limitazione della frequenza
Come procedura consigliata eseguire un PoC di prestazioni con un set di dati di esempio rappresentativo, in modo da poter determinare la dimensione appropriata della partizione.
Iniziare con una singola partizione e una singola attività di copia con l'impostazione DIU predefinita. La copia parallela è sempre consigliata per essere impostata come vuota (impostazione predefinita). Se la velocità effettiva della copia non è adatta, identificare e risolvere i colli di bottiglia delle prestazioni seguendo i passaggi di ottimizzazione delle prestazioni.
Aumentare gradualmente l'impostazione DIU fino a raggiungere il limite di larghezza di banda della rete o il limite di operazioni di I/O al secondo/larghezza di banda degli archivi dati oppure fino a raggiungere il numero massimo di 256 DIU consentito per una singola attività di copia.
Se sono state ottimizzate le prestazioni di una singola attività di copia, ma non sono ancora stati raggiunti i limiti massimi di velocità effettiva dell'ambiente, è possibile eseguire più attività di copia in parallelo.
Quando viene visualizzato un numero significativo di errori di limitazione dal monitoraggio delle attività di copia, indica che è stato raggiunto il limite di capacità dell'account di archiviazione. ADF proverà automaticamente a superare ogni errore di limitazione per assicurarsi che non ci saranno dati persi, ma troppi tentativi possono compromettere anche la velocità effettiva della copia. In tal caso, è consigliabile ridurre il numero di attività di copia in esecuzione simultaneamente per evitare quantità significative di errori di limitazione. Se si usa un'unica attività di copia per copiare i dati, è consigliabile ridurre la diu.
Migrazione dei dati Delta
È possibile usare diversi approcci per caricare solo i file nuovi o aggiornati da Data Lake Storage Gen1:
- Caricare file nuovi o aggiornati in base al tempo di cartella o nome file partizionato. Un esempio è /2019/05/13/*.
- Caricare file nuovi o aggiornati da LastModifiedDate. Se si copiano grandi quantità di file, eseguire prima di tutto le partizioni per evitare una bassa velocità effettiva di copia da un'unica attività di copia che analizza l'intero account Data Lake Storage Gen1 per identificare i nuovi file.
- Identificare i file nuovi o aggiornati da qualsiasi strumento o soluzione di terze parti. Passare quindi il nome del file o della cartella alla pipeline di Data Factory tramite un parametro o una tabella o un file.
La frequenza corretta per eseguire il caricamento incrementale dipende dal numero totale di file in Azure Data Lake Storage Gen1 e dal volume di file nuovi o aggiornati da caricare ogni volta.
Sicurezza di rete
Per impostazione predefinita, Azure Data Factory trasferisce i dati da Azure Data Lake Storage Gen1 a Gen2 usando una connessione crittografata tramite protocollo HTTPS. Il protocollo HTTPS offre la crittografia dei dati in transito e impedisce l'intercettazione e gli attacchi man-in-the-middle.
In alternativa, se non si desidera trasferire i dati tramite Internet pubblico, è possibile ottenere una maggiore sicurezza trasferendo i dati tramite una rete privata.
Mantieni elenchi di controllo di accesso
Per replicare gli elenchi di controllo di accesso insieme ai file di dati quando si esegue l'aggiornamento da Data Lake Storage Gen1 a Data Lake Storage Gen2, vedere Mantenere gli elenchi di controllo di accesso da Data Lake Storage Gen1.
Resilienza
All'interno di una singola esecuzione dell'attività di copia, ADF include un meccanismo di ripetizione dei tentativi incorporato che consente di gestire un determinato livello di errori temporanei negli archivi dati o nella rete sottostante. Se si esegue la migrazione di più di 10 TB di dati, è consigliabile partizionare i dati per ridurre il rischio di eventuali problemi imprevisti.
È anche possibile abilitare la tolleranza di errore nell'attività di copia per ignorare gli errori predefiniti. La verifica della coerenza dei dati nell'attività di copia può anche essere abilitata per eseguire una verifica aggiuntiva per assicurarsi che i dati non vengano solo copiati correttamente dall'origine all'archivio di destinazione, ma anche verificati di essere coerenti tra l'archivio di origine e quello di destinazione.
Autorizzazioni
In Data Factory il connettore Data Lake Storage Gen1 supporta l'entità servizio e l'identità gestita per le autenticazioni delle risorse di Azure. Il connettore Data Lake Storage Gen2 supporta la chiave dell'account, l'entità servizio e l'identità gestita per le autenticazioni delle risorse di Azure. Per consentire a Data Factory di spostarsi e copiare tutti i file o gli elenchi di controllo di accesso (ACL) è necessario concedere autorizzazioni sufficienti all'account per accedere, leggere o scrivere tutti i file e impostare ACL se si sceglie di. È necessario concedere all'account un ruolo con privilegi avanzati o di proprietario durante il periodo di migrazione e rimuovere le autorizzazioni elevate al termine della migrazione.