Eseguire la migrazione dei dati da Amazon S3 ad Azure Data Lake Storage Gen2
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Usare i modelli per eseguire la migrazione di petabyte di dati costituiti da centinaia di milioni di file da Amazon S3 ad Azure Data Lake Storage Gen2.
Nota
Se si vuole copiare un volume di dati di piccole dimensioni da AWS S3 ad Azure (ad esempio, meno di 10 TB), è più efficiente e facile usare lo strumento Copia dati di Azure Data Factory. Il modello descritto in questo articolo è più di quello necessario.
Informazioni sui modelli di soluzione
La partizione dei dati è consigliata soprattutto quando si esegue la migrazione di più di 10 TB di dati. Per partizionare i dati, usare l'impostazione "prefisso" per filtrare le cartelle e i file in Amazon S3 in base al nome e quindi ogni processo di copia di Azure Data Factory può copiare una partizione alla volta. È possibile eseguire più processi di copia ADF simultaneamente per una migliore velocità effettiva.
La migrazione dei dati richiede in genere una migrazione cronologica monouso e la sincronizzazione periodica delle modifiche da AWS S3 ad Azure. Di seguito sono riportati due modelli, in cui un modello copre la migrazione dei dati cronologici una tantum e un altro modello illustra la sincronizzazione delle modifiche da AWS S3 ad Azure.
Per consentire al modello di eseguire la migrazione dei dati cronologici da Amazon S3 ad Azure Data Lake Storage Gen2
Questo modello (nome modello: eseguire la migrazione dei dati cronologici da AWS S3 ad Azure Data Lake Storage Gen2) presuppone che sia stato scritto un elenco di partizioni in una tabella di controllo esterna in database SQL di Azure. Verrà quindi usata un'attività Lookup per recuperare l'elenco di partizioni dalla tabella di controllo esterna, eseguire l'iterazione su ogni partizione e fare in modo che ogni processo di copia di Azure Data Factory copia una partizione alla volta. Una volta completato qualsiasi processo di copia, usa l'attività Stored procedure per aggiornare lo stato di copia di ogni partizione nella tabella di controllo.
Il modello contiene cinque attività:
- La ricerca recupera le partizioni che non sono state copiate in Azure Data Lake Storage Gen2 da una tabella di controllo esterna. Il nome della tabella è s3_partition_control_table e la query per caricare i dati dalla tabella è "SELECT PartitionPrefix FROM s3_partition_control_table WHERE SuccessOrFailure = 0".
- ForEach ottiene l'elenco di partizioni dall'attività Lookup e scorre ogni partizione nell'attività TriggerCopy . È possibile impostare batchCount per eseguire più processi di copia di Azure Data Factory contemporaneamente. Questo modello è stato impostato su 2.
- ExecutePipeline esegue la pipeline CopyFolderPartitionFromS3 . Il motivo per cui si crea un'altra pipeline per creare una copia di ogni processo di copia di una partizione è che è facile eseguire di nuovo il processo di copia non riuscito per ricaricare la partizione specifica da AWS S3. Tutti gli altri processi di copia che in quel momento caricano altre partizioni non saranno interessati.
- Copiare ogni partizione da AWS S3 ad Azure Data Lake Storage Gen2.
- SqlServerStoredProcedure aggiorna lo stato della copia di ogni partizione nella tabella di controllo.
Il modello contiene due parametri:
- AWS_S3_bucketName è il nome del bucket in AWS S3 da cui si vuole eseguire la migrazione dei dati. Se si vuole eseguire la migrazione dei dati da più bucket in AWS S3, è possibile aggiungere una colonna nella tabella di controllo esterna per archiviare il nome del bucket per ogni partizione e aggiornare la pipeline per recuperare di conseguenza i dati da tale colonna.
- Azure_Storage_fileSystem è il nome del fileSystem in Azure Data Lake Storage Gen2 in cui si vuole eseguire la migrazione dei dati.
Per copiare i file modificati solo da Amazon S3 ad Azure Data Lake Storage Gen2
Questo modello (nome modello: copiare i dati differenziali da AWS S3 ad Azure Data Lake Storage Gen2) usa LastModifiedTime di ogni file per copiare i file nuovi o aggiornati solo da AWS S3 ad Azure. Tenere presente che i file o le cartelle sono già stati partizionati con informazioni timelice come parte del nome del file o della cartella in AWS S3 (ad esempio, /aaaa/mm/gg/file.csv), è possibile passare a questa esercitazione per ottenere l'approccio più efficiente per il caricamento incrementale di nuovi file. Questo modello presuppone che sia stato scritto un elenco di partizioni in una tabella di controllo esterna in database SQL di Azure. Verrà quindi usata un'attività Lookup per recuperare l'elenco di partizioni dalla tabella di controllo esterna, eseguire l'iterazione su ogni partizione e fare in modo che ogni processo di copia di Azure Data Factory copia una partizione alla volta. Quando ogni processo di copia inizia a copiare i file da AWS S3, si basa sulla proprietà LastModifiedTime per identificare e copiare solo i file nuovi o aggiornati. Una volta completato qualsiasi processo di copia, usa l'attività Stored procedure per aggiornare lo stato di copia di ogni partizione nella tabella di controllo.
Il modello contiene sette attività:
- La ricerca recupera le partizioni da una tabella di controllo esterna. Il nome della tabella è s3_partition_delta_control_table e la query per caricare i dati dalla tabella è "select distinct PartitionPrefix from s3_partition_delta_control_table".
- ForEach ottiene l'elenco di partizioni dall'attività Lookup e scorre ogni partizione nell'attività TriggerDeltaCopy . È possibile impostare batchCount per eseguire più processi di copia di Azure Data Factory contemporaneamente. Questo modello è stato impostato su 2.
- ExecutePipeline esegue la pipeline DeltaCopyFolderPartitionFromS3 . Il motivo per cui si crea un'altra pipeline per creare una copia di ogni processo di copia di una partizione è che è facile eseguire di nuovo il processo di copia non riuscito per ricaricare la partizione specifica da AWS S3. Tutti gli altri processi di copia che in quel momento caricano altre partizioni non saranno interessati.
- La ricerca recupera il tempo di esecuzione dell'ultimo processo di copia dalla tabella di controllo esterna in modo che i file nuovi o aggiornati possano essere identificati tramite LastModifiedTime. Il nome della tabella è s3_partition_delta_control_table e la query per caricare i dati dalla tabella è "select max(JobRunTime) as LastModifiedTime from s3_partition_delta_control_table where PartitionPrefix = '@{pipeline().parameters.prefixStr}' and SuccessOrFailure = 1".
- Copiare copia i file nuovi o modificati solo per ogni partizione da AWS S3 ad Azure Data Lake Storage Gen2. La proprietà modifiedDatetimeStart è impostata sull'ora di esecuzione dell'ultimo processo di copia. La proprietà modifiedDatetimeEnd è impostata sul tempo di esecuzione del processo di copia corrente. Tenere presente che l'ora viene applicata al fuso orario UTC.
- SqlServerStoredProcedure aggiorna lo stato della copia di ogni partizione e del tempo di esecuzione della copia nella tabella di controllo quando ha esito positivo. La colonna di SuccessOrFailure è impostata su 1.
- SqlServerStoredProcedure aggiorna lo stato della copia di ogni partizione e del tempo di esecuzione della copia nella tabella di controllo in caso di errore. La colonna di SuccessOrFailure è impostata su 0.
Il modello contiene due parametri:
- AWS_S3_bucketName è il nome del bucket in AWS S3 da cui si vuole eseguire la migrazione dei dati. Se si vuole eseguire la migrazione dei dati da più bucket in AWS S3, è possibile aggiungere una colonna nella tabella di controllo esterna per archiviare il nome del bucket per ogni partizione e aggiornare la pipeline per recuperare di conseguenza i dati da tale colonna.
- Azure_Storage_fileSystem è il nome del fileSystem in Azure Data Lake Storage Gen2 in cui si vuole eseguire la migrazione dei dati.
Come usare questi due modelli di soluzione
Per consentire al modello di eseguire la migrazione dei dati cronologici da Amazon S3 ad Azure Data Lake Storage Gen2
Creare una tabella di controllo in database SQL di Azure per archiviare l'elenco di partizioni di AWS S3.
Nota
Il nome della tabella è s3_partition_control_table. Lo schema della tabella di controllo è PartitionPrefix e SuccessOrFailure, dove PartitionPrefix è l'impostazione del prefisso in S3 per filtrare le cartelle e i file in Amazon S3 in base al nome e SuccessOrFailure è lo stato della copia di ogni partizione: 0 significa che questa partizione non è stata copiata in Azure e 1 significa che questa partizione è stata copiata correttamente in Azure. Nella tabella di controllo sono definite 5 partizioni e lo stato predefinito della copia di ogni partizione è 0.
CREATE TABLE [dbo].[s3_partition_control_table]( [PartitionPrefix] [varchar](255) NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_control_table (PartitionPrefix, SuccessOrFailure) VALUES ('a', 0), ('b', 0), ('c', 0), ('d', 0), ('e', 0);Creare una stored procedure nella stessa database SQL di Azure per la tabella di controllo.
Nota
Il nome della stored procedure è sp_update_partition_success. Verrà richiamato dall'attività SqlServerStoredProcedure nella pipeline di Azure Data Factory.
CREATE PROCEDURE [dbo].[sp_update_partition_success] @PartPrefix varchar(255) AS BEGIN UPDATE s3_partition_control_table SET [SuccessOrFailure] = 1 WHERE [PartitionPrefix] = @PartPrefix END GOPassare al modello Eseguire la migrazione dei dati cronologici da AWS S3 ad Azure Data Lake Storage Gen2 . Immettere le connessioni alla tabella di controllo esterna, AWS S3 come archivio dell'origine dati e Azure Data Lake Storage Gen2 come archivio di destinazione. Tenere presente che la tabella di controllo esterna e la stored procedure fanno riferimento alla stessa connessione.
Selezionare Usa questo modello.
Si noterà che sono state create 2 pipeline e 3 set di dati, come illustrato nell'esempio seguente:
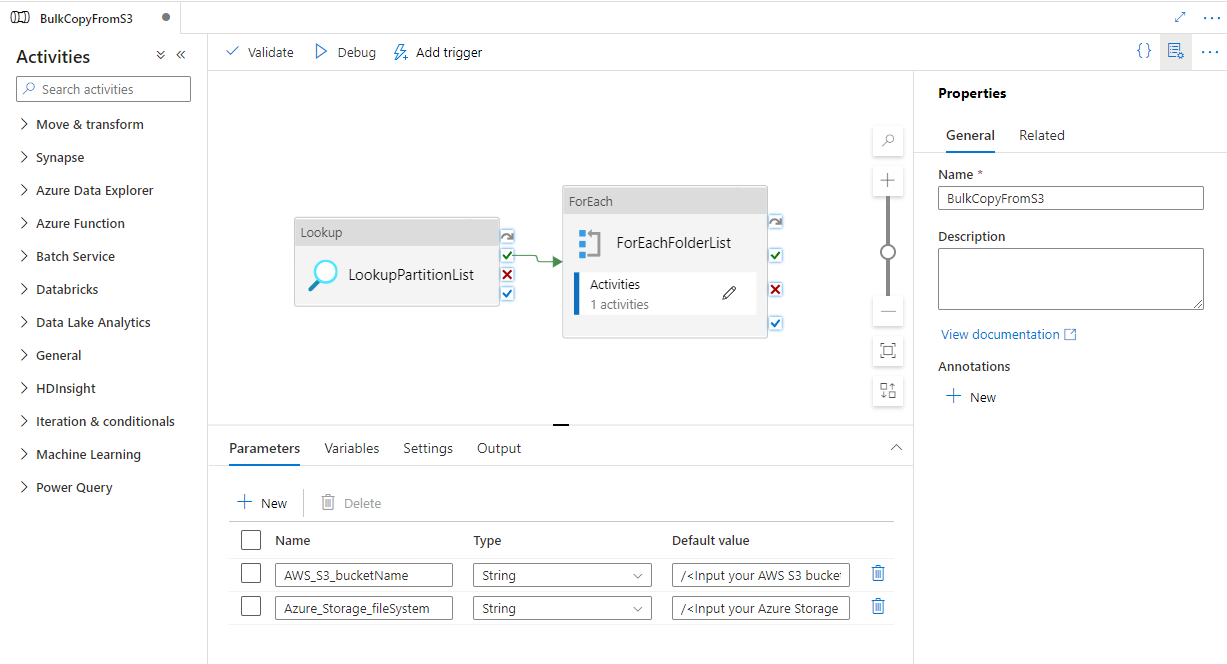
Passare alla pipeline "BulkCopyFromS3" e selezionare Debug, immettere i parametri. Quindi selezionare Fine.
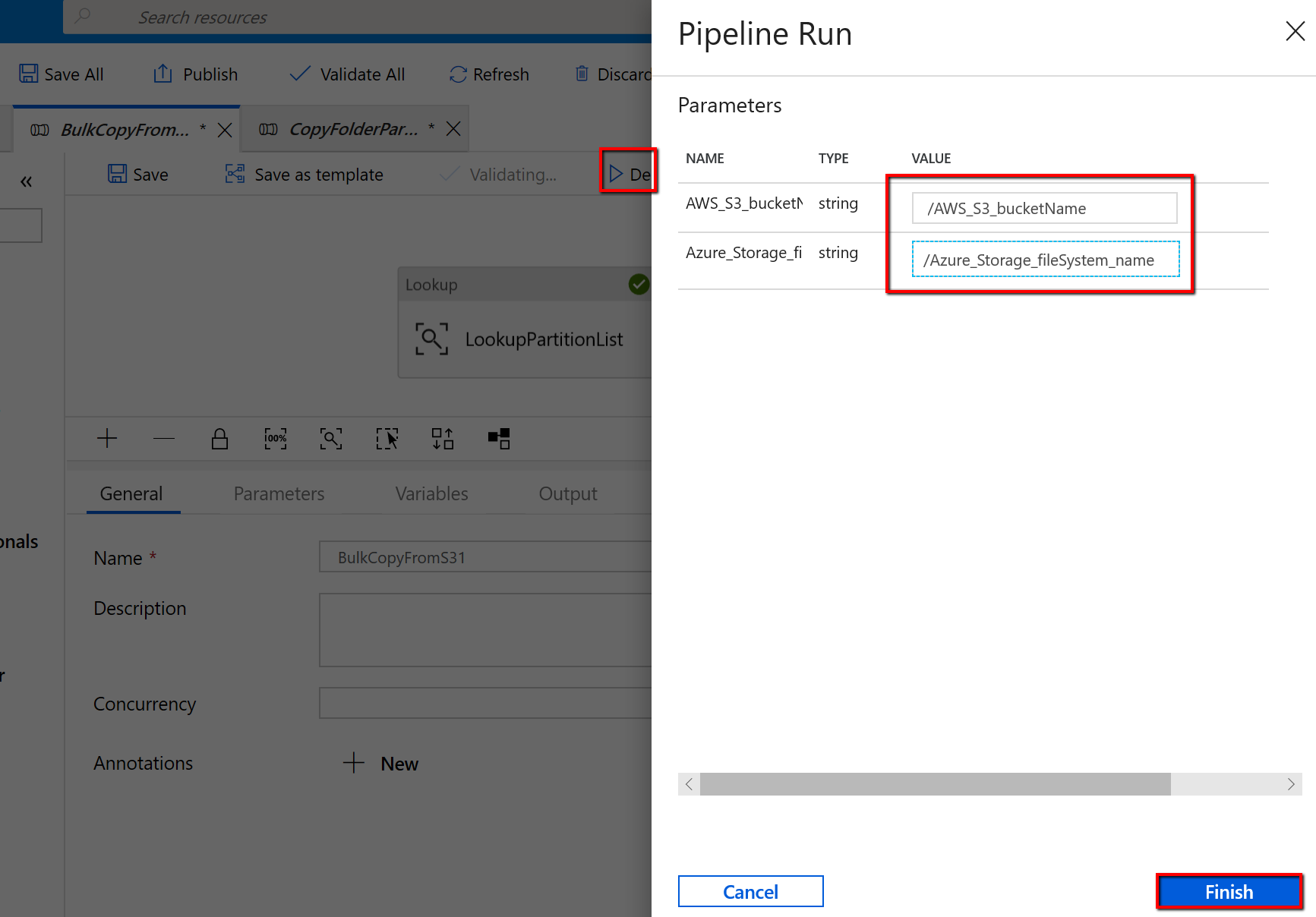
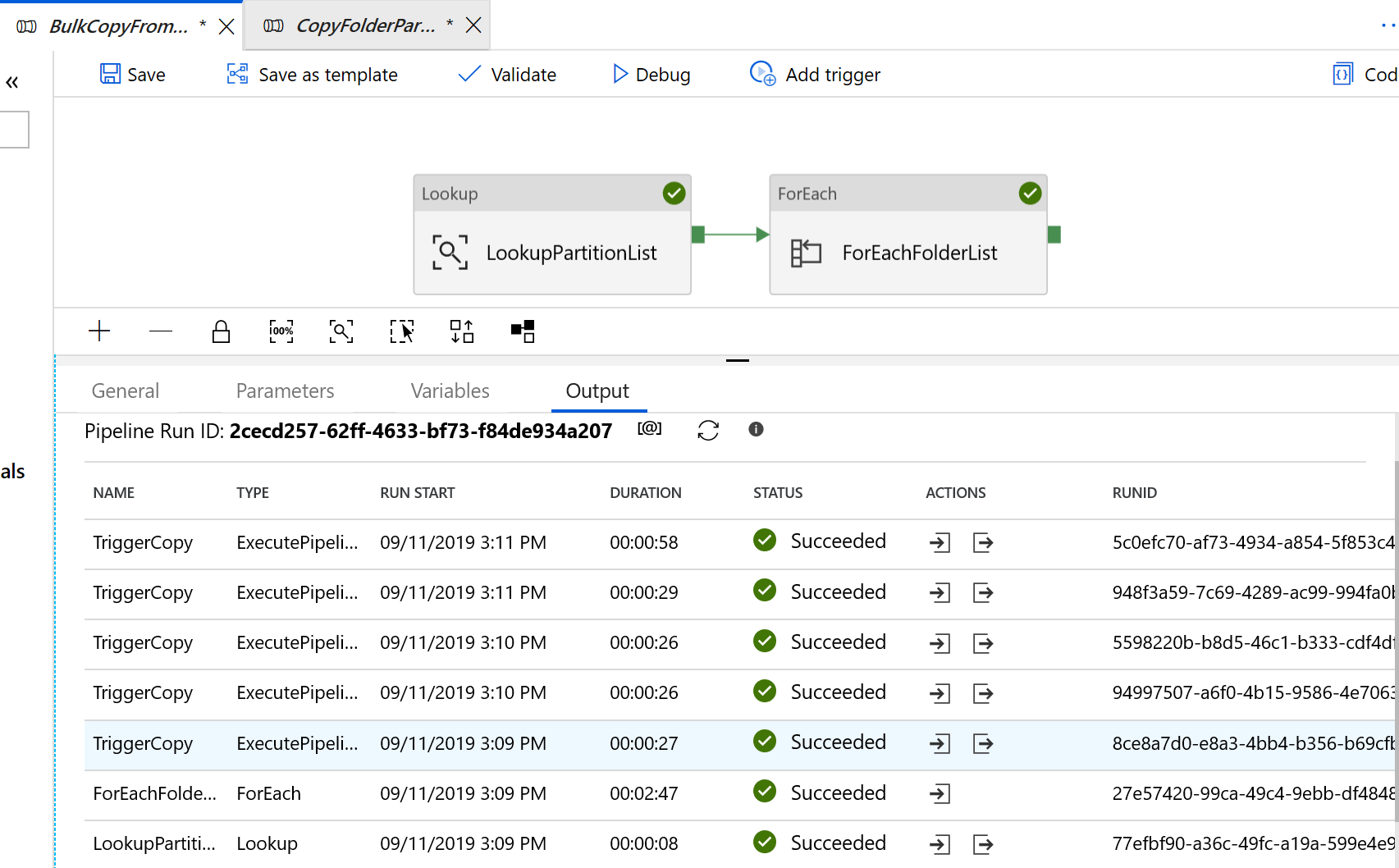
I risultati visualizzati sono simili all'esempio seguente:
Per copiare i file modificati solo da Amazon S3 ad Azure Data Lake Storage Gen2
Creare una tabella di controllo in database SQL di Azure per archiviare l'elenco di partizioni di AWS S3.
Nota
Il nome della tabella è s3_partition_delta_control_table. Lo schema della tabella di controllo è PartitionPrefix, JobRunTime e SuccessOrFailure, dove PartitionPrefix è l'impostazione del prefisso in S3 per filtrare le cartelle e i file in Amazon S3 per nome, JobRunTime è il valore datetime durante l'esecuzione dei processi di copia e SuccessOrFailure è lo stato della copia di ogni partizione: 0 indica che questa partizione non è stata copiata in Azure e 1 indica che questa partizione è stata copiata correttamente in Azure. Nella tabella di controllo sono definite 5 partizioni. Il valore predefinito per JobRunTime può essere l'ora in cui viene avviata la migrazione dei dati cronologici una tantum. L'attività di copia di Azure Data Factory copia i file in AWS S3 che sono stati modificati dopo tale data. Lo stato predefinito della copia di ogni partizione è 1.
CREATE TABLE [dbo].[s3_partition_delta_control_table]( [PartitionPrefix] [varchar](255) NULL, [JobRunTime] [datetime] NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES ('a','1/1/2019 12:00:00 AM',1), ('b','1/1/2019 12:00:00 AM',1), ('c','1/1/2019 12:00:00 AM',1), ('d','1/1/2019 12:00:00 AM',1), ('e','1/1/2019 12:00:00 AM',1);Creare una stored procedure nella stessa database SQL di Azure per la tabella di controllo.
Nota
Il nome della stored procedure è sp_insert_partition_JobRunTime_success. Verrà richiamato dall'attività SqlServerStoredProcedure nella pipeline di Azure Data Factory.
CREATE PROCEDURE [dbo].[sp_insert_partition_JobRunTime_success] @PartPrefix varchar(255), @JobRunTime datetime, @SuccessOrFailure bit AS BEGIN INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES (@PartPrefix,@JobRunTime,@SuccessOrFailure) END GOPassare al modello Copy delta data from AWS S3 to Azure Data Lake Storage Gen2 (Copia dati differenziali da AWS S3 a Azure Data Lake Storage Gen2 ). Immettere le connessioni alla tabella di controllo esterna, AWS S3 come archivio dell'origine dati e Azure Data Lake Storage Gen2 come archivio di destinazione. Tenere presente che la tabella di controllo esterna e la stored procedure fanno riferimento alla stessa connessione.
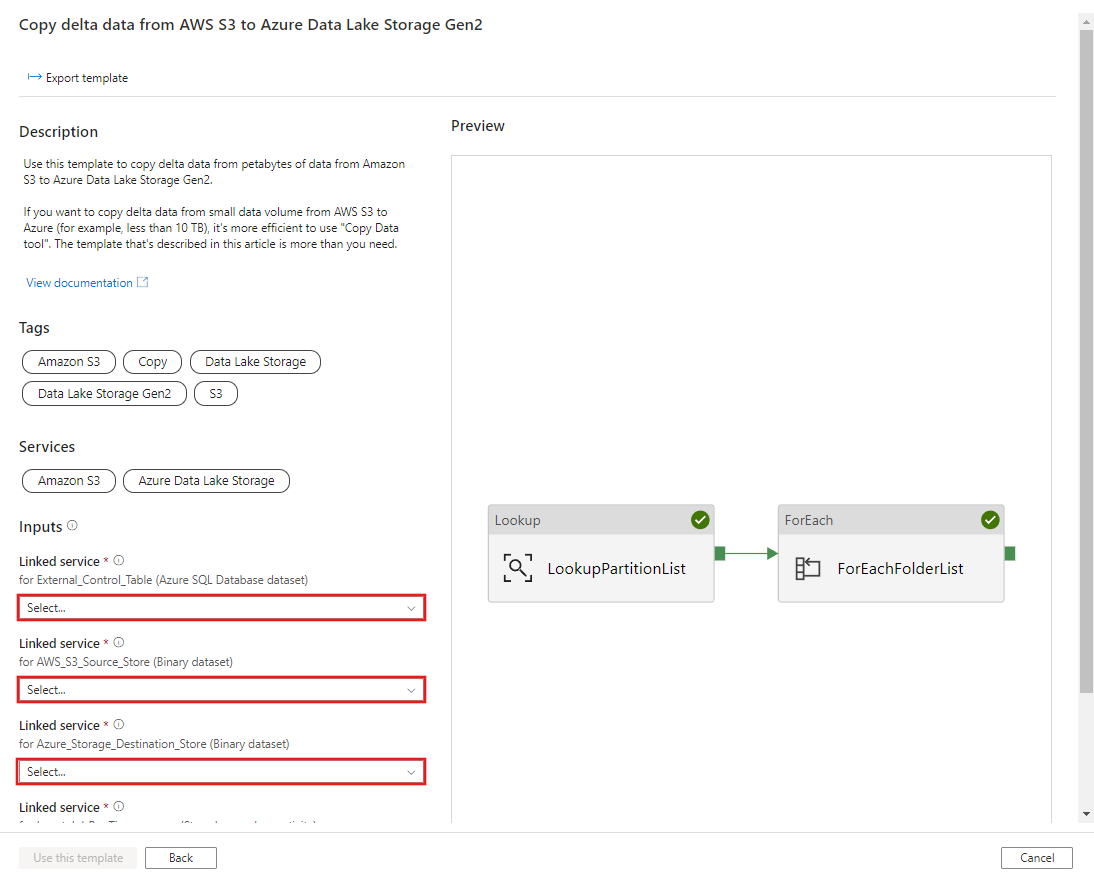
Selezionare Usa questo modello.
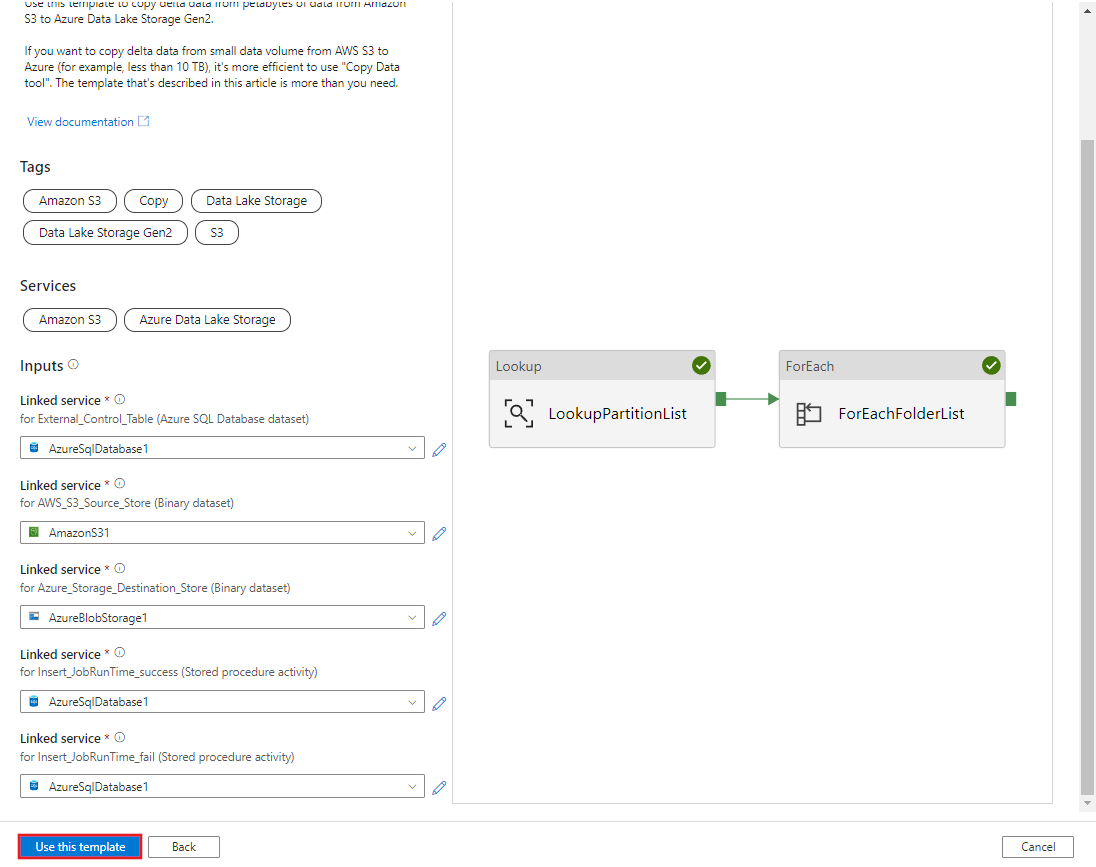
Si noterà che sono state create 2 pipeline e 3 set di dati, come illustrato nell'esempio seguente:
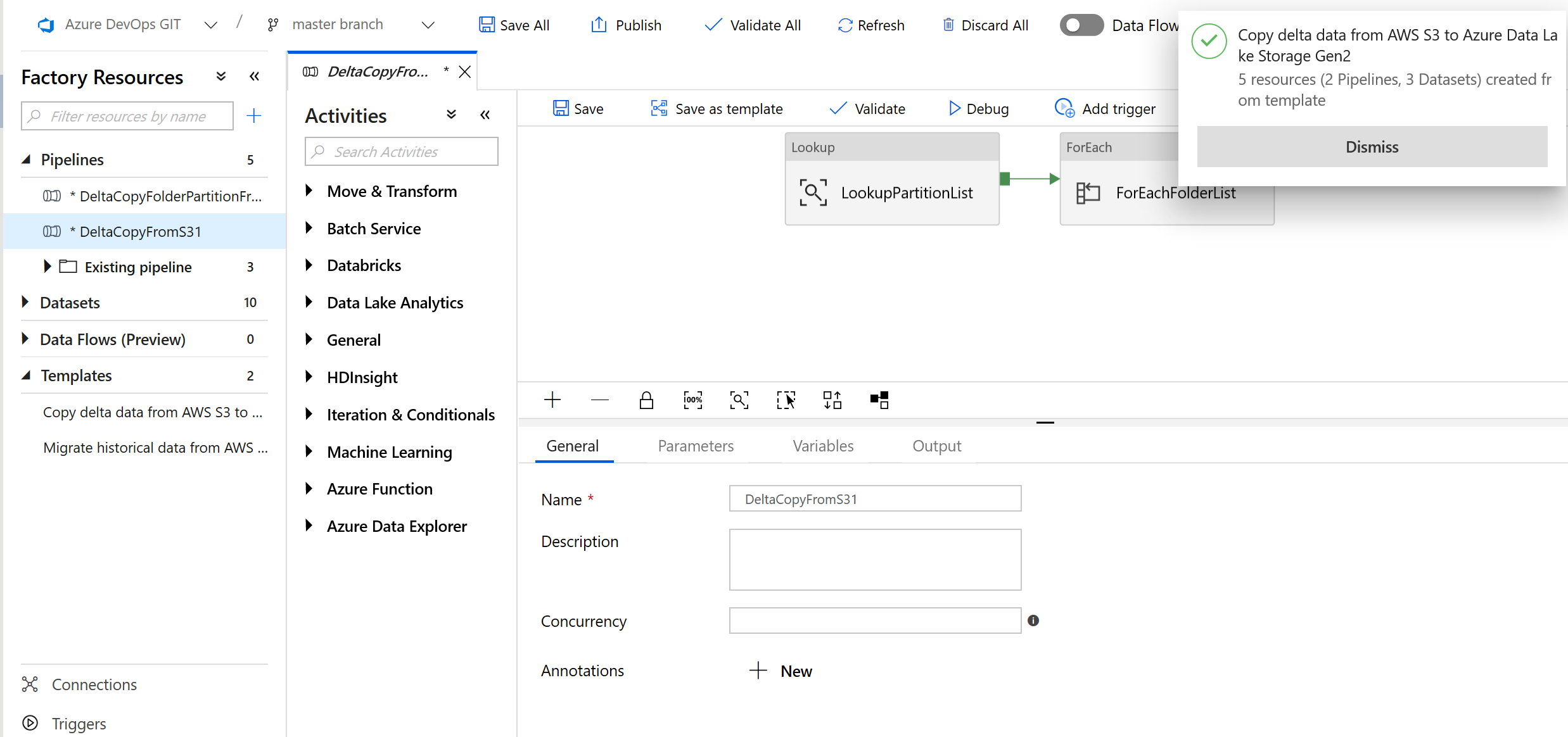
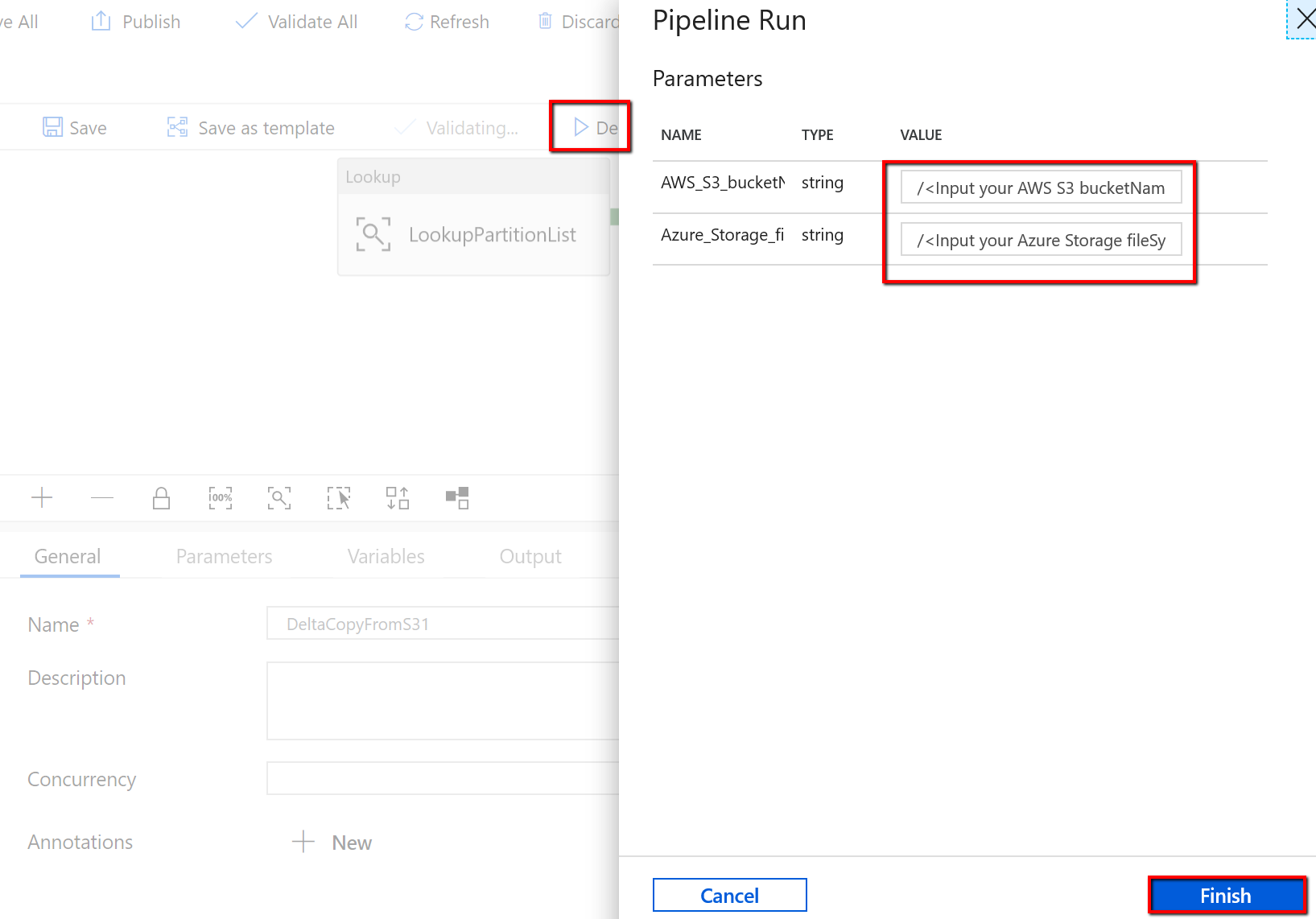
Passare alla pipeline "DeltaCopyFromS3" e selezionare Debug e immettere i parametri. Quindi selezionare Fine.
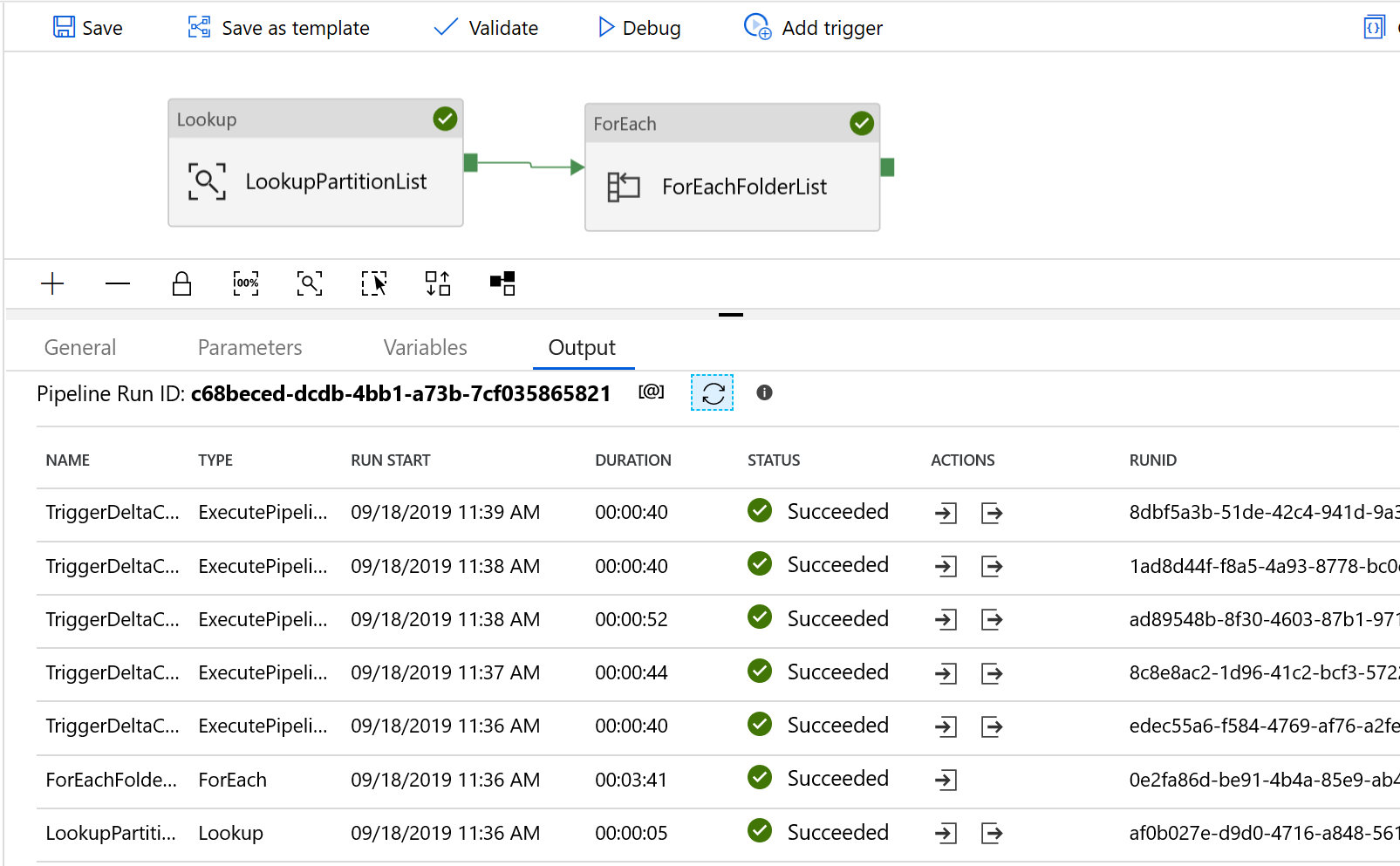
I risultati visualizzati sono simili all'esempio seguente:
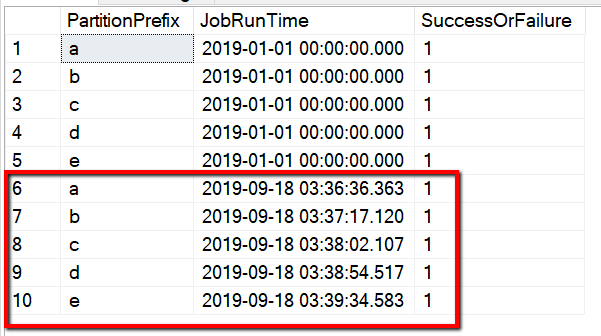
È anche possibile controllare i risultati della tabella di controllo tramite una query "select * from s3_partition_delta_control_table", verrà visualizzato l'output simile all'esempio seguente: