Trasformare i dati eseguendo un notebook di Databricks
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
L'attività notebook di Azure Databricks in una pipeline esegue un notebook di Databricks nell'area di lavoro di Azure Databricks. Questo articolo si basa sull'articolo relativo alle attività di trasformazione dei dati che presenta una panoramica generale della trasformazione dei dati e le attività di trasformazione supportate. Azure Databricks è una piattaforma gestita per l'esecuzione di Apache Spark.
È possibile creare un notebook di Databricks con un modello arm usando JSON o direttamente tramite l'interfaccia utente di Azure Data Factory Studio. Per una procedura dettagliata su come creare un'attività del notebook di Databricks usando l'interfaccia utente, fare riferimento all'esercitazione Eseguire un notebook di Databricks con l'attività notebook di Databricks in Azure Data Factory.
Aggiungere un'attività notebook per Azure Databricks a una pipeline con l'interfaccia utente
Per usare un'attività notebook per Azure Databricks in una pipeline, seguire questa procedura:
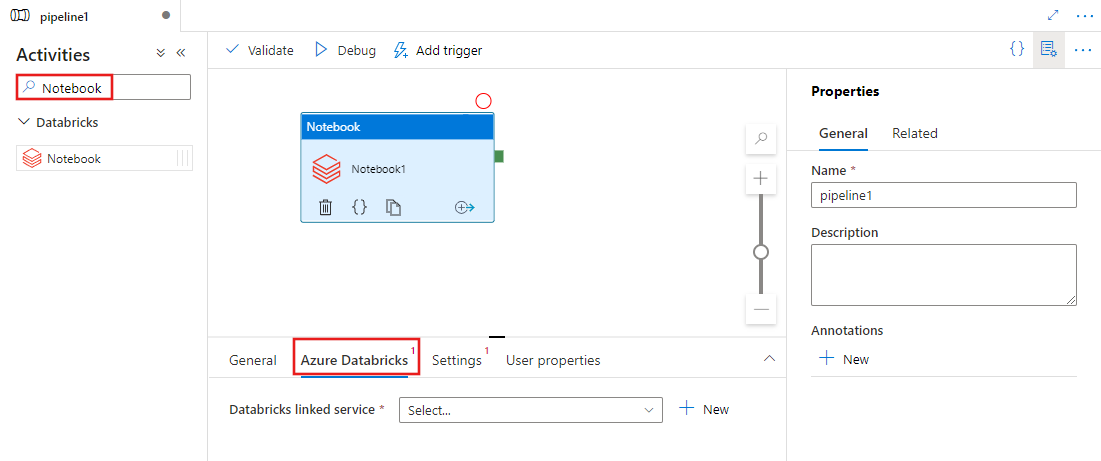
Cercare Notebook nel riquadro Attività pipeline e trascinare un'attività Notebook nell'area di disegno della pipeline.
Selezionare la nuova attività Notebook nell'area di disegno, se non è già selezionata.
Selezionare la scheda Azure Databricks per selezionare o creare un nuovo servizio collegato di Azure Databricks che eseguirà l'attività Notebook.
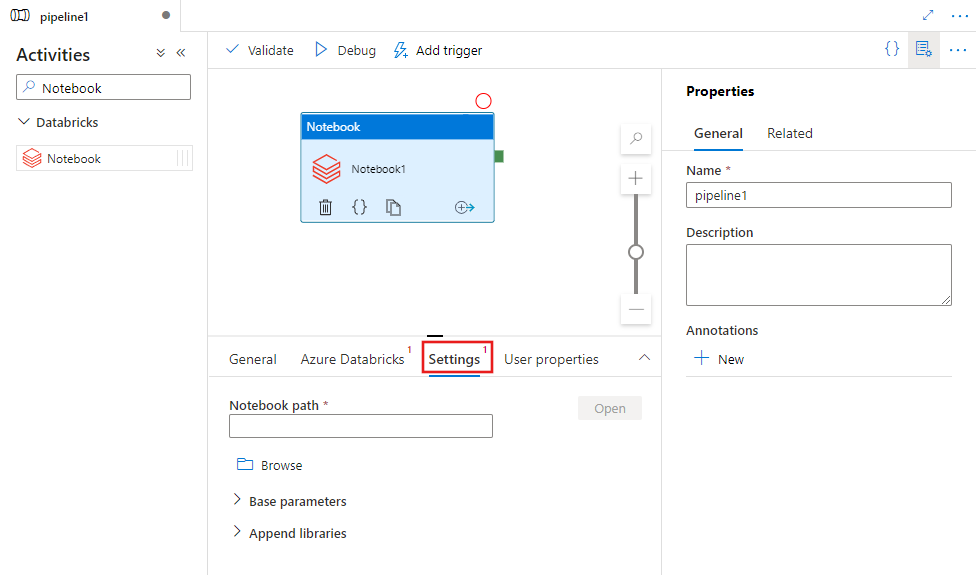
Selezionare la scheda Impostazioni e specificare il percorso del notebook da eseguire in Azure Databricks, i parametri di base facoltativi da passare al notebook e le eventuali librerie aggiuntive da installare nel cluster per eseguire il processo.
Definizione di attività dei notebook di Databricks
Ecco la definizione JSON di esempio di un'attività dei notebook di Databricks:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksNotebook",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"notebookPath": "/Users/user@example.com/ScalaExampleNotebook",
"baseParameters": {
"inputpath": "input/folder1/",
"outputpath": "output/"
},
"libraries": [
{
"jar": "dbfs:/docs/library.jar"
}
]
}
}
}
Proprietà dell'attività dei notebook di Databricks
La tabella seguente fornisce le descrizioni delle proprietà JSON usate nella definizione JSON:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| name | Nome dell'attività nella pipeline. | Sì |
| description | Testo che descrive l'attività. | No |
| type | Per l'attività dei notebook di Databricks il tipo di attività è DatabricksNotebook. | Sì |
| linkedServiceName | Nome del servizio collegato Databricks su cui è in esecuzione il notebook di Databricks. Per informazioni su questo servizio collegato, vedere l'articolo Servizi collegati di calcolo. | Sì |
| notebookPath | Percorso assoluto del notebook da eseguire nell'area di lavoro di Databricks. Questo percorso deve iniziare con una barra. | Sì |
| baseParameters | Matrice di coppie chiave-valore. I parametri base possono essere usati per ogni esecuzione attività. Se il notebook accetta un parametro non specificato, verrà usato il valore predefinito del notebook. Per altre informazioni sui parametri, vedere Notebook di Databricks. | No |
| libraries | Un elenco di librerie da installare nel cluster che eseguirà il processo. Può essere una matrice di <stringhe, oggetto> . | No |
Librerie supportate per le attività di Databricks
Nella definizione dell'attività Databricks precedente specificare questi tipi di libreria: jar, egg, whl, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"whl": "dbfs:/mnt/libraries/mlflow-0.0.1.dev0-py2-none-any.whl"
},
{
"whl": "dbfs:/mnt/libraries/wheel-libraries.wheelhouse.zip"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Per altre informazioni, consultare la documentazione di Databricks sui tipi di libreria.
Passaggio di parametri tra notebook e pipeline
È possibile passare parametri ai notebook usando la proprietà baseParameters nell'attività Databricks.
In alcuni casi, potrebbe essere necessario trasferire alcuni valori dal notebook al servizio, che possono essere utilizzati per il flusso di controllo (controlli condizionali) nel servizio o essere utilizzati da attività a valle (il limite di dimensione è di 2 MB).
Nel notebook è possibile chiamare dbutils.notebook.exit("returnValue") e il corrispondente "returnValue" verrà restituito al servizio.
È possibile utilizzare l'output nel servizio tramite espressioni come
@{activity('databricks notebook activity name').output.runOutput}.Importante
Se si passa un oggetto JSON, è possibile recuperare i valori aggiungendo nomi di proprietà. Esempio:
@{activity('databricks notebook activity name').output.runOutput.PropertyName}
Come caricare una libreria in Databricks
È possibile usare l'interfaccia utente dell'area di lavoro:
Usare l'interfaccia utente dell'area di lavoro di Databricks
Per ottenere il percorso dbfs della libreria aggiunto tramite l'interfaccia utente, è possibile usare l'interfaccia della riga di comando di Databricks.
In genere le librerie Jar sono archiviate in dbfs:/FileStore/jars quando si usa l'interfaccia utente. È possibile elencarle tutte tramite l'interfaccia della riga di comando: databricks fs ls dbfs:/FileStore/job-jars
In alternativa, è possibile usare l'interfaccia della riga di comando di Databricks:
Seguire Copiare la libreria usando l'interfaccia della riga di comando di Databricks
Usare l'interfaccia della riga di comando di Databricks (procedura di installazione)
Ad esempio, per copiare un file JAR in dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar