Come creare ed eseguire query su un indice di ricerca vettoriale
Questo articolo descrive come creare ed eseguire query su un indice di ricerca vettoriale usando Mosaic AI Vector Search.
È possibile creare e gestire componenti di ricerca vettoriale, ad esempio un endpoint di ricerca vettoriale e indici di ricerca vettoriale, usando l'interfaccia utente, Python SDKo l'API REST .
Requisiti
- Unity Catalog abilita l'area di lavoro.
- Calcolo serverless abilitato. Per istruzioni, vedere Connect to serverless compute.
- L'origine table deve avere il feed di dati delle modifiche abilitato. Per le istruzioni, vedere Usare il feed di dati delle modifiche Delta Lake in Azure Databricks.
- Per creare un indice di ricerca vettoriale, è necessario disporre dei privilegi di CREATE TABLE per il catalogschemawhere in cui verrà creato l'indice.
- Per eseguire una query su un indice di proprietà di un altro utente, è necessario disporre di privilegi aggiuntivi. Vedi Esegui query su un endpoint di ricerca vettoriale.
L'autorizzazione per creare e gestire gli endpoint di ricerca vettoriali viene configurata usando gli elenchi di controllo di accesso. Consulta gli ACL per l'endpoint di ricerca vettoriale .
Installazione
Per usare l'SDK di ricerca vettoriale, è necessario installarlo nel notebook. Usare il codice seguente:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
from databricks.vector_search.client import VectorSearchClient
Autenticazione
Vedere Protezione dei dati e autenticazione.
Creare un endpoint di ricerca vettoriale
È possibile creare un endpoint di ricerca vettoriale usando l'interfaccia utente di Databricks, Python SDK o l'API.
Creare un endpoint di ricerca vettoriale usando l'interfaccia utente
Seguire questa procedura per creare un endpoint di ricerca vettoriale usando l'interfaccia utente.
Nella barra laterale sinistra fare clic su Calcolo.
Fare clic sulla scheda ricerca vettoriale e fare clic su Crea.

Si apre il modulo Crea un endpoint. Immettere un nome per questo endpoint.
Fare clic su Conferma.
Creare un endpoint di ricerca vettoriale con Python SDK
Nell'esempio seguente viene usata la funzione create_endpoint() SDK per creare un endpoint di ricerca vettoriale.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearch(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
Creare un endpoint di ricerca vettoriale usando l'API REST
Consultare la documentazione di riferimento dell'API REST: POST /api/2.0/vector-search/endpoints.
(Facoltativo) Creare e configurare un endpoint per gestire il modello di incorporamento
Se si sceglie di usare databricks per calcolare gli incorporamenti, è possibile usare un endpoint delle API del modello di base preconfigurato o creare un endpoint di gestione di un modello per gestire il modello di incorporamento preferito. Per istruzioni, vedere API modello di base con pagamento in base al token o Creare un modello di base che gestisce gli endpoint. Per esempi di notebook, consultare gli esempi per chiamare un modello di embedding.
Quando si configura un endpoint di incorporamento, Databricks consiglia di remove la selezione predefinita di Scala su zero. Gli endpoint di servizio possono richiedere un paio di minuti per scaldarsi, e la query iniziale su un indice con un endpoint ridimensionato può andare in timeout.
Nota
L'inizializzazione dell'indice di ricerca vettoriale potrebbe andare in timeout se l'endpoint di embedding non è configurato correttamente per il set di dati. È consigliabile usare solo endpoint CPU per set di dati e test di piccole dimensioni. Per set di dati di dimensioni maggiori, usare un endpoint GPU per ottenere prestazioni ottimali.
Creare un indice di ricerca vettoriale
È possibile creare un indice di ricerca vettoriale usando l'interfaccia utente, Python SDK o l'API REST. L'interfaccia utente è l'approccio più semplice.
Esistono due tipi di indici:
- Delta Sync Index si sincronizza automaticamente con il Delta Tabledi origine, aggiornando l'indice in modo automatico e incrementale man mano che i dati sottostanti nel Delta Table cambiano.
- Direct Vector Access Index supporta la lettura diretta e scrittura di vettori e metadati. L'utente è responsabile dell'aggiornamento di questa table tramite l'API REST o Python SDK. Questo tipo di indice non può essere creato usando l'interfaccia utente. È necessario usare l'API REST o l'SDK.
Creare un indice usando l'interfaccia utente
Nella barra laterale sinistra fare clic su Catalog per aprire l'interfaccia utente di Esplora Catalog.
Vai al Delta table che desideri utilizzare.
Fare clic sul pulsante crea
in alto a destra e indice di ricerca vector dal menu a discesa.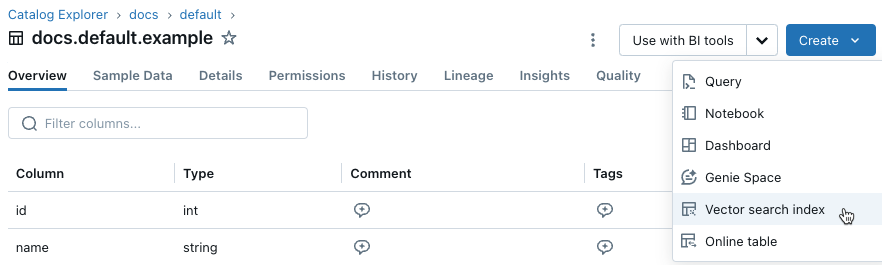
Usare i selettori nella finestra di dialogo per configurare l'indice.
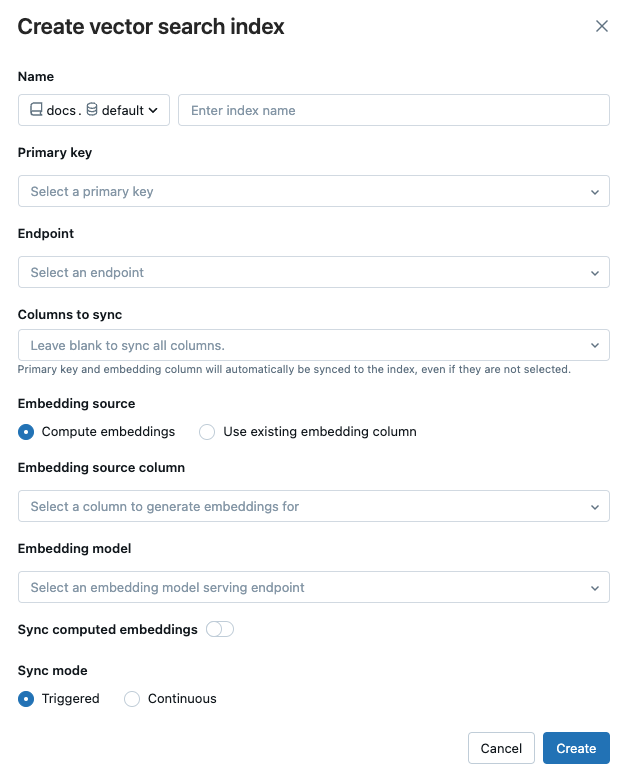
Nome: nome da utilizzare per il table online in Unity Catalog. Il nome richiede un namespace a tre livelli,
<catalog>.<schema>.<name>. Sono consentiti solo caratteri alfanumerici e caratteri di sottolineatura.chiave primaria: Column da usare come chiave primaria.
Endpoint: Select l'endpoint di ricerca vettoriale che desideri utilizzare.
Columns a sync: Select al columns al sync con l'indice vettoriale. Se lasci questo campo vuoto, tutti i columns della fonte table vengono sincronizzati con l'indice. La chiave primaria column e la sorgente di incorporamento column o il vettore di incorporamento column sono sempre sincronizzati.
Sorgente di incorporamento: indicare se si desidera che Databricks calcoli gli incorporamenti per un testo column nel Delta table (Calcolo degli incorporamenti) o se il tuo Delta table contiene incorporamenti precalcolati (Usa l' columnincorporamento esistente ).
- Se hai selezionato calcolare incorporamenti, select l'column per cui desideri che gli incorporamenti vengano calcolati e l'endpoint che gestisce il modello di incorporamento. Sono supportati solo i testi columns.
- Se hai selezionato Usa embedding esistente column, select il column che contiene gli embedding precomputati e la dimensione dell'embedding. Il formato dell'embedding precomputato column deve essere
array[float].
Sync incorporamenti calcolati: attivare o disattivare questa impostazione per salvare gli incorporamenti generati in un CatalogtableUnity. Per ulteriori informazioni, vedere Salva l'incorporamento generato table.
Sync modalità: modalità continua mantiene l'indice in sync con alcuni secondi di latenza. Tuttavia, ha un costo più elevato associato ad esso, poiché è necessario predisporre un cluster di calcolo per l'esecuzione continua della pipeline di streaming sync. Per continuo e attivato, l'update è incrementale — vengono elaborati solo i dati modificati dall'ultimo sync.
Con la modalità sync attivata, si utilizza l'SDK di Python o l'API REST per avviare il sync. Consultare Update un indice Delta Sync.
Al termine della configurazione dell'indice, fare clic su Crea.
Creare un indice con Python SDK
Nell'esempio seguente viene creato un indice delta Sync con incorporamenti calcolati da Databricks.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
Nell'esempio seguente viene creato un indice Delta Sync con incorporamenti autogestiti. In questo esempio viene inoltre illustrato l'uso del parametro facoltativo columns_to_sync per select solo un subset di columns da usare nell'indice.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
Per impostazione predefinita, tutti i columns del table di origine vengono sincronizzati con l'indice. Per sync solo un subset di columns, usare columns_to_sync. La chiave primaria e l'incorporamento columns sono sempre incluse nell'indice.
Per syncsolo la chiave primaria e l'incorporamento column, è necessario specificarli in columns_to_sync come illustrato di seguito:
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Per synccolumnsaggiuntive, specificarle come illustrato. Non è necessario includere la chiave primaria e l'embedding column, poiché sono sempre sincronizzati.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
Nell'esempio seguente viene creato un indice di accesso a vettori diretti.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Creare un indice usando l'API REST
Consulta la documentazione di riferimento dell'API REST: POST /api/2.0/vector-search/indexes.
Salva table di incorporamento generato
Se Databricks genera gli incorporamenti, è possibile salvare gli incorporamenti generati a table su Unity Catalog. Questo table viene creato nella stessa schema dell'indice vettoriale ed è collegato dalla pagina dell'indice vettoriale.
Il nome del table è il nome dell'indice di ricerca vettoriale, aggiunto da _writeback_table. Il nome non è modificabile.
È possibile accedere e interrogare i table come qualsiasi altro table in Unity Catalog. Tuttavia, non è consigliabile eliminare o modificare il table, perché non è progettato per essere aggiornato manualmente. Il table viene eliminato automaticamente se l'indice viene eliminato.
Update un indice di ricerca vettoriale
Update un indice delta Sync
Gli indici creati con modalitàsync continua update automaticamente quando cambia il table Delta di origine. Se si utilizza la modalità attivatasync, utilizzare il Python SDK o l'API REST per avviare il sync.
Python SDK
index.sync()
REST API
Vedere la documentazione di riferimento dell'API REST: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Update un indice di accesso a vettori diretti
È possibile usare l'SDK di Python o l'API REST per insert, updateo eliminare dati da un indice di accesso diretto ai vettori.
Python SDK
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
API REST
Consultare la documentazione di riferimento dell'API REST: POST /api/2.0/vector-search/indexes.
L'esempio di codice seguente illustra come update un indice usando un token di accesso personale .
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
Nell'esempio di codice seguente viene illustrato come update un indice usando un'entità servizio.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
Eseguire una query su un endpoint di ricerca vettoriale
È possibile eseguire query solo sull'endpoint di ricerca vettoriale usando il Python SDK, l'API REST o la funzione AI SQL vector_search().
Nota
Se l'utente che esegue query sull'endpoint non è il proprietario dell'indice di ricerca vettoriale, l'utente deve disporre dei privilegi uc seguenti:
- USE CATALOG sul catalog che contiene l'indice di ricerca vettoriale.
- USE SCHEMA sul schema che contiene l'indice di ricerca vettoriale.
- SELECT sull'indice di ricerca vettoriale.
Per eseguire una ricerca ibrida di somiglianza con parole chiave, set il parametro query_type per hybrid. Il valore predefinito è ann (vicino più prossimo approssimativo).
Python SDK
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
API REST
Consultare la documentazione di riferimento dell'API REST: POST /api/2.0/vector-search/indexes/{index_name}/query.
Nell'esempio di codice seguente viene illustrato come eseguire query su un indice usando un token di accesso personale ( PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query Vector Search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
Nell'esempio di codice seguente viene illustrato come eseguire una query su un indice usando un principale del servizio.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint (TODO: link), then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
Importante
La funzione di intelligenza artificiale vector_search() è disponibile in anteprima pubblica.
Per utilizzare la funzione di intelligenza artificiale , consultare la funzione di ricerca vettoriale .
Usare filtri per le query
Una query può definire filtri basati su qualsiasi column nel delta table.
similarity_search restituisce solo le righe che corrispondono ai filtri specificati. Sono supportati i filtri seguenti:
| Operatore di filtro | Comportamento | Esempi |
|---|---|---|
NOT |
Nega il filtro. La chiave deve terminare con "NOT". Ad esempio, "color NOT" con valore "rosso" corrisponde ai documenti in cui il colore non è rosso, come nel caso del documento where. |
{"id NOT": 2}
{“color NOT”: “red”}
|
< |
Controlla se il valore del campo è minore del valore del filtro. La chiave deve terminare con " <". Ad esempio, "price <" con valore 200 corrisponde ai documenti where il prezzo è minore di 200. | {"id <": 200} |
<= |
Controlla se il valore del campo è minore o uguale al valore del filtro. La chiave deve terminare con " <=". Ad esempio, "price <=" con valore 200 corrisponde ai documenti where il prezzo è minore o uguale a 200. | {"id <=": 200} |
> |
Controlla se il valore del campo è maggiore del valore del filtro. La chiave deve terminare con " >". Ad esempio, "prezzo >" con valore 200 corrisponde ai documenti where in cui il prezzo è maggiore di 200. | {"id >": 200} |
>= |
Controlla se il valore del campo è maggiore o uguale al valore del filtro. La chiave deve terminare con " >=". Ad esempio, "price >=" con valore 200 corrisponde ai documenti where in cui il prezzo è maggiore o uguale a 200. | {"id >=": 200} |
OR |
Controlla se il valore del campo corrisponde a uno dei filtri values. La chiave deve contenere OR per separare più sottochiavi. Ad esempio, color1 OR color2 con valore ["red", "blue"] corrisponde a documenti wherecolor1 è red o color2 è blue. |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
Trova la corrispondenza con stringhe parziali. | {"column LIKE": "hello"} |
| Nessun operatore di filtro specificato | Il filtro verifica la corrispondenza esatta. Se vengono specificate più values, corrisponde a una qualsiasi delle values. |
{"id": 200}
{"id": [200, 300]}
|
Vedere gli esempi di codice seguenti:
Python SDK
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
REST API
Vedere POST /api/2.0/vector-search/indexes/{index_name}/query.
Notebook di esempio
Gli esempi in questa sezione illustrano l'uso di Python SDK per la ricerca vettoriale.
Esempi di LangChain
Vedi Come utilizzare LangChain con la Ricerca Vettoriale di Mosaic AI per l'integrazione della Ricerca Vettoriale di Mosaic AI con i pacchetti LangChain.
Il notebook seguente illustra come convertire i risultati della ricerca di somiglianza in documenti LangChain.
Ricerca vettoriale con il notebook Python SDK
Notebook : esempi per chiamare un modello di embedding
I notebook seguenti illustrano come configurare un endpoint Mosaic AI Model Serving per la generazione di incorporamenti.