Mosaic AI Vector Search
Questo articolo offre una panoramica della soluzione di database vettoriale di Databricks, Mosaic AI Vector Search, incluso cos’è e come funziona.
Che cos'è Mosaic AI Vector Search?
Mosaic AI Vector Search è un database vettoriale integrato in Databricks Data Intelligence Platform e integrato con i relativi strumenti di governance e produttività. Un database vettoriale è un database ottimizzato per archiviare e recuperare gli incorporamenti. Gli incorporamenti sono rappresentazioni matematiche del contenuto semantico dei dati, in genere dati di testo o immagine. Gli incorporamenti vengono generati da un modello linguistico di grandi dimensioni e sono un componente chiave di molte applicazioni GenAI che dipendono dalla ricerca di documenti o immagini simili tra loro. Esempi ne sono i sistemi RAG, i sistemi di raccomandazione e il riconoscimento di immagini e video.
Con Mosaic AI Vector Search si crea un indice di ricerca vettoriale da un delta table. L'indice include dati incorporati con i metadati. È quindi possibile eseguire query sull'indice usando un'API REST per identificare i vettori più simili e restituire i documenti associati. È possibile strutturare l'indice per sync automaticamente quando viene aggiornato il table Delta sottostante.
Mosaic AI Vector Search supporta quanto segue:
- Ricerca ibrida di somiglianza tra parole chiave.
- Filtro.
- Elenchi di controllo di accesso (ACL) per gestire gli endpoint di ricerca vettoriali.
- Sync selezionato solo columns.
- Salva e sync incorporamenti generati.
Come funziona La ricerca vettoriale di Mosaic AI Vector?
Mosaic AI Vector Search usa l'algoritmo HNSW (Hierarchical Navigable Small World) per le ricerche approssimative più vicine e la metrica di distanza L2 per misurare la somiglianza del vettore di incorporamento. Se si vuole usare la somiglianza del coseno, è necessario normalizzare gli incorporamenti dei punti dati, prima di inserirli nella ricerca vettoriale. Quando i punti dati vengono normalizzati, la classificazione prodotta dalla distanza L2 corrisponde alla classificazione prodotta dalla somiglianza del coseno.
Mosaic AI Vector Search supporta anche la ricerca ibrida di somiglianza delle parole chiave, che combina la ricerca di incorporamento basata su vettori con tecniche di ricerca tradizionali basate su parole chiave. Questo approccio corrisponde a parole esatte nella query, usando anche una ricerca di somiglianza basata su vettori per acquisire le relazioni semantiche e il contesto della query.
Integrando queste due tecniche, la ricerca ibrida di somiglianza tra parole chiave recupera i documenti che contengono non solo le parole chiave esatte, ma anche quelle concettualmente simili, fornendo risultati di ricerca più completi e pertinenti. Questo metodo è particolarmente utile nelle applicazioni RAG where i dati di origine hanno parole chiave univoche, ad esempio SKU o identificatori non adatti alla ricerca di somiglianza pura.
Per informazioni dettagliate sull'API, vedere le informazioni di riferimento sull’SDK Python e Eseguire query su un endpoint di ricerca vettoriale.
Calcolo della ricerca di somiglianza
Il calcolo della ricerca di somiglianza impiega la formula seguente:
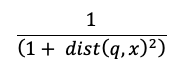
where
dist è la distanza euclidea tra la query q e la voce di indice x:
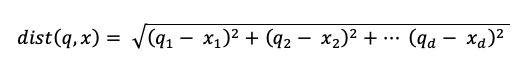
Algoritmo di ricerca delle parole chiave
I punteggi di rilevanza vengono calcolati usando Okapi BM25. Viene eseguita la ricerca di tutto il testo o della stringa columns, inclusi l'incorporamento del testo di origine e i metadati columns in formato testo o stringa. La funzione di tokenizzazione divide in corrispondenza dei limiti delle parole, rimuove la punteggiatura e converte tutto il testo in minuscolo.
In che modo vengono combinate la ricerca di somiglianza e la ricerca di parole chiave
I risultati della ricerca di somiglianza e della ricerca delle parole chiave vengono combinati usando la funzione RRF (Reciprocal Rank Fusion).
L’RRF riassegna il punteggio di ogni documento da ogni metodo usando il punteggio:
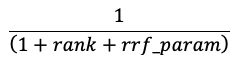
Nell'equazione precedente, la classificazione inizia a 0, somma i punteggi per ciascun documento e restituisce i documenti di punteggio più alti.
rrf_param controlla l'importanza relativa dei documenti di priorità superiore e inferiore. Sulla base della letteratura, rrf_param varia da set a 60.
I punteggi vengono normalizzati in modo che il punteggio più alto sia 1 e il punteggio più basso sia 0 usando l'equazione seguente:
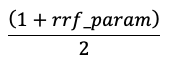
Opzioni per fornire incorporamenti vettoriali
Per creare un database vettoriale in Databricks, è prima necessario decidere come fornire gli incorporamenti vettoriali. Databricks supporta tre opzioni:
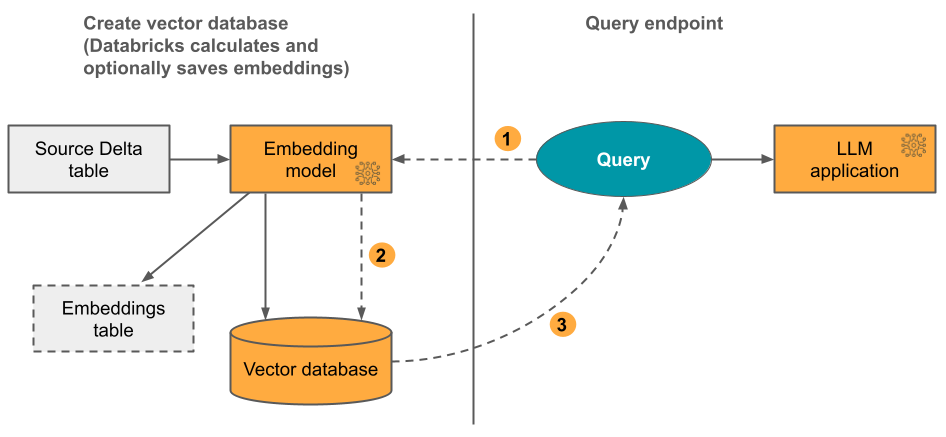
Opzione 1: Indice Delta Sync con incorporamenti calcolati da Databricks. È possibile fornire una sorgente Delta table che contiene dati in formato testo. Databricks calcola gli incorporamenti, usando un modello specificato e, facoltativamente, salva gli incorporamenti in un table in Unity Catalog. Quando il Delta table viene aggiornato, l'indice rimane sincronizzato con il Delta table.
Il diagramma seguente illustra il processo:
- Calcolare gli incorporamenti delle query. La query può includere filtri di metadati.
- Eseguire ricerche di somiglianza per identificare i documenti più rilevanti.
- Restituire i documenti più rilevanti e aggiungerli alla query.
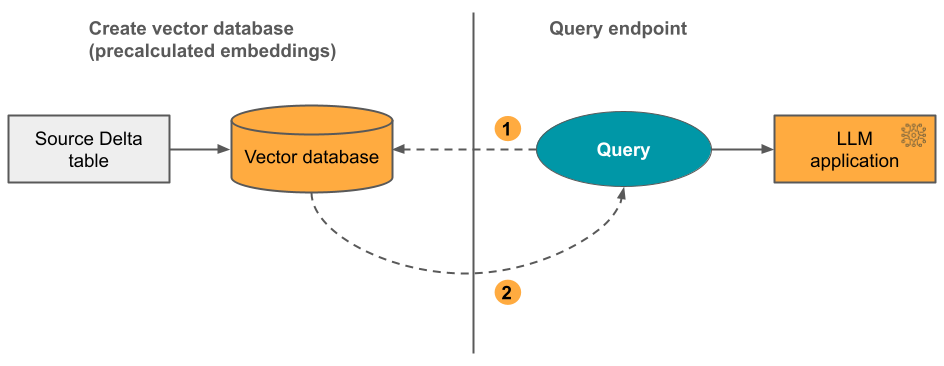
Opzione 2: Indice Delta Sync con incorporamenti autogestiti Si fornisce un Delta table di origine che contiene incorporamenti precalcolati. Quando il Delta table viene aggiornato, l'indice rimane sincronizzato con il Delta table.
Il diagramma seguente illustra il processo:
- La query è costituita da incorporamenti e può includere filtri di metadati.
- Eseguire ricerche di somiglianza per identificare i documenti più rilevanti. Restituire i documenti più rilevanti e aggiungerli alla query.
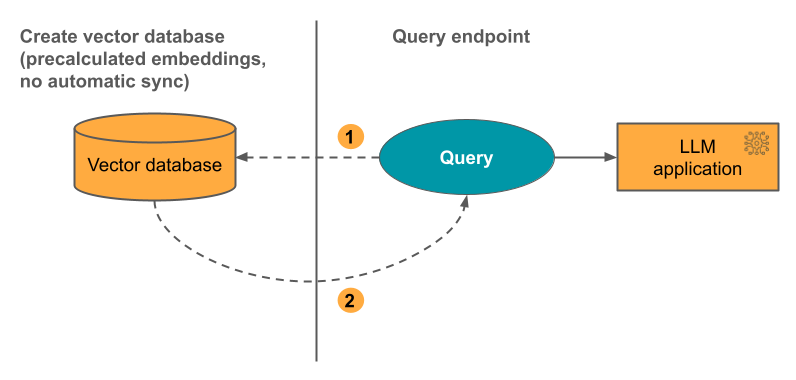
opzione 3: Direct Vector Access Index È necessario update manualmente l'indice usando l'API REST quando gli incorporamenti table cambiano.
Il diagramma seguente illustra il processo:
 automatici
automatici
Come set la ricerca del vettore di intelligenza artificiale mosaico
Per usare Mosaic AI Vector Search, è necessario creare quanto segue:
Un endpoint di ricerca vettoriale. Questo endpoint serve l'indice di ricerca vettoriale. Puoi interrogare e update l'endpoint utilizzando l'API REST o l'SDK. Per istruzioni, vedere Creare un endpoint di ricerca vettoriale.
Gli endpoint aumentano automaticamente per supportare le dimensioni dell'indice o il numero di richieste simultanee. Gli endpoint non vengono ridimensionati automaticamente.
Un indice di ricerca vettoriale. L'indice di ricerca vettoriale viene creato da un Delta table ed è ottimizzato per fornire ricerche dei vicini più prossimi approssimati in tempo reale. L'obiettivo della ricerca è identificare i documenti simili alla query. Gli indici di ricerca vettoriali vengono visualizzati in e sono regolati da Unity Catalog. Per istruzioni, vedere Creare un indice di ricerca vettoriale.
Inoltre, se si sceglie di usare Databricks per calcolare gli incorporamenti, è possibile usare un endpoint delle API del modello di base preconfigurato o creare un endpoint di servizio del modello per gestire il modello di incorporamento preferito. Per istruzioni, vedere API modello di base con pagamento per token o Creare un modello di IA generativa che serve gli endpoint.
Per eseguire query sull'endpoint di servizio del modello, usare l'API REST o l’SDK Python. La tua query può definire filtri in base a qualsiasi column nel Delta table. Per informazioni dettagliate, vedere Usare filtri per le query, le Informazioni di riferimento sull'API o le Informazioni di riferimento sull’SDK Python.
Requisiti
- Unity Catalog area di lavoro abilitato.
- Calcolo serverless abilitato. Per istruzioni, vedere Connettersi all’elaborazione serverless.
- L'table di origine deve avere il feed di dati delle modifiche abilitato. Per istruzioni, vedere Usare il feed di dati delle modifiche Delta Lake in Azure Databricks.
- Per creare un indice di ricerca vettoriale, è necessario disporre dei privilegi di CREATE TABLE sul catalogschemawhere dove verrà creato l'indice.
L'autorizzazione per creare e gestire gli endpoint di ricerca vettoriali viene configurata usando gli elenchi di controllo di accesso. Vedere ACL dell'endpoint di ricerca vettoriale.
protezione e autenticazione dei dati
Databricks implementa i controlli di sicurezza seguenti per proteggere i dati:
- Ogni richiesta del cliente a Mosaic AI Vector Search è isolata, autenticata e autorizzata logicamente.
- Mosaic AI Vector Search crittografa tutti i dati inattivi (AES-256) e in transito (TLS 1.2+).
Mosaic AI Vector Search supporta due modalità di autenticazione:
Token dell'entità servizio. Un amministratore può generate un token dell'entità servizio e passarlo all'SDK o all'API. Vedere Uso delle entità servizio. Per i casi d'uso di produzione, Databricks consiglia di usare un token dell'entità servizio.
# Pass in a service principal vsc = VectorSearchClient(workspace_url="...", service_principal_client_id="...", service_principal_client_secret="..." )Token di accesso personale. È possibile usare un token di accesso personale per eseguire l'autenticazione con Mosaic AI Vector Search. Vedere Autenticazione con token di accesso personale. Se si usa l'SDK in un ambiente notebook, l'SDK genera automaticamente un token PAT per l'autenticazione.
# Pass in the PAT token client = VectorSearchClient(workspace_url="...", personal_access_token="...")
Le chiavi gestite dal cliente (CMK) sono supportate sugli endpoint creati a partire dell'8 maggio 2024.
Monitorare l'utilizzo e i costi
Il sistema di utilizzo fatturabile table consente di monitorare l'utilizzo e i costi associati agli indici e agli endpoint di ricerca vettoriali. Di seguito è fornito un esempio di query:
WITH all_vector_search_usage (
SELECT *,
CASE WHEN usage_metadata.endpoint_name IS NULL
THEN 'ingest'
ELSE 'serving'
END as workload_type
FROM system.billing.usage
WHERE billing_origin_product = 'VECTOR_SEARCH'
),
daily_dbus AS (
SELECT workspace_id,
cloud,
usage_date,
workload_type,
usage_metadata.endpoint_name as vector_search_endpoint,
SUM(usage_quantity) as dbus
FROM all_vector_search_usage
GROUP BY all
ORDER BY 1,2,3,4,5 DESC
)
SELECT * FROM daily_dbus
Per informazioni dettagliate sul contenuto dell'utilizzo della fatturazione table, vedere sistema di utilizzo fatturabile table riferimento. Nel Notebook di esempio seguente, sono disponibili query aggiuntive.
Taccuino delle query sul sistema di ricerca vettoriale tables
Limiti relativi alle dimensioni delle risorse e dei dati
L'table seguente riepiloga i limiti delle dimensioni delle risorse e dei dati per gli endpoint e gli indici di ricerca vettoriali:
| Conto risorse | Granularità | Limit |
|---|---|---|
| Endpoint di ricerca vettoriali | Per area di lavoro | 100 |
| Incorporamenti | Per endpoint | 320.000.000 |
| Dimensione di incorporamento | Per indice | 4096 |
| Indici | Per endpoint | 50 |
| Columns | Per indice | 50 |
| Columns | Tipi supportati: byte, short, integer, long, float, double, boolean, string, timestamp, date | |
| Campi dei metadati | Per indice | 50 |
| Nome dell'indice | Per indice | 128 caratteri |
I limiti seguenti si applicano alla creazione e alla update degli indici di ricerca vettoriale:
| Conto risorse | Granularità | Limit |
|---|---|---|
| Dimensioni delle righe per l'indice delta Sync | Per indice | 100 KB |
| Dimensioni column origine di incorporamento per l'indice delta Sync | Per indice | 32764 byte |
| Dimensione della richiesta di operazione di upsert bulk limit per l'indice Direct Vector | Per indice | 10 MB |
| Dimensioni della richiesta di eliminazione bulk limit per l'indice Direct Vector | Per indice | 10 MB |
I limiti seguenti si applicano all'API della query.
| Conto risorse | Granularità | Limit |
|---|---|---|
| Lunghezza del testo della query | Per query | 32764 byte |
| Numero massimo di risultati restituiti | Per query | 10,000 |
Limiti
- Le autorizzazioni a livello di riga e column non sono supportate. Tuttavia, è possibile implementare elenchi di controllo di accesso a livello di applicazione personalizzati usando l'API di filtro.