Migliorare la qualità della pipeline di dati RAG
Questo articolo illustra come sperimentare le scelte della pipeline di dati da un punto di vista pratico nell'implementazione delle modifiche della pipeline di dati.
Componenti chiave della pipeline di dati
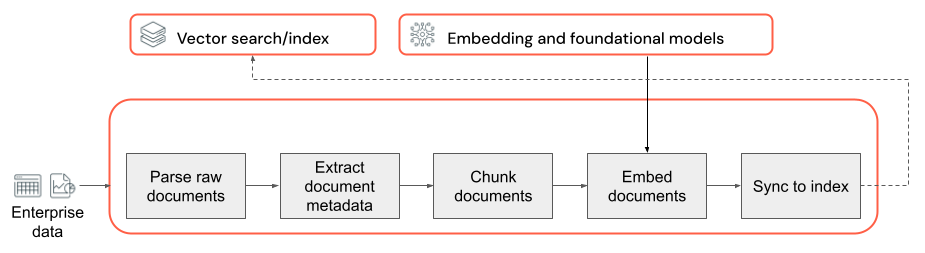
La base di qualsiasi applicazione RAG con dati non strutturati è la pipeline di dati. Questa pipeline è responsabile della preparazione dei dati non strutturati in un formato che può essere utilizzato efficacemente dall'applicazione RAG. Anche se questa pipeline di dati può diventare arbitrariamente complessa, di seguito sono riportati i componenti chiave da considerare per la prima compilazione dell'applicazione RAG:
- Composizione del corpus: selezione delle origini dati e del contenuto corretti in base al caso d'uso specifico.
- Analisi: estrazione di informazioni pertinenti dai dati non elaborati usando tecniche di analisi appropriate.
- Suddivisione in blocchi: scomporre i dati analizzati in blocchi più piccoli e gestibili per un recupero efficiente.
- Incorporamento: conversione dei dati di testo suddivisi in blocchi in una rappresentazione vettoriale numerica che acquisisce il significato semantico.
Composizione del corpus
Senza il corpus di dati corretto, l'applicazione RAG non può recuperare le informazioni necessarie per rispondere a una query dell’utente. I dati corretti dipendono interamente dai requisiti e dagli obiettivi specifici dell'applicazione, rendendo cruciale dedicare tempo alla comprensione delle sfumature dei dati disponibili (vedere la sezione Raccolta dei requisiti per indicazioni su questo argomento).
Ad esempio, quando si crea un bot di assistenza clienti, è possibile prendere in considerazione l’inclusione di:
- Documenti della knowledge base
- Domande frequenti
- Manuali e specifiche del prodotto
- Guide alla risoluzione dei problemi
Coinvolgere esperti di dominio e stakeholder fin dall'inizio di qualsiasi progetto per identificare e curare contenuti pertinenti che potrebbero migliorare la qualità e la copertura del corpus dei dati. Possono fornire informazioni dettagliate sui tipi di query che è probabile che gli utenti inviino e aiutare a classificare in ordine di priorità le informazioni più importanti da includere.
Analisi in corso
Dopo aver identificato le origini dati per l'applicazione RAG, il passaggio successivo è l’estrazione delle informazioni necessarie dai dati non elaborati. Questo processo, noto come analisi, comporta la trasformazione dei dati non strutturati in un formato che può essere utilizzato efficacemente dall'applicazione RAG.
Le tecniche e gli strumenti di analisi specifici usati dipendono dal tipo di dati in uso. Ad esempio:
- Documenti di testo (PDF, documenti di Word): librerie pronte per l’uso come non strutturate e PyPDF2 possono gestire vari formati di file e offrire opzioni per personalizzare il processo di analisi.
- Documenti HTML: librerie di analisi HTML come BeautifulSoup possono essere usate per estrarre contenuto pertinente dalle pagine web. Con esse, è possibile esplorare la struttura HTML, selezionare elementi specifici ed estrarre il testo o gli attributi desiderati.
- Immagini e documenti scansionati: le tecniche di riconoscimento ottico dei caratteri (OCR) sono in genere necessarie per estrarre testo dalle immagini. Le librerie OCR più diffuse includono Tesseract, Amazon Textract, Visione di Azure AI OCR e API Google Cloud Vision.
Procedure consigliate per l'analisi dei dati
Quando si analizzano i dati, considerare le seguenti procedure consigliate:
- Pulizia dei dati: pre-elaborare il testo estratto per rimuovere eventuali informazioni irrilevanti o fastidiose, come intestazioni, piè di pagina o caratteri speciali. Essere consapevoli della riduzione della quantità di informazioni non necessarie o in formato non valido che la catena RAG deve elaborare.
- Gestione di errori ed eccezioni: implementare meccanismi di gestione e registrazione degli errori per identificare e risolvere eventuali problemi riscontrati durante il processo di analisi. Questo aiuta a identificare i problemi e a diagnosticarli rapidamente. In questo modo spesso si punta a problemi upstream con la qualità dei dati di origine.
- Personalizzazione della logica di analisi: a seconda della struttura e del formato dei dati, potrebbe essere necessario personalizzare la logica di analisi per estrarre le informazioni più pertinenti. Anche se può richiedere ulteriori sforzi iniziali, investire il tempo necessario per eseguire questa operazione spesso evita molti problemi di qualità downstream.
- Valutazione della qualità dell'analisi: valutare regolarmente la qualità dei dati analizzati esaminando manualmente un campione dell'output. Ciò consente di identificare eventuali problemi o aree per migliorare il processo di analisi.
Suddivisione in blocchi
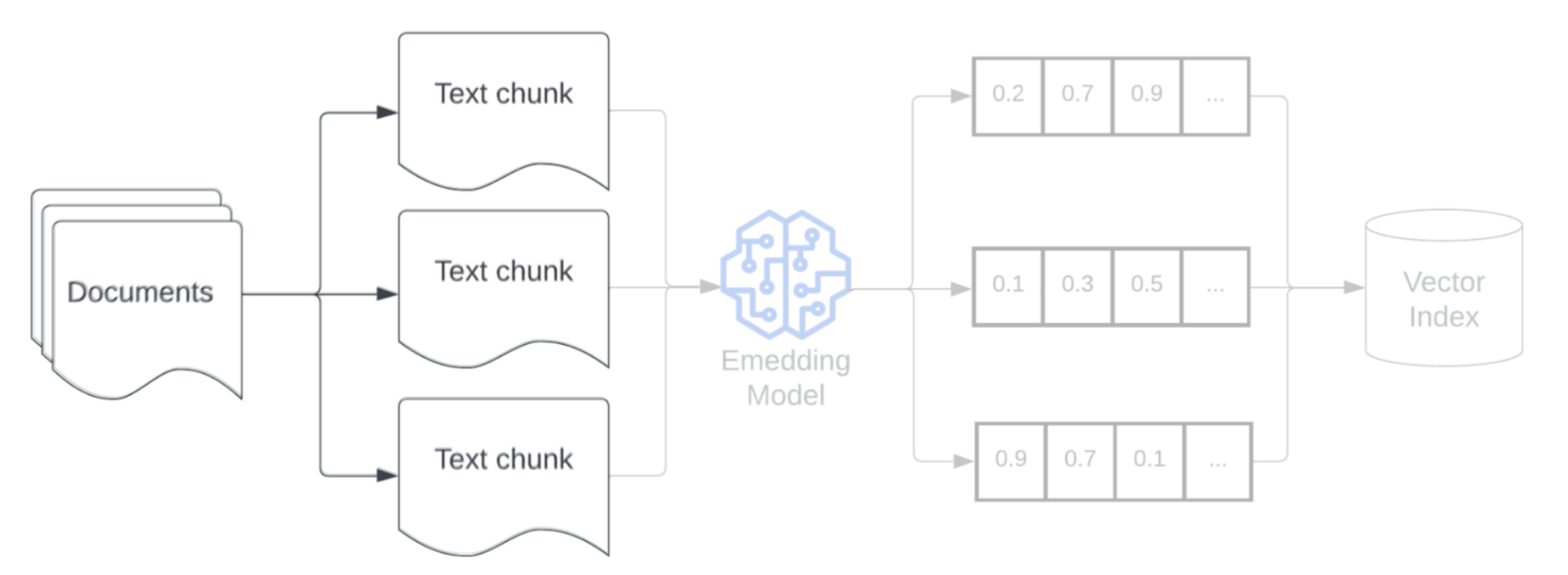
Dopo aver analizzato i dati non elaborati in un formato più strutturato, il passaggio successivo è suddividerli in unità gestibili più piccole denominate blocchi. La segmentazione di documenti di grandi dimensioni in blocchi più piccoli e concentrati semanticamente garantisce che i dati recuperati si adattino al contesto LLM, riducendo al minimo l'inclusione di informazioni irrilevanti o fastidiose. Le scelte effettuate sulla suddivisione in blocchi influiscono direttamente sui dati recuperati forniti da LLM, rendendoli uno dei primi livelli di ottimizzazione in un'applicazione RAG.
Quando si crea una suddivisione in blocchi dei dati, considerare i fattori seguenti:
- Strategia di suddivisione in blocchi: il metodo usato per dividere il testo originale in blocchi. Ciò può prevedere tecniche di base, come la suddivisione per frasi, paragrafi o conteggi di caratteri/token specifici, fino a strategie di suddivisione più avanzate specifiche per il documento.
- Dimensioni del blocco: blocchi più piccoli possono concentrarsi su dettagli specifici, ma perdere alcune informazioni circostanti. I blocchi più grandi possono acquisire più contesto, ma anche includere informazioni irrilevanti.
- Sovrapposizione tra blocchi: per assicurarsi che le informazioni importanti non vengano perse durante la suddivisione dei dati in blocchi, considerare la possibilità di includere alcune sovrapposizioni tra blocchi adiacenti. La sovrapposizione può garantire la continuità e la conservazione del contesto tra blocchi.
- Coerenza semantica: quando possibile, cercare di creare blocchi semanticamente coerenti, ossia che contengono informazioni correlate e che possono stare da soli come un'unità significativa di testo. A tale scopo, è possibile considerare la struttura dei dati originali, ad esempio paragrafi, sezioni o limiti dell'argomento.
- Metadati: l’inclusione di metadati pertinenti all'interno di ogni blocco, ad esempio il nome del documento di origine, l'intestazione della sezione o i nomi dei prodotti, può migliorare il processo di recupero. Queste informazioni aggiuntive nel blocco consentono di associare le query di recupero ai blocchi.
Strategie di suddivisione in blocchi dei dati
Trovare il metodo di suddivisione in blocchi giusto è un processo iterativo e dipendente dal contesto. Non esiste un approccio che si adatta a tutte le dimensioni; il metodo e le dimensioni ottimali del blocco dipendono dal caso d'uso specifico e dalla natura dei dati elaborati. In generale, le strategie di suddivisione in blocchi possono essere considerate come le seguenti:
- Suddivisione in blocchi a dimensione fissa: suddividere il testo in blocchi di dimensioni predeterminate, ad esempio un numero fisso di caratteri o token, (ad esempio LangChain CharacterTextSplitter). Anche se la suddivisione per un numero arbitrario di caratteri/token è rapida e facile da configurare, in genere non comporta blocchi semanticamente coerenti.
- Suddivisione in blocchi basata su paragrafo: usare i limiti naturali del paragrafo nel testo per definire i blocchi. Questo metodo può contribuire a preservare la coerenza semantica dei blocchi, poiché i paragrafi contengono spesso informazioni correlate (ad esempio LangChain RecursiveCharacterTextSplitter).
- Suddivisione in blocchi specifica per il formato: i formati come markdown o HTML hanno una struttura intrinseca al loro interno, che può essere usata per definire limiti di blocchi (ad esempio, intestazioni markdown). A tale scopo, è possibile usare strumenti come MarkdownHeaderTextSplitter di LangChain o strumenti di suddivisione basati sulle intestazioni/delle sezioni a tale scopo.
- Suddivisione in blocchi semantici: le tecniche come la modellazione di argomenti possono essere applicate per identificare sezioni semanticamente coerenti all'interno del testo. Questi approcci analizzano il contenuto o la struttura di ogni documento per determinare i limiti di blocchi più appropriati in base ai cambiamenti di argomento. Anche se più coinvolta rispetto ad approcci più basilari, la suddivisione in blocchi semantici può aiutare a creare blocchi più allineati alle divisioni semantiche naturali nel testo (vedere LangChain SemanticChunker per un esempio di questo aspetto).
Esempio: Suddivisione in blocchi a dimensione fissa
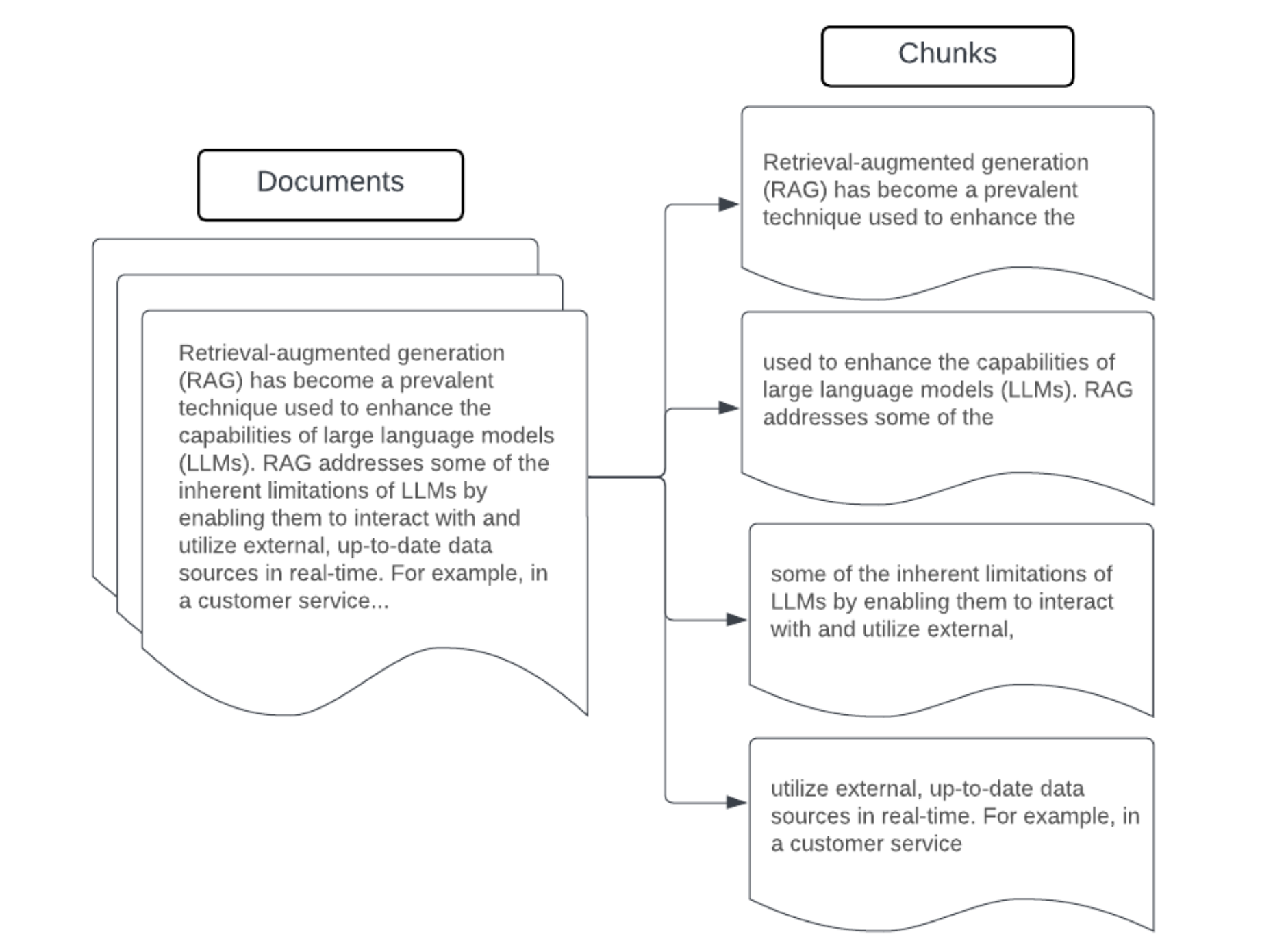
Esempio di suddivisione in blocchi a dimensione fissa usando RecursiveCharacterTextSplitter di LangChain con chunk_size=100 e chunk_overlap=20. ChunkViz offre un modo interattivo per visualizzare il modo in cui le diverse dimensioni dei blocchi e i valori di sovrapposizione dei blocchi con i separatori di caratteri di Langchain influiscono sui blocchi risultanti.
Modello di incorporamento
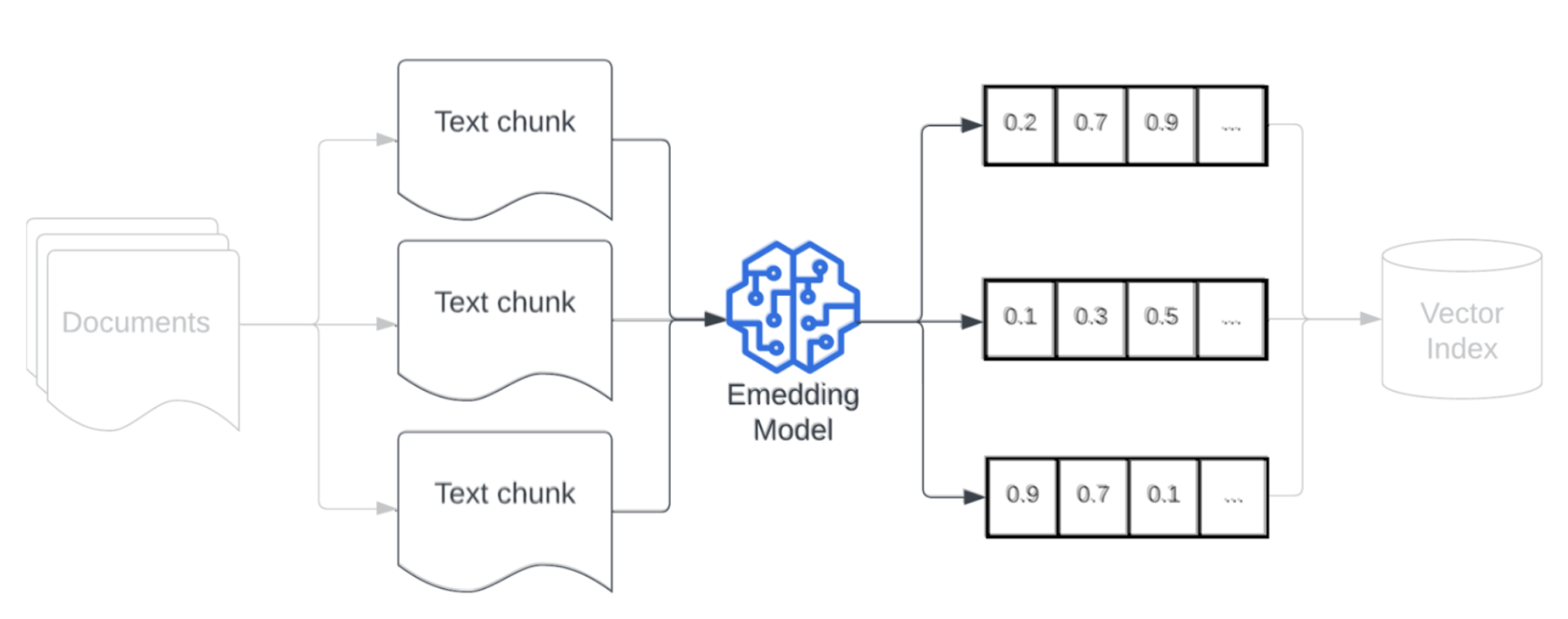
Dopo la suddivisione in blocchi dei dati, il passaggio successivo consiste nel convertire i blocchi di testo in una rappresentazione vettoriale usando un modello di incorporamento. Un modello di incorporamento viene usato per convertire ogni blocco di testo in una rappresentazione vettoriale che ne acquisisce il significato semantico. Rappresentando blocchi come vettori densi, gli incorporamenti consentono il recupero rapido e accurato dei blocchi più pertinenti in base alla loro similarità semantica con una query di recupero. Al momento della query, la query di recupero verrà trasformata usando lo stesso modello di incorporamento usato per incorporare i blocchi nella pipeline di dati.
Quando si seleziona un modello di incorporamento, considerare i seguenti fattori:
- Scelta del modello: ogni modello di incorporamento presenta le sue sfumature e i benchmark disponibili potrebbero non acquisire le caratteristiche specifiche dei dati. Sperimentare diversi modelli di incorporamento pronti all’uso, anche quelli che possono avere una posizione bassa in classifiche standard come MTEB. Ecco alcuni esempi da considerare includono:
- Numero massimo di token: essere consapevoli del limite massimo di token per il modello di incorporamento scelto. Se si creano blocchi che superano questo limite, essi verranno troncati, perdendo potenzialmente informazioni importanti. Ad esempio, bge-large-en-v1.5 ha un limite massimo di token pari a 512.
- Dimensioni del modello: i modelli di incorporamento più grandi offrono in genere prestazioni migliori, ma richiedono più risorse di calcolo. Trovare un equilibrio tra prestazioni ed efficienza in base al caso d'uso specifico e alle risorse disponibili.
- Ottimizzazione: se l'applicazione RAG gestisce un linguaggio specifico di dominio (ad esempio, terminologia o acronimi interni della società), è consigliabile ottimizzare il modello di incorporamento su dati specifici del dominio. Ciò consente al modello di acquisire meglio le sfumature e la terminologia del dominio specifico e spesso può portare a un miglioramento delle prestazioni di recupero.