Scaricare le architetture di riferimento di lakehouse
Questo articolo illustra le linee guida per l’architettura per il lakehouse in termini di origine dati, inserimento, trasformazione, esecuzione di query ed elaborazione, gestione, analisi/output e archiviazione.
Ogni architettura di riferimento ha un PDF scaricabile in formato 11 x 17 (A3).
Architettura di riferimento generica
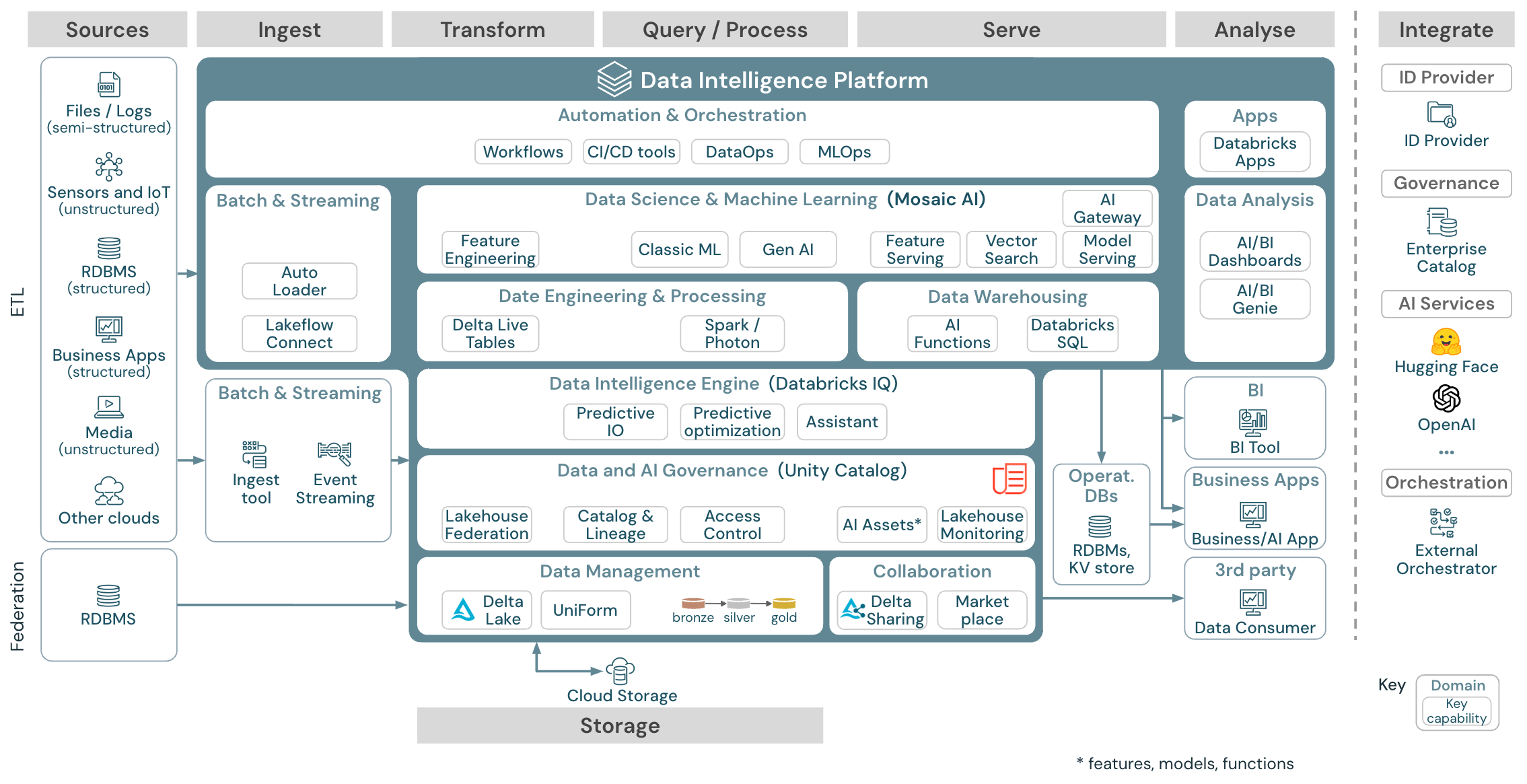
Download: Architettura di riferimento generica lakehouse per Databricks (PDF)
Organizzazione delle architetture di riferimento
L’architettura di riferimento è strutturata lungo le corsie origine, inserimento, trasformazione, query e processo, servizio, analisi e archiviazione:
Origine
L’architettura distingue tra dati semistrutturati e non strutturati (sensori e IoT, supporti, file/log) e dati strutturati (RDBMS, applicazioni aziendali). Le origini SQL (RDBMS) possono anche essere integrate nel lakehouse e nel catalogo Unity senza ETL tramite la federazione lakehouse. Inoltre, i dati potrebbero essere caricati da altri provider di servizi cloud.
Inserimento
I dati possono essere inseriti nel lakehouse tramite batch o streaming:
- I file recapitati all'archiviazione cloud possono essere caricati direttamente usando il caricatore automatico di Databricks.
- Per l’inserimento batch di dati da applicazioni aziendali in Delta Lake, databricks lakehouse si basa su strumenti di inserimento partner con adattatori specifici per questi sistemi di record.
- Gli eventi di streaming possono essere inseriti direttamente da sistemi di streaming di eventi come Kafka usando Databricks Structured Streaming. Le risorse di streaming possono essere sensori, IoT o processi di change data capture .
Storage
I dati vengono in genere archiviati nel sistema di archiviazione cloud in cui le pipeline ETL usano l’architettura medallion per archiviare i dati in modo curato come file/tabelle Delta.
Trasformare ed eseguire query ed elaborare
Databricks lakehouse usa i motori Apache Spark e Photon per tutte le trasformazioni e le query.
Grazie alla sua semplicità, il framework dichiarativo DLT (Delta Live Tables) è una buona scelta per la creazione di pipeline di elaborazione dati affidabili, gestibili e testabili.
Basato su Apache Spark e Photon, Databricks Data Intelligence Platform supporta entrambi i tipi di carichi di lavoro: query SQL tramite SQL warehouse e carichi di lavoro SQL, Python e Scala tramite cluster di aree di lavoro.
Per un’analisi scientifica dei dati (modellazione ml e intelligenza artificiale di generazione), la piattaforma databricks per intelligenza artificiale e Machine Learning fornisce una runtime di Machine Learning specializzata per AutoML e per la codifica dei processi di Machine Learning. Tutti i flussi di lavoro di data science e MLOps sono supportati in modo ottimale da MLflow.
Server
Per i casi d’uso di DWH e BI, Databricks lakehouse fornisce Databricks SQL, il data warehouse basato su SQL Warehouse e sql warehouse serverless.
Per l’apprendimento automatico, la gestione dei modelli è una funzionalità di gestione di modelli scalabili, in tempo reale e di livello aziendale che si trova nel piano di controllo di Databricks.
Database operativi: i sistemi esterni, ad esempio i database operativi, possono essere usati per archiviare e distribuire prodotti dati finali alle applicazioni utente.
Collaborazione: i partner aziendali ottengono l’accesso sicuro ai dati necessari tramite la condivisione Delta. In base alla condivisione delta, Databricks Marketplace è un forum aperto per lo scambio di prodotti dati.
Analisi
Le applicazioni aziendali finali si trovano in questa corsia riservata. Tra gli esempi sono inclusi i client personalizzati, ad esempio applicazioni di intelligenza artificiale connesse a Mosaic AI Model Serving per inferenza in tempo reale o applicazioni che accedono ai dati di cui è stato eseguito il push dal lakehouse a un database operativo.
Per i casi d’uso di BI, gli analisti usano in genere gli strumenti di business intelligence per accedere al data warehouse. Gli sviluppatori SQL possono anche usare l’editor SQL di Databricks (non illustrato nel diagramma) per le query e il dashboard.
La piattaforma di data intelligence offre anche dashboard per creare visualizzazioni dei dati e condividere informazioni dettagliate.
Funzionalità per i carichi di lavoro
Inoltre, Databricks lakehouse include funzionalità di gestione che supportano tutti i carichi di lavoro:
Governance dei dati e dell'intelligenza artificiale
Il sistema di governance centrale dei dati e dell'intelligenza artificiale in Databricks Data Intelligence Platform è Unity Catalog. Il catalogo unity offre un’unica posizione per gestire i criteri di accesso ai dati che si applicano in tutte le aree di lavoro e supporta tutti gli asset creati o usati nella lakehouse, ad esempio tabelle, volumi, funzionalità (archivio funzionalità) e modelli (registro modelli). È anche possibile usare Unity Catalog per acquisire la derivazione dei dati di runtime tra query eseguite in Databricks.
Il monitoraggio di Databricks lakehouse consente di monitorare la qualità dei dati in tutte le tabelle dell'account. Può anche tenere traccia delle prestazioni dei modelli di Machine Learning e degli endpoint di gestione dei modelli.
Per un’osservabilità, le tabelle di sistema sono un archivio analitico che si trova in Databricks dei dati operativi dell'account. Le tabelle di sistema possono essere usate per un’osservabilità cronologica nell’account.
Motore di intelligence dei dati
Databricks Data Intelligence Platform consente all’intera organizzazione di usare i dati e l'intelligenza artificiale. Si basa su DatabricksIQ e combina l’intelligenza artificiale generativa con i vantaggi di unificazione di una lakehouse per comprendere la semantica univoca dei dati.
Databricks Assistant è disponibile nei notebook di Databricks, nell’editor SQL e nell'editor di file come assistente di intelligenza artificiale compatibile con il contesto per gli sviluppatori.
Orchestrazione
I processi di Databricks orchestrano l’elaborazione dei dati, l’apprendimento automatico e le pipeline di analisi nella piattaforma data intelligence di Databricks. Le tabelle live delta consentono di creare pipeline ETL affidabili e gestibili con sintassi dichiarativa.
Architettura di riferimento di Data Intelligence Platform in Azure
L’architettura di riferimento di Azure Databricks deriva dall’architettura di riferimento generica aggiungendo servizi specifici di Azure per gli elementi Source, Ingest, Serve, Analysis/Output e Storages.
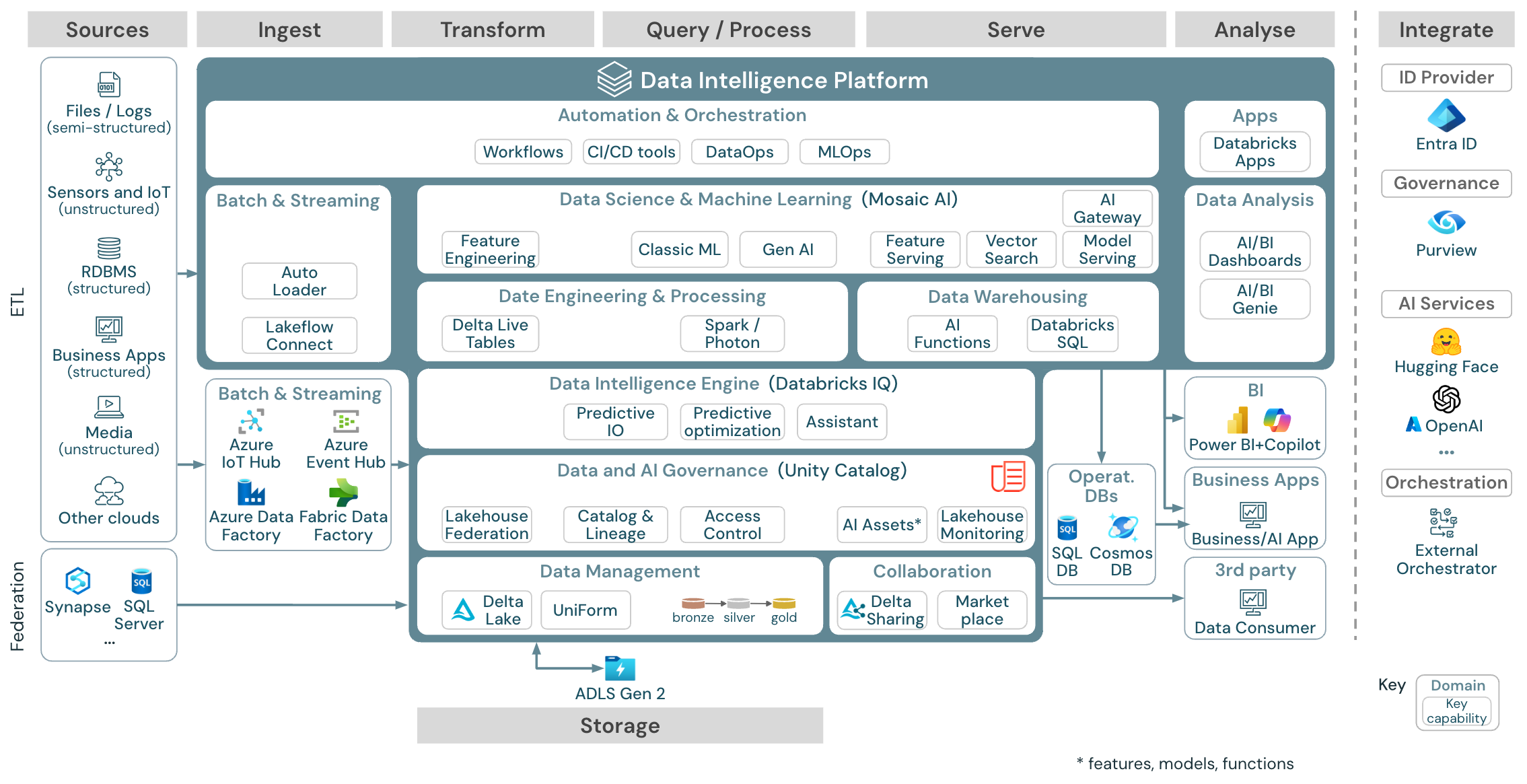
Download: Architettura di riferimento per databricks lakehouse in Azure
L’architettura di riferimento di Azure mostra i servizi specifici di Azure seguenti per inserimento, archiviazione, gestione e analisi/output:
- Azure Synapse e SQL Server come sistemi di origine per Lakehouse Federation
- Hub IoT di Azure e Hub eventi di Azure per l’inserimento in streaming
- Uso di Azure Data Factory per l’inserimento dati
- Un account di archiviazione di Azure Data Lake Storage (ADLS) Gen 2
- Database SQL di Azure e Azure Cosmos DB come database operativi
- Azure Purview come catalogo aziendale in cui UC esportare le informazioni sullo schema e sulla derivazione
- Strumento BI basato su Power BI
Nota
- Questa vista dell’architettura di riferimento è incentrata solo sui servizi di Azure e sul lakehouse di Databricks. Lakehouse in Databricks è una piattaforma aperta che si integra con un ampio ecosistema di strumenti partner.
- I servizi del provider di servizi cloud visualizzati non sono esaustivi. Vengono selezionati per illustrare il concetto.
Caso d’utilizzo: Batch ETL
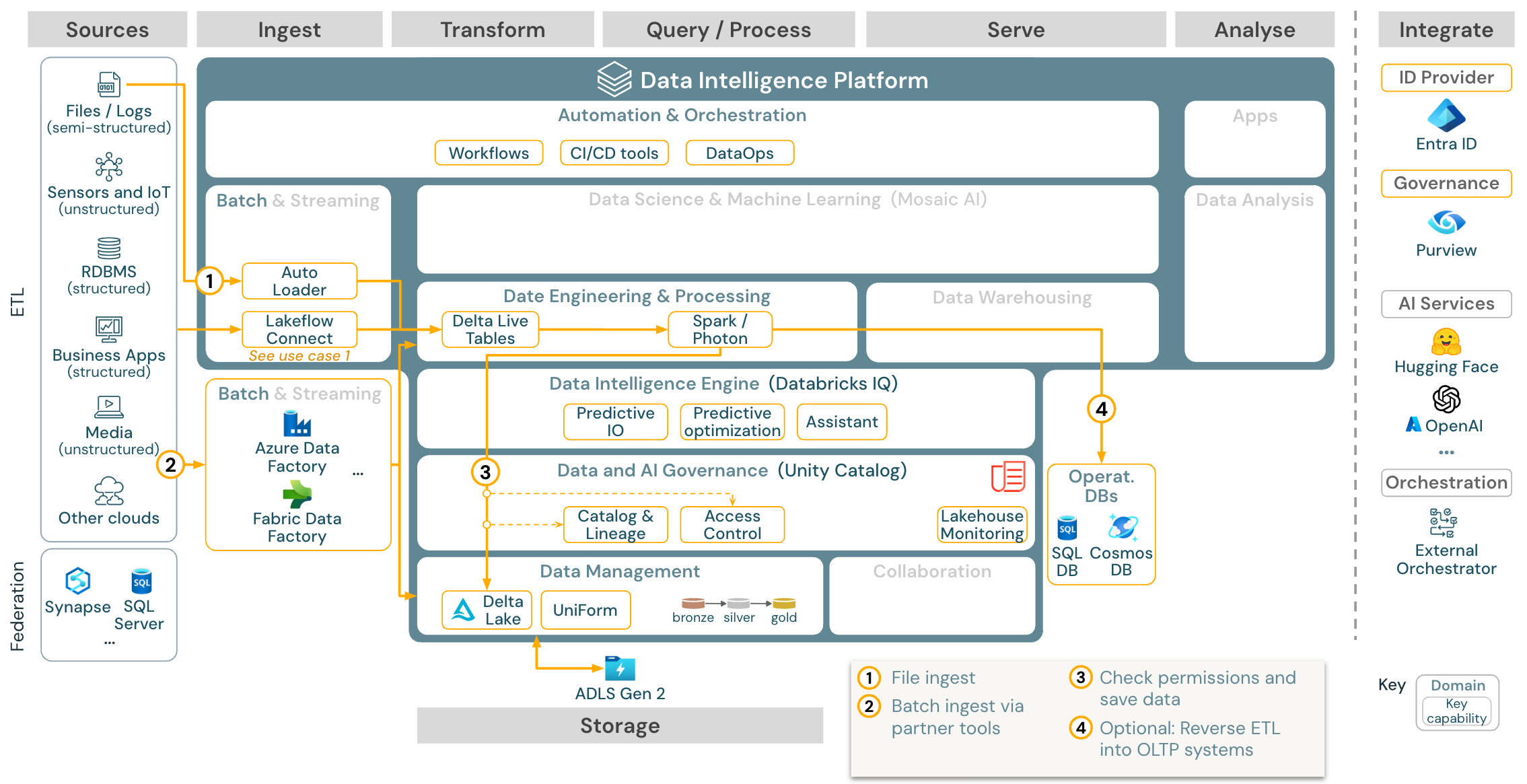
Download: Architettura di riferimento batch ETL per Azure Databricks
Gli strumenti di inserimento usano adattatori specifici dell’origine per leggere i dati dall’origine e quindi archiviarli nell'archiviazione cloud da cui il caricatore automatico può leggerlo o chiamare direttamente Databricks, ad esempio con gli strumenti di inserimento dei partner integrati nel lakehouse di Databricks. Per caricare i dati, databricks ETL e motore di elaborazione, tramite DLT, esegue le query. I flussi di lavoro singoli o multitasking possono essere orchestrati da Processi di Databricks e regolati da Unity Catalog (controllo di accesso, controllo, derivazione e così via). Se i sistemi operativi a bassa latenza che richiedono l’accesso a tabelle d’oro specifiche, possono essere esportati in un database operativo, ad esempio RDBMS o archivio chiave-valore alla fine della pipeline ETL.
Caso d’utilizzo: Streaming e Change Data Capture (CDC)
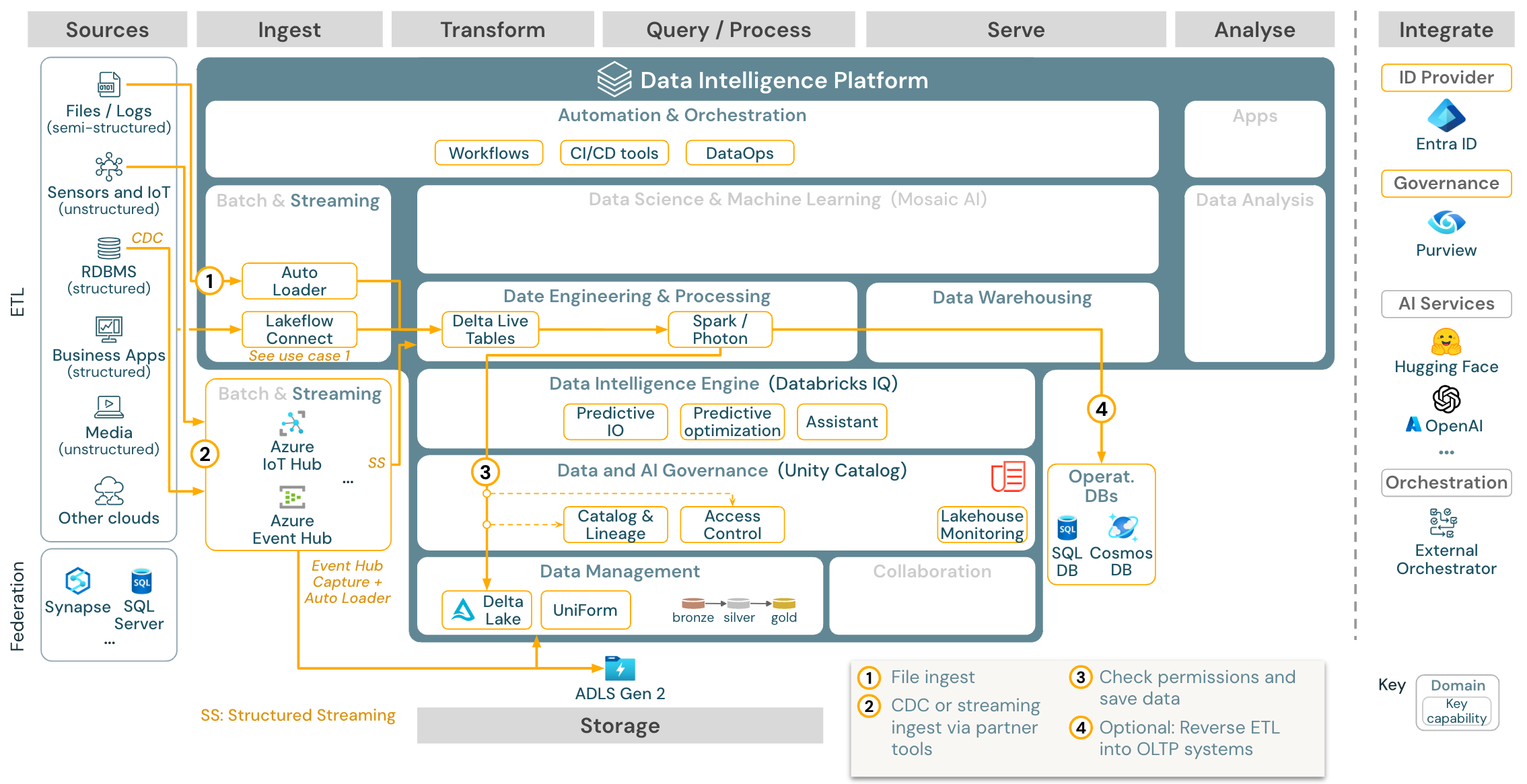
Download: Architettura di streaming strutturato Spark per Azure Databricks
Il motore ETL di Databricks usa Spark Structured Streaming per leggere da code di eventi come Apache Kafka o Hub eventi di Azure. I passaggi downstream seguono l’approccio del caso d'uso di Batch precedente.
Change Data Capture (CDC) in tempo reale usa in genere una coda di eventi per archiviare gli eventi estratti. Da qui, il caso d'uso segue il caso d’utilizzo di streaming.
Se CDC viene eseguito in batch in cui i record estratti vengono prima archiviati nell'archiviazione cloud, Databricks Autoloader può leggerli e il caso d'uso segue Batch ETL.
Machine Learning e intelligenza artificiale
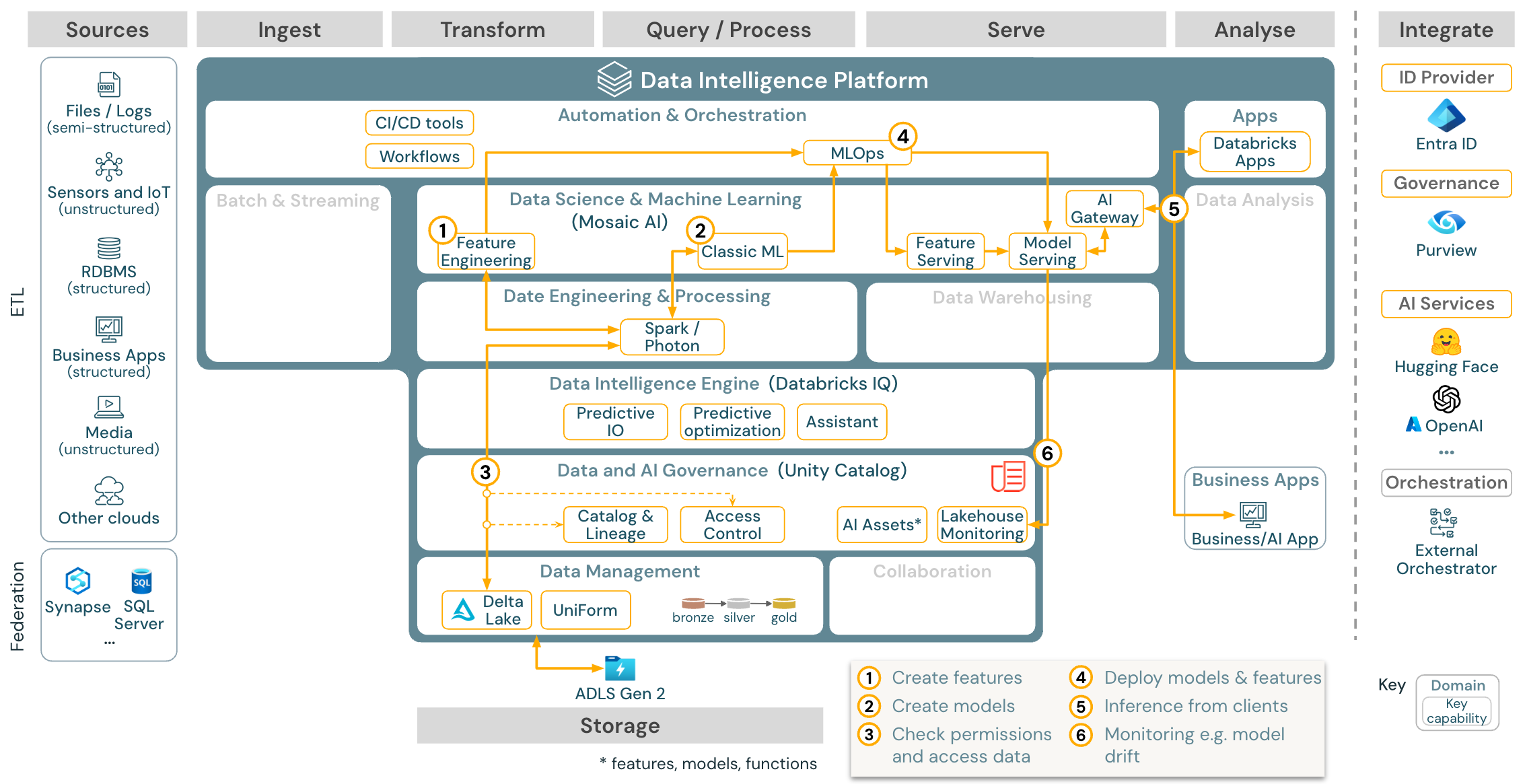
Per l’apprendimento automatico, Databricks Data Intelligence Platform offre l'intelligenza artificiale mosaica, fornita con librerie di machine e deep learning all’avanguardia. Offre funzionalità come Feature Store e registro modelli (integrati nel catalogo unity), funzionalità a basso codice con AutoML e integrazione di MLflow nel ciclo di vita dell’analisi scientifica dei dati.
Tutti gli asset correlati all'analisi scientifica dei dati (tabelle, funzionalità e modelli) sono regolati da Unity Catalog e i data scientist possono usare i processi di Databricks per orchestrare i processi.
Per la distribuzione di modelli in modo scalabile e di livello aziendale, usare le funzionalità MLOps per pubblicare i modelli nella gestione dei modelli.
Caso d’utilizzo: Generazione aumentata di recupero (intelligenza artificiale di generazione)
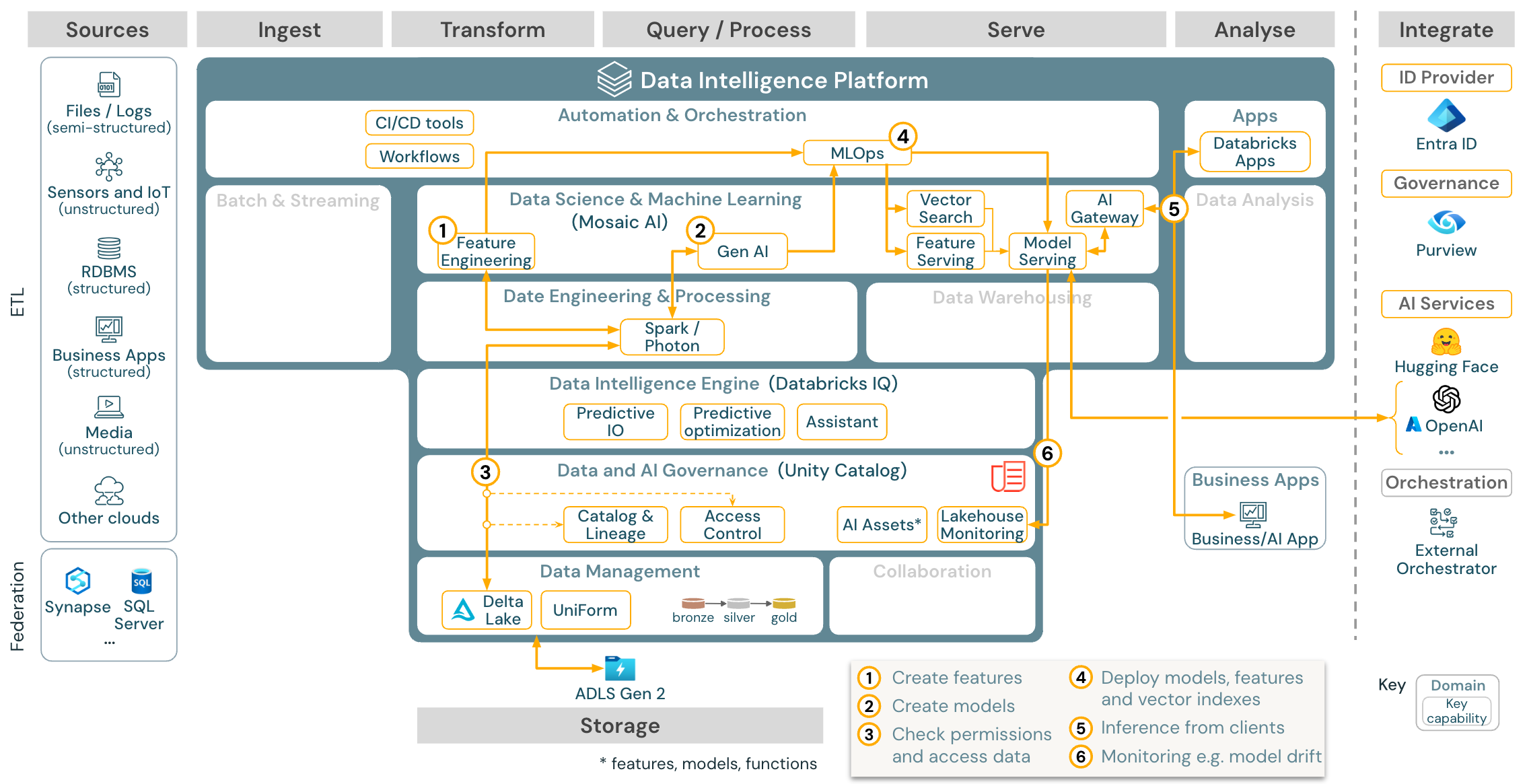
Per i casi d’uso generativi dell’intelligenza artificiale, Mosaic AI include librerie all’avanguardia e funzionalità di intelligenza artificiale di generazione specifiche, dalla progettazione dei prompt all’ottimizzazione dei modelli esistenti e dalla pre-training da zero. L’architettura precedente mostra un esempio di come la ricerca vettoriale può essere integrata per creare un’applicazione di intelligenza artificiale rag (generazione aumentata di recupero).
Per la distribuzione di modelli in modo scalabile e di livello aziendale, usare le funzionalità MLOps per pubblicare i modelli nella gestione dei modelli.
Caso d’utilizzo: Analisi BI e SQL
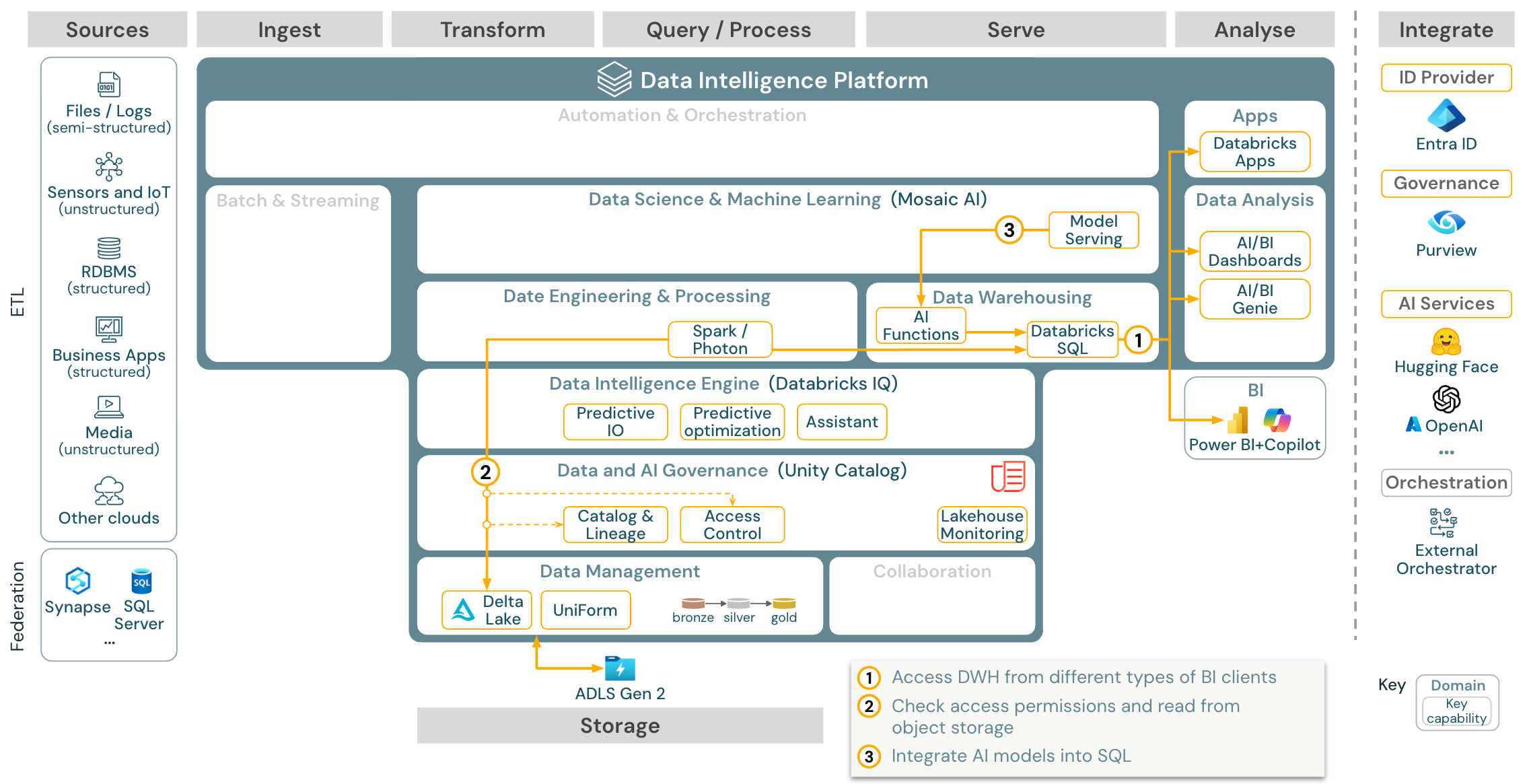
Download: Architettura di riferimento di analisi BI e SQL per Azure Databricks
Per i casi d’utilizzo di BUSINESS INTELLIGENCE, gli analisti aziendali possono usare dashboard, l’editor SQL di Databricks o strumenti bi specifici, ad esempio Tableau o Power BI. In tutti i casi, il motore è Databricks SQL (serverless o non serverless) e l’individuazione dei dati, l’esplorazione e il controllo di accesso vengono forniti da Unity Catalog.
Caso d’utilizzo: federazione lakehouse
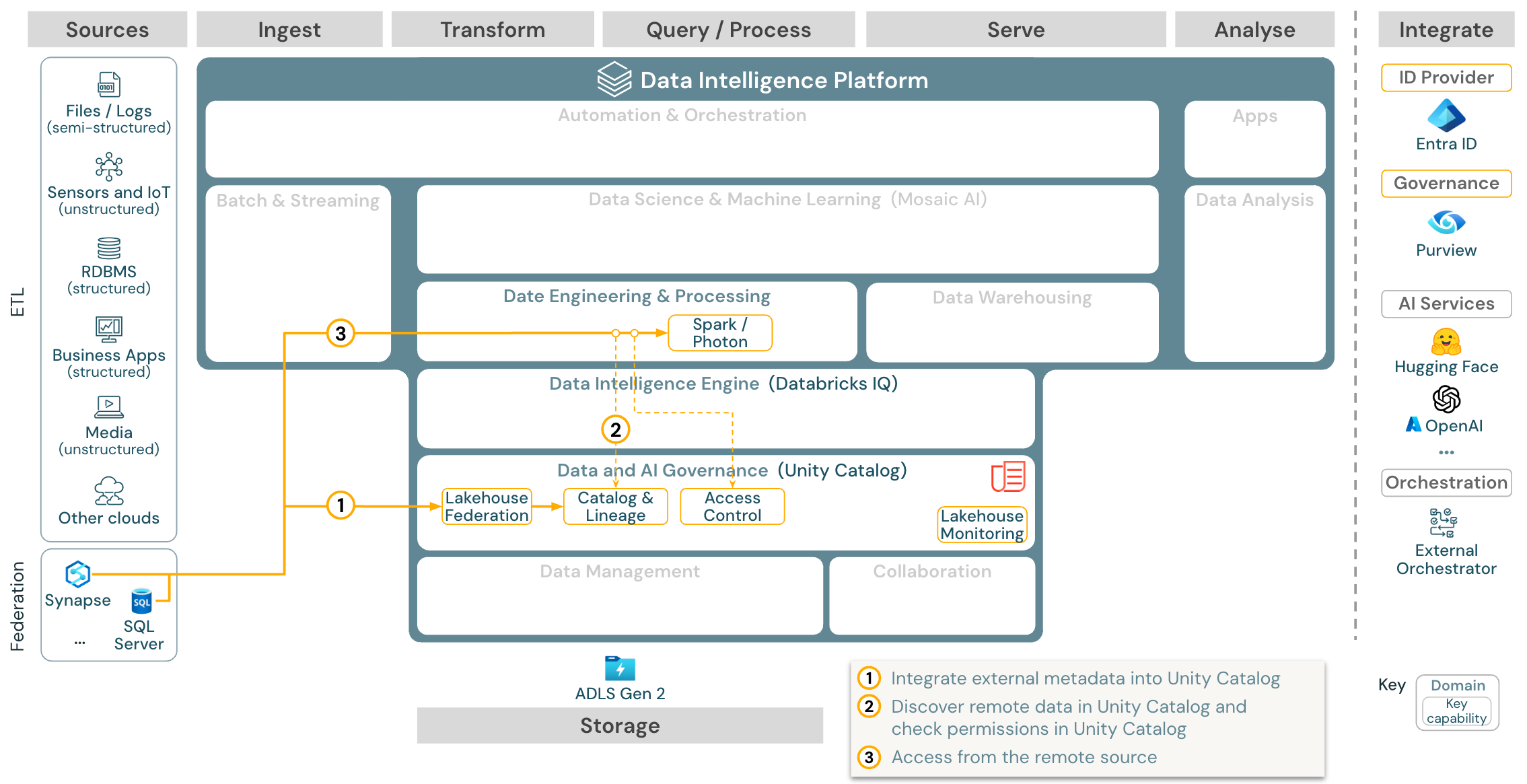
Download: Architettura di riferimento della federazione Lakehouse per Azure Databricks
La federazione di Lakehouse consente l’integrazione di database SQL di dati esterni( ad esempio MySQL, Postgres, SQL Server o Azure Synapse) con Databricks.
Tutti i carichi di lavoro (IA, DWH e BI) possono trarre vantaggio da questo senza dover prima ETL i dati nell’archiviazione oggetti. Il catalogo di origine esterno viene mappato nel catalogo Unity e il controllo di accesso con granularità fine può essere applicato all’accesso tramite la piattaforma Databricks.
Caso d’utilizzo: condivisione dei dati aziendali
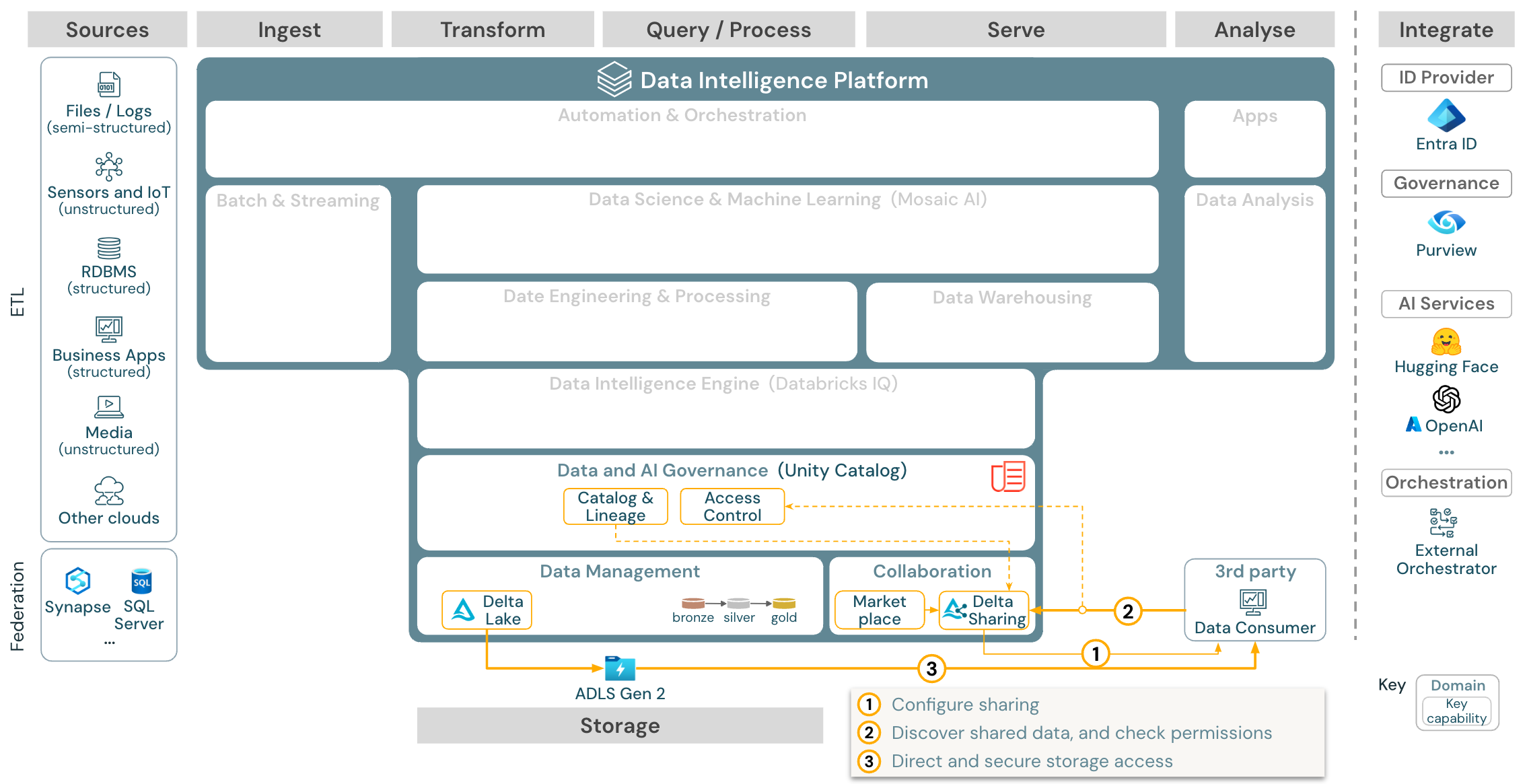
Download: Architettura di riferimento per la condivisione dei dati aziendali per Azure Databricks
La condivisione dei dati di livello aziendale viene fornita dalla condivisione Delta. Fornisce accesso diretto ai dati nell'archivio oggetti protetto da Unity Catalog e Databricks Marketplace è un forum aperto per lo scambio di prodotti dati.