Scopo della piattaforma lakehouse
Un framework moderno per i dati e la piattaforma di intelligenza artificiale
Per illustrare lo scopo della piattaforma di business intelligence per i dati di Databricks, è utile innanzitutto definire un framework di base per la piattaforma moderna per i dati e l’intelligenza artificiale:
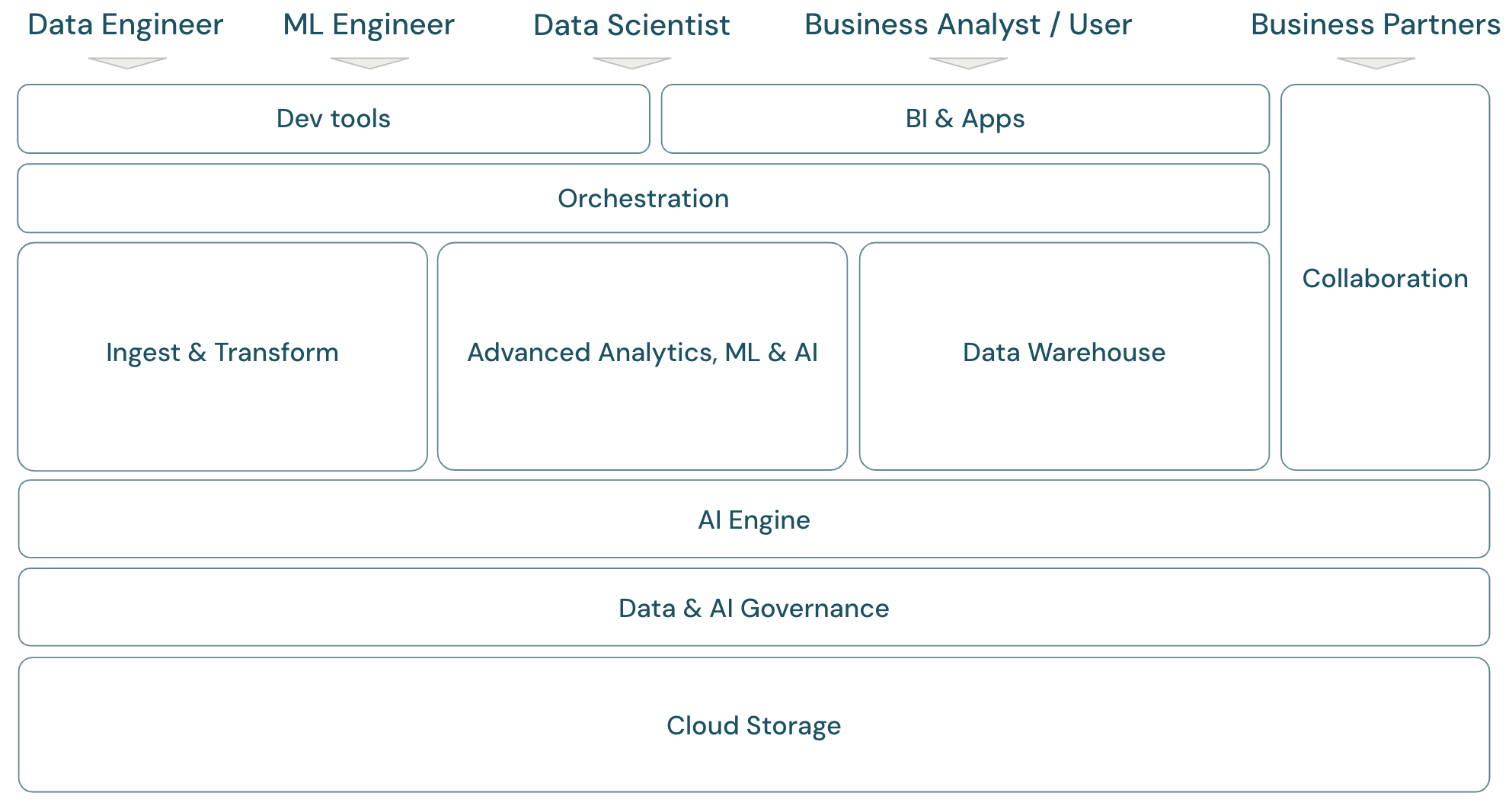
Panoramica dell’ambito lakehouse
Databricks Data Intelligence Platform copre il framework completo della piattaforma dati moderna. Si basa sull’architettura lakehouse e basata su un motore di data intelligence che comprende le qualità uniche dei dati. Si tratta di una base aperta e unificata per carichi di lavoro ETL, ML/AI e DWH/BI e ha Unity Catalog come soluzione di governance centralizzata per i dati e l'intelligenza artificiale.
Utenti del framework della piattaforma
Il framework illustra i membri primari del team di dati (persona) che lavorano con le applicazioni nel framework:
- I data engineer forniscono a data scientist e business analyst dati accurati e riproducibili per informazioni tempestive sul processo decisionale e in tempo reale. Implementano processi ETL altamente coerenti e affidabili per aumentare la fiducia e la fiducia degli utenti nei dati. Assicurano che i dati siano ben integrati con i vari pilastri dell’azienda e in genere seguano le procedure consigliate per la progettazione del software.
- I data scientist combinano competenze analitiche e comprensione aziendale per trasformare i dati in dati analitici strategici e modelli predittivi. Si tratta di una soluzione efficace per tradurre le sfide aziendali in soluzioni basate sui dati, sia che attraverso informazioni analitiche retrospettive o modellazione predittiva di tipo forward-looking. Sfruttando la modellazione dei dati e le tecniche di Machine Learning, progettano, sviluppano e distribuiscono modelli che svelano modelli, tendenze e previsioni dai dati. Agiscono come ponte, convertendo narrazioni di dati complesse in storie comprensibili, assicurando che gli stakeholder aziendali non solo comprendano, ma possano anche agire sulle raccomandazioni basate sui dati, a sua volta guidando un approccio incentrato sui dati alla risoluzione dei problemi all'interno di un'’organizzazione.
- I tecnici ml (ingegneri di Machine Learning) guidano l’applicazione pratica di data science in prodotti e soluzioni creando, distribuendo e mantenendo modelli di Machine Learning. Il loro obiettivo principale è quello di orientarsi verso l’aspetto tecnico dello sviluppo e della distribuzione dei modelli. I tecnici ML garantiscono solidità, affidabilità e scalabilità dei sistemi di Machine Learning in ambienti live, risolvendo le sfide correlate alla qualità dei dati, all’infrastruttura e alle prestazioni. Integrando i modelli di intelligenza artificiale e Machine Learning nei processi aziendali operativi e nei prodotti rivolti agli utenti, facilitano l’uso dei data science nella risoluzione delle sfide aziendali, garantendo che i modelli non rimangano solo nella ricerca, ma favoriscano un valore aziendale tangibile.
- analisti aziendali e gli utenti aziendali: gli analisti aziendali forniscono agli stakeholder e ai team aziendali dati utilizzabili. Spesso interpretano i dati e creano report o altre documentazioni per la gestione usando gli strumenti di business intelligence standard. In genere sono il primo punto di contatto per gli utenti aziendali non tecnici e i colleghi operativi per domande di analisi rapida. I dashboard e le applicazioni aziendali distribuite sulla piattaforma Databricks possono essere utilizzati direttamente dagli utenti aziendali.
- I partner commerciali sono stakeholder importanti in un mondo aziendale sempre più in rete. Sono definiti come società o individui con cui un’azienda ha una relazione formale per raggiungere un obiettivo comune e può includere venditori, fornitori, distributori e altri partner di terze parti. La condivisione dei dati è un aspetto importante delle partnership commerciali, in quanto consente il trasferimento e lo scambio di dati per migliorare la collaborazione e il processo decisionale basato sui dati.
Domini del framework della piattaforma
La piattaforma è costituita da più domini:
Archiviazione: Nel cloud i dati vengono archiviati principalmente in archiviazione oggetti scalabili, efficienti e resilienti nel cloud providers.
Governance: funzionalità relative alla governance dei dati, ad esempio il controllo di accesso, il controllo, la gestione dei metadati, il rilevamento della derivazione e il monitoraggio per tutti i dati e gli asset di intelligenza artificiale.
Motore di intelligenza artificiale: il motore di intelligenza artificiale offre le funzionalità di intelligenza artificiale generative per l’intera piattaforma.
Inserimento e trasformazione: funzionalità per i carichi di lavoro ETL.
Analisi avanzata, Machine Learning e intelligenza artificiale: tutte le funzionalità relative all’apprendimento automatico, all’intelligenza artificiale, all’intelligenza artificiale generativa e anche all’analisi di streaming.
Data warehouse: dominio che supporta i casi d’uso di DWH e BI.
Automazione: gestione del flusso di lavoro per l'elaborazione dei dati, l'apprendimento automatico, le pipeline di analisi, tra cui il supporto CI/CD e MLOps.
Strumenti ETL & DS: gli strumenti front-end usati principalmente dai data engineer, dai data scientist e dai tecnici ml per il lavoro.
Strumenti di business intelligence: gli strumenti front-end usati principalmente dagli analisti bi per il lavoro.
Collaborazione: funzionalità per la condivisione dei dati tra due o più parti.
Scopo della piattaforma Databricks
Databricks Data Intelligence Platform e i relativi componenti possono essere mappati al framework nel modo seguente:
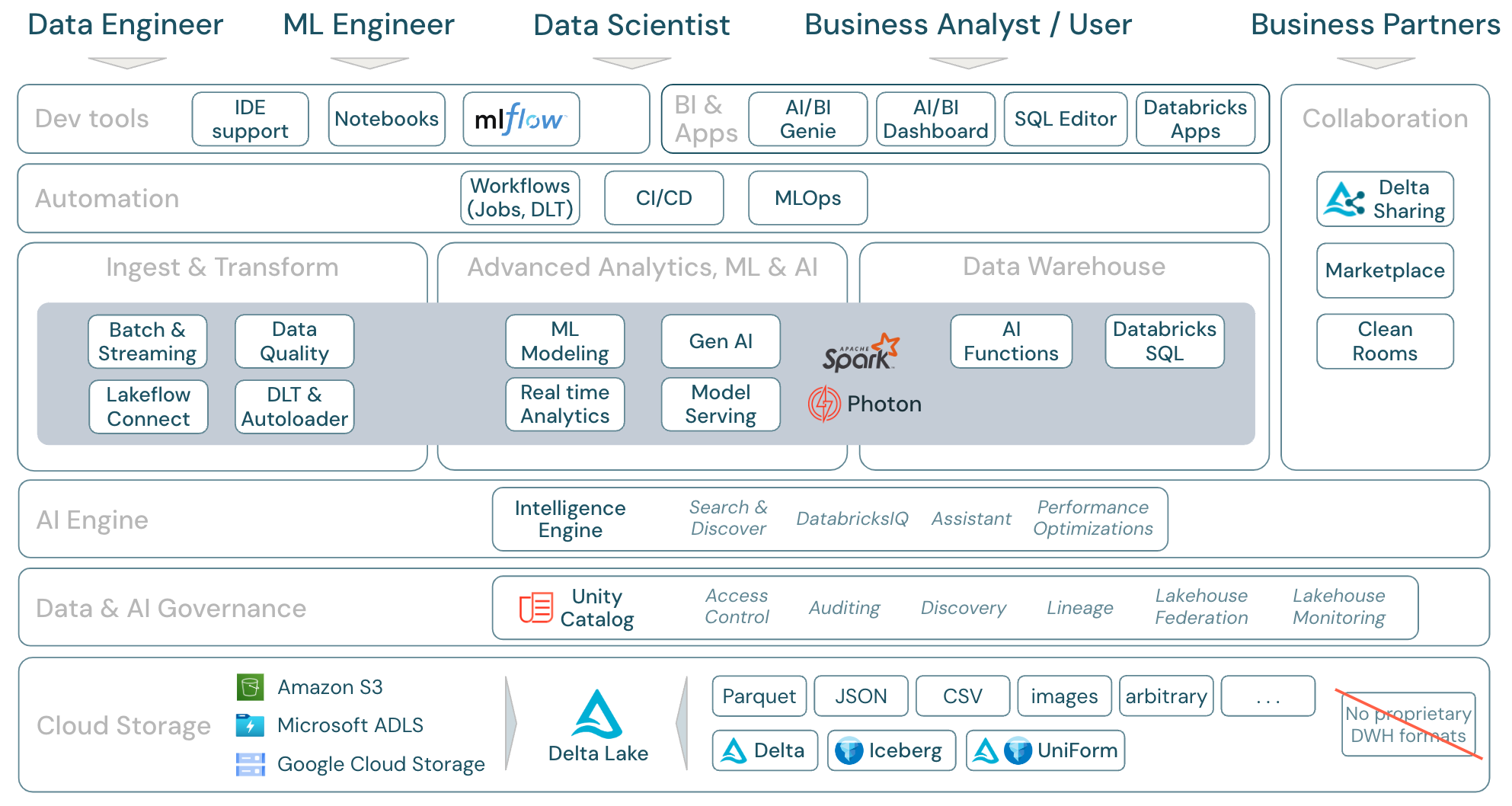
Download: Ambito di lakehouse - componenti di Databricks
Carichi di lavoro di dati in Azure Databricks
Soprattutto, Databricks Data Intelligence Platform copre tutti i carichi di lavoro pertinenti per il dominio dati in una sola piattaforma, con Apache Spark/Photon come motore:
Inserimento e trasformazione
Databricks offre diversi modi di inserimento dati:
- Databricks LakeFlow Connect offre connettori predefiniti per l'inserimento da applicazioni e database aziendali. La pipeline di inserimento risultante è gestita da Unity Catalog ed è alimentata da calcolo serverless e Delta Live Tables.
- Caricatore automatico elabora in modo incrementale ed automaticamente i file che arrivano nello storage cloud in lavori pianificati o continui, senza dover gestire le informazioni di stato. Una volta inseriti, i dati non elaborati devono essere trasformati in modo che siano pronti per BI e ML/I. Databricks offre potenti funzionalità ETL per data engineer, data scientist e analisti.
Delta Live Tables (DLT) consente di scrivere processi ETL in modo dichiarativo, semplificando l'intero processo di implementazione. La qualità dei dati può essere migliorata definendo le aspettative dei dati.
Analisi avanzata, Machine Learning e intelligenza artificiale
La piattaforma include Databricks Mosaic AI, una set di strumenti di machine learning e intelligenza artificiale completamente integrati per machine learning e deep learning classico, nonché modelli generativi di intelligenza artificiale e modelli di linguaggio di grandi dimensioni. Illustra l’intero flusso di lavoro, dalla preparazione dei dati alla creazione di modelli di Machine Learning e Deep Learning, a Mosaic AI Model Serving.
Spark Structured Streaming e DLT consentono l’analisi in tempo reale.
Data warehouse
Databricks Data Intelligence Platform offre anche una soluzione di data warehouse completa con Databricks SQL, governata centralmente da Unity Catalog con controllo di accesso con granularità fine.
funzioni di intelligenza artificiale sono funzioni SQL predefinite che consentono di applicare l'intelligenza artificiale ai dati direttamente da SQL. L'integrazione dell'IA nei flussi di lavoro di analisi fornisce l'accesso alle informazioni precedentemente inaccessibili agli analisti e consente loro di prendere decisioni più informate, gestire i rischi e sostenere un vantaggio competitivo grazie all'innovazione e all'efficienza basata sui dati.
Struttura delle aree delle funzionalità di Azure Databricks
Si tratta di un mapping delle funzionalità di Databricks Data Intelligence Platform agli altri livelli del framework, dal basso verso l’alto:
Archiviazione nel cloud
Tutti i dati per il lakehouse vengono archiviati nell’archivio oggetti del provider di servizi cloud. Databricks supporta tre providerscloud: AWS, Azure e GCP. I file in vari formati strutturati e semistrutturati (ad esempio Parquet, CSV, JSON e Avro), nonché i formati non strutturati (ad esempio immagini e documenti), vengono inseriti e trasformati usando processi batch o di streaming.
Delta Lake è il formato di dati consigliato per il lakehouse (transazioni di file, affidabilità, coerenza, aggiornamenti e così via) ed è completamente open source per evitare il blocco. E Delta Universal Format (UniForm) consente di leggere Delta tables con i Client Iceberg.
Non vengono usati formati di dati proprietari nella piattaforma data intelligence di Databricks.
Gestione dei dati e dell'intelligenza artificiale
Oltre al livello di archiviazione, Unity Catalog offre un'ampia gamma di funzionalità di governance dei dati e intelligenza artificiale, tra cui di gestione dei metadati nel metastore, controllo di accesso, controllo, l'individuazione dei datie derivazione dei dati.
Il monitoraggio di Lakehouse offre metriche di qualità predefinite per gli asset di dati e intelligenza artificiale e dashboard generati automaticamente per visualizzare queste metriche.
Le origini SQL esterne possono essere integrate nella Catalog lakehouse e Unity tramite federazione lakehouse.
Motore di intelligenza artificiale
La piattaforma di data intelligence si basa sull’architettura lakehouse e migliorata dal motore di data intelligence DatabricksIQ. DatabricksIQ combina l’intelligenza artificiale generativa con i vantaggi di unificazione dell’architettura lakehouse per comprendere la semantica univoca dei dati. Ricerca intelligente e Assistente Databricks sono esempi di servizi basati sull’intelligenza artificiale che semplificano l’uso della piattaforma per ogni utente.
Orchestrazione
I processi di Databricks consentono di eseguire carichi di lavoro diversi per il ciclo di vita completo dei dati e dell’intelligenza artificiale in qualsiasi cloud. Consentono di orchestrare i processi, come Delta Live Tables per SQL, Spark, notebook, DBT, modelli di ML e altro ancora.
La piattaforma supporta anche CI/CD e MLOps
Strumenti ETL & DS
A livello di consumo, i data engineer e i tecnici ml lavorano in genere con la piattaforma usando gli IDE. I data scientist preferiscono spesso notebook e usano i runtime ML e IA e il sistema del flusso di lavoro di Machine Learning MLflow per tenere traccia degli esperimenti e gestire il ciclo di vita del modello.
Strumenti di Business Intelligence
Gli analisti aziendali usano in genere lo strumento di business intelligence preferito per accedere al data warehouse di Databricks. Databricks SQL può essere sottoposto a query tramite diversi strumenti di analisi e bi, vedere BI e visualizzazione
Inoltre, la piattaforma offre strumenti di query e analisi predefiniti:
- dashboard di intelligenza artificiale/BI per trascinare le visualizzazioni dei dati e condividere informazioni dettagliate.
- Gli esperti di dominio, ad esempio gli analisti dei dati, configurano spazi di intelligenza artificiale/BI Genie con set di dati, query di esempio e linee guida di testo per aiutare Genie a tradurre le domande aziendali in query analitiche. Dopo set, gli utenti aziendali possono porre domande e utilizzare generate per visualizzare e comprendere i dati operativi.
- Databricks Apps consente agli sviluppatori di creare applicazioni di dati e intelligenza artificiale sicure nella piattaforma Databricks e di condividerle con gli utenti.
- Editor SQL per gli analisti SQL per analizzare i dati.
Collaborazione
Delta Sharing è un protocollo aperto sviluppato da Azure Databricks per la condivisione sicura dei dati con altre organizzazioni, indipendentemente dalle piattaforme di elaborazione usate.
Databricks Marketplace è un forum aperto per lo scambio di prodotti dati. Sfrutta Delta Sharing per offrire ai dati providers gli strumenti per condividere i prodotti dati in modo sicuro e dà ai consumatori di dati il potere di esplorare ed espandere il loro accesso ai dati e ai servizi dati di cui hanno bisogno.
Clean Rooms usa la condivisione Delta e l'elaborazione serverless per fornire un ambiente sicuro che protegga la privacy where più parti possono collaborare sui dati aziendali sensibili senza l'accesso diretto ai dati degli altri.