Febbraio 2020
Queste funzionalità e i miglioramenti della piattaforma Azure Databricks sono stati rilasciati a febbraio 2020.
Nota
Le versioni vengono gestite in staging. L'account Azure Databricks potrebbe non essere aggiornato fino a una settimana dopo la data di rilascio iniziale.
Databricks Runtime 6.4 per Genomica disponibile a livello generale
26 febbraio 2020
Databricks Runtime 6.4 per Genomica è basato su Databricks Runtime 6.4. Include numerosi miglioramenti e aggiornamenti da Databricks Runtime 6.3 per Genomica.
Le funzionalità principali sono:
- È ora possibile personalizzare gli utenti della pipeline DNASeq possono disabilitare in modo selettivo qualsiasi combinazione legittima delle fasi di allineamento di lettura, chiamata variante e annotazione variante. Gli utenti possono anche eseguire l'allineamento in lettura a fine singola.
- La versione di Glow inclusa in Databricks Runtime 6.4 per Genomica offre ora API Python e Scala per le funzioni esposte in precedenza solo tramite espressioni SQL. Queste funzioni sono disponibili per le operazioni dataframe, offrendo una maggiore sicurezza in fase di compilazione.
Databricks Runtime 6.4 ML disponibile a livello generale
26 febbraio 2020
Databricks Runtime 6.4 ML offre aggiornamenti della libreria, tra cui:
- PyTorch: da 1.3.1 a 1.4.0
- Horovod: da 0.18.2 a 1.19.0
Per informazioni dettagliate, vedere le note sulla versione completa di Databricks Runtime 6.4 per ML (EoS).
Databricks Runtime 6.4 disponibile a livello generale
26 febbraio 2020
Databricks Runtime 6.4 GA offre nuove funzionalità, miglioramenti e molte correzioni di bug.
- Elaborare i nuovi file di dati in modo incrementale con il caricatore automatico (anteprima pubblica). Il caricatore automatico offre un modo più efficiente per elaborare i nuovi file di dati in modo incrementale man mano che arrivano in un archivio BLOB cloud durante LTL. Si tratta di un miglioramento rispetto allo streaming strutturato basato su file, che identifica i nuovi file elencando ripetutamente la directory cloud e monitorando i file visualizzati e può essere molto inefficiente man mano che la directory cresce.
- Caricare i dati in Delta Lake con tentativi idempotenti (anteprima pubblica). Il
COPY INTOcomando SQL consente di caricare i dati in Delta Lake con tentativi idempotenti (anteprima pubblica). Per caricare i dati in Delta Lake, è necessario usare le API dataframe di Apache Spark. Se si verificano errori durante i carichi, è necessario gestirli in modo efficace. - Metriche delle operazioni per tutte le scritture, aggiornamenti ed eliminazioni su un Delta table ora mostrate nella cronologia table.
- Le figure matplotlib inline ora abilitate per impostazione predefinita nei notebook di Azure Databricks (anteprima pubblica).
Per informazioni dettagliate, vedere le note sulla versione complete di Databricks Runtime 6.4 (EoS).
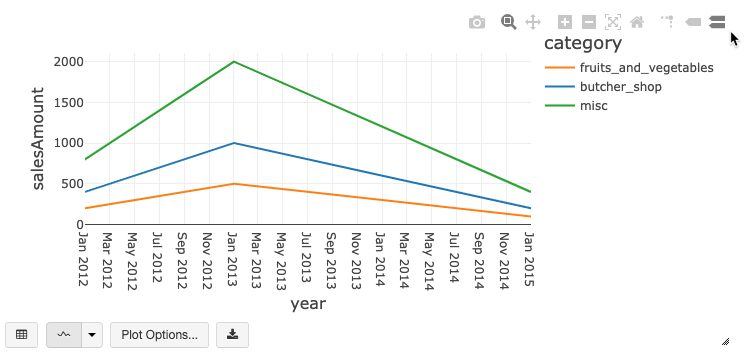
Nuovi grafici interattivi che offrono interazioni avanzate lato client
25 febbraio - 3 marzo 2019: versione 3.14
Questa versione introduce due nuovi tipi di grafico interattivo che sostituiscono le implementazioni del grafico a barre e del grafico a linee. Oltre alle funzionalità del grafico esistenti, il grafico a linee include alcune nuove opzioni di tracciato personalizzato: l'impostazione di un intervallo dell'asse Y, la visualizzazione o la nascondere degli indicatori e l'applicazione della scala del log all'asse Y. Entrambi i grafici dispongono di una barra degli strumenti predefinita che supporta un set avanzato di interazioni lato client.
Se si desidera usare le implementazioni del grafico esistenti, è possibile select le dal menu a discesa Grafici Legacy. I grafici esistenti continueranno a usare le implementazioni disponibili in precedenza.
Nuova rete di inserimento di dati che aggiunge le integrazioni dei partner con Delta Lake (anteprima pubblica)
24 febbraio 2020
A questo punto è possibile popolare facilmente la "lakehouse", il data lake grazie ai tipi di strutture di dati e alle funzionalità di gestione dei dati che in genere si get con un data warehouse, da centinaia di origini dati a Delta Lake. Al centro di questa rete è la nuova raccolta Di integrazioni partner, accessibile dall'area di lavoro e fornisce l'accesso a un'enorme rete di origini dati tramite i partner Fivetran, Qlik, Infoworks, StreamSets e Syncsort.

Per una panoramica, vedere il blog. Per informazioni dettagliate, vedere Partner tecnologici.
Aggiunta automatica dell’autore dell’area di lavoro come amministratore di Azure Databricks
24 febbraio 2020
Prima del 24 febbraio 2020, l'utente che ha creato un'area di lavoro di Azure Databricks verrà aggiunto solo come utente amministratore per l'area di lavoro se ha fatto clic sul pulsante Avvia area di lavoro nel portale di Azure o è stato aggiunto come amministratore da un utente che era già un utente amministratore nell'area di lavoro (qualsiasi Collaboratore di Azure per la sottoscrizione che ha fatto clic sul pulsante Avvia area di lavoro verrebbe creato come utente amministratore nell'area di lavoro). Ora l'utente che crea l'area di lavoro verrà aggiunto automaticamente come amministratore dell'area di lavoro.
Per informazioni dettagliate sulla creazione e l'avvio di aree di lavoro, vedere Gestire la sottoscrizione
Flag per la gestione della sicurezza dell’area di lavoro e delle funzionalità dei notebook ora disponibili
4-11 febbraio 2020: versione 3.12
Questa versione introduce nuovi flag per la gestione delle intestazioni di sicurezza inviate per impedire attacchi all'area di lavoro, nonché l'accesso ai download dei risultati dei notebook e al controllo delle versioni git. Tutte queste opzioni amministrative sono abilitate per impostazione predefinita.