Eseguire query Apache Hive usando gli strumenti Data Lake per Visual Studio
Informazioni su come usare gli strumenti Data Lake per Visual Studio per eseguire query su Apache Hive. Gli strumenti Data Lake consentono di creare, inviare e monitorare facilmente query Hive in Apache Hadoop in Azure HDInsight.
Prerequisiti
Un cluster Apache Hadoop in HDInsight. Per informazioni sulla creazione di questo elemento, vedere Creare cluster Apache Hadoop in Azure HDInsight con un modello di Resource Manager.
Visual Studio. Nella procedura descritta in questo articolo viene usato Visual Studio 2019.
Strumenti HDInsight per Visual Studio o Azure Data Lake Tools per Visual Studio. Per informazioni sull'installazione e la configurazione degli strumenti, vedere Installare Strumenti Data Lake per Visual Studio.
Eseguire query Apache Hive usando Visual Studio
Per la creazione e l'esecuzione di query Hive sono disponibili due opzioni:
- Creare query ad hoc.
- Creare un'applicazione Hive.
Creare una query Hive ad hoc
È possibile eseguire query ad hoc in modalità Batch o Interattivo.
Avviare Visual Studio e selezionare Continua senza codice.
In Esplora server fare clic con il pulsante destro del mouse su Azure, selezionare Connessione alla sottoscrizione di Microsoft Azure... e quindi completare il processo di accesso.
Espandere HDInsight, fare clic con il pulsante destro del mouse sul cluster in cui si vuole eseguire la query, quindi scegliere Scrivi una query Hive.
Immettere la query Hive seguente:
SELECT * FROM hivesampletable;Seleziona Execute. Per impostazione predefinita, la modalità di esecuzione è impostata su Interattivo.
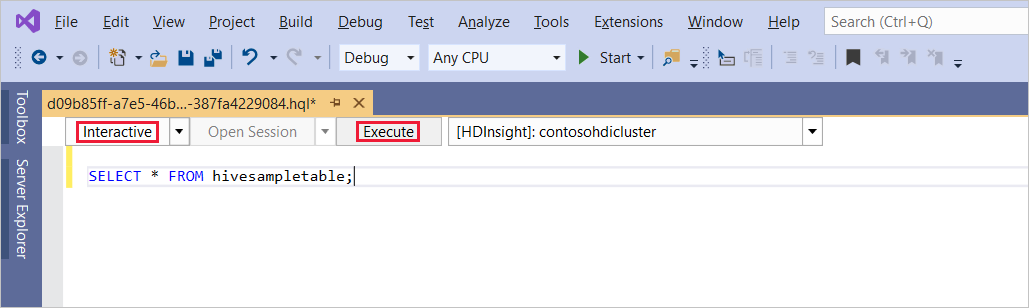
Per eseguire la stessa query in modalità Batch, cambiare l'impostazione dell'elenco a discesa da Interattivo a Batch. Il pulsante di esecuzione passa da Esegui a Invia.

L'editor Hive supporta IntelliSense. Strumenti Data Lake per Visual Studio supporta il caricamento di metadati remoti quando si modifica lo script Hive. Se ad esempio si digita
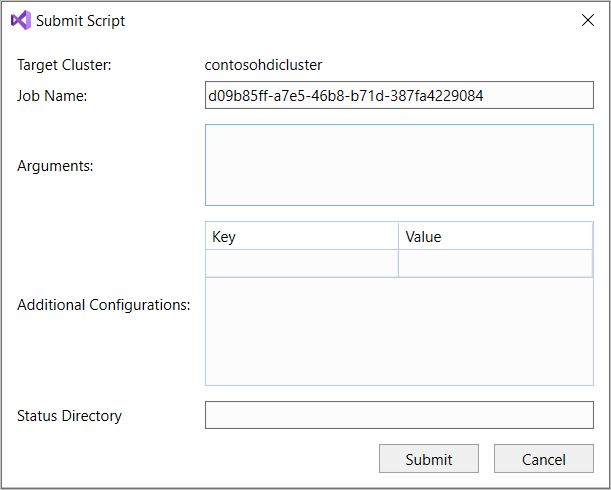
SELECT * FROM, IntelliSense elenca tutti i nomi di tabella suggeriti. Quando si specifica un nome di tabella, IntelliSense elenca i nomi delle colonne. Gli strumenti supportano la maggior parte delle funzioni definite dall'utente predefinite, delle sottoquery e delle istruzioni DML Hive. IntelliSense suggerisce solo i metadati del cluster selezionato nella barra degli strumenti HDInsight.Nella barra degli strumenti della query (l'area sotto la scheda della query e sopra il testo della query), selezionare Invia oppure selezionare la freccia a discesa accanto a Invia e scegliere Avanzate dall'elenco a discesa. Se si seleziona quest'ultima opzione,
Se è stata selezionata l'opzione di invio avanzato, configurare le impostazioni per Nome processo, Argomenti, Configurazioni aggiuntive e Directory di stato nella finestra di dialogo Invia script. Selezionare quindi Invia.
Creare un'applicazione Hive
Per eseguire una query Hive creando un'applicazione Hive, seguire questa procedura:
Aprire Visual Studio.
Nella finestra iniziale selezionare Crea un nuovo progetto.
Nella finestra Crea un nuovo progetto immettere Hive nella casella Cerca modelli. Scegliere quindi Applicazione Hive e selezionare Avanti.
Nella finestra Configura il nuovo progetto immettere un Nome progetto, selezionare o creare una Posizione per il nuovo progetto e quindi selezionare Crea.
Aprire il file Script.hql creato con il progetto e incollarvi le seguenti istruzioni HiveQL:
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4j Logs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;Queste istruzioni eseguono le azioni seguenti:
DROP TABLE: elimina la tabella, se presente.CREATE EXTERNAL TABLE: crea una nuova tabella "esterna" in Hive. Le tabelle esterne archiviano solo la definizione della tabella in Hive. I dati rimangono nella posizione originale.Nota
Le tabelle esterne devono essere usate quando si prevede che i dati sottostanti vengano aggiornati da un'origine esterna, ad esempio un processo MapReduce o un servizio di Azure.
L'eliminazione di una tabella esterna non comporta anche l'eliminazione dei dati. Viene eliminata solo la definizione della tabella.
ROW FORMAT: indica a Hive il modo in cui sono formattati i dati. In questo caso, i campi in ogni log sono separati da uno spazio.STORED AS TEXTFILE LOCATION: indica a Hive che i dati vengono archiviati nella directory example/data e che vengono archiviati come testo.SELECT: seleziona un numero di tutte le righe in cui la colonnat4include il valore[ERROR]. Questa istruzione restituisce un valore pari a3, poiché sono presenti tre righe contenenti questo valore.INPUT__FILE__NAME LIKE '%.log': indica a Hive di restituire solo i dati dei file che terminano con .log. Questa clausola limita la ricerca al file sample.log che contiene i dati.
Dalla barra degli strumenti del file di query (con un aspetto simile alla barra degli strumenti della query ad hoc), selezionare il cluster HDInsight che si vuole usare per questa query. Modificare quindi Interattivo in Batch (se necessario) e selezionare Invia per eseguire le istruzioni come processo Hive.
Verrà visualizzata una finestra di riepilogo del processo Hive con informazioni relative al processo in esecuzione. Usare il collegamento Aggiorna per aggiornare le informazioni del processo finché il campo Stato processo non viene impostato su Completato.
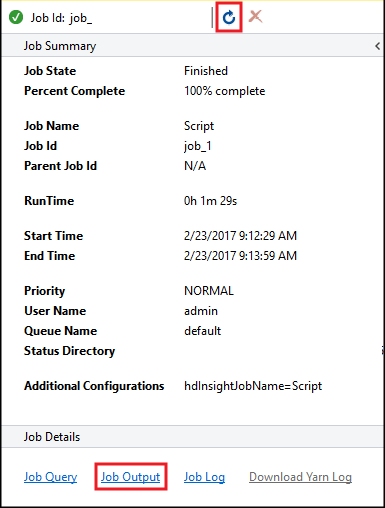
Selezionare Output del processo per visualizzare l'output di questo processo. Mostra
[ERROR] 3, ovvero il valore restituito dalla query.
Esempio aggiuntivo
L'esempio seguente si basa sulla tabella log4jLogs creata nella procedura precedente Creare un'applicazione Hive.
In Esplora server fare clic con il pulsante destro del mouse sul cluster e scegliere Scrivi una query Hive.
Immettere la query Hive seguente:
set hive.execution.engine=tez; CREATE TABLE IF NOT EXISTS errorLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log';Queste istruzioni eseguono le azioni seguenti:
CREATE TABLE IF NOT EXISTS: crea una tabella, se non esiste già. Poiché non viene usatala parola chiaveEXTERNAL, questa istruzione crea una tabella interna. Le tabelle interne vengono archiviate nel data warehouse di Hive e sono gestite da Hive.Nota
A differenza delle tabelle
EXTERNAL, se si elimina una tabella interna, vengono eliminati anche i dati sottostanti.STORED AS ORC: archivia i dati nel formato ORC, Optimized Row Columnar. ORC è un formato altamente ottimizzato ed efficiente per l'archiviazione di dati Hive.INSERT OVERWRITE ... SELECT: seleziona le righe della tabellalog4jLogscontenenti[ERROR], quindi inserisce i dati nella tabellaerrorLogs.
Modificare Interattivo in Batch, se necessario, quindi selezionare Invia.
Per verificare che il processo abbia creato la tabella, passare a Esplora server ed espandere Azure>HDInsight. Espandere il cluster HDInsight e quindi espandere Database Hive>predefinito. Vengono elencate la tabella errorLogs e la tabella Log4jLogs.
Passaggi successivi
Come si può notare, gli strumenti HDInsight per Visual Studio forniscono un modo semplice per lavorare con le query Hive in HDInsight.
Per informazioni generali su Hive in HDInsight, vedere Cosa sono Apache Hive e HiveQL in Azure HDInsight
Per informazioni su altri modi in cui è possibile usare Hadoop in HDInsight, vedere Usare MapReduce in Apache Hadoop in HDInsight
Per altre informazioni sugli Strumenti di HDInsight per Visual Studio, vedere Usare Strumenti Data Lake per Visual Studio per connettersi ad Azure HDInsight ed eseguire query Apache Hive