Usare Strumenti Data Lake per Visual Studio per connettersi ad Azure HDInsight ed eseguire query Apache Hive
Informazioni su come usare Microsoft Azure Data Lake e strumenti di analisi di flusso per Visual Studio (Strumenti Data Lake). Usare lo strumento per connettersi ai cluster Apache Hadoop in Azure HDInsight e inviare query Hive.
Per altre informazioni sull'uso di HDInsight, vedere Introduzione a HDInsight.
È possibile usare Strumenti Data Lake per Visual Studio per accedere ad Azure Data Lake Analytics e a HDInsight. Per informazioni su Strumenti Data Lake, vedere Sviluppare script U-SQL tramite Strumenti Data Lake per Visual Studio.
Prerequisiti
Per completare questo articolo e usare Strumenti Data Lake per Visual Studio, sono necessari gli elementi seguenti:
Un cluster HDInsight di Azure. Per creare un cluster Azure HDInsight, vedere Iniziare a usare Apache Hadoop in Azure HDInsight. Per eseguire query Apache Hive interattive, è necessario un cluster Interactive Query in HDInsight.
Visual Studio. Visual Studio Community Edition è gratuito. Le istruzioni illustrate di seguito sono disponibili per Visual Studio 2019.
Installare Data Lake Tools per Visual Studio
Seguire le istruzioni appropriate per installare Data Lake Tools per la versione di Visual Studio:
Per Visual Studio 2017 o Visual Studio 2019:
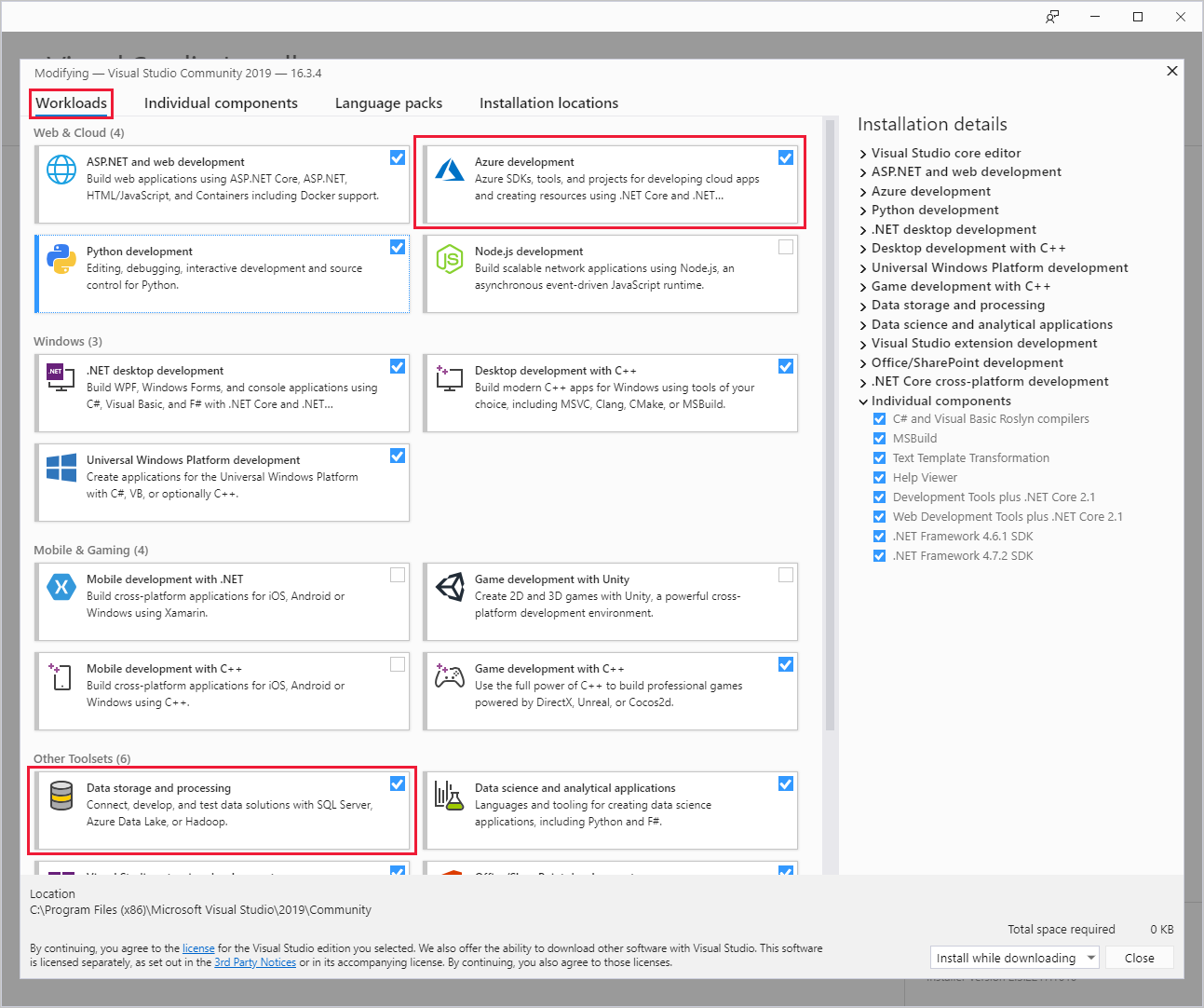
Durante l'installazione di Visual Studio, assicurarsi di includere il carico di lavoro Sviluppo di Azure o l'archiviazione e l'elaborazione dei dati.
Per le installazioni esistenti di Visual Studio, passare alla barra dei menu dell'IDE e selezionare Strumenti Recupera strumenti>e funzionalità per aprire Programma di installazione di Visual Studio. Nella scheda Carichi di lavoro selezionare almeno il carico di lavoro Sviluppo di Azure (in Web e cloud). In alternativa, selezionare il carico di lavoro Archiviazione ed elaborazione dei dati (in Altri set di strumenti).
Per Visual Studio 2015:
Scaricare Strumenti Data Lake. Scegliere la versione di Strumenti Data Lake che corrisponde alla versione di Visual Studio in uso.
Aggiornare Strumenti Data Lake per Visual Studio
Assicurarsi quindi di aggiornare Data Lake Tools alla versione più recente.
Aprire Visual Studio.
Nella finestra Start selezionare Continua senza codice.
Nella barra dei menu dell'IDE di Visual Studio scegliere Estensioni Gestisci estensioni>.
Nella finestra di dialogo Gestisci estensioni espandere il nodo Aggiornamenti.
Se l'elenco degli aggiornamenti disponibili include Azure Data Lake e Strumenti di analisi di flusso, selezionarlo. Selezionare quindi il pulsante Aggiorna . Quando viene visualizzata la finestra di dialogo Scarica e installa , Visual Studio aggiunge l'estensione Azure Data Lake e Stream Analytics Tools alla pianificazione degli aggiornamenti.
Chiudere tutte le finestre di Visual Studio. Verrà visualizzata la finestra di dialogo Programma di installazione VSIX.
Selezionare Licenza per leggere le condizioni di licenza, quindi selezionare Chiudi per tornare alla finestra di dialogo Programma di installazione VSIX.
Selezionare Modifica. Viene avviata l'installazione dell'aggiornamento dell'estensione. Dopo un po' di tempo, la finestra di dialogo cambia per indicare che è stata apportata una modifica. Selezionare Chiudi e quindi riavviare Visual Studio per completare l'installazione.
Nota
È possibile usare solo Strumenti Data Lake versione 2.3.0.0 o successiva per connettersi ai cluster Interactive Query ed eseguire query Hive interattive.
Connettersi alle sottoscrizioni di Azure
È possibile usare Strumenti Data Lake per Visual Studio per connettersi ai cluster HDInsight, eseguire alcune operazioni di gestione di base ed eseguire query Hive.
Nota
Per informazioni sulla connessione a un cluster Hadoop generico, vedere Come scrivere e inviare query Hive con Visual Studio.
Connettersi a una sottoscrizione di Azure
Per connettersi alla sottoscrizione di Azure:
Aprire Visual Studio.
Nella finestra Start selezionare Continua senza codice.
Nella barra dei menu dell'IDE scegliere Visualizza>Esplora server.
In Esplora server fare clic con il pulsante destro del mouse su Azure, scegliere Connetti alla sottoscrizione di Microsoft Azure e completare il processo di autenticazione. In Esplora server espandere Azure>HDInsight per visualizzare un elenco di cluster HDInsight esistenti.
Se non sono presenti cluster, crearne uno usando il portale di Azure, Azure PowerShell o HDInsight SDK. Per altre informazioni, vedere Configurare cluster in HDInsight.
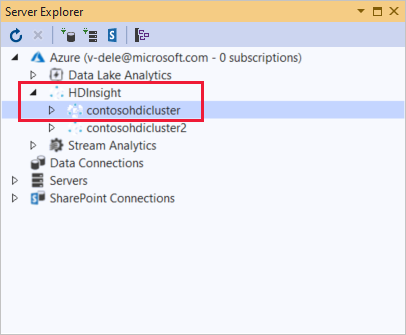
Espandere un cluster HDInsight. Il cluster contiene nodi per i database Hive. Inoltre, un account di archiviazione predefinito, tutti gli account di archiviazione collegati aggiuntivi e il log del servizio Hadoop. È possibile espandere ulteriormente le entità.
Dopo la connessione alla sottoscrizione di Azure, è possibile eseguire le attività seguenti.
Connettersi ad Azure da Visual Studio
Per connettersi al portale di Azure da Visual Studio:
In Esplora server espandere Azure>HDInsight e selezionare il cluster.
Fare clic con il pulsante destro del mouse su un cluster HDInsight e scegliere Gestisci cluster in portale di Azure.
Domande e commenti e suggerimenti offerti da Visual Studio
Per porre domande e inviare commenti e suggerimenti da Visual Studio:
In Esplora server scegliere Azure>HDInsight.
Fare clic con il pulsante destro del mouse su HDInsight e scegliere MSDN Forum per porre domande o Inviare commenti e suggerimenti per inviare commenti e suggerimenti.
Collegamento o modifica di un cluster
Nota
Attualmente l'unico tipo di cluster HDInsight a cui è possibile collegare è un tipo Hive.
Per collegare un cluster HDInsight:
Fare clic con il pulsante destro del mouse su HDInsight e quindi scegliere Collega un cluster HDInsight per visualizzare la finestra di dialogo Collega un cluster HDInsight.
Immettere un URL di connessione nel formato
https://CLUSTERNAME.azurehdinsight.net. Il nome del cluster compila automaticamente la parte del nome del cluster dell'URL quando si passa a un altro campo. Immettere quindi nome utente e password e selezionare Avanti.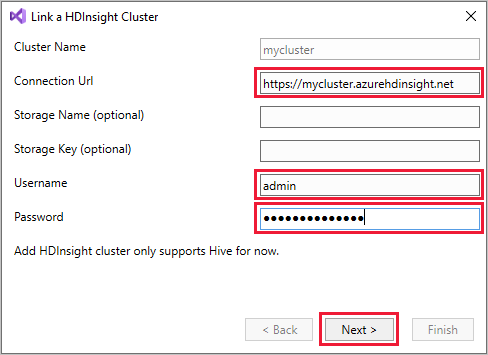
Selezionare Fine. Se il collegamento del cluster ha esito positivo, il cluster viene elencato nel nodo HDInsight .
Per aggiornare un cluster collegato, fare clic con il pulsante destro del mouse sul cluster e scegliere Modifica. È quindi possibile aggiornare le informazioni sul cluster.
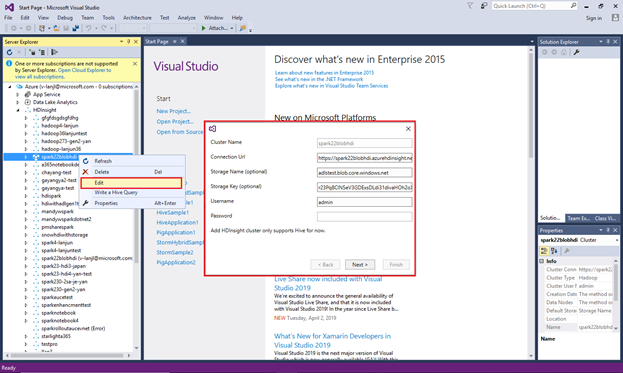
Esplorare risorse collegate
Da Esplora server è possibile visualizzare l'account di archiviazione predefinito e qualsiasi account di archiviazione collegato. Se si espande l'account di archiviazione predefinito, è possibile visualizzare i contenitori presenti. L'account di archiviazione predefinito e il contenitore predefinito sono contrassegnati.
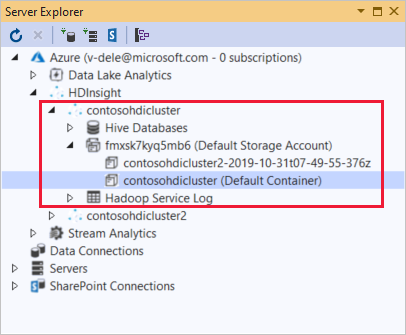
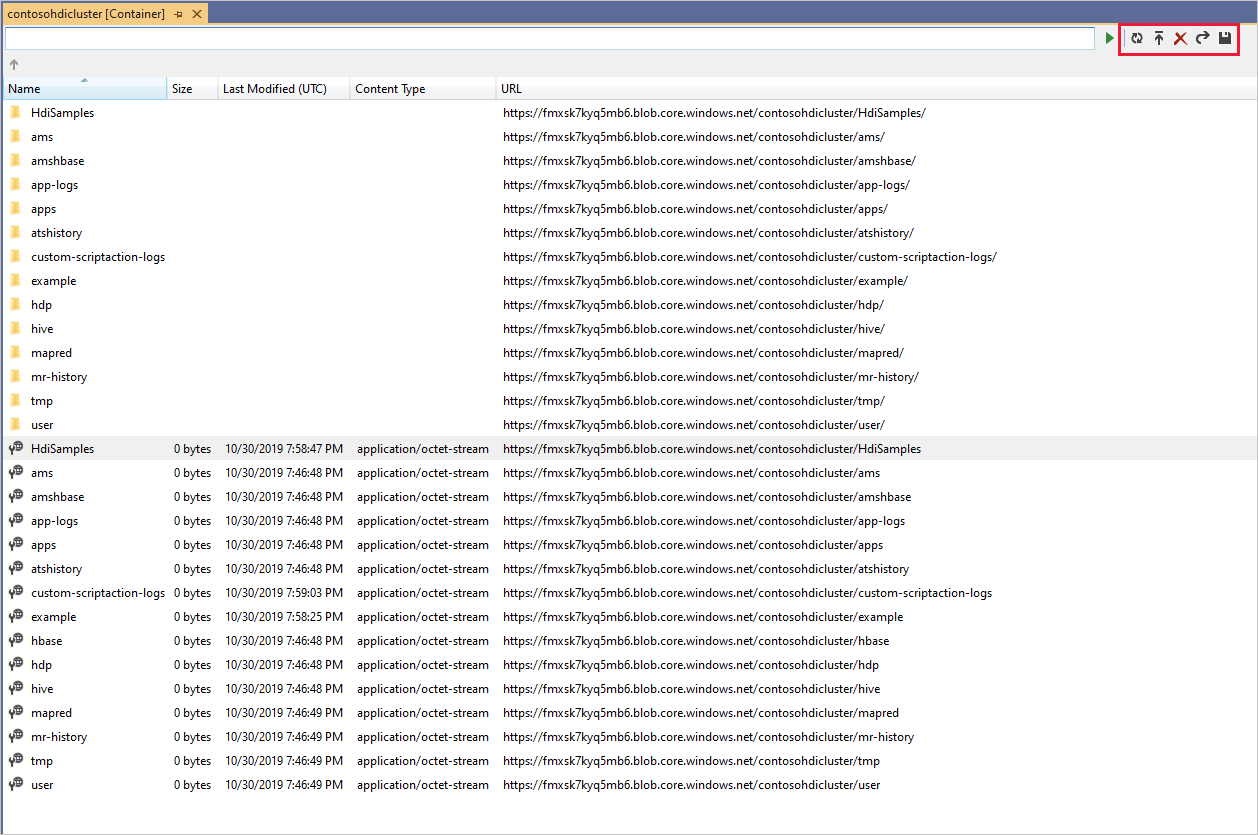
Fare clic con il pulsante destro del mouse su un contenitore e selezionare Visualizza contenitore per visualizzare il contenuto del contenitore. Dopo aver aperto un contenitore, è possibile usare i pulsanti della barra degli strumenti per aggiornare l'elenco di contenuto, Caricare BLOB, Eliminare BLOB selezionati, Aprire BLOB e scaricare (Salva con nome) selezionati.
Eseguire query Interactive Apache Hive
Apache Hive è un'infrastruttura di data warehouse basata su Hadoop. Hive viene usato per riepilogo, le query e l'analisi dei dati. È possibile usare Strumenti Data Lake per Visual Studio per eseguire query Hive da Visual Studio. Per altre informazioni su Hive, vedere Informazioni su Apache Hive e HiveQL in Azure HDInsight.For more information about Hive, see What is Apache Hive and HiveQL on Azure HDInsight?.
Interactive Query in Azure HDInsight usa Hive in LLAP in Apache Hive 2.1. Interactive Query offre interattività a query complesse di tipo data warehouse su set di dati archiviati di grandi dimensioni. L'esecuzione di query Hive in Interactive Query è molto più veloce rispetto ai processi batch Hive tradizionali.
Nota
È possibile eseguire query Hive interattive solo quando ci si connette a un cluster Interactive Query in HDInsight.
È anche possibile usare Strumenti Data Lake per Visual Studio per visualizzare gli elementi all'interno di un processo Hive. Strumenti Data Lake per Visual Studio raccoglie ed espone i log Yarn di determinati processi Hive.
In Esplora server scegliere Azure>HDInsight e selezionare il cluster. Questo nodo è il punto di partenza in Esplora server per le sezioni da seguire.
Visualizzare hivesampletable
Tutti i cluster HDInsight hanno una tabella Hive di esempio predefinita denominata hivesampletable.
Nel cluster scegliere Hive Databases default hivesampletable( Hive Databases>default>hivesampletable).
Per visualizzare lo
hivesampletableschema:Espandere hivesampletable. Vengono visualizzati i nomi e i tipi di dati delle
hivesampletablecolonne.Per visualizzare i
hivesampletabledati:Fare clic con il pulsante destro del mouse su hivesampletable e selezionare Visualizza prime 100 righe. L'elenco di 100 risultati viene visualizzato nella finestra Hive Table: hivesampletable . Questa azione equivale all'esecuzione della query Hive seguente usando il driver ODBC Hive:
SELECT * FROM hivesampletable LIMIT 100È possibile personalizzare il numero di righe modificando Numero di righe. È possibile scegliere 50, 100, 200 o 1000 righe dall'elenco a discesa.
Creare tabelle Hive
Per creare una tabella Hive, è possibile usare l'interfaccia utente grafica o query Hive. Per informazioni sull'uso di query Hive, vedere Creare ed eseguire query Hive.
Nel cluster scegliere Database>Hive predefiniti.
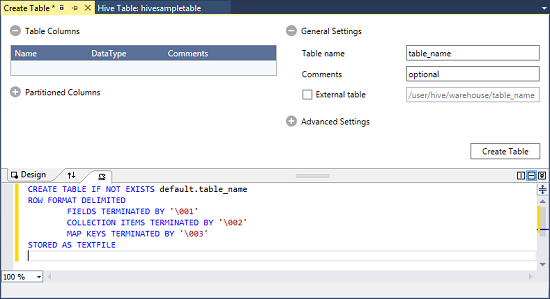
Fare clic con il pulsante destro del mouse su default e scegliere Crea tabella.
Configurare la tabella.
Selezionare il pulsante Crea tabella per inviare il processo, che crea la nuova tabella Hive.
Creare ed eseguire query Hive
Per la creazione e l'esecuzione di query Hive sono disponibili due opzioni:
- Creare query ad hoc
- Creare un'applicazione Hive
Creare una query ad hoc
Per creare ed eseguire una query ad hoc:
Fare clic con il pulsante destro del mouse sul cluster in cui si vuole eseguire la query e selezionare Scrivi una query Hive.
Immettere una query Hive.
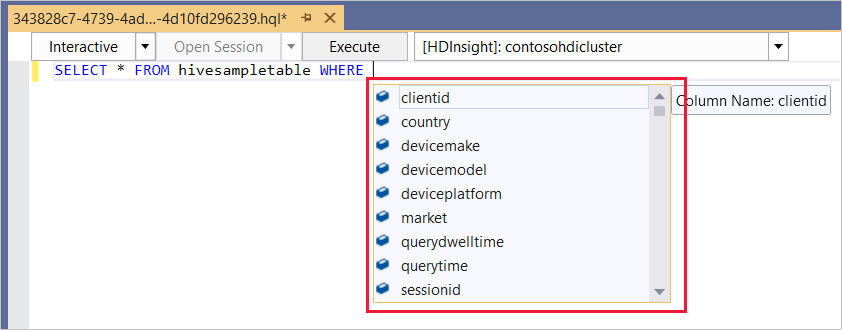
L'editor Hive supporta IntelliSense. Strumenti Data Lake per Visual Studio supporta il caricamento di metadati remoti quando si modifica lo script Hive. Se ad esempio si digita
SELECT * FROM, IntelliSense elenca tutti i nomi di tabella suggeriti. Quando si specifica un nome di tabella, IntelliSense elenca i nomi delle colonne. Gli strumenti supportano la maggior parte delle funzioni definite dall'utente predefinite, delle sottoquery e delle istruzioni DML Hive.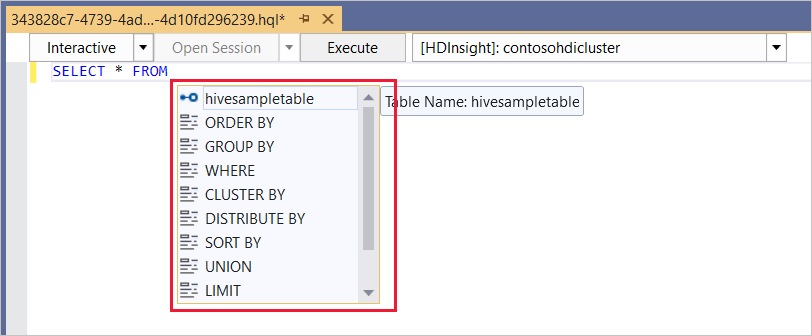
Nota
IntelliSense suggerisce solo i metadati del cluster selezionato nella barra degli strumenti HDInsight.
Ecco una query di esempio che è possibile usare:
SELECT devicemodel, COUNT(devicemodel) AS deviceCount FROM hivesampletable GROUP BY devicemodel ORDER BY devicemodelScegliere la modalità di esecuzione:
Interattivo
Nel primo elenco a discesa scegliere Interattivo e quindi selezionare Esegui.

Batch
Nel primo elenco a discesa scegliere Batch e quindi selezionare Invia. In alternativa, selezionare l'icona a discesa accanto a Invia e scegliere Avanzate.
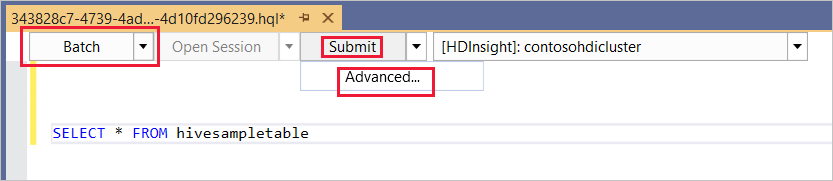
Se si seleziona l'opzione di invio avanzato, viene visualizzata la finestra di dialogo Invia script . Configurare il nome del processo, gli argomenti, le configurazioni aggiuntive e la directory di stato per lo script.
Nota
Non è possibile inviare batch ai cluster Interactive Query. È necessario usare la modalità interattiva.
Creare un'applicazione Hive
Per creare ed eseguire una soluzione Hive:
Nella barra dei menu scegliere File>Nuovo>progetto.
Nella finestra Crea un nuovo progetto selezionare la casella di ricerca e digitare Hive. Scegliere quindi Applicazione Hive e selezionare Avanti.
Nella finestra Configura il nuovo progetto immettere un nome di progetto, selezionare o creare il percorso del progetto e quindi selezionare Crea.
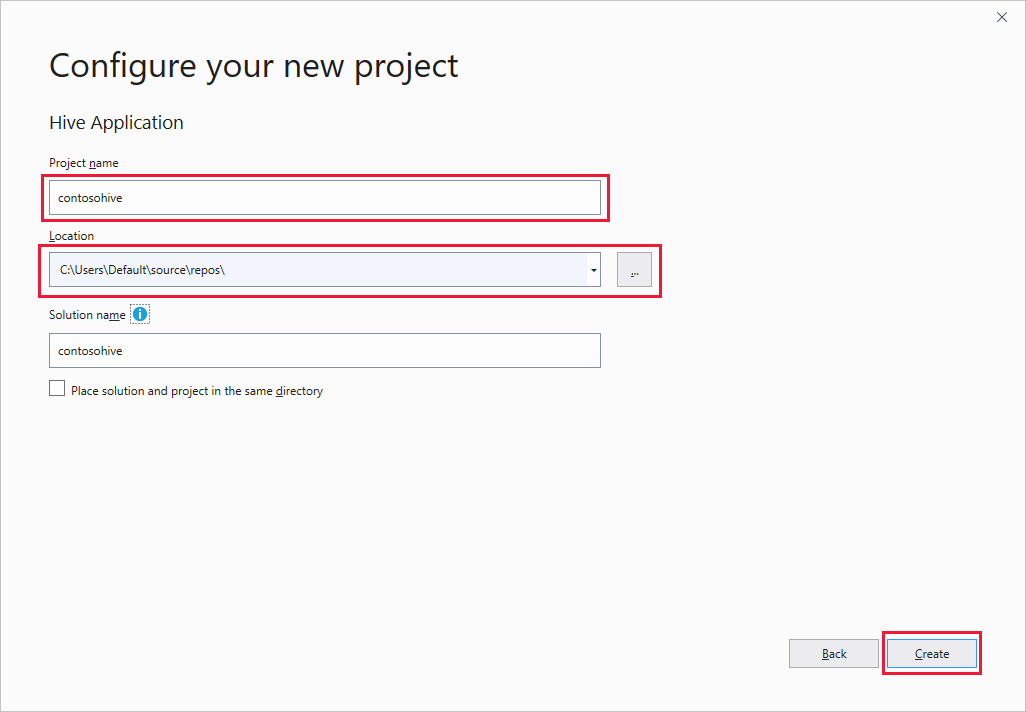
In Esplora soluzioni fare doppio clic su Script.hql per aprire lo script.
Visualizzare il riepilogo e l'output del processo
Il riepilogo del processo varia leggermente tra batch e modalità interattiva .
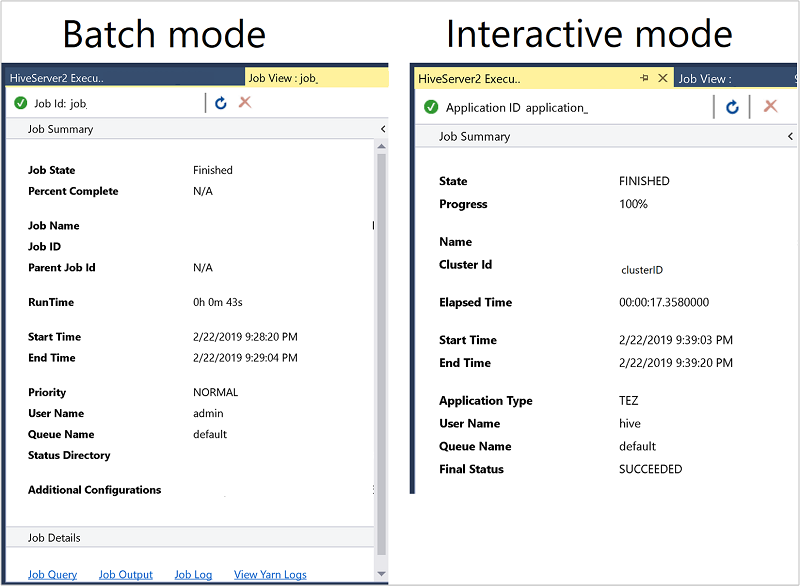
Usare l'icona Aggiorna per aggiornare lo stato fino a quando lo stato del processo non viene modificato in Fine.
Per i dettagli del processo in modalità Batch, selezionare i collegamenti nella parte inferiore per visualizzare la query del processo, l'output del processo o il log dei processi o per visualizzare i log yarn.
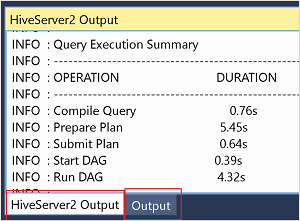
Per informazioni dettagliate sul processo dalla modalità interattiva , vedere i riquadri Output e Output HiveServer2.
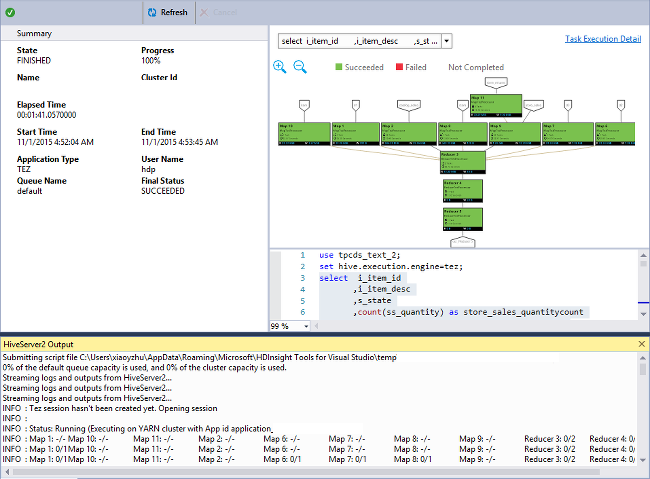
Visualizzare il grafico dei processi
Attualmente, i grafici dei processi vengono visualizzati solo per i processi Hive che usano Tez come motore di esecuzione. Per informazioni sull'abilitazione di Tez, vedere Che cos'è Apache Hive e HiveQL in Azure HDInsight?. Vedere anche Usare Apache Tez invece di Map Reduce.
Per visualizzare tutti gli operatori all'interno del vertice, fare doppio clic sui vertici del grafico del processo. È anche possibile puntare a un operatore specifico per visualizzare altri dettagli sull'operatore.
Anche se Tez viene specificato come motore di esecuzione, il grafico del processo potrebbe non essere visualizzato se non viene avviata alcuna applicazione Tez. Questa situazione può verificarsi perché il processo non contiene istruzioni DML. In alternativa, poiché le istruzioni DML possono restituire senza avviare un'applicazione Tez. Ad esempio, SELECT * FROM table1 non avvierà l'applicazione Tez.
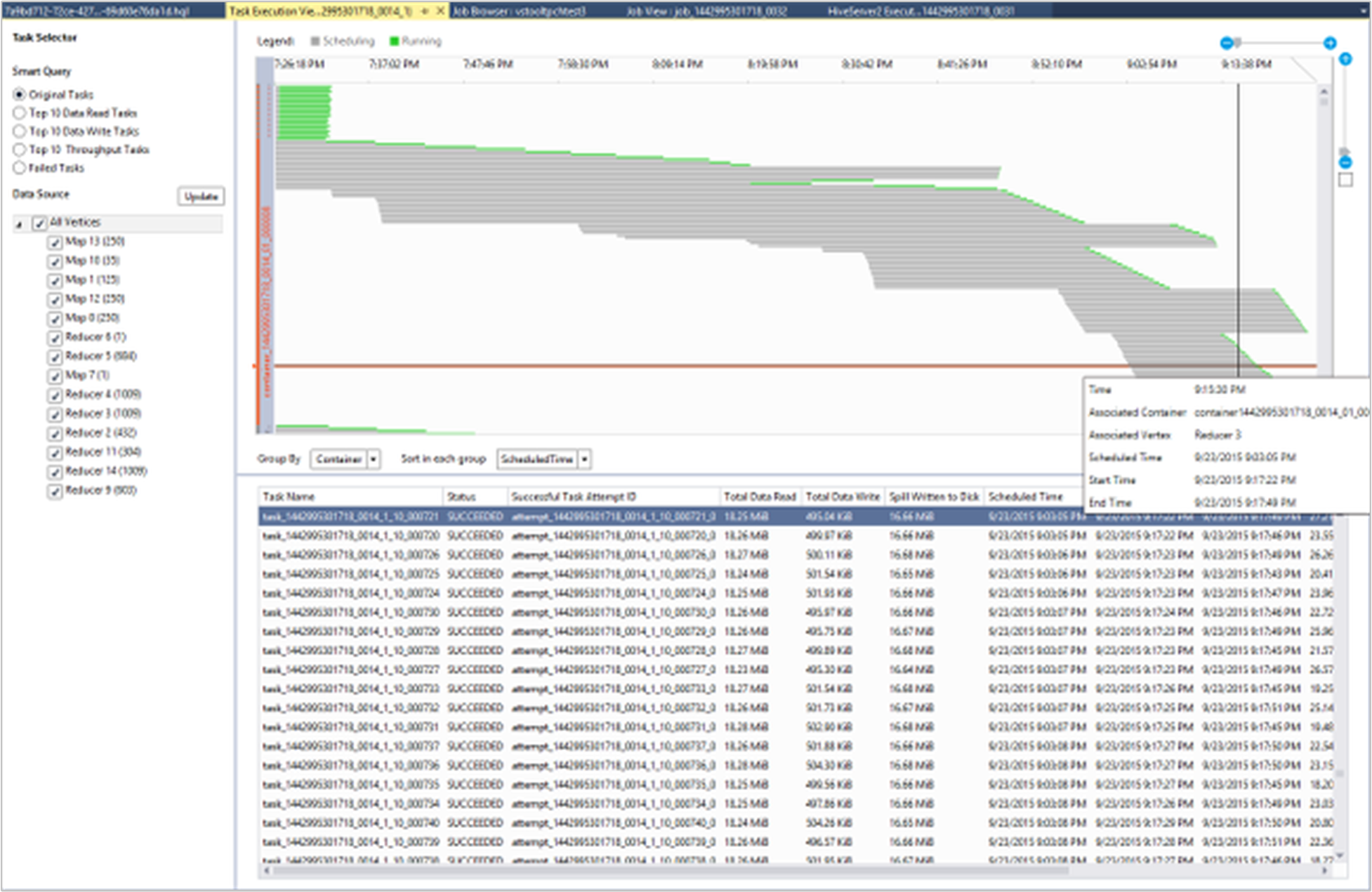
Visualizzare i dettagli di esecuzione delle attività
Nel grafico del processo è possibile selezionare Dettagli esecuzione attività per ottenere informazioni strutturate e visualizzate per i processi Hive. È anche possibile ottenere altri dettagli sul processo. Se si verificano problemi di prestazioni, è possibile usare la visualizzazione per ottenere altri dettagli sul problema. Ad esempio, è possibile recuperare informazioni sul funzionamento di ogni attività e informazioni dettagliate su ogni attività (dati di lettura/scrittura, pianificazione/ora di inizio/fine e altro ancora). Usare le informazioni per ottimizzare le configurazioni dei processi o l'architettura di sistema in base alle informazioni visualizzate.
Visualizzare processi Hive
È possibile visualizzare query di processo, output di processo, log di processo e log Yarn per i processi Hive.
Nella versione più recente degli strumenti è possibile visualizzare gli elementi all'interno dei processi Hive raccogliendo e visualizzando i log yarn. Un log Yarn consente di analizzare eventuali problemi di prestazioni. Per altre informazioni su come HDInsight raccoglie i log yarn, vedere Accedere ai log dell'applicazione YARN di Apache Hadoop.
Per visualizzare processi Hive:
Fare clic con il pulsante destro del mouse su un cluster HDInsight e scegliere Visualizza processi.
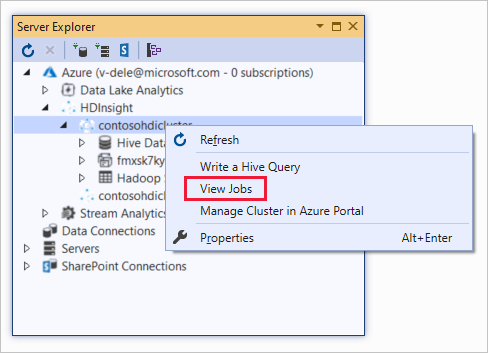
Viene visualizzato l'elenco di processi Hive eseguiti nel cluster.
Selezionare un processo. Nella finestra Riepilogo processo Hive selezionare uno dei collegamenti seguenti:
- Query processo
- Output processo
- Log processo
- Yarn Log
Eseguire script Apache Pig
Nella barra dei menu scegliere File>Nuovo>progetto.
Nella finestra Start selezionare la casella di ricerca e immettere Pig. Selezionare quindi Pig Application (Applicazione Pig) e quindi selezionare Next (Avanti).
Nella finestra Configura il nuovo progetto immettere un nome progetto e selezionare o creare un percorso per il progetto. Selezionare Crea.
Nel riquadro Esplora soluzioni IDE fare doppio clic su Script.pig per aprire lo script.
Commenti, suggerimenti e problemi noti
È stato risolto un problema a causa del quale i risultati che iniziano con valori Null non vengono visualizzati. Se questo problema impedisce di lavorare, contattare il team di supporto.
Lo script HQL creato da Visual Studio viene codificato, a seconda dell'impostazione dell'area locale dell'utente. Lo script non viene eseguito correttamente se lo si carica in un cluster come file binario.
Passaggi successivi
In questo articolo è stato illustrato come usare il pacchetto Strumenti Data Lake per Visual Studio per connettersi ai cluster HDInsight da Visual Studio. È stato anche illustrato come eseguire una query Hive.