Pianificazione della capacità per cluster HDInsight
Prima di distribuire un cluster HDInsight, pianificarne la capacità prevista determinando la scalabilità e le prestazioni necessarie. Con questa azione di pianificazione è possibile ottimizzare sia la semplicità di utilizzo sia i costi. Alcune decisioni relative alla capacità del cluster non possono essere cambiate dopo la distribuzione. Se i parametri delle prestazioni cambiano, è comunque possibile smontare e ricreare un cluster senza perdere i dati archiviati.
Di seguito sono elencate alcune domande che consentono di pianificare correttamente la capacità:
- In quale area geografica si intende distribuire il cluster?
- Quanto spazio di archiviazione è necessario?
- Quale tipo di cluster è opportuno distribuire?
- Che tipo di macchina virtuale, e di quali dimensioni, dovrebbero usare i nodi del cluster?
- Quanti nodi di lavoro dovrebbe avere il cluster?
Scegliere un'area di Azure
L'area di Azure determina il luogo in cui viene fisicamente eseguito il provisioning del cluster. Per ridurre al minimo la latenza di lettura e scrittura, è opportuno che il cluster si trovi vicino ai dati.
HDInsight è disponibile in molte aree di Azure. Per trovare l'area più vicina, vedere Prodotti disponibili in base all'area.
Scegliere le dimensioni e la posizione di archiviazione
Posizione della risorsa di archiviazione predefinita
La risorsa di archiviazione predefinita, che può essere un account di Archiviazione di Azure o Azure Data Lake Storage, deve trovarsi nella stessa posizione del cluster. Archiviazione di Azure è disponibile in tutte le posizioni, Data Lake Archiviazione è disponibile in alcune aree. Vedere la disponibilità corrente di Data Lake Archiviazione.
Posizione dei dati esistenti
Se si vuole usare un account di archiviazione o un'istanza di Data Lake Storage esistente come archiviazione predefinita del cluster, è necessario distribuire il cluster nella stessa area.
Dimensioni dello spazio di archiviazione
In un cluster distribuito è possibile collegare un altro account Archiviazione di Azure o accedere ad altri Archiviazione Data Lake. Tutti gli account di archiviazione devono trovarsi nella stessa area del cluster, mentre un'istanza di Data Lake Storage può trovarsi anche in un'area diversa, anche se distanze elevate potrebbero introdurre una certa latenza.
Archiviazione di Azure presenta alcuni limiti di capacità, mentre Data Lake Archiviazione è quasi illimitato. Un cluster può accedere a una combinazione di account di archiviazione diversi. Esempi tipici includono:
- Quando è probabile che la quantità di dati superi la capacità di archiviazione di un singolo contenitore di archiviazione BLOB.
- Quando è possibile che la frequenza di accesso al contenitore BLOB superi la soglia in cui è in funzione la limitazione.
- Quando si vuole rendere disponibili per il cluster i dati già caricati in un contenitore BLOB.
- Quando si preferisce isolare le varie parti della risorsa di archiviazione per motivi di sicurezza o per semplificare le attività di amministrazione.
Per prestazioni ottimali, usare solo un contenitore per ogni account archiviazione.
Scegliere un tipo di cluster
Il tipo di cluster determina il carico di lavoro per cui è configurata l'esecuzione del cluster HDInsight. I tipi includono Apache Hadoop, Apache Kafka o Apache Spark. Per una descrizione dettagliata dei tipi di cluster disponibili, vedere Introduzione ad Azure HDInsight. Ogni tipo di ogni cluster ha una topologia di distribuzione specifica che include i requisiti relativi alle dimensioni e al numero di nodi.
Scegliere il tipo e le dimensioni della macchina virtuale
Ogni tipo di cluster contiene un set di tipi di nodo, a cui sono associate opzioni specifiche per il tipo e la dimensione della macchina virtuale.
Per determinare le dimensioni ottimali del cluster per il tipo di applicazione, è possibile effettuare un benchmark della capacità del cluster e aumentare le dimensioni in base a quanto specificato. È possibile, ad esempio, usare un carico di lavoro simulato o una query canary. Eseguire i carichi di lavoro simulati in cluster di dimensioni diverse. Aumentare gradualmente le dimensioni fino a raggiungere le prestazioni previste. È possibile inserire periodicamente una query canary tra le altre query di produzione per verificare se il cluster ha o meno risorse sufficienti.
Per altre informazioni su come scegliere la famiglia di VM appropriata per il carico di lavoro, vedere Selezione delle dimensioni appropriate per le macchine virtuali del cluster.
Scegliere la scalabilità del cluster
La scalabilità di un cluster è determinata dalla quantità di nodi della macchina virtuale. Per tutti i tipi di cluster, sono disponibili tipi di nodo con scalabilità specifica e tipi di nodo che supportano la scalabilità orizzontale. Ad esempio, un cluster può richiedere esattamente tre nodi Apache ZooKeeper o due nodi Head. I nodi di lavoro che eseguono l'elaborazione dei dati in modo distribuito traggono vantaggio da un altro nodo di lavoro.
A seconda del tipo di cluster, l'aumento del numero di nodi di lavoro aggiunge più capacità di calcolo, ad esempio più core. Un numero maggiore di nodi aumenterà la quantità totale di memoria richiesta dall'intero cluster per supportare l'archiviazione in memoria dei dati elaborati. Come per la scelta del tipo e della dimensione della macchina virtuale, anche la scelta del grado di scalabilità del cluster viene eseguita in modo empirico. Usare carichi di lavoro simulati o query canary.
È possibile aumentare i nodi del cluster per soddisfare richieste di carico di picco. Quindi è possibile ridimensionarlo quando i nodi aggiuntivi non sono più necessari. La funzionalità di scalabilità automatica consente di dimensionare automaticamente il cluster in base a metriche e tempistiche predeterminate. Per altre informazioni sulla scalabilità manuale dei cluster, vedere Dimensionare i cluster HDInsight.
Ciclo di vita del cluster
I costi vengono addebitati per l'intera durata di un cluster. Se il cluster è necessario solo in alcuni momenti, è possibile creare cluster su richiesta usando Azure Data Factory. In alternativa, è possibile creare script di PowerShell che eseguono il provisioning ed eliminano il cluster e quindi pianificare gli script tramite Automazione di Azure.
Nota
Quando viene eliminato un cluster, viene eliminato anche il metastore Hive predefinito. Per mantenere il metastore per la creazione del cluster successivo, usare un archivio di metadati esterno come Database di Azure o Apache Oozie.
Isolare gli errori di processo del cluster
L'esecuzione parallela di più componenti di mapping e la riduzione dei componenti su un cluster multinodo possono generare talvolta degli errori. Per isolare il problema, provare a eseguire test distribuiti. Eseguire più processi simultanei in un cluster con un singolo nodo di lavoro. Espandere quindi questo approccio per eseguire più processi simultaneamente in cluster che contengono più di un nodo. Per creare un cluster HDInsight a nodo singolo in Azure, usare l'opzione Custom(size, settings, apps) e il valore 1 per Numero di nodi di lavoro nella sezione Dimensioni del cluster durante il provisioning di un nuovo cluster nel portale.
Visualizzare la gestione delle quote per HDInsight
Visualizzare un livello granulare e una categorizzazione della quota a livello di famiglia di macchine virtuali. Visualizzare la quota corrente e la quota rimanente per un'area a livello di famiglia di macchine virtuali.
Nota
Questa funzionalità è attualmente disponibile in HDInsight 4.x e 5.x per l'area EUAP Stati Uniti orientali. Altre aree da seguire successivamente.
Visualizzare la quota corrente:
Vedere la quota corrente e la quota rimanente per un'area a livello di famiglia di macchine virtuali.
Nella barra di ricerca superiore della portale di Azure cercare e selezionare Quote.
Nella pagina Quota selezionare Azure HDInsight
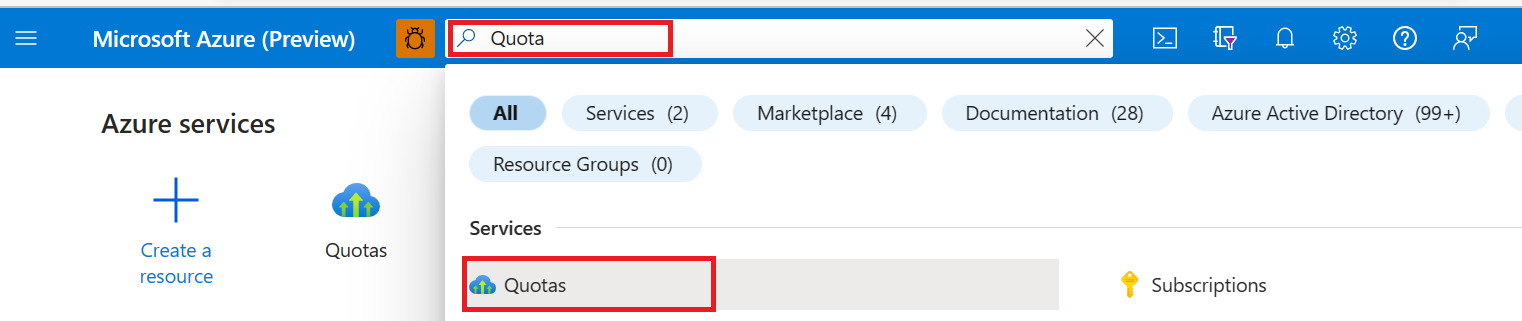
Nella casella a discesa selezionare la sottoscrizione e l'area geografica
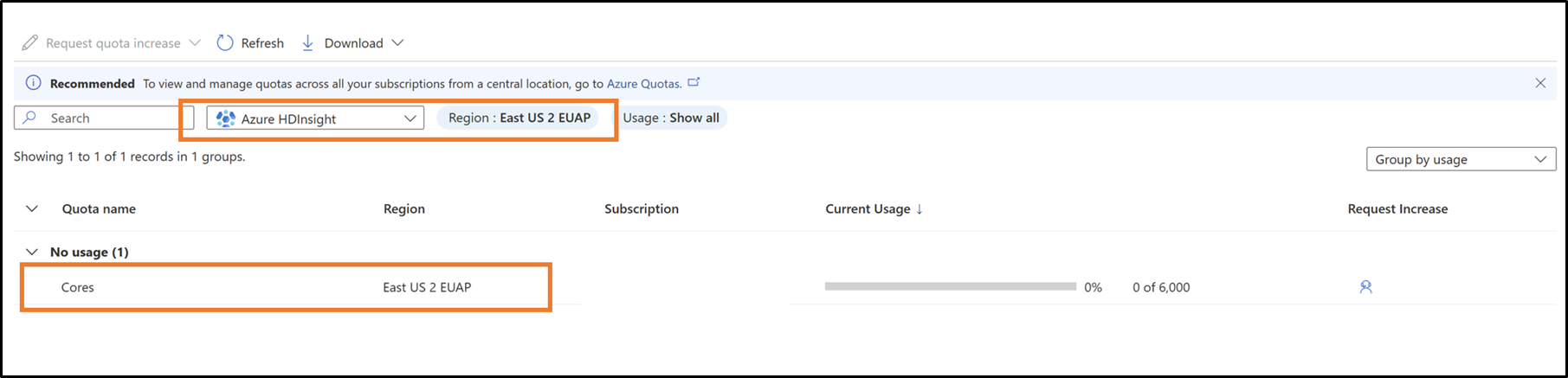
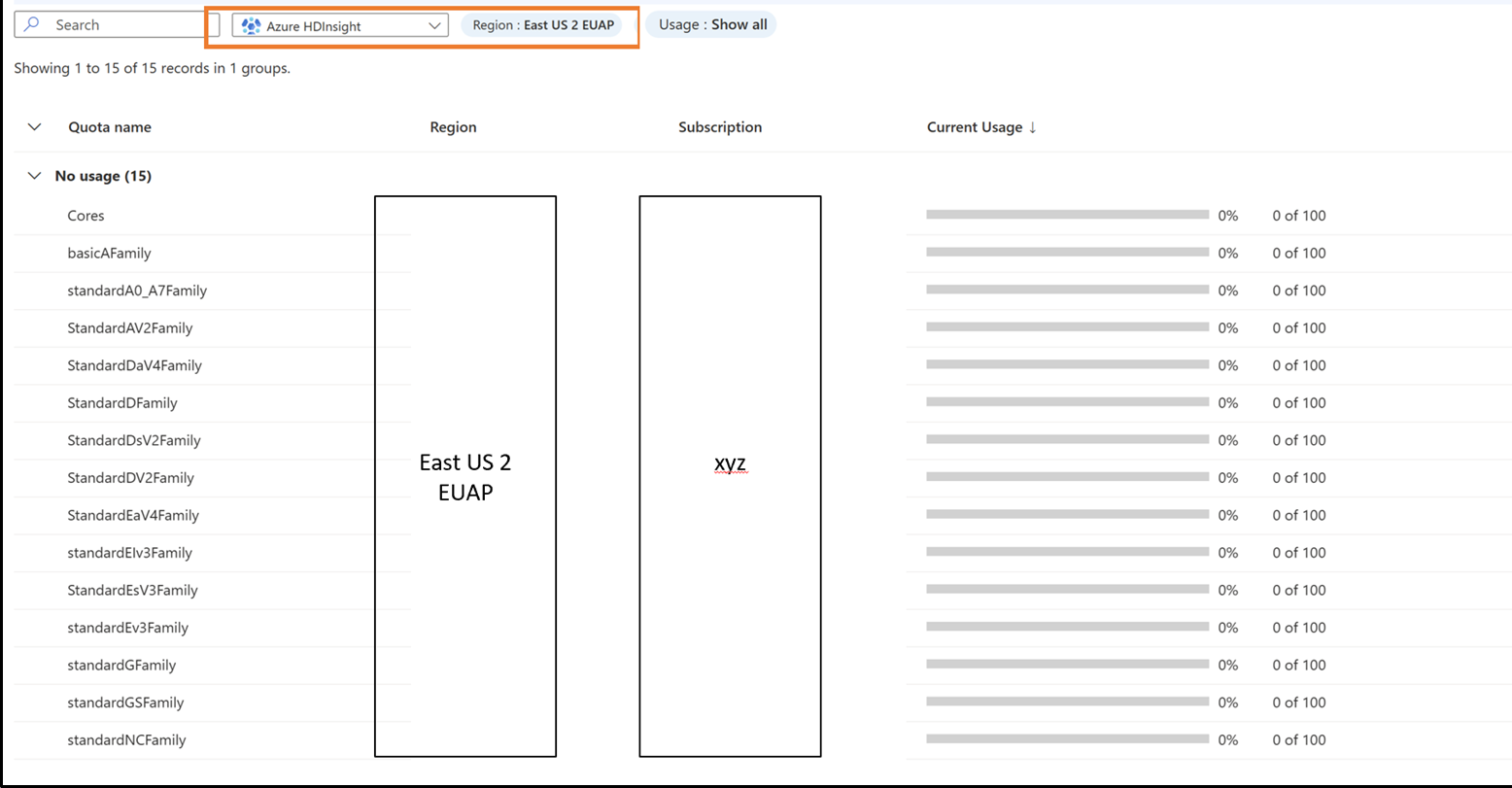
Richiedere nuove quote per famiglia di macchine virtuali e area
- Fare clic sulla riga per cui si desidera visualizzare i dettagli della quota.
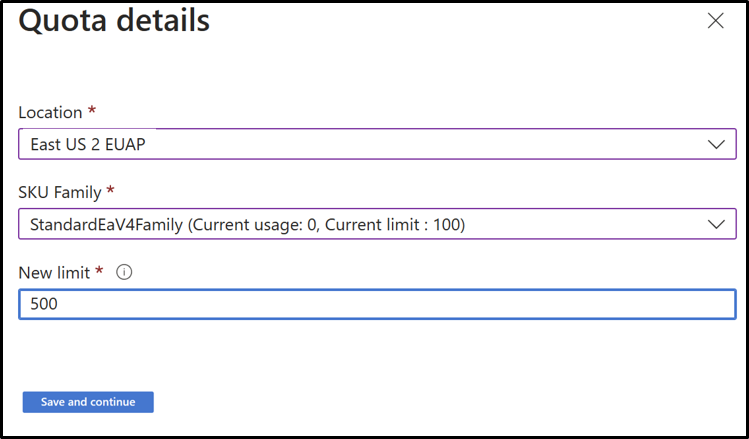




Obiettivi di vendita
Per altre informazioni sulla gestione delle quote di sottoscrizione, vedere Richiesta di aumenti della quota.
Passaggi successivi
- Configurare cluster in HDInsight con Apache Hadoop, Spark, Kafka e altro ancora: Informazioni su come configurare e configurare cluster in HDInsight.
- Monitorare le prestazioni del cluster: informazioni sui principali scenari da monitorare per il cluster HDInsight che potrebbero influire sulla relativa capacità.