Debug del processo Spark non riuscito con Azure Toolkit for IntelliJ (anteprima)
Questo articolo fornisce istruzioni dettagliate su come usare gli strumenti HDInsight in Azure Toolkit for IntelliJ per eseguire applicazioni di debug degli errori Spark.
Prerequisiti
Kit di sviluppo di Oracle Java. Questa esercitazione usa Java versione 8.0.202.
IntelliJ IDEA. Questo articolo usa IntelliJ IDEA Community 2019.1.3.
Azure Toolkit for IntelliJ. Vedere Installazione di Azure Toolkit for IntelliJ.
Connettersi al cluster HDInsight. Vedere Connettersi al cluster HDInsight.
Microsoft Azure Storage Explorer. Vedere Scaricare Archiviazione di Microsoft Azure Explorer.
Creare un progetto con un modello di debug
Creare un progetto spark2.3.2 per continuare il debug degli errori, eseguire il debug dell'attività di errore nel file di esempio in questo documento.
Aprire IntelliJ IDEA. Aprire la finestra Nuovo progetto .
a. Selezionare Azure Spark/HDInsight nel riquadro sinistro.
b. Selezionare Spark Project with Failure Task Debugging Sample(Preview)(Scala) (Progetto Spark con debug attività di errore(anteprima)(Scala) dalla finestra principale.
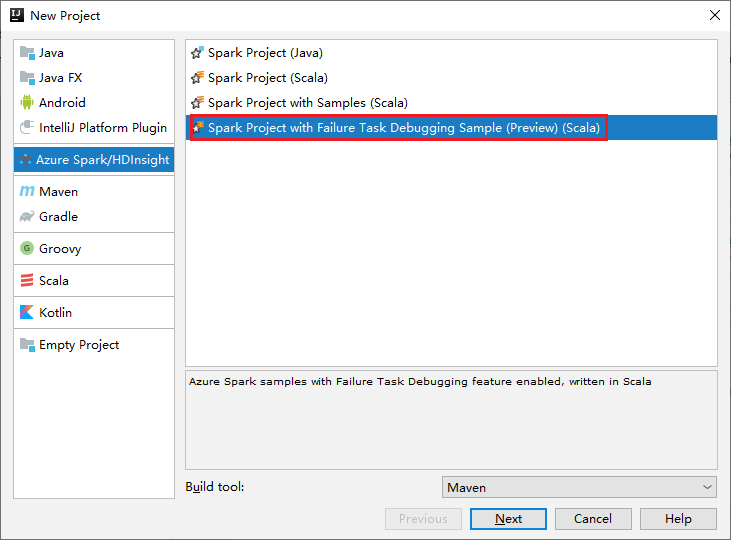
c. Selezionare Avanti.
Nella finestra di dialogo New Project (Nuovo progetto) eseguire questa procedura:
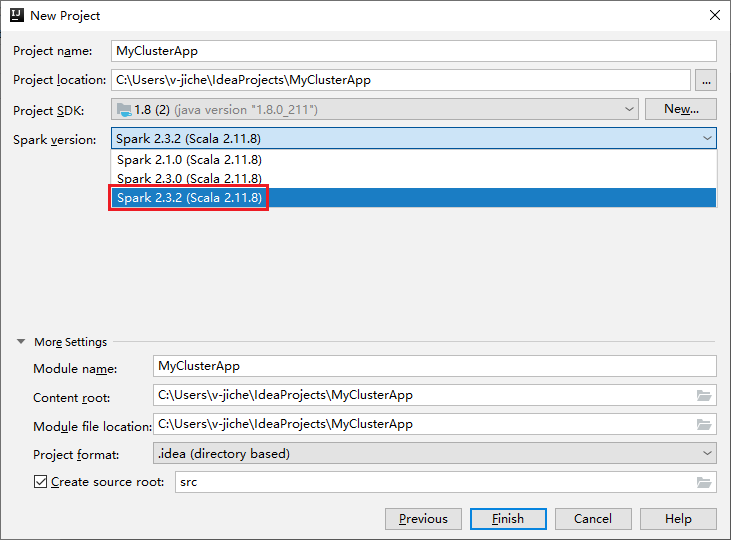
a. Specificare un nome per il progetto e il relativo percorso.
b. Nell'elenco a discesa Project SDK selezionare Java 1.8 per cluster Spark 2.3.2 .
c. Nell'elenco a discesa Versione Spark selezionare Spark 2.3.2(Scala 2.11.8).
d. Selezionare Fine.
Selezionare src>main>scala per aprire il codice nel progetto. In questo esempio viene usato lo script AgeMean_Div().
Eseguire un'applicazione Spark Scala/Java in un cluster HDInsight
Creare un'applicazione Spark Scala/Java, quindi eseguire l'applicazione in un cluster Spark seguendo questa procedura:
Fare clic su Aggiungi configurazione per aprire la finestra Run/Debug Configurations (Configurazioni di esecuzione/debug).

Nella finestra di dialogo Run/Debug Configurations (Esegui/Debug delle configurazioni) selezionare il segno più (+). Selezionare quindi l'opzione Apache Spark in HDInsight .
Passare alla scheda Esecuzione remota nel cluster . Immettere le informazioni per Nome, Cluster Spark e Nome classe principale. Questi strumenti supportano il debug con executor. numExecutors, il valore predefinito è 5 e non impostare un valore superiore a 3. Per ridurre il tempo di esecuzione, è possibile aggiungere spark.yarn.maxAppAttempts in Configurazioni processo e impostare il valore su 1. Fare clic sul pulsante OK per salvare la configurazione.
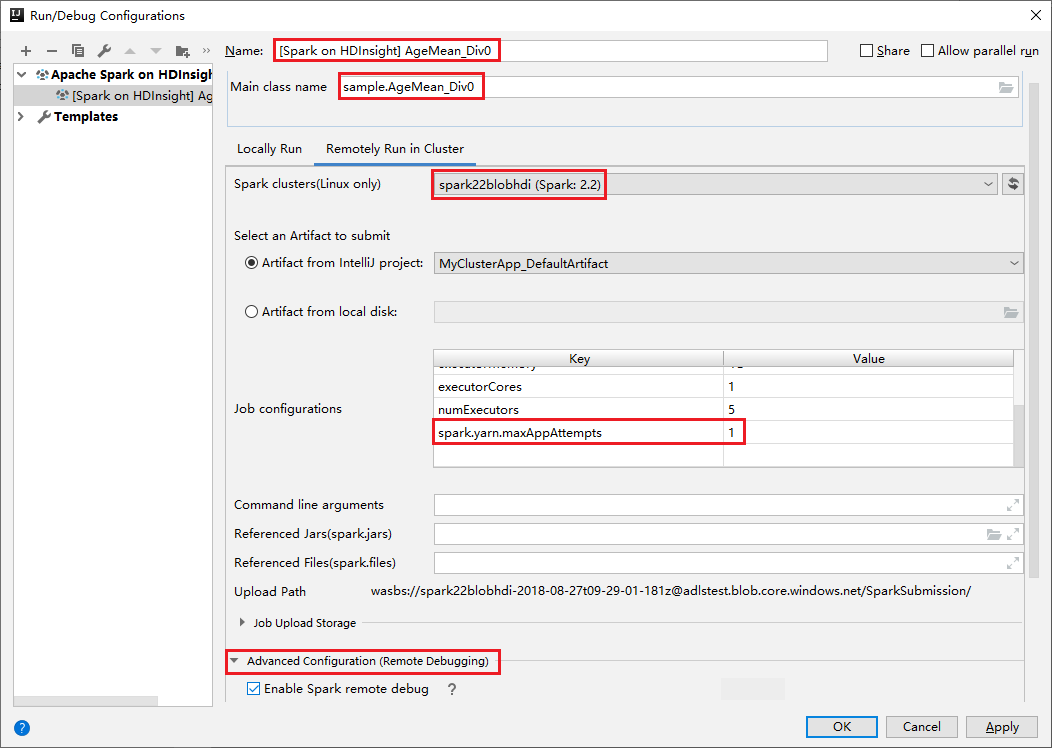
A questo punto, la configurazione viene salvata con il nome specificato. Per visualizzare i dettagli della configurazione, selezionare il relativo nome. Per apportare modifiche, selezionare Modifica configurazioni.
Dopo aver completato le impostazioni di configurazione, è possibile eseguire il progetto nel cluster remoto.

È possibile controllare l'ID applicazione dalla finestra di output.

Scaricare il profilo di processo non riuscito
Se l'invio del processo non riesce, è possibile scaricare il profilo di processo non riuscito nel computer locale per un ulteriore debug.
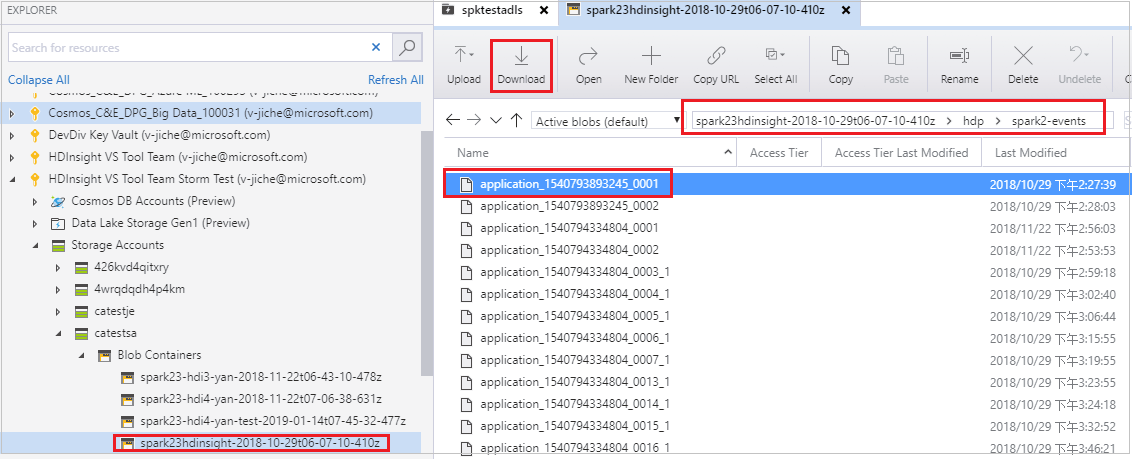
Aprire Archiviazione di Microsoft Azure Explorer, individuare l'account HDInsight del cluster per il processo non riuscito, scaricare le risorse del processo non riuscito dal percorso corrispondente: \hdp\spark2-events\.spark-failures\<ID> applicazione in una cartella locale. La finestra attività mostrerà lo stato di avanzamento del download.
Configurare l'ambiente di debug locale ed eseguire il debug in caso di errore
Aprire il progetto originale o creare un nuovo progetto e associarlo al codice sorgente originale. Attualmente è supportata solo la versione spark2.3.2 per il debug degli errori.
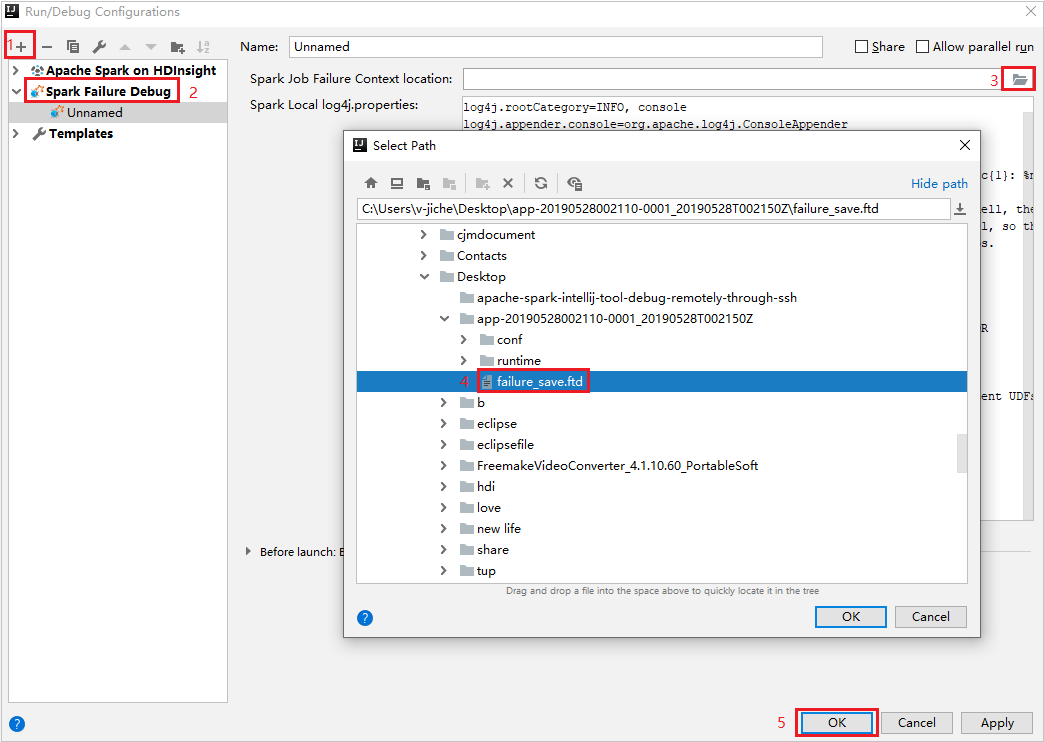
In IntelliJ IDEA creare un file di configurazione debug errori Spark, selezionare il file FTD dalle risorse del processo non riuscito precedentemente scaricate per il campo Percorso contesto errore processo Spark.
Fare clic sul pulsante Esecuzione locale sulla barra degli strumenti. L'errore verrà visualizzato nella finestra Esegui.
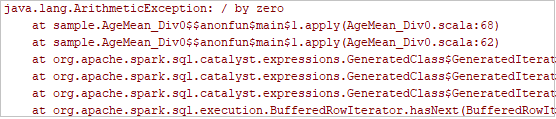
Impostare il punto di interruzione come indicato dal log, quindi fare clic sul pulsante debug locale per eseguire il debug locale esattamente come i normali progetti Scala/Java in IntelliJ.
Dopo il debug, se il progetto viene completato correttamente, è possibile inviare di nuovo il processo non riuscito al cluster Spark nel cluster HDInsight.
Passaggi successivi
Scenari
- Apache Spark con BI: Eseguire l'analisi interattiva dei dati usando Spark in HDInsight con gli strumenti di business intelligence
- Apache Spark con Machine Learning: usare Spark in HDInsight per l'analisi della temperatura di compilazione usando dati HVAC
- Apache Spark con Machine Learning: utilizzare Spark in HDInsight per prevedere i risultati di un controllo alimentare
- Analisi dei log del sito Web con Apache Spark in HDInsight
Creare ed eseguire applicazioni
- Creare un'applicazione autonoma con Scala
- Eseguire processi in modalità remota in un cluster Apache Spark usando Apache Livy
Strumenti ed estensioni
- Usare Azure Toolkit for IntelliJ per creare applicazioni Apache Spark per un cluster HDInsight
- Usare Azure Toolkit for IntelliJ per il debug remoto di applicazioni Apache Spark tramite VPN
- Usare gli strumenti HDInsight in Azure Toolkit for Eclipse per creare applicazioni Apache Spark
- Usare i notebook di Apache Zeppelin con un cluster Apache Spark in HDInsight
- Kernel disponibili per Jupyter Notebook nel cluster Apache Spark per HDInsight
- Usare pacchetti esterni con Jupyter Notebook
- Installare Jupyter Notebook nel computer e connetterlo a un cluster HDInsight Spark