Usare il modello di apprendimento approfondito Microsoft Cognitive Toolkit con un cluster Azure HDInsight Spark
In questo articolo viene illustrata la procedura seguente.
Eseguire uno script personalizzato per installare Microsoft Cognitive Toolkit in un cluster Azure HDInsight Spark.
Caricare un oggetto Jupyter Notebook nel cluster Apache Spark per vedere come applicare ai file un modello con training di apprendimento approfondito di Microsoft Cognitive Toolkit in un account di Archiviazione BLOB di Azure tramite l'API Python Spark (PySpark)
Prerequisiti
Un cluster Apache Spark in HDInsight. Vedere Creare un cluster Apache Spark.
Familiarità nell'uso di Jupyter Notebook con Spark in HDInsight. Per altre informazioni, vedere l'articolo su come caricare i dati ed eseguire query con Apache Spark in HDInsight.
Svolgimento della soluzione
Questa soluzione è divisa tra questo articolo e un jupyter Notebook caricato come parte di questo articolo. In questo articolo verrà completata la procedura seguente:
- Eseguire un'azione script in un cluster HDInsight Spark per installare i pacchetti Microsoft Cognitive Toolkit e Python.
- Caricare Jupyter Notebook che esegue la soluzione nel cluster HDInsight Spark.
I passaggi rimanenti seguenti sono illustrati in Jupyter Notebook.
- Caricare immagini di esempio in un set di dati distribuito resiliente Spark o RDD.
- Caricare i moduli e definire i set di impostazioni.
- Scaricare il set di dati in locale nel cluster Spark.
- Convertire il set di dati in RDD.
- Classificare le immagini tramite un modello con training Cognitive Toolkit.
- Scaricare il modello con training Cognitive Toolkit nel cluster Spark.
- Definire le funzioni usate dai nodi del ruolo di lavoro.
- Classificare le immagini nei nodi del ruolo di lavoro.
- Valutare l'accuratezza del modello.
Installare Microsoft Cognitive Toolkit
È possibile installare Microsoft Cognitive Toolkit in un cluster Spark tramite l'azione script. L'azione script usa script personalizzati per installare i componenti nel cluster che non sono disponibili per impostazione predefinita. È possibile usare lo script personalizzato del portale di Azure usando HDInsight .NET SDK o Azure PowerShell. È possibile usare lo script anche per installare il toolkit sia nell’ambito della creazione del cluster sia quando il cluster è in esecuzione.
In questo articolo il toolkit verrà installato dal portale, dopo la creazione del cluster. Per altri modi di eseguire lo script personalizzato, vedere Personalizzare cluster HDInsight tramite azione script.
Tramite il portale di Azure
Per istruzioni su come usare il portale di Azure per eseguire l'azione script, vedere Personalizzare i cluster HDInsight usando l'azione script. Assicurarsi di specificare i dati seguenti per installare Microsoft Cognitive Toolkit. Usare i valori seguenti per l'azione script:
| Proprietà | valore |
|---|---|
| Tipo di script | - Personalizzato |
| Nome | Installare MCT |
| URI script Bash | https://raw.githubusercontent.com/Azure-Samples/hdinsight-pyspark-cntk-integration/master/cntk-install.sh |
| Tipi di nodo: | Head, Worker |
| Parametri | None |
Caricare Jupyter Notebook nel cluster Azure HDInsight Spark
Per usare Microsoft Cognitive Toolkit con il cluster Azure HDInsight Spark, è necessario caricare Jupyter Notebook CNTK_model_scoring_on_Spark_walkthrough.ipynb nel cluster Azure HDInsight Spark. Tale notebook è disponibile in GitHub all'indirizzo https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration.
Scaricare e decomprimere https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration.
In un Web browser passare a
https://CLUSTERNAME.azurehdinsight.net/jupyterdoveCLUSTERNAMEè il nome del cluster.Da Jupyter Notebook selezionare Carica nell'angolo in alto a destra e quindi passare al download e selezionare il file
CNTK_model_scoring_on_Spark_walkthrough.ipynb.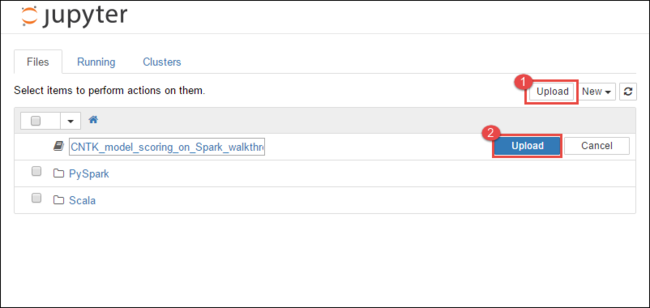
Selezionare di nuovo Carica .
Dopo aver caricato il notebook, fare clic sul nome del notebook e quindi seguire le istruzioni nel notebook stesso su come caricare il set di dati ed eseguire l'articolo.
Vedi anche
Scenari
- Apache Spark con Business Intelligence: eseguire l'analisi interattiva dei dati con strumenti di Business Intelligence mediante Spark in HDInsight
- Apache Spark con Machine Learning: utilizzare Spark in HDInsight per l'analisi della temperatura di compilazione utilizzando dati HVAC
- Apache Spark con Machine Learning: utilizzare Spark in HDInsight per prevedere i risultati di un controllo alimentare
- Analisi dei log del sito Web con Apache Spark in HDInsight
- Analisi dei dati di telemetria di Application Insights con Apache Spark in HDInsight
Creare ed eseguire applicazioni
- Creare un'applicazione autonoma con Scala
- Eseguire processi in modalità remota in un cluster Apache Spark usando Apache Livy
Strumenti ed estensioni
- Usare il plug-in degli strumenti HDInsight per IntelliJ IDEA per creare e inviare applicazioni Spark in Scala
- Usare il plug-in Strumenti HDInsight per IntelliJ IDEA per eseguire il debug di applicazioni Apache Spark in remoto
- Usare i notebook di Apache Zeppelin con un cluster Apache Spark in HDInsight
- Kernel disponibili per Jupyter Notebook nel cluster Apache Spark per HDInsight
- Usare pacchetti esterni con Jupyter Notebook
- Installare Jupyter Notebook nel computer e connetterlo a un cluster HDInsight Spark