Esercitazione: Creare pipeline di Machine Learning di produzione
SI APPLICA A:  Python SDK azure-ai-ml v2 (corrente)
Python SDK azure-ai-ml v2 (corrente)
Nota
Per un'esercitazione in cui viene usato SDK v1 per creare una pipeline, vedere Esercitazione: Creare una pipeline di Azure Machine Learning per la classificazione delle immagini
L'attività principale di una pipeline di Machine Learning consiste nel dividere un'attività completa di Machine Learning in un flusso di lavoro composto da più passaggi. Ogni passaggio è un componente gestibile che può essere sviluppato, ottimizzato, configurato e automatizzato singolarmente. I passaggi sono connessi tramite interfacce ben definite. Il servizio pipeline di Azure Machine Learning orchestra automaticamente tutte le dipendenze tra i passaggi della pipeline. I vantaggi dell'uso di una pipeline sono la standardizzazione della procedura MLOps, la collaborazione in team scalabile, l'efficienza del training e la riduzione dei costi. Per altre informazioni sui vantaggi delle pipeline, vedere Cosa sono le pipeline di Azure Machine Learning.
In questa esercitazione si usa Azure Machine Learning per creare un progetto di Machine Learning pronto per la produzione usando Azure Machine Learning Python SDK v2.
Questo vuol dire che sarà possibile sfruttare l'SDK Python di Azure Machine Learning Python per:
- Ottenere un handle all'area di lavoro di Azure Machine Learning
- Creare asset di dati di Azure Machine Learning
- Creare componenti riutilizzabili di Azure Machine Learning
- Creare, convalidare ed eseguire pipeline di Azure Machine Learning
Durante questa esercitazione si crea una pipeline di Azure Machine Learning per eseguire il training di un modello per la previsione predefinita del credito. La pipeline gestisce due passaggi:
- Preparazione dei dati
- Training e registrazione del modello sottoposto a training
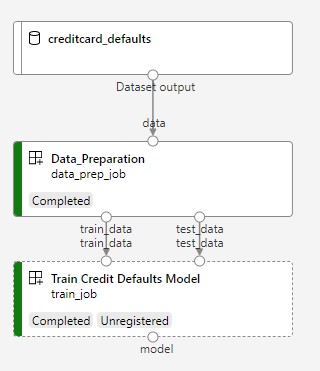
L'immagine successiva mostra una pipeline semplice così come verrà visualizzata nello studio di Azure dopo l'invio.
Il primo passaggio è la preparazione dei dati, il secondo è il training.
Questo video illustra come iniziare a usare lo studio di Azure Machine Learning in modo da poter seguire i passaggi dell'esercitazione. Il video mostra come creare un notebook, creare un'istanza di ambiente di calcolo e clonare il notebook. I passaggi sono descritti anche nelle sezioni seguenti.
Prerequisiti
-
Per usare Azure Machine Learning, è necessaria un'area di lavoro. Se non è disponibile, completare Creare le risorse necessarie per iniziare creare un'area di lavoro e ottenere maggiori informazioni su come usarla.
Importante
Se l'area di lavoro di Azure Machine Learning è configurata con una rete virtuale gestita, potrebbe essere necessario aggiungere regole in uscita per consentire l'accesso ai repository di pacchetti Python pubblici. Per altre informazioni, vedere Scenario: Accedere ai pacchetti di Machine Learning pubblici.
-
Accedere allo studio e selezionare l'area di lavoro, se non è già aperta.
Completare l'esercitazione Caricare i dati, accedervi ed esplorarli per creare l'asset di dati necessario in questa esercitazione. Assicurarsi di eseguire tutto il codice per creare l'asset di dati iniziale. Esplorare i dati e modificarli se si vuole, ma in questa esercitazione serviranno solo i dati iniziali.
-
Aprire o creare un notebook nell'area di lavoro:
- Se si vuole copiare e incollare il codice nelle celle, creare un nuovo notebook.
- In alternativa, aprire tutorials/get-started-notebooks/pipeline.ipynb dalla sezione Esempi dello studio. Selezionare quindi Clona per aggiungere il notebook in File. Per trovare notebook di esempio, vedere Learn from sample notebooks (Informazioni sui notebook di esempio).
Impostare il kernel e aprirlo in Visual Studio Code (VS Code)
Nella barra superiore sopra il notebook aperto creare un'istanza di ambiente di calcolo, se non ne è già disponibile una.

Se l'istanza di ambiente di calcolo viene arrestata, selezionare Avviare ambiente di calcolo e attendere fino a quando non è in esecuzione.

Attendere che l'istanza di calcolo sia in esecuzione. Assicurarsi quindi che il kernel, trovato in alto a destra, sia
Python 3.10 - SDK v2. In caso contrario, usare l'elenco a discesa per selezionare questo kernel.
Se questo kernel non viene visualizzato, verificare che l'istanza di calcolo sia in esecuzione. In caso affermativo, selezionare il pulsante Aggiorna in alto a destra del notebook.
Se viene visualizzato un banner che indica che è necessario eseguire l'autenticazione, selezionare Autentica.
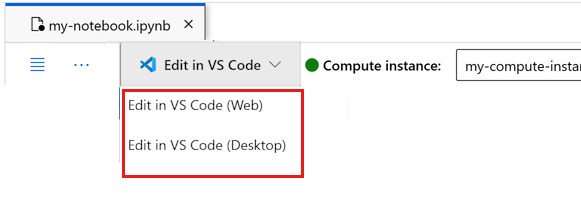
È possibile eseguire il notebook qui o aprirlo in VS Code per usare un ambiente di sviluppo integrato (IDE) completo con la potenza delle risorse di Azure Machine Learning. Selezionare Apri in VS Code, quindi selezionare l'opzione Web o desktop. Quando viene avviato in questo modo, VS Code viene collegato all'istanza di ambiente di calcolo, al kernel e al file system dell'area di lavoro.




Importante
La parte rimanente di questa esercitazione contiene le celle del notebook dell'esercitazione. Copiarli e incollarli nel nuovo notebook oppure passare ora al notebook se è stato clonato.
Configurare le risorse della pipeline
Il framework di Azure Machine Learning può essere usato dall'interfaccia della riga di comando, da Python SDK o dall'interfaccia dello studio. In questo esempio si usa Azure Machine Learning Python SDK v2 per creare una pipeline.
Prima di creare la pipeline, sono necessarie le risorse seguenti:
- Asset di dati per il training
- Ambiente software per eseguire la pipeline
- Risorsa di calcolo in cui eseguire il processo
Creare un handle all'area di lavoro
Prima di passare ai dettagli del codice, è necessario un modo per fare riferimento all'area di lavoro. Verrà creato un oggetto ml_client per un handle all'area di lavoro. Sarà quindi possibile usare ml_client per gestire le risorse e i processi.
Nella cella successiva immettere l'ID sottoscrizione, il nome del gruppo di risorse e il nome dell'area di lavoro. Per trovare questi valori:
- In alto a destra nella barra degli strumenti dello studio di Azure Machine Learning selezionare il nome dell'area di lavoro.
- Copiare i valori per l'area di lavoro, il gruppo di risorse e l'ID sottoscrizione nel codice.
- Sarà necessario copiare un valore, chiudere l'area e incollarlo, quindi tornare indietro per quello successivo.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Nota
La creazione di MLClient non comporta la connessione all'area di lavoro. L'inizializzazione del client avviene in modo differito e viene attesa la prima volta in cui è necessario effettuare una chiamata (questa operazione verrà eseguita nella cella di codice successiva).
Verificare la connessione effettuando una chiamata a ml_client. Poiché è la prima volta che si effettua una chiamata all'area di lavoro, può essere necessario eseguire l'autenticazione.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
Accedere all'asset di dati registrato
Per iniziare, recuperare i dati registrati in precedenza in Esercitazione: Caricare i dati, accedervi ed esplorarli in Azure Machine Learning.
- Azure Machine Learning usa un oggetto
Dataper registrare una definizione riutilizzabile dei dati e utilizzare i dati all'interno di una pipeline.
# get a handle of the data asset and print the URI
credit_data = ml_client.data.get(name="credit-card", version="initial")
print(f"Data asset URI: {credit_data.path}")
Creare un ambiente di processo per i passaggi della pipeline
Finora è stato creato un ambiente di sviluppo nell'istanza di ambiente calcolo, il computer di sviluppo. È anche necessario un ambiente da usare per ogni passaggio della pipeline. Ogni passaggio può avere un suo ambiente oppure è possibile usare alcuni ambienti comuni per più passaggi.
In questo esempio viene creato un ambiente Conda per i processi usando un file YAML Conda. Per prima cosa, creare una directory in cui archiviare il file.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Creare ora il file nella directory delle dipendenze.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=0.24.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- xlrd==2.0.1
- mlflow== 2.4.1
- azureml-mlflow==1.51.0
La specifica contiene alcuni pacchetti consueti da usare nella pipeline (numpy, pip) e alcuni pacchetti specifici di Azure Machine Learning (azureml-mlflow).
I pacchetti di Azure Machine Learning non sono obbligatori per eseguire processi di Azure Machine Learning. Tuttavia, l'aggiunta di questi pacchetti consente di interagire con Azure Machine Learning per registrare le metriche e i modelli, tutto all'interno del processo di Azure Machine Learning. Verranno usati nello script di training più avanti in questa esercitazione.
Usare il file YAML per creare e registrare questo ambiente personalizzato nell'area di lavoro:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
pipeline_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults pipeline",
tags={"scikit-learn": "0.24.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
version="0.2.0",
)
pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
print(
f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
)
Creare la pipeline di training
Dopo aver creato tutti gli asset necessari per eseguire la pipeline, è il momento di creare la pipeline stessa.
Le pipeline di Azure Machine Learning sono flussi di lavoro di ML riutilizzabili che in genere sono costituiti da diversi componenti. La vita tipica di un componente è:
- Scrivere la specifica yaml del componente o crearlo a livello di codice usando
ComponentMethod. - Facoltativamente, registrare il componente con un nome e una versione nell'area di lavoro per renderlo riutilizzabile e condivisibile.
- Caricare il componente dal codice della pipeline.
- Implementare la pipeline usando gli input, gli output e i parametri del componente.
- Inviare la pipeline.
Esistono due modi per creare un componente, con una definizione a livello di codice e con una definizione YAML. Le due sezioni successive illustrano in modo dettagliato entrambe le modalità per la creazione di un componente. È possibile creare i due componenti provando entrambe le opzioni o scegliere il metodo preferito.
Nota
In questa esercitazione per semplicità viene usato lo stesso ambiente di calcolo per tutti i componenti. È però possibile impostare ambienti di calcolo diversi per ogni componente, ad esempio aggiungendo una riga come train_step.compute = "cpu-cluster". Per visualizzare un esempio di creazione di una pipeline con ambienti di calcolo diversi per ogni componente, vedere la sezione sul processo della pipeline di base nell'esercitazione sulla pipeline cifar-10.
Creare il componente 1: preparazione dei dati (usando la definizione a livello di codice)
Per iniziare, creare il primo componente. Questo componente gestisce la pre-elaborazione dei dati. L'attività di pre-elaborazione viene eseguita nel file Python data_prep.py.
Creare prima di tutto una cartella di origine per il componente data_prep:
import os
data_prep_src_dir = "./components/data_prep"
os.makedirs(data_prep_src_dir, exist_ok=True)
Questo script esegue la semplice attività di dividere i dati in set di dati di training e test. Azure Machine Learning monta i set di dati come cartelle nelle risorse di calcolo, pertanto è stata creata una funzione ausiliaria select_first_file per accedere al file di dati all'interno della cartella di input montata.
Viene usato MLFlow per registrare i parametri e le metriche durante l'esecuzione della pipeline.
%%writefile {data_prep_src_dir}/data_prep.py
import os
import argparse
import pandas as pd
from sklearn.model_selection import train_test_split
import logging
import mlflow
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
credit_train_df, credit_test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
# output paths are mounted as folder, therefore, we are adding a filename to the path
credit_train_df.to_csv(os.path.join(args.train_data, "data.csv"), index=False)
credit_test_df.to_csv(os.path.join(args.test_data, "data.csv"), index=False)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Ora che si dispone di uno script in grado di eseguire l'attività desiderata, creare un componente di Azure Machine Learning.
Usare l'oggetto CommandComponent per utilizzo generico che può eseguire azioni della riga di comando. Questa azione della riga di comando può chiamare direttamente comandi di sistema o eseguire uno script. Gli input/output si specificano nella riga di comando tramite la notazione ${{ ... }}.
from azure.ai.ml import command
from azure.ai.ml import Input, Output
data_prep_component = command(
name="data_prep_credit_defaults",
display_name="Data preparation for training",
description="reads a .xl input, split the input to train and test",
inputs={
"data": Input(type="uri_folder"),
"test_train_ratio": Input(type="number"),
},
outputs=dict(
train_data=Output(type="uri_folder", mode="rw_mount"),
test_data=Output(type="uri_folder", mode="rw_mount"),
),
# The source folder of the component
code=data_prep_src_dir,
command="""python data_prep.py \
--data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} \
--train_data ${{outputs.train_data}} --test_data ${{outputs.test_data}} \
""",
environment=f"{pipeline_job_env.name}:{pipeline_job_env.version}",
)
Facoltativamente, registrare il componente nell'area di lavoro per il riutilizzo futuro.
# Now we register the component to the workspace
data_prep_component = ml_client.create_or_update(data_prep_component.component)
# Create (register) the component in your workspace
print(
f"Component {data_prep_component.name} with Version {data_prep_component.version} is registered"
)
Creare il componente 2: training (usando la definizione YAML)
Il secondo componente creato utilizza i dati di training e test, esegue il training di un modello basato su albero e restituisce il modello di output. Usare le funzionalità di registrazione di Azure Machine Learning per registrare e visualizzare lo stato di avanzamento dell'apprendimento.
È stata usata la classe CommandComponent per creare il primo componente. Questa volta si userà la definizione YAML per definire il secondo componente. Ogni metodo ha i suoi vantaggi. Una definizione YAML può essere archiviata insieme al codice e offrirebbe un monitoraggio della cronologia leggibile. Il metodo a livello di codice mediante CommandComponent può essere più semplice con la documentazione relativa alla classe integrata e il completamento del codice.
Creare la directory per questo componente:
import os
train_src_dir = "./components/train"
os.makedirs(train_src_dir, exist_ok=True)
Creare lo script di training nella directory:
%%writefile {train_src_dir}/train.py
import argparse
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
import os
import pandas as pd
import mlflow
def select_first_file(path):
"""Selects first file in folder, use under assumption there is only one file in folder
Args:
path (str): path to directory or file to choose
Returns:
str: full path of selected file
"""
files = os.listdir(path)
return os.path.join(path, files[0])
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
os.makedirs("./outputs", exist_ok=True)
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
parser.add_argument("--model", type=str, help="path to model file")
args = parser.parse_args()
# paths are mounted as folder, therefore, we are selecting the file from folder
train_df = pd.read_csv(select_first_file(args.train_data))
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# paths are mounted as folder, therefore, we are selecting the file from folder
test_df = pd.read_csv(select_first_file(args.test_data))
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.model, "trained_model"),
)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Come si può notare nello script di training, una volta eseguito il training del modello, il file del modello viene salvato e registrato nell'area di lavoro. È ora possibile usare il modello registrato negli endpoint di inferenza.
Per l'ambiente di questo passaggio si usa uno degli ambienti predefiniti (curati) di Azure Machine Learning. Il tag azureml indica al sistema di cercare il nome negli ambienti curati.
Creare prima di tutto il file YAML che descrive il componente:
%%writefile {train_src_dir}/train.yml
# <component>
name: train_credit_defaults_model
display_name: Train Credit Defaults Model
# version: 1 # Not specifying a version will automatically update the version
type: command
inputs:
train_data:
type: uri_folder
test_data:
type: uri_folder
learning_rate:
type: number
registered_model_name:
type: string
outputs:
model:
type: uri_folder
code: .
environment:
# for this step, we'll use an AzureML curate environment
azureml://registries/azureml/environments/sklearn-1.0/labels/latest
command: >-
python train.py
--train_data ${{inputs.train_data}}
--test_data ${{inputs.test_data}}
--learning_rate ${{inputs.learning_rate}}
--registered_model_name ${{inputs.registered_model_name}}
--model ${{outputs.model}}
# </component>
Ora creare e registrare il componente. La registrazione consente di riutilizzare il componente in altre pipeline. Inoltre, chiunque altro abbia accesso all'area di lavoro potrà usare il componente registrato.
# importing the Component Package
from azure.ai.ml import load_component
# Loading the component from the yml file
train_component = load_component(source=os.path.join(train_src_dir, "train.yml"))
# Now we register the component to the workspace
train_component = ml_client.create_or_update(train_component)
# Create (register) the component in your workspace
print(
f"Component {train_component.name} with Version {train_component.version} is registered"
)
Creare la pipeline dai componenti
Ora che entrambi i componenti sono stati definiti e registrati, è possibile iniziare a implementare la pipeline.
Qui si usano i dati di input, il rapporto di divisione e il nome del modello registrato come variabili di input. Chiamare quindi i componenti e connetterli tramite gli identificatori di input/output. È possibile accedere agli output di ogni passaggio tramite la proprietà .outputs.
Le funzioni Python restituite da load_component() funzionano come qualsiasi normale funzione Python usata all'interno di una pipeline per chiamare ogni passaggio.
Per scrivere il codice della pipeline si usa uno specifico elemento Decorator @dsl.pipeline che identifica le pipeline di Azure Machine Learning. Nell'elemento Decorator è possibile specificare la descrizione della pipeline e le risorse predefinite, ad esempio ambiente di calcolo e archiviazione. Come le funzioni Python, le pipeline possono avere input. È quindi possibile creare più istanze di una singola pipeline con input diversi.
Qui sono stati usati i dati di input, il rapporto di divisione e il nome del modello registrato come variabili di input. I componenti vengono quindi chiamati e connessi tramite i relativi identificatori di input/output. È possibile accedere agli output di ogni passaggio tramite la proprietà .outputs.
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
from azure.ai.ml import dsl, Input, Output
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E data_perp-train pipeline",
)
def credit_defaults_pipeline(
pipeline_job_data_input,
pipeline_job_test_train_ratio,
pipeline_job_learning_rate,
pipeline_job_registered_model_name,
):
# using data_prep_function like a python call with its own inputs
data_prep_job = data_prep_component(
data=pipeline_job_data_input,
test_train_ratio=pipeline_job_test_train_ratio,
)
# using train_func like a python call with its own inputs
train_job = train_component(
train_data=data_prep_job.outputs.train_data, # note: using outputs from previous step
test_data=data_prep_job.outputs.test_data, # note: using outputs from previous step
learning_rate=pipeline_job_learning_rate, # note: using a pipeline input as parameter
registered_model_name=pipeline_job_registered_model_name,
)
# a pipeline returns a dictionary of outputs
# keys will code for the pipeline output identifier
return {
"pipeline_job_train_data": data_prep_job.outputs.train_data,
"pipeline_job_test_data": data_prep_job.outputs.test_data,
}
Usare ora la definizione della pipeline per creare un'istanza di una pipeline con il set di dati, il rapporto di divisione scelto e il nome scelto per il modello.
registered_model_name = "credit_defaults_model"
# Let's instantiate the pipeline with the parameters of our choice
pipeline = credit_defaults_pipeline(
pipeline_job_data_input=Input(type="uri_file", path=credit_data.path),
pipeline_job_test_train_ratio=0.25,
pipeline_job_learning_rate=0.05,
pipeline_job_registered_model_name=registered_model_name,
)
Inviare il processo
È ora possibile inviare il processo per l'esecuzione in Azure Machine Learning. Questa volta si userà create_or_update in ml_client.jobs.
Qui si passa anche un nome dell'esperimento. Un esperimento è un contenitore per tutte le iterazioni eseguite in un determinato progetto. Tutti i processi inviati con lo stesso nome dell'esperimento verranno elencati uno accanto all'altro nello studio di Azure Machine Learning.
Al termine, la processo registra un modello nell'area di lavoro come risultato del training.
# submit the pipeline job
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_registered_components",
)
ml_client.jobs.stream(pipeline_job.name)
È possibile tenere traccia dello stato di avanzamento della pipeline usando il collegamento generato nella cella precedente. Quando si seleziona questo collegamento per la prima volta, è possibile che la pipeline sia ancora in esecuzione. Al termine, è possibile esaminare i risultati di ogni componente.
Fare doppio clic sul componente Train Credit Defaults Model.
Esistono due risultati importanti da visualizzare sul training:
Visualizzare i log:
- Selezionare la scheda Output e log.
- Aprire le cartelle per arrivare a
user_logs>std_log.txtQuesta sezione mostra lo stdout dell'esecuzione dello script.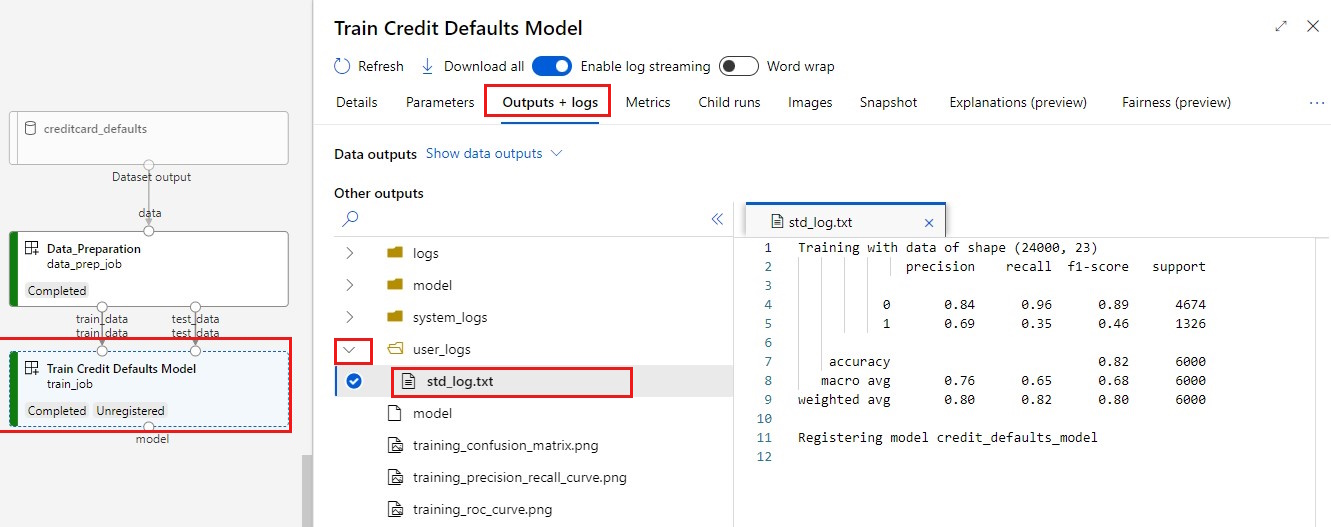
Visualizzare le metriche: selezionare la scheda Metriche. Questa sezione mostra le diverse metriche registrate. In questo esempio, mlflow
autologging, ha registrato automaticamente le metriche di training.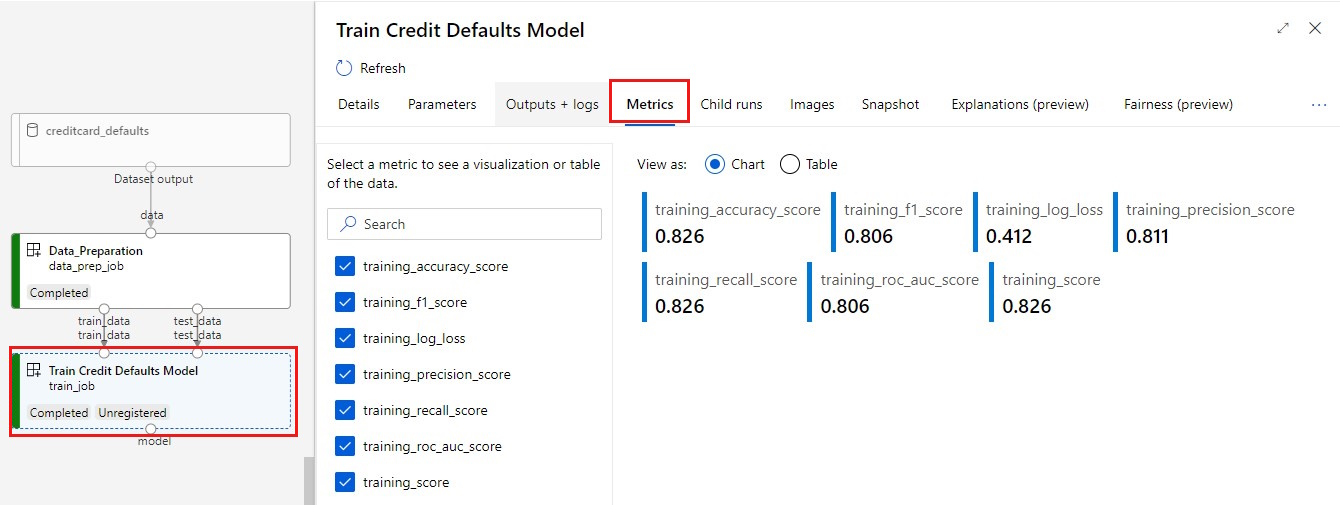


Distribuire il modello come endpoint online
Per informazioni su come distribuire il modello in un endpoint online, vedere l'esercitazione Distribuire un modello come endpoint online.
Pulire le risorse
Se si prevede di continuare con altre esercitazioni, procedere direttamente a Passaggi successivi.
Arrestare l'istanza di ambiente di calcolo
Se non si prevede di usare subito l'istanza di ambiente di calcolo, arrestarla:
- Nell'area di spostamento a sinistra nello studio selezionare Ambiente di calcolo.
- Nelle schede in alto selezionare Istanze di ambiente di calcolo
- Selezionare l'istanza di ambiente di calcolo nell'elenco.
- Sulla barra degli strumenti in alto selezionare Arresta.
Eliminare tutte le risorse
Importante
Le risorse create possono essere usate come prerequisiti per altre esercitazioni e procedure dettagliate per Azure Machine Learning.
Se le risorse create non servono più, eliminarle per evitare addebiti:
Nella casella di ricerca della portale di Azure immettere Gruppi di risorse e selezionarlo nei risultati.
Nell'elenco selezionare il gruppo di risorse creato.
Nella pagina Panoramica selezionare Elimina gruppo di risorse.
Immettere il nome del gruppo di risorse. Quindi seleziona Elimina.
Passaggi successivi
Informazioni su come Pianificare i processi della pipeline di Machine Learning