Modificare la composizione dei risultati della ricerca in Ricerca di intelligenza artificiale di Azure
Questo articolo illustra la composizione dei risultati della ricerca e come modellare i risultati della ricerca in base agli scenari. I risultati della ricerca vengono restituiti in una risposta di query. La forma di una risposta è determinata dai parametri nella query stessa. Questi parametri includono:
- Numero di corrispondenze trovate nell'indice (
count) - Numero di corrispondenze restituite nella risposta (50 per impostazione predefinita, configurabile tramite
top) o per pagina (skipetop) - Punteggio di ricerca per ogni risultato, usato per la classificazione (
@search.score) - Campi inclusi nei risultati della ricerca (
select) - Logica di ordinamento (
orderby) - Evidenziazione dei termini all'interno di un risultato, corrispondenza per l'intero termine o parziale nel corpo
- Elementi facoltativi del ranker semantico (
answersnella parte superiore,captionsper ogni corrispondenza)
I risultati della ricerca possono includere campi di primo livello, ma la maggior parte della risposta è costituita dai documenti corrispondenti in una matrice.
Client e API per la definizione della risposta alla query
È possibile usare i client seguenti per configurare una risposta di query:
- Esplora ricerche nella portale di Azure, usando la visualizzazione JSON in modo da poter specificare qualsiasi parametro supportato
- Documenti - POST (API REST)
- Metodo SearchClient.Search (Azure SDK per .NET)
- Metodo SearchClient.Search (Azure SDK per Python)
- Metodo SearchClient.Search (Azure per JavaScript)
- Metodo SearchClient.Search (Azure per Java)
Composizione dei risultati
I risultati sono principalmente tabulari, costituiti da campi di tutti i retrievable campi o limitati solo a tali campi specificati nel select parametro . Le righe sono i documenti corrispondenti, in genere classificati in ordine di pertinenza, a meno che la logica della query non impedisca la classificazione della pertinenza.
È possibile scegliere quali campi si trovano nei risultati della ricerca. Anche se un documento di ricerca potrebbe avere un numero elevato di campi, in genere sono necessari solo alcuni per rappresentare ogni documento nei risultati. In una richiesta di query aggiungere select=<field list> per specificare i retrievable campi da visualizzare nella risposta.
Selezionare i campi che offrono contrasto e differenziazione tra i documenti, fornendo informazioni sufficienti per invitare una risposta click-through da parte dell'utente. In un sito di e-commerce potrebbe trattarsi di un nome di prodotto, una descrizione, un marchio, un colore, una dimensione, un prezzo e una valutazione. Per l'indice hotels-sample predefinito, potrebbe trattarsi dei campi "select" nell'esempio seguente:
POST /indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City",
"count": true
}
Suggerimenti per risultati imprevisti
In alcuni casi, l'output delle query non è quello che si prevede di vedere. Ad esempio, si potrebbe notare che alcuni risultati sembrano essere duplicati o un risultato che dovrebbe essere visualizzato vicino alla parte superiore è posizionato più in basso nei risultati. Quando i risultati delle query sono imprevisti, è possibile provare queste modifiche alle query per verificare se i risultati migliorano:
Cambiare
searchMode=any(predefinito) insearchMode=allper richiedere corrispondenze su tutti i criteri e non su alcuni. Questo è particolarmente vero quando gli operatori booleani sono inclusi nella query.Sperimentare diversi analizzatori lessicali o analizzatori personalizzati per verificare se cambia il risultato della query. L'analizzatore predefinito suddivide le parole sillabate e riduce le parole alle forme radice, migliorando in genere l'affidabilità di una risposta di query. Tuttavia, se è necessario mantenere i trattini o se le stringhe includono caratteri speciali, potrebbe essere necessario configurare analizzatori personalizzati per assicurarsi che l'indice contenga token nel formato corretto. Per ulteriori informazioni vedere Ricerca e modelli di termini parziali con caratteri speciali (trattini, caratteri jolly, espressione regolare, criteri).
Conteggio delle corrispondenze
Il count parametro restituisce il numero di documenti nell'indice considerati una corrispondenza per la query. Per restituire il conteggio, aggiungere count=true alla richiesta di query. Non esiste alcun valore massimo imposto dal servizio di ricerca. A seconda della query e del contenuto dei documenti, il conteggio può essere elevato come ogni documento nell'indice.
Il conteggio è accurato quando l'indice è stabile. Se il sistema aggiunge, aggiorna o elimina attivamente documenti, il conteggio è approssimativo, escluso tutti i documenti che non sono completamente indicizzati.
Il conteggio non sarà interessato dalla manutenzione di routine o da altri carichi di lavoro nel servizio di ricerca. Tuttavia, se si dispone di più partizioni e una singola replica, è possibile riscontrare fluttuazioni a breve termine nel conteggio dei documenti (alcuni minuti) quando le partizioni vengono riavviate.
Suggerimento
Per controllare le operazioni di indicizzazione, è possibile verificare se l'indice contiene il numero previsto di documenti aggiungendo count=true in una query di ricerca search=* vuota. Il risultato è il conteggio completo dei documenti nell'indice.
Quando si testa la sintassi delle query count=true è possibile indicare rapidamente se le modifiche restituiscono risultati maggiori o minori, che possono essere utili feedback.
Numero di risultati nella risposta
Ricerca di intelligenza artificiale di Azure usa il paging lato server per impedire alle query di recuperare troppi documenti contemporaneamente. I parametri di query che determinano il numero di risultati in una risposta sono top e skip. top fa riferimento al numero di risultati della ricerca in una pagina. skip è un intervallo di e indica al motore di topricerca il numero di risultati da ignorare prima di ottenere il set successivo.
La dimensione predefinita della pagina è 50, mentre la dimensione massima della pagina è 1.000. Se si specifica un valore maggiore di 1.000 e sono presenti più di 1.000 risultati nell'indice, vengono restituiti solo i primi 1.000 risultati. Se il numero di corrispondenze supera le dimensioni della pagina, la risposta include informazioni per recuperare la pagina successiva dei risultati. Ad esempio:
"@odata.nextLink": "https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01"
Le corrispondenze principali sono determinate dal punteggio di ricerca, presupponendo che la query sia una ricerca full-text o semantica. In caso contrario, le corrispondenze principali sono un ordine arbitrario per le query di corrispondenza esatte (dove uniform @search.score=1.0 indica una classificazione arbitraria).
Impostare top per eseguire l'override del valore predefinito 50. Nelle API di anteprima più recenti, se si usa una query ibrida, è possibile specificare maxTextRecallSize per restituire fino a 10.000 documenti.
Per controllare il paging di tutti i documenti restituiti in un set di risultati, utilizzare top e skip insieme. Questa query restituisce il primo set di 15 documenti corrispondenti più un conteggio delle corrispondenze totali.
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 0
}
Questa query restituisce il secondo set, ignorando il primo 15 per ottenere il successivo 15 (da 16 a 30):
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 15
}
Non è garantito che i risultati delle query impaginate siano stabili se l'indice sottostante viene modificato. Il paging modifica il valore di skip per ogni pagina, ma ogni query è indipendente e opera sulla visualizzazione corrente dei dati così come esiste nell'indice in fase di query (in altre parole, non esiste alcuna memorizzazione nella cache o snapshot dei risultati, ad esempio quelli presenti in un database per utilizzo generico).
Di seguito è riportato un esempio di come si potrebbero ottenere duplicati. Si supponga che un indice con quattro documenti:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
Si supponga ora di voler ottenere i risultati restituiti due alla volta, ordinati in base alla classificazione. Eseguire questa query per ottenere la prima pagina dei risultati: $top=2&$skip=0&$orderby=rating desc, che produce i risultati seguenti:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
Nel servizio si supponga che un quinto documento venga aggiunto all'indice tra le chiamate di query: { "id": "5", "rating": 4 }. Successivamente, si esegue una query per recuperare la seconda pagina:$top=2&$skip=2&$orderby=rating desc, e ottenere questi risultati:
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
Si noti che il documento 2 viene recuperato due volte. Questo perché il nuovo documento 5 ha un valore maggiore per la classificazione, quindi ordina prima del documento 2 e si trova nella prima pagina. Anche se questo comportamento potrebbe essere imprevisto, è tipico del comportamento di un motore di ricerca.
Paging in un numero elevato di risultati
Una tecnica alternativa per il paging consiste nell'usare un ordinamento e un filtro di intervallo come soluzione alternativa per skip.
In questa soluzione alternativa, l'ordinamento e il filtro vengono applicati a un campo ID documento o a un altro campo univoco per ogni documento. Il campo univoco deve avere le attribuzioni filterable e sortable nell'indice di ricerca.
Eseguire una query per restituire una pagina completa di risultati ordinati.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc" }Scegliere l'ultimo risultato restituito dalla query di ricerca. Di seguito è riportato un risultato di esempio con solo un valore ID.
{ "id": "50" }Usare tale valore ID in una query di intervallo per recuperare la pagina successiva dei risultati. Questo campo ID deve avere valori univoci. In caso contrario, la paginazione potrebbe includere risultati duplicati.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }L'impaginazione termina quando la query restituisce zero risultati.
Nota
Gli filterable attributi e sortable possono essere abilitati solo quando un campo viene aggiunto per la prima volta a un indice, non possono essere abilitati in un campo esistente.
Ordinamento dei risultati
In una query di ricerca a testo pieno i risultati possono essere classificati in base a:
- un punteggio di ricerca
- un punteggio di reranker semantico
- un ordinamento in un
sortablecampo
È anche possibile aumentare le corrispondenze trovate in campi specifici aggiungendo un profilo di punteggio.
Ordina per punteggio di ricerca
Per le query di ricerca full-text, i risultati vengono classificati automaticamente in base a un punteggio di ricerca usando un algoritmo BM25, calcolato in base alla frequenza dei termini, alla lunghezza del documento e alla lunghezza media del documento.
L'intervallo @search.score non è associato o 0 fino a (ma non incluso) 1,00 nei servizi meno recenti.
Per entrambi gli algoritmi, un @search.score valore uguale a 1,00 indica un set di risultati senza caratteri di sottolineatura o non classificati, in cui il punteggio 1,0 è uniforme in tutti i risultati. I risultati senza punteggio si verificano in caso di una query di ricerca fuzzy, con caratteri jolly, di espressione regolare o una ricerca vuota (search=*). Se è necessario imporre una struttura di classificazione sui risultati senza caratteri di sottolineatura, prendere in considerazione un'espressione orderby per raggiungere tale obiettivo.
Ordine in base al reranker semantico
Se si usa il ranker semantico, determina @search.rerankerScore l'ordinamento dei risultati.
L'intervallo @search.rerankerScore è compreso tra 1 e 4,00, dove un punteggio più alto indica una corrispondenza semantica più forte.
Ordine con orderby
Se l'ordinamento coerente è un requisito dell'applicazione, è possibile definire un'orderbyespressione in un campo. Solo i campi indicizzati come "ordinabili" possono essere usati per ordinare i risultati.
Campi comunemente usati in un orderby includono classificazione, data e posizione. Per filtrare in base alla posizione, è necessario che l'espressione di filtro chiami la geo.distance() funzione, oltre al nome del campo.
I campi numerici (Edm.Double, Edm.Int32, Edm.Int64) vengono ordinati in ordine numerico (ad esempio, 1, 2, 10, 11, 20).
I campi stringa (Edm.String, sottocampi) vengono ordinati in base all'ordinamento ASCII o all'ordinamento Unicode, a seconda della Edm.ComplexType lingua.
Il contenuto numerico nei campi stringa viene ordinato alfabeticamente (1, 10, 11, 2, 20).
Le stringhe maiuscole vengono ordinate in anticipo (MELA, Mela, BANANA, Banana, mela, banana). È possibile assegnare un normalizzatore di testo per pre-elaborare il testo prima dell'ordinamento per modificare questo comportamento. L'uso del tokenizzatore minuscolo in un campo non ha alcun effetto sul comportamento di ordinamento perché Ricerca intelligenza artificiale di Azure ordina in una copia nonanalyzed del campo.
Le stringhe con segni diacritici appaiono per ultimo (Äpfel, Öffnen, Üben)
Aumentare la pertinenza usando un profilo di punteggio
Un altro approccio che promuove la coerenza degli ordini consiste nell'usare un profilo di punteggio personalizzato. I profili di punteggio offrono un maggiore controllo sulla classificazione degli elementi nei risultati della ricerca, con la possibilità di aumentare le corrispondenze trovate in campi specifici. La logica di assegnazione dei punteggi aggiuntiva consente di ignorare le piccole differenze tra le repliche perché i punteggi di ricerca per ogni documento sono più distanti. Per questo approccio è consigliabile usare l'algoritmo di classificazione.
Evidenziazione dei risultati
L'evidenziazione dei risultati fa riferimento alla formattazione del testo (ad esempio evidenziazione grassetto o giallo) applicata ai termini corrispondenti in un risultato, rendendo più semplice individuare la corrispondenza. L'evidenziazione è utile per campi di contenuto più lunghi, ad esempio un campo di descrizione, in cui la corrispondenza non è immediatamente ovvia.
Si noti che l'evidenziazione viene applicata ai singoli termini. Non esiste alcuna funzionalità di evidenziazione per il contenuto di un intero campo. Se si desidera evidenziare una frase, è necessario specificare i termini corrispondenti (o la frase) in una stringa di query racchiusa tra virgolette. Questa tecnica è descritta più avanti in questa sezione.
Le istruzioni di evidenziazione dei risultati vengono fornite nella richiesta di query. Le query che attivano l'espansione delle query nel motore, ad esempio la ricerca fuzzy e con caratteri jolly, hanno un supporto limitato per l'evidenziazione dei risultati.
Requisiti per l'evidenziazione dei riscontri
- I campi devono essere
Edm.StringoCollection(Edm.String) - I campi devono essere attribuiti in
searchable
Specificare l'evidenziazione nella richiesta
Per restituire i termini evidenziati, includere il parametro di evidenziazione nella richiesta di query. Il parametro è impostato su un elenco delimitato da virgole di campi.
Per impostazione predefinita, il formato di markup è <em>; tuttavia, è possibile eseguire l'override del tag usando i parametri highlightPreTag e highlightPostTag. Il codice client gestisce la risposta, ad esempio applicando un carattere in grassetto o uno sfondo giallo.
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
Per impostazione predefinita, Azure AI Search restituisce fino a cinque evidenziazioni per campo. È possibile modificare questo numero aggiungendo un trattino seguito da un numero intero. Ad esempio, "highlight": "description-10" restituisce fino a 10 termini evidenziati per la corrispondenza del contenuto nel campo della descrizione.
Risultati evidenziati
Quando l'evidenziazione viene aggiunta alla query, la risposta include un oggetto @search.highlights per ogni risultato in modo che il codice dell'applicazione possa essere destinato a tale struttura. L'elenco dei campi specificati per "highlight" è incluso nella risposta.
In una ricerca di parole chiave, ogni termine viene analizzato in modo indipendente. Una query per "segreti divini" restituisce corrispondenze in qualsiasi documento contenente uno dei due termini.
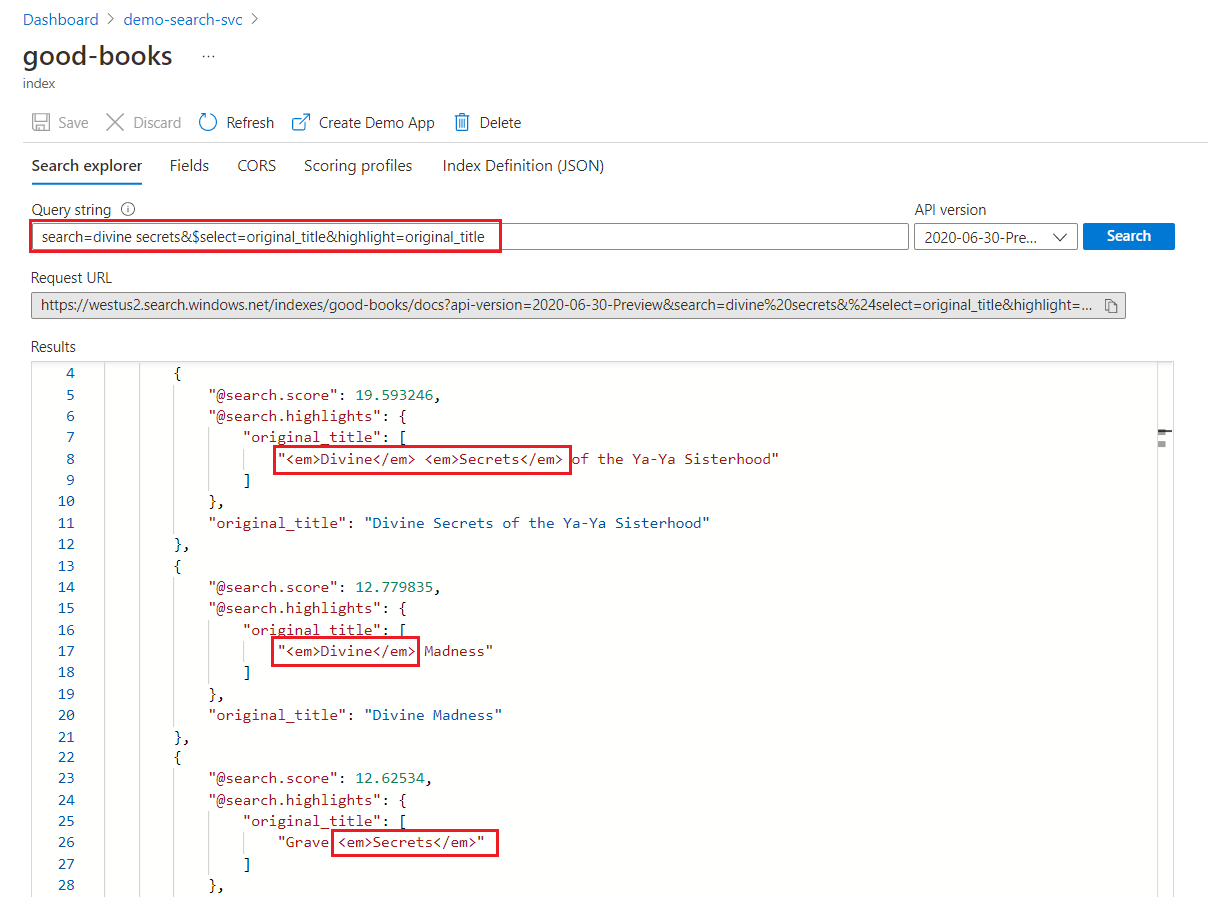
Evidenziazione della ricerca di parole chiave
All'interno di un campo evidenziato, la formattazione viene applicata a termini interi. Ad esempio, in una corrispondenza contro "I segreti divini della sorellanza Ya-Ya", la formattazione viene applicata a ogni termine separatamente, anche se sono consecutivi.
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
Evidenziazione della ricerca di frasi
La formattazione di interi termini si applica anche in una ricerca di frasi, in cui più termini sono racchiusi tra virgolette doppie. L'esempio seguente è la stessa query, ad eccezione del fatto che "segreti divini" viene inviato come frase racchiusa tra virgolette (alcuni client REST richiedono che le virgolette interne vengano precedute da una barra rovesciata \"):
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "\"divine secrets\"",
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
Poiché i criteri hanno ora entrambi i termini, nell'indice di ricerca viene trovata una sola corrispondenza. La risposta alla query precedente è simile alla seguente:
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
Evidenziazione di frasi nei servizi meno recenti
I servizi di ricerca creati prima del 15 luglio 2020 implementano un'esperienza di evidenziazione diversa per le query di frasi.
Per gli esempi seguenti, si supponga che una stringa di query che includa la frase racchiusa tra virgolette "super bowl". Prima di luglio 2020, qualsiasi termine nella frase è evidenziato:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
Per i servizi di ricerca creati dopo luglio 2020, vengono restituite solo frasi che corrispondono alla query di frase completa in @search.highlights:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
Passaggi successivi
Per generare rapidamente una pagina di ricerca per il client, prendere in considerazione queste opzioni:
Creare un'app demo, nella portale di Azure, crea una pagina HTML con una barra di ricerca, una navigazione in base a facet e un'area di anteprima se sono presenti immagini.
Aggiungi ricerca a un'app ASP.NET Core (MVC) è un'esercitazione e un esempio di codice che compila un client funzionale.
Aggiungere la ricerca alle app Web è un'esercitazione e un esempio di codice C# che usa le librerie JavaScript React per l'esperienza utente. L'app viene distribuita usando App Web statiche di Azure e implementa la paginazione.