Eseguire query sui file Delta Lake (v1) usando il pool SQL serverless in Azure Synapse Analytics
In questo articolo verrà spiegato come scrivere una query usando il pool Synapse SQL serverless per leggere file Delta Lake. Delta Lake è un livello di archiviazione open source che consente di usare transazioni ACID (Atomicity, Consistency, Isolation And Durability, ovvero atomicità, coerenza, isolamento e durabilità) in Apache Spark e nei carichi di lavoro di Big Data. Per altre informazioni, guardare il video su come eseguire query su tabelle Delta Lake.
Importante
I pool SQL serverless possono eseguire query su Delta Lake versione 1.0. Le modifiche introdotte dalla versione Delta Lake 1.2 , ad esempio la ridenominazione delle colonne, non sono supportate in serverless. Se si usano le versioni successive di Delta con vettori di eliminazione, checkpoint v2 e altri, è consigliabile usare altri motori di query come l'endpoint SQL di Microsoft Fabric per Lakehouse.
Il pool SQL serverless nell'area di lavoro di Synapse consente di leggere i dati archiviati in formato Delta Lake e di usarli per gli strumenti di creazione di report. Un pool SQL serverless può leggere i file Delta Lake creati usando Apache Spark, Azure Databricks o qualsiasi altro producer del formato Delta Lake.
I pool di Apache Spark in Azure Synapse consentono agli ingegneri dei dati di modificare i file Delta Lake usando Scala, PySpark e .NET. I pool SQL serverless consentono agli analisti dei dati di creare report sui file Delta Lake creati dagli ingegneri dei dati.
Importante
L'esecuzione di query in formato Delta Lake con il pool SQL serverless rappresenta una funzionalità disponibile a livello generale. Tuttavia, l'esecuzione di query sulle tabelle Spark Delta è ancora una funzionalità disponibile in anteprima pubblica e non è pronta per ambienti di produzione. Se si eseguono query su tabelle Delta create usando i pool di Spark, potrebbero verificarsi problemi noti. Vedere i problemi noti in Supporto self-help per il pool SQL serverless.
Esempio di avvio rapido
La funzione OPENROWSET consente di leggere il contenuto dei file Delta Lake fornendo l'URL alla cartella radice.
Leggere la cartella Delta Lake
Il modo più semplice per visualizzare il contenuto del file DELTA consiste nel fornire l'URL del file alla funzione OPENROWSET e specificare il formato DELTA. Se il file è disponibile pubblicamente o se l'identità di Microsoft Entra può accedere a questo file, dovrebbe essere possibile visualizzare il contenuto del file usando una query simile a quella illustrata nell'esempio seguente:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/delta-lake/covid/',
FORMAT = 'delta') as rows;
I nomi e i tipi di dati delle colonne vengono letti automaticamente dai file Delta Lake. La funzione OPENROWSET usa i tipi più adatti, ad esempio VARCHAR(1000) per le colonne stringa.
L'URI nella funzione OPENROWSET deve fare riferimento alla cartella radice Delta Lake che contiene una sottocartella denominata _delta_log.
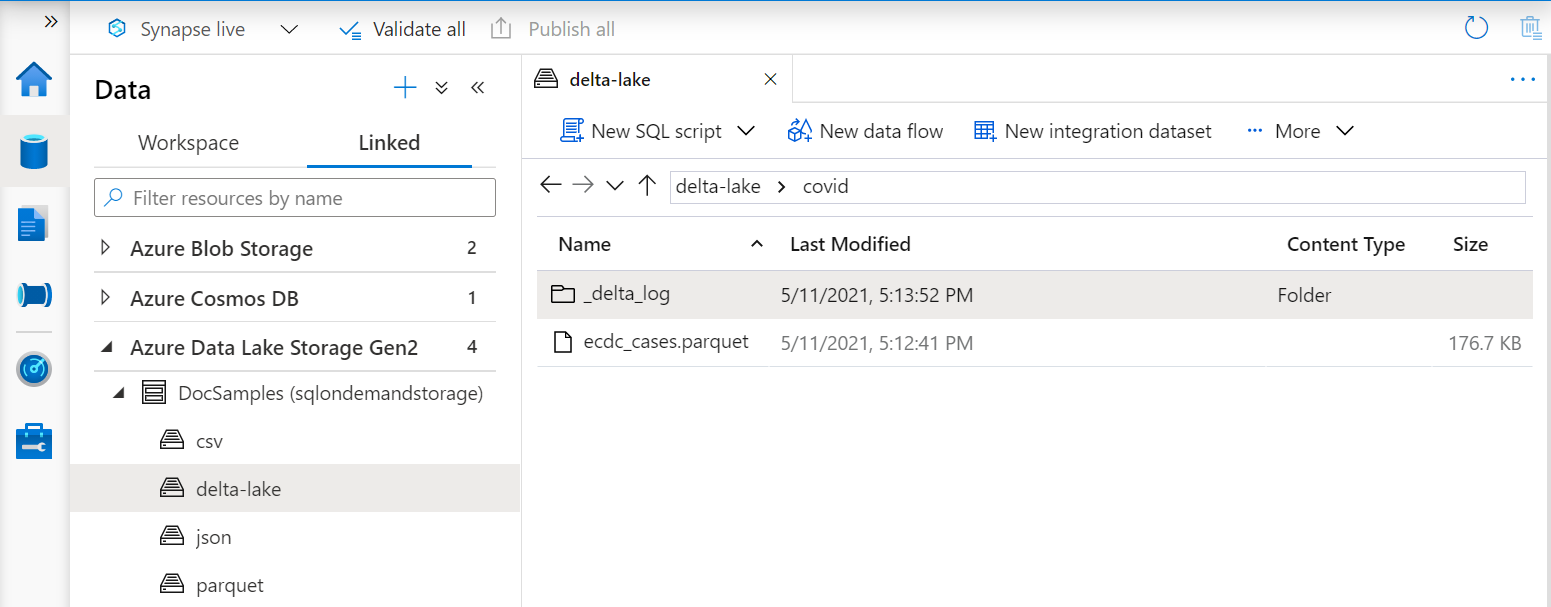
Se questa sottocartella non è disponibile, non si usa il formato Delta Lake. È possibile convertire in formato Delta Lake i file Parquet semplici presenti nella cartella usando lo script Python di Apache Spark seguente:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
Per migliorare le prestazioni delle query, è consigliabile specificare tipi espliciti nella clausola WITH.
Nota
Il pool Synapse SQL serverless usa l'inferenza dello schema per determinare automaticamente le colonne e i relativi tipi. Le regole per l'inferenza dello schema sono le stesse usate per i file Parquet. Per il mapping dei tipi Delta Lake al tipo nativo SQL, vedere il mapping dei tipi per Parquet.
Assicurarsi di poter accedere al file. Se il file è protetto con chiave di firma di accesso condiviso o identità di Azure personalizzata, è necessario configurare le credenziali a livello di server per l'account di accesso SQL.
Importante
Assicurarsi di usare regole di confronto del database UTF-8 (ad esempio Latin1_General_100_BIN2_UTF8) perché i valori stringa nei file Delta Lake vengono codificati usando la codifica UTF-8.
Una mancata corrispondenza tra la codifica del testo nel file Delta Lake e le regole di confronto può causare errori di conversione imprevisti.
È possibile modificare facilmente le regole di confronto predefinite del database corrente usando l'istruzione T-SQL seguente: ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8;. Per altre informazioni sulle regole di confronto, vedere Tipi di regole di confronto supportati per Synapse SQL.
Utilizzo dell'origine dati
Negli esempi precedenti è stato usato il percorso completo del file. In alternativa, è possibile creare un'origine dati esterna con il percorso che punta alla cartella radice della risorsa di archiviazione. Dopo aver creato l'origine dati esterna, usare l'origine dati e il percorso relativo del file nella funzione OPENROWSET. In questo modo non è necessario usare l'URI assoluto completo dei file. È anche possibile definire credenziali personalizzate per accedere alla posizione di archiviazione.
Importante
Le origini dati possono essere create solo in database personalizzati (non nel database master o nei database replicati dai pool di Apache Spark).
Per usare gli esempi seguenti, è necessario completare il passaggio seguente:
- Creare un database con un'origine dati che faccia riferimento all'account di archiviazione per NYC Yellow Taxi.
- Inizializzare gli oggetti eseguendo uno script di configurazione sul database creato nel passaggio 1. Questo script di installazione creerà le origini dati, le credenziali con ambito database e i formati di file esterni usati in questi esempi.
Se il database è stato creato e il contesto è stato impostato sul database (usando l'istruzione USE database_name o l'elenco a discesa per la selezione del database in un editor di query), è possibile creare l'origine dati esterna contenente l'URI radice del set di dati e usarla per eseguire query sui file Delta Lake:
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://sqlondemandstorage.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
Se un'origine dati è protetta con una chiave di firma di accesso condiviso o un'identità personalizzata, è possibile configurare l'origine dati con credenziali con ambito database.
Specificare in modo esplicito lo schema
OPENROWSET consente di specificare in modo esplicito le colonne che si intende leggere dal file usando la clausola WITH:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
Con la specifica esplicita dello schema del set di risultati, è possibile ridurre al minimo le dimensioni del tipo e usare i tipi più precisi VARCHAR(6) per le colonne stringa invece di quello VARCHAR(1000). La riduzione dei tipi potrebbe migliorare significativamente le prestazioni delle query.
Importante
Assicurarsi di specificare in modo esplicito le regole di confronto UTF-8 (ad esempio Latin1_General_100_BIN2_UTF8) per tutte le colonne stringa nella clausola WITH o impostare regole di confronto UTF-8 a livello di database.
La mancata corrispondenza tra la codifica del testo nelle regole di confronto delle colonne di file e stringa potrebbe causare errori di conversione imprevisti.
È possibile cambiare facilmente regole di confronto predefinite del database corrente usando l'istruzione T-SQL seguente: alter database current collate Latin1_General_100_BIN2_UTF8 È possibile impostare facilmente le regole di confronto sui tipi di colonna usando la definizione seguente: geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8
Set di dati
In questo esempio viene usato il set di dati di NYC Yellow Taxi. Il set di dati PARQUET originale viene convertito in formato DELTA e la versione DELTA viene usata negli esempi.
Eseguire query su dati partizionati
Il set di dati usato in questo esempio è diviso (partizionato) in sottocartelle separate.
A differenza di Parquet, non è necessario indicare come destinazione partizioni specifiche usando la funzione FILEPATH. OPENROWSET identificherà le colonne di partizionamento nella struttura di cartelle Delta Lake e consentirà di eseguire query direttamente sui dati usando queste colonne. Questo esempio illustra gli importi delle tariffe per anno, mese e payment_type per i primi tre mesi del 2017.
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
La funzione OPENROWSET eliminerà le partizioni che non corrispondono ai valori di year e month nella clausola where. Questa tecnica di eliminazione di file/partizioni ridurrà significativamente il set di dati, migliorerà le prestazioni e abbasserà il costo della query.
Il nome della cartella nella funzione OPENROWSET (yellow in questo esempio) viene concatenato usando LOCATION nell'origine dati DeltaLakeStorage e deve fare riferimento alla cartella Delta Lake radice che contiene una sottocartella denominata _delta_log.
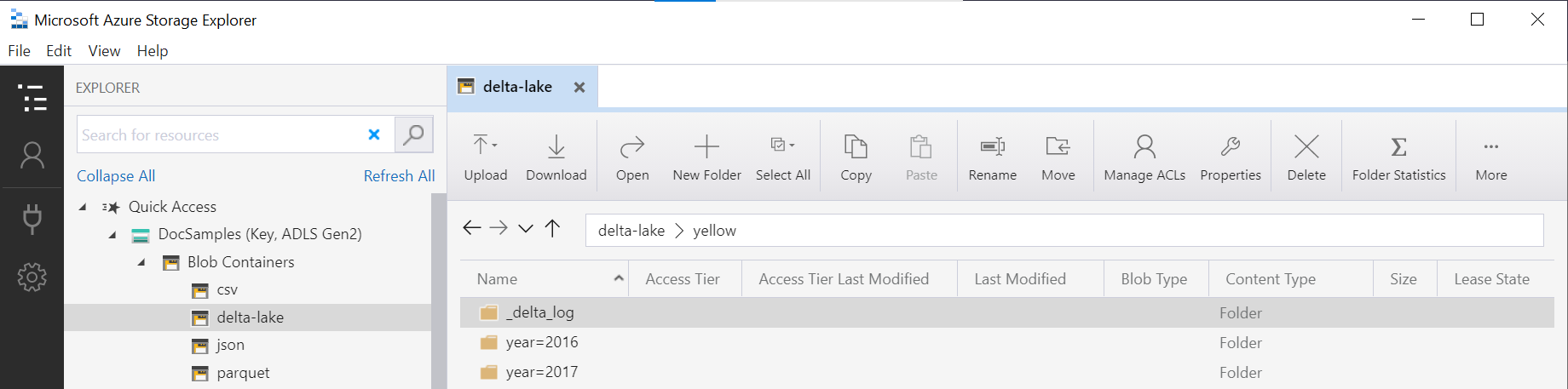
Se questa sottocartella non è disponibile, non si usa il formato Delta Lake. È possibile convertire in formato Delta Lake i file Parquet semplici presenti nella cartella usando lo script Python di Apache Spark seguente:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
Il secondo argomento della funzione DeltaTable.convertToDeltaLake rappresenta le colonne di partizionamento (anno e mese) che fanno parte dello schema della cartella (year=*/month=* in questo esempio) e i relativi tipi.
Limiti
- Esaminare le limitazioni e i problemi noti nella pagina self-help del pool SQL serverless di Synapse.
Contenuto correlato
Per informazioni su come eseguire query su tipi nidificati Parquet, passare al prossimo articolo. Se si vuole continuare a creare una soluzione Delta Lake, vedere gli articoli relativi a come creare viste o tabelle esterne nella cartella Delta Lake.