Risolvere i problemi relativi al pool SQL serverless in Azure Synapse Analytics
Questo articolo contiene informazioni su come risolvere i problemi più frequenti del pool SQL serverless in Azure Synapse Analytics.
Per altre informazioni su Azure Synapse Analytics, vedere gli argomenti in Panoramica.
Synapse Studio
Synapse Studio è uno strumento intuitivo per accedere ai dati usando un browser senza dover installare gli strumenti di accesso al database. Synapse Studio non è progettato per leggere set di dati di grandi dimensioni o per la gestione completa di oggetti SQL.
L'opzione relativa al pool SQL serverless è disattivata in Synapse Studio
Se Synapse Studio non riesce a stabilire una connessione con il pool SQL serverless, si noterà che la relativa opzione è disattivata o che lo stato visualizzato è Offline.
In genere, questo problema si verifica per uno dei due motivi seguenti:
- La rete impedisce la comunicazione con il back-end di Azure Synapse Analytics. Il caso più frequente è che la porta TCP 1443 è bloccata. Per consentire il funzionamento del pool SQL serverless, sbloccare questa porta. Anche altri problemi potrebbero impedire il funzionamento del pool SQL serverless. Per altre informazioni, vedere la guida alla risoluzione dei problemi.
- Non si hanno le autorizzazioni per accedere al pool SQL serverless. Per ottenere l'accesso, è necessario chiedere a uno degli amministratori dell'area di lavoro di Azure Synapse di essere aggiunti al ruolo di amministratore dell'area di lavoro o di amministratore di SQL. Per altre informazioni, vedere Controllo di accesso ad Azure Synapse.
Connessione WebSocket chiusa in modo imprevisto
La query potrebbe non riuscire con il messaggio di errore Websocket connection was closed unexpectedly. Questo messaggio indica che la connessione del browser a Synapse Studio è stata interrotta, ad esempio a causa di un problema di rete.
- Per risolvere questo problema, eseguire di nuovo la query.
- Provare a usare Azure Data Studio o SQL Server Management Studio per le stesse query invece di Synapse Studio per ulteriori indagini.
- Se questo messaggio si verifica spesso nell'ambiente, chiedere aiuto all'amministratore di rete. È anche possibile controllare le impostazioni del firewall e consultare la guida alla risoluzione dei problemi.
- Se il problema persiste, creare un ticket di supporto tramite il portale di Azure.
I database serverless non vengono visualizzati in Synapse Studio
Se i database creati nel pool SQL serverless non vengono visualizzati, verificare se il pool SQL serverless è stato avviato. Se il pool SQL serverless è disattivato, i database non verranno visualizzati. Eseguire una query qualsiasi, ad esempio SELECT 1, sul pool SQL serverless per attivarlo e rendere visibili i database.
Il pool SQL serverless di Synapse non è disponibile
La causa di questo comportamento è in genere una configurazione di rete non corretta. Assicurarsi che le porte siano configurate correttamente. Se si usa un firewall o endpoint privati, controllare anche queste impostazioni.
Infine, assicurarsi siano stati concessi i ruoli appropriati e che non siano stati revocati.
Non è possibile creare un nuovo database perché la richiesta usa la chiave vecchia/scaduta
Questo errore è causato dalla modifica della chiave gestita dal cliente dell'area di lavoro usata per la crittografia. È possibile scegliere di crittografare di nuovo tutti i dati nell'area di lavoro con la versione più recente della chiave attiva. Per recrittografare, sostituire la chiave nel portale di Azure con una chiave temporanea e quindi sostituirla di nuovo con la chiave da usare per la crittografia. Vedere come gestire le chiavi dell'area di lavoro.
Il pool SQL serverless di Synapse non è disponibile dopo il trasferimento di una sottoscrizione a un tenant di Microsoft Entra diverso
Se la sottoscrizione è stata spostata in un altro tenant di Microsoft Entra, potrebbero verificarsi alcuni problemi con il pool SQL serverless. Creare un ticket di supporto e si verrà contattati dal supporto tecnico di Azure per risolvere il problema.
Accesso alle risorse di archiviazione
Se si verificano errori durante il tentativo di accesso ai file in Archiviazione di Azure, assicurarsi di avere l'autorizzazione per l'accesso ai dati. Dovrebbe essere possibile accedere ai file disponibili pubblicamente. Se si tenta di accedere ai dati senza credenziali, assicurarsi che l'identità di Microsoft Entra possa accedere direttamente ai file.
Se si dispone di una chiave di firma di accesso condiviso da usare per accedere ai file, assicurarsi di aver creato credenziali a livello di server o con ambito database contenenti tale credenziale. Le credenziali sono necessarie per accedere ai dati usando l'identità gestita dell'area di lavoro e il nome dell'entità servizio (SPN) personalizzato.
Non è possibile leggere, elencare o accedere ai file in Azure Data Lake Storage
Se si usa un account di accesso di Microsoft Entra senza credenziali esplicite, assicurarsi che l'identità di Microsoft Entra possa accedere ai file nella risorsa di archiviazione. Per accedere ai file, l'identità di Microsoft Entra deve avere l'autorizzazione lettore dati dei BLOB di archiviazione oppure le autorizzazioni per Elenco e Lettura negli elenchi di controllo di accesso (ACL) in ADLS. Per altre informazioni, vedere La query non riesce perché no è possibile aprire il file.
Se si accede all'archiviazione usando credenziali, assicurarsi che l'identità gestita o il nome dell'entità servizio abbia il ruolo Lettore di dati o Collaboratore oppure autorizzazioni specifiche dell'elenco di controllo di accesso. Se è stato usato un token di firma di accesso condiviso, assicurarsi che abbia l'autorizzazione rl e che non sia scaduto.
Se si usa un account di accesso SQL e la funzione OPENROWSET senza un'origine dati, assicurarsi di avere credenziali a livello di server che corrispondano all'URI di archiviazione e di avere l'autorizzazione per accedere all'archiviazione.
La query non riesce perché non è possibile aprire il file
Se la query non riesce con l'errore File cannot be opened because it does not exist or it is used by another process e si è certi che entrambi i file esistano e non siano in uso da un altro processo, allora il pool SQL serverless non può accedere al file. Questo problema si verifica in genere perché l'identità di Microsoft Entra non ha i diritti di accesso al file o perché un firewall ne blocca l'accesso.
Per impostazione predefinita, il pool SQL serverless prova ad accedere al file usando l'identità di Microsoft Entra. Per risolvere questo problema, è necessario avere i diritti appropriati per l'accesso al file. Il modo più semplice consiste nel concedere a se stessi il ruolo Collaboratore ai dati dei BLOB di archiviazione nell'account di archiviazione su cui si prova a eseguire query.
Per altre informazioni, vedi:
- Controllo di accesso a Microsoft Entra ID per l'archiviazione
- Controllare l'accesso agli account di archiviazione per il pool SQL serverless in Azure Synapse Analytics
Alternativa al ruolo Collaboratore ai dati dei BLOB di archiviazione
Invece di concedere a se stessi il ruolo Collaboratore ai dati dei BLOB di archiviazione, è anche possibile concedere autorizzazioni più granulari su un sottoinsieme di file.
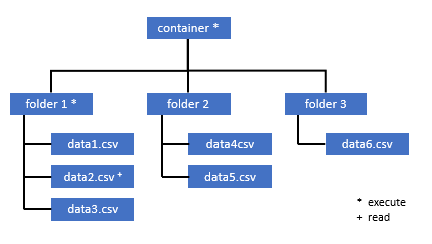
Tutti gli utenti che hanno bisogno di accedere ad alcuni dati in questo contenitore, devono avere anche l'autorizzazione EXECUTE per tutte le cartelle padre fino alla radice (il contenitore).
Vedere altre informazioni su come impostare gli elenchi di controllo di accesso in Azure Data Lake Storage Gen2.
Nota
L'autorizzazione EXECUTE a livello di contenitore deve essere impostata in Data Lake Storage Gen2. Le autorizzazioni per la cartella possono essere impostate in Azure Synapse.
Se si vogliono eseguire query su data2.csv in questo esempio, sono necessarie le autorizzazioni seguenti:
- Autorizzazione EXECUTE per il contenitore
- Autorizzazione EXECUTE per folder1
- Autorizzazione di lettura per data2.csv
Accedere ad Azure Synapse con un account utente amministratore con autorizzazioni complete per i dati ai quali si vuole accedere.
Nel riquadro dei dati fare clic con il pulsante destro del mouse sul file e scegliere Gestisci accesso.
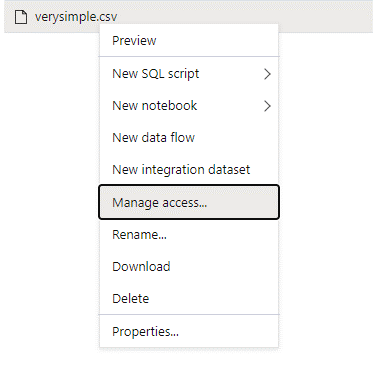
Selezionare almeno l'autorizzazione Lettura. Immettere il nome dell'entità utente o l'ID oggetto dell'utente, ad esempio,
user@contoso.com. Selezionare Aggiungi.Concedere a questo utente l'autorizzazione di lettura.

Nota
Per gli utenti guest, questo passaggio deve essere eseguito direttamente con Azure Data Lake perché non può essere eseguito direttamente tramite Azure Synapse.
Non è possibile elencare il contenuto della directory nel percorso
Questo errore indica che l'utente che esegue query su Azure Data Lake non può elencare i file nell'archiviazione. Esistono diversi scenari in cui può verificarsi questo errore:
- L'utente di Microsoft Entra che usa l'autenticazione pass-through di Microsoft Entra non ha l'autorizzazione per elencare i file in Data Lake Storage.
- L'ID Microsoft Entra o l'utente SQL che legge i dati usa una chiave di firma di accesso condiviso o un'identità gestita dell'area di lavoro e tale chiave o identità non ha l'autorizzazione per elencare i file nell'archiviazione.
- L'utente che accede ai dati di Dataverse non ha l'autorizzazione per eseguire query sui dati in Dataverse. Questo scenario può verificarsi se si usano utenti SQL.
- L'utente che accede a Delta Lake potrebbe non avere l'autorizzazione per leggere il log delle transazioni di Delta Lake.
Il modo più semplice per risolvere questo problema consiste nell'assegnare a se stessi il ruolo Collaboratore ai dati dei BLOB di archiviazione nell'account di archiviazione su cui si sta tentando di eseguire query.
Per altre informazioni, vedi:
- Controllo di accesso a Microsoft Entra ID per l'archiviazione
- Controllare l'accesso agli account di archiviazione per il pool SQL serverless in Azure Synapse Analytics
Non è possibile elencare il contenuto della tabella di Dataverse
Se si usa Collegamento ad Azure Synapse per Dataverse per leggere le tabelle di DataVerse collegate, è necessario usare l'account Microsoft Entra per accedere ai dati collegati usando il pool SQL serverless. Per altre informazioni, vedere Collegamento ad Azure Synapse per Dataverse con Azure Data Lake.
Se si tenta di usare un account di accesso SQL per leggere una tabella esterna che fa riferimento alla tabella di DataVerse, verrà visualizzato l'errore seguente: External table '???' is not accessible because content of directory cannot be listed.
Le tabelle esterne di Dataverse usano sempre l'autenticazione pass-through di Microsoft Entra. Non è possibile configurarle per l'uso di una chiave di firma di accesso condiviso o un'identità gestita dell'area di lavoro.
Non è possibile elencare il contenuto del log delle transazioni di Delta Lake
Quando il pool SQL serverless non riesce a leggere la cartella del log delle transazioni di Delta Lake, viene restituito l'errore seguente:
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
Assicurarsi che la cartella _delta_log esista. È possibile che si stiano eseguendo query su file Parquet normali non convertiti in formato Delta Lake. Se la cartella _delta_log esiste, assicurarsi di avere l'autorizzazione Lettura ed Elenco per le cartelle Delta Lake sottostanti. Provare a leggere i file JSON direttamente usando FORMAT='csv'. Inserire l'URI nel parametro BULK:
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
Se la query non riesce, il chiamante non ha l'autorizzazione per leggere i file di archiviazione sottostanti.
Esecuzione della query
È possibile che si verifichino errori durante l'esecuzione di query nei casi seguenti:
- Il chiamante non può accedere ad alcuni oggetti.
- La query non può accedere ai dati esterni.
- La query contiene alcune funzionalità che non sono supportate nei pool SQL serverless.
La query non riesce perché non può essere eseguita a causa di vincoli di risorse correnti
La query potrebbe non riuscire con il messaggio di errore This query cannot be executed due to current resource constraints. Questo messaggio indica che il pool SQL serverless non può essere eseguito al momento. Ecco alcune opzioni per la risoluzione dei problemi:
- Assicurarsi di usare tipi di dati di dimensioni ragionevoli.
- Se la query è destinata ai file Parquet, provare a definire tipi espliciti per le colonne stringa perché saranno VARCHAR(8000) per impostazione predefinita. Controllare i tipi di dati dedotti.
- Se la query è destinata a file CSV, valutare se creare statistiche.
- Per ottimizzare la query, vedere Procedure consigliate per le prestazioni del pool SQL serverless.
Timeout query scaduto
Se la query è stata eseguita per più di 30 minuti sul pool SQL serverless, viene restituito l'errore Query timeout expired. Questo limite per il pool SQL serverless non può essere cambiato.
- Provare a ottimizzare la query applicando procedure consigliate.
- Provare a materializzare parti delle query usando CREATE EXTERNAL TABLE AS SELECT (CETAS).
- Controllare se nel pool SQL serverless è in esecuzione un carico di lavoro simultaneo, perché le altre query potrebbero occupare le risorse. In tal caso, è possibile dividere il carico di lavoro in più aree di lavoro.
Nome di oggetto non valido
L'errore Invalid object name 'table name' indica che si sta usando un oggetto, ad esempio una tabella o una vista, che non esiste nel database del pool SQL serverless. Provare queste opzioni:
Elencare le tabelle o le viste e verificare se l'oggetto esiste. Usare SQL Server Management Studio o Azure Data Studio perché Synapse Studio potrebbe mostrare alcune tabelle non disponibili nel pool SQL serverless.
Se l'oggetto viene visualizzato, verificare se sono in uso alcune regole di confronto del database binario/con distinzione tra maiuscole e minuscole. È possibile che il nome dell'oggetto non corrisponda al nome usato nella query. Con le regole di confronto di un database binario,
Employeeeemployeesono due oggetti diversi.Se l'oggetto non viene visualizzato, è possibile che si stia tentando di eseguire query su una tabella da un database Lake o Spark. La tabella potrebbe non essere disponibile nel pool SQL serverless perché:
- La tabella include alcuni tipi di colonna che non possono essere rappresentati nel pool SQL serverless.
- La tabella ha un formato non supportato nel pool SQL serverless. Gli esempi sono Avro o ORC.
I dati binari o di tipo stringa verrebbero troncati
Questo errore si verifica se la lunghezza del tipo di colonna binario o stringa (ad esempio VARCHAR, VARBINARY o NVARCHAR) è più breve delle dimensioni effettive dei dati da leggere. È possibile correggere questo errore aumentando la lunghezza del tipo di colonna:
- Se la colonna stringa è definita come tipo
VARCHAR(32)e il testo è di 60 caratteri, usare il tipoVARCHAR(60)(o più lungo) nello schema della colonna. - Se si usa l'inferenza dello schema (senza lo schema
WITH), tutte le colonne stringa vengono definite automaticamente come di tipoVARCHAR(8000). Se si riceve questo errore, definire in modo esplicito lo schema in una clausolaWITHcon il tipo di colonnaVARCHAR(MAX)più grande per risolvere l'errore. - Se la tabella si trova nel database Lake, provare ad aumentare le dimensioni delle colonne stringa nel pool di Spark.
- Provare a impostare
SET ANSI_WARNINGS OFFper consentire al pool SQL serverless di troncare automaticamente i valori VARCHAR, se ciò non influirà sulle funzionalità.
Virgoletta di chiusura mancante dopo la stringa di caratteri
In rari casi in cui si usa l'operatore LIKE in una colonna stringa o in un confronto con i valori letterali stringa, è possibile che venga visualizzato l'errore seguente:
Unclosed quotation mark after the character string
Questo errore può verificarsi se si usano le regole di confronto Latin1_General_100_BIN2_UTF8 nella colonna. Provare a impostare le regole di confronto Latin1_General_100_CI_AS_SC_UTF8 sulla colonna invece delle regole di confronto Latin1_General_100_BIN2_UTF8 per risolvere il problema. Se l'errore persiste, generare una richiesta di supporto tramite il portale di Azure.
Non è stato possibile allocare spazio per tempdb durante il trasferimento dei dati da una distribuzione all'altra
L'errore Could not allocate tempdb space while transferring data from one distribution to another viene restituito quando il motore di esecuzione delle query non è in grado di elaborare i dati e di trasferirli tra i nodi che eseguono la query. Si tratta di un caso speciale dell'errore generico La query non riesce perché non può essere eseguita a causa di vincoli di risorse correnti. Questo errore viene restituito quando le risorse allocate al database tempdb non sono sufficienti per eseguire la query.
Applicare le procedure consigliate prima di inviare un ticket di supporto.
La query non riesce con un errore nella gestione di un file esterno (numero massimo di errori raggiunto)
Se la query non riesce con il messaggio di errore error handling external file: Max errors count reached, significa che un tipo di colonna specificato non corrisponde ai dati da caricare.
Per ottenere altre informazioni sull'errore e sulle righe e le colonne da esaminare, cambiare la versione del parser da 2.0 a 1.0.
Esempio
Se si vuole eseguire una query sul file names.csv con questa Query 1, il pool SQL serverless di Azure Synapse restituisce l'errore seguente: Error handling external file: 'Max error count reached'. File/External table name: [filepath]. Ad esempio:
Il file names.csv contiene:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
Query 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
Causa
Non appena la versione del parser viene cambiata da 2.0 a 1.0, i messaggi di errore consentono di identificare il problema. Il nuovo messaggio di errore è ora Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
Il troncamento indica che il tipo di colonna è troppo piccolo per adattare i dati. Il nome più lungo di questo file names.csv contiene sette caratteri. Il tipo di dati corrispondente da usare deve essere almeno VARCHAR(7). L'errore è causato da questa riga di codice:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
Cambiando la query di conseguenza è possibile risolvere l'errore. Dopo il debug, impostare di nuovo la versione del parser su 2.0 per ottenere le massime prestazioni.
Per altre informazioni su quando usare quale versione del parser, vedere Usare OPENROWSET con il pool SQL serverless in Synapse Analytics.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
Non è possibile eseguire il caricamento bulk perché non è stato possibile aprire il file
L'errore Cannot bulk load because the file could not be opened viene restituito se un file viene modificato durante l'esecuzione della query. È possibile che venga visualizzato un messaggio di errore simile a Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)
I pool SQL serverless non possono leggere i file che vengono modificati durante l'esecuzione della query. La query non può applicare un blocco sui file. Se si è certi che l'operazione di modifica è di accodamento, è possibile provare a impostare l'opzione seguente: {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}.
Per altre informazioni, vedere come eseguire query su file di solo accodamento o creare tabelle nei file di solo accodamento.
La query non riesce con un errore di conversione dei dati
La query potrebbe non riuscire con il messaggio di errore Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath]. Questo messaggio indica che i tipi di dati non corrispondono ai dati effettivi per il numero di riga n e la colonna m.
Questo messaggio di errore viene visualizzato, ad esempio, se si prevedono solo numeri interi nei dati, ma nella riga n è presente una stringa.
Per risolvere il problema, esaminare il file e i tipi di dati scelti. Controllare anche se le impostazioni del delimitatore di riga e del carattere di terminazione del campo sono corrette. Nell'esempio seguente viene illustrato come eseguire il controllo usando VARCHAR come tipo di colonna.
Per altre informazioni sui caratteri di terminazione dei campi, sui delimitatori di riga e sulle virgolette di escape, vedere Eseguire query sui file CSV.
Esempio
Se si vuole una query sul file names.csv:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
Con la query seguente:
Query 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Il pool SQL serverless di Azure Synapse restituisce l'errore Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
È necessario esplorare i dati e prendere una decisione informata per gestire questo problema. Per esaminare i dati che causano questo problema, è necessario prima cambiare il tipo di dati. Invece di eseguire query sulla colonna ID con il tipo di dati SMALLINT, viene ora usato VARCHAR(100) per analizzare questo problema.
Con questa Query 2 leggermente modificata, i dati possono ora essere elaborati per restituire l'elenco dei nomi.
Query 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Come si può osservare, i dati presentano valori imprevisti per ID nella quinta riga. In tali circostanze, è importante concordare con il proprietario aziendale dei dati come evitare dati danneggiati come quelli di questo esempio. Se la prevenzione non è possibile a livello di applicazione, un tipo di dati VARCHAR di dimensioni ragionevoli potrebbe essere l'unica opzione disponibile.
Suggerimento
Provare a rendere VARCHAR() il più breve possibile. Evitare VARCHAR(MAX) se possibile perché può compromettere le prestazioni.
Il risultato della query non è quello previsto
La query potrebbe riuscire, ma si potrebbe notare che il set di risultati non è quello. È possibile che le colonne risultanti siano vuote o che vengano restituiti dati imprevisti. In questo scenario è probabile che sia stato scelto un delimitatore di riga o un terminatore di campo non corretto.
Per risolvere questo problema, esaminare di nuovo i dati e cambiare tali impostazioni. Il debug di questa query è semplice, come illustrato nell'esempio seguente.
Esempio
Se si vuole eseguire una query sul file names.csv con la Query 1, il pool SQL serverless di Azure Synapse restituisce un risultato strano:
In names.csv:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
Non sembra esserci alcun valore nella colonna Firstname. Al contrario, tutti i valori sono finiti nella colonna ID. I valori sono separati da una virgola. Il problema è stato causato da questa riga di codice, perché è necessario scegliere la virgola invece del punto e virgola come carattere di terminazione del campo:
FIELDTERMINATOR =';',
Cambiando questo singolo carattere, è possibile risolvere il problema:
FIELDTERMINATOR =',',
Il set di risultati creato dalla Query 2 è ora quello previsto:
Query 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Restituisce:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
La colonna di tipo non è compatibile con il tipo di dati esterno
Se la query non riesce con il messaggio di errore Column [column-name] of type [type-name] is not compatible with external data type […], è probabile che sia stato eseguito il mapping di un tipo di dati PARQUET a un tipo di dati SQL non corretto.
Ad esempio, se il file Parquet ha una colonna di prezzi con numeri di tipo FLOAT (ad esempio 12,89) e si è tentato di eseguirne il mapping a INT, verrà restituito questo messaggio di errore.
Per risolvere il problema, esaminare il file e i tipi di dati scelti. Questa tabella di mapping consente di scegliere un tipo di dati SQL corretto. Come procedura consigliata, specificare il mapping solo per le colonne che altrimenti verrebbero risolte nel tipo di dati VARCHAR. Evitando VARCHAR quando possibile si ottengono prestazioni migliori nelle query.
Esempio
Se si vuole eseguire una query sul file taxi-data.parquet con questa Query 1, il pool SQL serverless di Azure Synapse restituisce l'errore seguente:
Il file taxi-data.parquet contiene:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
Query 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
Questo messaggio di errore indica che i tipi di dati non sono compatibili e include il suggerimento di usare FLOAT anziché INT. L'errore è causato da questa riga di codice:
SumTripDistance INT,
Con questa Query 2 leggermente modificata, i dati possono ora essere elaborati e vengono visualizzate tutte e tre le colonne:
Query 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
La query fa riferimento a un oggetto che non è supportato in modalità di elaborazione distribuita
L'errore The query references an object that is not supported in distributed processing mode indica che è stato usato un oggetto o una funzione che non è possibile usare durante l'esecuzione di query sui dati in Archiviazione di Azure o nell'archiviazione analitica di Azure Cosmos DB.
Alcuni oggetti, ad esempio le viste di sistema e le funzioni, non possono essere usati mentre si eseguono query sui dati archiviati in Azure Data Lake o nell'archiviazione analitica di Azure Cosmos DB. Evitare di usare le query che aggiungono dati esterni a viste di sistema, caricare dati esterni in una tabella temporanea o usare alcune funzioni di sicurezza o metadati per filtrare i dati esterni.
Chiamata WaitIOCompletion non riuscita
Il messaggio di errore WaitIOCompletion call failed indica che la query non è riuscita durante l'attesa del completamento dell'operazione di I/O che legge i dati dall'archiviazione remota (Azure Data Lake).
Il messaggio di errore ha il formato seguente: Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
Assicurarsi che l'archiviazione sia posizionata nella stessa area del pool SQL serverless. Nelle metriche di archiviazione verificare che nel livello di archiviazione non siano presenti altri carichi di lavoro (ad esempio, il caricamento di nuovi file) che potrebbero saturare le richieste di I/O.
Il campo HRESULT contiene il codice del risultato. I codici di errore seguenti sono i più comuni insieme alle possibili soluzioni.
Questo codice di errore indica che il file di origine non è presente nell'archiviazione.
Questo codice errore può verificarsi per diversi motivi:
- Il file è stato eliminato da un'altra applicazione.
- In questo scenario comune viene avviata l'esecuzione della query, viene eseguita l'enumerazione dei file e i file vengono trovati. Successivamente, durante l'esecuzione della query, viene eliminato un file. Ad esempio, potrebbe essere eliminato da Databricks, Spark o Azure Data Factory. La query non riesce perché il file non viene trovato.
- Questo problema può verificarsi anche con il formato delta. La query potrebbe riuscire al nuovo tentativo perché è presente una nuova versione della tabella e non viene ripetuta la query sul file eliminato.
- Il piano di esecuzione memorizzato nella cache non è valido.
- Come mitigazione temporanea, eseguire il comando
DBCC FREEPROCCACHE. Se il problema persiste, creare un ticket di supporto.
- Come mitigazione temporanea, eseguire il comando
Sintassi non corretta in prossimità di NOT
L'errore Incorrect syntax near 'NOT' indica che sono presenti alcune tabelle esterne con colonne che contengono il vincolo NOT NULL nella definizione.
- Aggiornare la tabella per rimuovere NOT NULL dalla definizione di colonna.
- Questo errore può talvolta verificarsi anche temporaneamente con le tabelle create da un'istruzione CETAS. Se il problema non viene risolto, è possibile provare a eliminare e creare nuovamente la tabella esterna.
La colonna di partizione restituisce valori NULL
Se la query restituisce valori NULL anziché colonne di partizionamento o non riesce a trovare le colonne di partizione, sono disponibili alcuni passaggi possibili per la risoluzione dei problemi:
- Se si usano tabelle per eseguire query su un set di dati partizionato, le tabelle non supportano il partizionamento. Sostituire la tabella con le viste partizionate.
- Se si usano le viste partizionate con OPENROWSET che esegue query su file partizionati usando la funzione FILEPATH(), assicurarsi di aver specificato correttamente il criterio con caratteri jolly nel percorso e di aver usato l'indice appropriato per fare riferimento al carattere jolly.
- Se si eseguono query sui file direttamente nella cartella partizionata, le colonne di partizionamento non sono le parti delle colonne di file. I valori di partizionamento vengono inseriti nei percorsi delle cartelle e non nei file. Per questo motivo, i file non contengono i valori di partizionamento.
Non è stato possibile inserire un valore nel batch per il tipo di colonna DATETIME2
L'errore Inserting value to batch for column type DATETIME2 failed indica che il pool serverless non è in grado di leggere i valori di data dai file sottostanti. Il valore datetime archiviato nel file Parquet o Delta Lake non può essere rappresentato come una colonna DATETIME2.
Esaminare il valore minimo nel file usando Spark e verificare che alcune date siano inferiori a 0001-01-03. Se i file sono stati archiviati usando Spark 2.4 (versione di runtime non supportata) o con la versione di Spark successiva che usa ancora il formato di archiviazione datetime legacy, i valori datetime precedenti vengono scritti usando il calendario giuliano che non è allineato al calendario gregoriano prolettico usato nei pool SQL serverless.
Potrebbe esserci una differenza di due giorni tra il calendario giuliano usato per scrivere i valori in Parquet (in alcune versioni di Spark) e il calendario gregoriano prolettico usato nel pool SQL serverless. Questa differenza può causare la conversione in un valore di data negativo, che non è valido.
Provare a usare Spark per aggiornare questi valori perché vengono considerati come valori di data non validi in SQL. L'esempio seguente illustra come aggiornare i valori non compresi negli intervalli di date SQL a NULL in Delta Lake:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
Questa modifica rimuove i valori che non possono essere rappresentati. Gli altri valori di data potrebbero essere caricati correttamente, ma non correttamente rappresentati perché esiste ancora una differenza tra i calendari giuliano e gregoriano prolettico. Se si usa Spark 3.0 o versione precedente, è possibile riscontrare variazioni di data impreviste anche per le date antecedenti a 1900-01-01.
È consigliabile eseguire la migrazione a Spark 3.1 o versione successiva e passare al calendario gregoriano prolettico. Le versioni più recenti di Spark usano per impostazione predefinita un calendario gregoriano prolettico allineato al calendario nel pool SQL serverless. Ricaricare i dati legacy con la versione superiore di Spark e usare l'impostazione seguente per correggere le date:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
Query non riuscita a causa di una modifica della topologia o di un errore del contenitore di calcolo
Questo errore potrebbe indicare che si è verificato un problema di processo interno nel pool SQL serverless. Inviare un ticket di supporto con tutti i dettagli necessari che potrebbero aiutare il team di supporto tecnico di Azure ad analizzare il problema.
Descrivere qualsiasi anomalia rispetto al carico di lavoro normale. È ad esempio possibile che siano state inviate numerose richieste simultanee oppure che sia stata avviata l'esecuzione di un carico di lavoro speciale o di una query prima che si verificasse l'errore.
Timeout dell'espansione di caratteri jolly
Come descritto nella sezione Eseguir query su cartelle e più file, il pool SQL serverless supporta la lettura di più file/cartelle usando caratteri jolly. Esiste un limite massimo di 10 caratteri jolly per ogni query. È necessario tenere presente che questa funzionalità presenta svantaggi. Il pool serverless richiede tempo per elencare tutti i file che possono corrispondere al carattere jolly. Si verifica di conseguenza una latenza, che può aumentare se si sta tentando di eseguire query su un numero elevato di file. In questo caso è possibile che si riscontri l'errore seguente:
"Wildcard expansion timed out after X seconds."
Per evitare questo errore, è possibile eseguire diversi passaggi di mitigazione:
- Applicare le procedure consigliate descritte in Procedure consigliate per il pool SQL serverless.
- Provare a ridurre il numero di file su cui si sta tentando di eseguire query, comprimendo i file in file di dimensioni maggiori. Provare a mantenere dimensioni dei file superiori a 100 MB.
- Assicurarsi che vengano applicati filtri sulle colonne di partizionamento laddove possibile.
- Se si usa il formato di file differenziale, usare la funzionalità di ottimizzazione della scrittura di Spark. In questo modo è possibile migliorare le prestazioni delle query riducendo la quantità di dati che è necessario leggere ed elaborare. Per informazioni su come usare l'ottimizzazione della scrittura, vedere Uso dell'ottimizzazione della scrittura in Apache Spark.
- Per evitare alcuni dei caratteri jolly di primo livello impostando efficacemente come hardcoded i filtri impliciti sulle colonne di partizionamento, usare SQL dinamico.
Colonna mancante quando si usa l'inferenza automatica dello schema
È possibile eseguire facilmente query sui fil senza conoscere o specificare lo schema, omettendo la clausola WITH. In tal caso, i nomi e i tipi di dati delle colonne verranno dedotti dai file. Tenere presente che se si leggono numerosi file contemporaneamente, lo schema verrà dedotto dal primo file che il servizio recupera dall'archiviazione. Ciò può significare che alcune colonne previste vengono omesse, perché non sono contenute nel file usato dal servizio per definire lo schema. Per specificare esplicitamente lo schema, usare la clausola OPENROWSET WITH. Se si specifica lo schema (usando la tabella esterna o la clausola OPENROWSET WITH) verrà usata la modalità di percorso lax predefinita. Ciò significa che le colonne che non esistono in alcuni file verranno restituite come NULLs (per le righe di tali file). Per comprendere come viene usata la modalità di percorso, consultare la seguente documentazione e l'esempio.
Impostazione
I pool SQL serverless consentono di usare T-SQL per configurare gli oggetti di database. Esistono alcuni vincoli:
- Non è possibile creare oggetti in
masterelakehouseo in database Spark. - È necessario avere una chiave master per creare credenziali.
- È necessario avere l'autorizzazione per fare riferimento ai dati usati negli oggetti.
Non è possibile creare un database
Se viene visualizzato l'errore CREATE DATABASE failed. User database limit has been already reached., significa che è stato creato il numero massimo di database supportati in un'area di lavoro. Per altre informazioni, vedere Vincoli.
- Se è necessario separare gli oggetti, usare gli schemi all'interno dei database.
- Se è necessario fare riferimento ad Azure Data Lake Storage, creare database lakehouse o database Spark che verranno sincronizzati nel pool SQL serverless.
La creazione o l'alterazione di tabelle non è riuscita perché le dimensioni minime della riga superano le dimensioni massime della riga della tabella di 8060 byte
Tutte le tabelle possono avere una dimensione massima di 8 kB per riga (non sono inclusi i dati VARCHAR(MAX)/VARBINARY(MAX) fuori riga). Se si crea una tabella in cui le dimensioni totali delle celle nella riga superano 8060 byte, verrà restituito l'errore seguente:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
Questo errore potrebbe verificarsi nel database Lake se si crea una tabella Spark con dimensioni di colonna che superano 8060 byte e il pool SQL serverless non può creare un tabella che faccia riferimento ai dati della tabella Spark.
Come prevenzione, evitare di usare i tipi di dimensioni fissi come CHAR(N) e sostituirli con i tipi di dimensione variabili VARCHAR(N) o ridurre le dimensioni in CHAR(N). Vedere Limitazione dei gruppi di righe 8 kB in SQL Server.
Creare una chiave master nel database o aprire la chiave master nella sessione prima di eseguire questa operazione
Se la query non riesce con il messaggio di errore Please create a master key in the database or open the master key in the session before performing this operation., significa che al momento il database utente non ha accesso a una chiave master.
Molto probabilmente è stato creato un nuovo database utente e non è stata ancora creata una chiave master.
Per risolvere questo problema, creare una chiave master con la query seguente:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
Nota
Sostituire 'strongpasswordhere' con un segreto diverso.
L'istruzione CREATE non è supportata nel database master
Se la query non riesce con il messaggio di errore Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database., significa che il database master nel pool SQL serverless non supporta la creazione di:
- Tabelle esterne.
- Origini dati esterne.
- Credenziali con ambito database.
- Formati di file esterni.
Ecco la soluzione:
creare un database utente:
CREATE DATABASE <DATABASE_NAME>Eseguire un'istruzione CREATE nel contesto di <DATABASE_NAME> che non era riuscita in precedenza per il database
master.Ecco un esempio di creazione di un formato di file esterno:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
Non è possibile creare l'account di accesso o l'utente di Microsoft Entra
Se viene visualizzato un errore durante il tentativo di creare un nuovo account di accesso o utente di Microsoft Entra in un database, controllare l'account di accesso usato per connettersi al database. L'account di accesso che sta tentando di creare un nuovo utente di Microsoft Entra deve avere l'autorizzazione per accedere al dominio di Microsoft Entra e verificare se l'utente esiste. Tenere presente che:
- Gli account di accesso SQL non hanno questa organizzazione, quindi se si usa l'autenticazione di SQL si riceverà sempre questo errore.
- Se si usa un account di accesso di Microsoft Entra per creare nuovi account di accesso, verificare se si ha l'autorizzazione per accedere al dominio di Microsoft Entra.
Azure Cosmos DB
I pool SQL serverless consentono di eseguire query sull'archiviazione analitica di Azure Cosmos DB usando la funzione OPENROWSET. Assicurarsi che il contenitore di Azure Cosmos DB disponga di archiviazione analitica. Assicurarsi di aver specificato correttamente il nome dell'account, del database e del contenitore. Verificare inoltre che la chiave dell'account Azure Cosmos DB sia valida. Per altre informazioni, consulta Prerequisiti.
Non è possibile eseguire query su Azure Cosmos DB usando la funzione OPENROWSET
Se non è possibile connettersi all'account Azure Cosmos DB, esaminare i prerequisiti. Nella tabella seguente sono elencati i possibili errori e le azioni di risoluzione dei problemi.
| Error | Causa principale |
|---|---|
| Errori di sintassi: - Sintassi non corretta in prossimità di OPENROWSET.- ... non è un'opzione del provider BULK OPENROWSET riconosciuta.- Sintassi non corretta in prossimità di .... |
Possibili cause radice: - Non viene usato Azure Cosmos DB come primo parametro. - Nel terzo parametro viene usato un valore letterale stringa invece di un identificatore. - Il terzo parametro (nome del contenitore) non viene specificato. |
| È presente un errore nella stringa di connessione di Azure Cosmos DB. | - L'account, il database o la chiave non è specificata. - Un'opzione in una stringa di connessione non viene riconosciuta. - Alla fine di una stringa di connessione è stato inserito un punto e virgola ( ;). |
| La risoluzione del percorso di Azure Cosmos DB non è riuscita con l'errore "Il nome dell'account non è corretto" o "Il nome del database non è corretto". | Il nome specificato per l'account, il database o il contenitore non è stato trovato oppure l'archiviazione analitica non è stata abilitata per la raccolta specificata. |
| La risoluzione del percorso di Azure Cosmos DB non è riuscita con l'errore "Il valore del segreto non è corretto" o "Il segreto è null o vuoto". | La chiave dell'account non è valida o non è presente. |
Durante la lettura dei tipi di stringa di Azure Cosmos DB viene restituito un avviso relativo alle regole di confronto UTF-8
Il pool SQL serverless restituisce un avviso in fase di compilazione se le regole di confronto della colonna OPENROWSET non hanno codifica UTF-8. È possibile cambiare facilmente le regole di confronto predefinite per tutte le funzioni OPENROWSET in esecuzione nel database corrente usando l'istruzione T-SQL:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
la regola di confronto Latin1_General_100_BIN2_UTF8 offre prestazioni ottimali quando si filtrano i dati usando predicati stringa.
Righe mancanti nell'archivio analitico di Azure Cosmos DB
Alcuni elementi di Azure Cosmos DB potrebbero non essere restituiti dalla funzione OPENROWSET. Tenere presente che:
- Esiste un ritardo di sincronizzazione tra l'archivio transazionale e quello analitico. Il documento immesso nell'archivio transazionale di Azure Cosmos DB potrebbe comparire nell'archivio analitico dopo due o tre minuti.
- Il documento potrebbe violare alcuni vincoli dello schema.
La query restituisce valori NULL in alcuni elementi di Azure Cosmos DB
Azure Synapse SQL restituisce NULL anziché i valori visualizzati nell'archivio transazionale nei casi seguenti:
- Esiste un ritardo di sincronizzazione tra l'archivio transazionale e quello analitico. Il valore immesso nell'archivio transazionale di Azure Cosmos DB potrebbe comparire nell'archivio analitico dopo due o tre minuti.
- La clausola WITH potrebbe contenere un errore in un nome di colonna o in un'espressione di percorso. Il nome della colonna (o l'espressione di percorso dopo il tipo di colonna) nella clausola WITH deve corrispondere ai nomi delle proprietà nella raccolta di Azure Cosmos DB. Il confronto fa distinzione tra maiuscole e minuscole. Ad esempio,
productCodeeProductCodesono proprietà diverse. Assicurarsi che i nomi delle colonne corrispondano esattamente ai nomi delle proprietà di Azure Cosmos DB. - La proprietà potrebbe non essere stata spostata nell'archivio analitico perché viola alcuni vincoli dello schema, ad esempio più di 1.000 proprietà o più di 127 livelli di annidamento.
- Se si usa una rappresentazione dello schema ben definita, il valore nell'archivio transazionale potrebbe avere un tipo errato. Lo schema ben definito blocca i tipi per ogni proprietà eseguendo il campionamento dei documenti. Qualsiasi valore aggiunto nell'archivio transazionale che non corrisponde al tipo viene considerato errato e non ne viene eseguita la migrazione all'archivio analitico.
- Se si usa la rappresentazione dello schema con la massima fedeltà, assicurarsi di aggiungere il suffisso di tipo dopo il nome della proprietà, ad esempio
$.price.int64. Se non si vede un valore per il percorso a cui si fa riferimento, è possibile che sia archiviato in un percorso di tipo diverso, ad esempio$.price.float64. Per altre informazioni, vedere Eseguire query sulle raccolte di Azure Cosmos DB nello schema con massima fedeltà.
La colonna non è compatibile con il tipo di dati esterno
L'errore Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. viene restituito se il tipo di colonna specificato nella clausola WITH non corrisponde al tipo nel contenitore di Azure Cosmos DB. Provare a cambiare il tipo di colonna come descritto nella sezione Mapping dei tipi di Azure Cosmos DB a SQL o usare il tipo VARCHAR.
Risolvere: il percorso di Azure Cosmos DB non è riuscito con errore
Se viene visualizzato l'errore Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'., verificare se sono stati usati endpoint privati in Azure Cosmos DB. Per consentire al pool SQL serverless di accedere a un archivio analitico con endpoint privati, è necessario configurare gli endpoint privati per l'archivio analitico di Azure Cosmos DB.
Problemi di prestazioni di Azure Cosmos DB
Se si verificano alcuni problemi di prestazioni imprevisti, assicurarsi di applicare le procedure consigliate, ad esempio:
- Assicurarsi di inserire l'applicazione client, il pool serverless e l'archiviazione analitica di Azure Cosmos DB nella stessa area.
- Assicurarsi di usare la clausola WITH con tipi di dati ottimali.
- Assicurarsi di usare la regola di confronto Latin1_General_100_BIN2_UTF8 quando si filtrano i dati usando predicati stringa.
- Se sono presenti query ripetute che potrebbero essere memorizzate nella cache, provare a usare CETAS per archiviare i risultati delle query in Azure Data Lake Storage.
Delta Lake
Esistono alcune limitazioni che potrebbero essere riscontrate nel supporto per Delta Lake nei pool SQL serverless:
- Assicurarsi di fare riferimento alla cartella radice di Delta Lake nella funzione OPENROWSET o nella posizione della tabella esterna.
- La cartella radice deve avere una sottocartella denominata
_delta_log. La query non riesce se non è presente una cartella_delta_log. Se la cartella non viene visualizzata, si fa riferimento a file Parquet semplici che devono essere convertiti in Delta Lake usando i pool di Apache Spark. - Non specificare caratteri jolly per descrivere lo schema di partizione. La query di Delta Lake identifica automaticamente le partizioni di Delta Lake.
- La cartella radice deve avere una sottocartella denominata
- Le tabelle Delta Lake create nei pool di Apache Spark sono automaticamente disponibili nel pool SQL serverless, ma lo schema non viene aggiornato (limitazione dell'anteprima pubblica). Se si aggiungono colonne nella tabella Delta usando un pool di Spark, le modifiche non verranno visualizzate nel database del pool SQL serverless.
- Le tabelle esterne non supportano il partizionamento. Usare viste partizionate nella cartella di Delta Lake per usare l'eliminazione di partizioni. Vedere problemi noti e soluzioni alternative più avanti nell'articolo.
- I pool SQL serverless non supportano le query di spostamento cronologico. Usare i pool di Apache Spark in Synapse Analytics per leggere dati cronologici.
- I pool SQL serverless non supportano l'aggiornamento di file di Delta Lake. È possibile usare il pool SQL serverless per eseguire query sulla versione più recente di Delta Lake. Usare i pool di Apache Spark in Synapse Analytics per aggiornare Delta Lake.
- Non è possibile archiviare i risultati delle query nell'archiviazione in formato Delta Lake usando il comando CETAS. Il comando CETAS supporta solo Parquet e CSV come formati di output.
- I pool SQL serverless in Synapse Analytics sono compatibili con il lettore Delta versione 1.
- I pool SQL serverless in Synapse Analytics non supportano i set di dati con il filtro BLOOM. Il pool SQL serverless ignora i filtri BLOOM.
- Il supporto di Delta Lake non è disponibile nei pool SQL dedicati. Assicurarsi di usare pool SQL serverless per eseguire query sui file di Delta Lake.
- Per altre informazioni sui problemi noti relativi ai pool SQL serverless, vedere Problemi noti di Azure Synapse Analytics.
Supporto serverless versione 1.0 Delta
I pool SQL serverless leggono solo la versione Delta Lake 1.0. I pool SQL serverless sono un lettore Delta con livello 1 e non supporta le funzionalità seguenti:
- Le mappature di colonna vengono ignorate: i pool SQL serverless restituiranno i nomi di colonna originali.
- I vettori Delete vengono ignorati e verrà restituita la versione precedente delle righe eliminate/aggiornate (risultati possibilmente errati).
- Le funzionalità Delta Lake seguenti non sono supportate: checkpoint V2, timestamp senza fuso orario, controllo protocollo VACUUM
I vettori Delete vengono ignorati
Se la tabella Delta Lake è configurata per usare scrittore Delta versione 7, memorizzerà le righe eliminate e le versioni precedenti delle righe eliminate nei vettori Delete. Dal momento che i pool SQL hanno lettore Delta livello 1, ignoreranno i vettori Delete e probabilmente produrranno risultati errati durante la lettura di versioni Delta Lake non supportate.
La ridenominazione delle colonne nella tabella Delta non è supportata
Il pool SQL serverless non supporta l'esecuzione di query su tabelle Delta Lake con le colonne rinominate. Il pool SQL serverless non può leggere i dati dalla colonna rinominata.
Il valore di una colonna nella tabella Delta è NULL
Se si usa un set di dati di Delta che richiede un lettore Delta versione 2 o successiva e usa funzionalità non supportate nella versione 1 (ad esempio la ridenominazione, l'eliminazione o il mapping di colonne), i valori nelle colonne a cui viene fatto riferimento potrebbero non essere visualizzati.
Il formato del testo JSON non è corretto
Questo errore indica che il pool SQL serverless non è in grado di leggere il log delle transazioni di Delta Lake. Verrà probabilmente visualizzato il messaggio di errore:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Assicurarsi che il set di dati di Delta Lake non sia danneggiato. Verificare di poter leggere il contenuto della cartella di Delta Lake usando il pool di Apache Spark in Azure Synapse. In questo modo ci si assicura che il file _delta_log non sia danneggiato.
Soluzione alternativa
Provare a creare un checkpoint nel set di dati di Delta Lake usando il pool di Apache Spark ed eseguire di nuovo la query. Il checkpoint aggrega i file di log JSON transazionali e potrebbe risolvere il problema.
Se il set di dati è valido, creare un ticket di supporto e fornire altre informazioni:
- Non apportare modifiche come l'aggiunta o la rimozione delle colonne oppure l'ottimizzazione della tabella perché questa operazione potrebbe cambiare lo stato dei file di log delle transazioni di Delta Lake.
- Copiare il contenuto della cartella
_delta_login una nuova cartella vuota. Non copiare i file.parquet data. - Provare a leggere il contenuto copiato nella nuova cartella e verificare se si riceve lo stesso errore.
- Inviare il contenuto del file
_delta_logcopiato al supporto tecnico di Azure.
È ora possibile continuare a usare la cartella di Delta Lake con il pool di Spark. I dati copiati verranno forniti al supporto tecnico Microsoft se si è autorizzati a condividere queste informazioni. Il team di Azure esaminerà il contenuto del file delta_log e fornirà altre informazioni su possibili errori e soluzioni alternative.
Risolvere i log di Delta non riusciti
L'errore seguente indica che il pool SQL serverless non è in grado di risolvere i log di Delta: Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder. La causa più comune è che last_checkpoint_file nella cartella _delta_log è maggiore di 200 byte a causa del campo checkpointSchema aggiunto in Spark 3.3.
Esistono due opzioni per risolvere questo errore:
- Modificare la configurazione appropriata nel notebook Spark e generare un nuovo checkpoint, in modo che
last_checkpoint_filevenga ricreato. Se si usa Azure Databricks, la modifica della configurazione è la seguente:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Eseguire il downgrade a Spark 3.2.1.
Il team di progettazione sta attualmente lavorando a un supporto completo per Spark 3.3.
La tabella Delta creata in Spark non viene visualizzata nel pool serverless
Nota
La replica delle tabelle Delta create in Spark è ancora in anteprima pubblica.
Se è stata creata una tabella Delta in Spark e non viene visualizzata nel pool SQL serverless, verificare quanto segue:
- Attendere un po' di tempo (in genere 30 secondi) perché le tabelle Spark vengono sincronizzate con ritardo.
- Se la tabella non viene visualizzata nel pool SQL serverless dopo qualche tempo, controllare lo schema della tabella Spark Delta. Le tabelle Spark con tipi complessi o con tipi non supportati in serverless non sono disponibili. Provare a creare una tabella Parquet Spark con lo stesso schema in un database Lake e verificare se tale tabella viene visualizzata nel pool SQL serverless.
- Controllare la cartella Delta Lake per l'accesso all'identità gestita dell'area di lavoro a cui fa riferimento la tabella. Il pool SQL serverless usa l'identità gestita dell'area di lavoro per ottenere le informazioni sulle colonne della tabella dall'archiviazione per creare la tabella.
Database Lake
Le tabelle di database Lake create tramite finestra di progettazione Spark o Synapse sono automaticamente disponibili nel pool SQL serverless per l'esecuzione di query. È possibile usare il pool SQL serverless per eseguire query su tabelle Parquet, CSV e Delta Lake create usando il pool di Spark e aggiungere altri schemi, viste, procedure, funzioni con valori di tabella e utenti di Microsoft Entra nel ruolo db_datareader al database Lake. I possibili problemi sono elencati in questa sezione.
Una tabella creata in Spark non è disponibile nel pool serverless
Le tabelle create potrebbero non essere immediatamente disponibili nel pool SQL serverless.
- Le tabelle saranno disponibili nei pool serverless con un certo ritardo. Potrebbe essere necessario attendere 5-10 minuti dopo la creazione di una tabella in Spark per visualizzarla nel pool SQL serverless.
- Nel pool SQL serverless sono disponibili solo le tabelle che fanno riferimento a formati Parquet, CSV e Delta. Non sono disponibili altri tipi di tabella.
- Una tabella contenente alcuni tipi di colonna non supportati non sarà disponibile nel pool SQL serverless.
- L'accesso alle tabelle Delta Lake nei database Lake è disponibile in anteprima pubblica. Controllare altri problemi elencati in questa sezione o nella sezione su Delta Lake.
Una tabella esterna creata in Spark mostra risultati imprevisti nel pool serverless
Può verificarsi una mancata corrispondenza tra la tabella esterna Spark di origine e la tabella esterna replicata nel pool serverless. Il problema può verificarsi se i file usati per la creazione di tabelle esterne Spark sono senza estensioni. Per ottenere i risultati appropriati, assicurarsi che tutti i file siano con estensioni come Parquet.
L'operazione non è consentita per un database replicato
Questo errore viene restituito se si sta tentando di modificare un database Lake o di creare tabelle esterne, origini dati esterne, credenziali con ambito database o altri oggetti nel database Lake. Questi oggetti possono essere creati solo nei database SQL.
I database Lake vengono replicati dal pool di Apache Spark e gestiti da Apache Spark. Pertanto, non è possibile creare oggetti come nei database SQL usando il linguaggio T-SQL.
Nei database Lake sono consentite solo le operazioni seguenti:
- Creazione, eliminazione o modifica di viste, routine e funzioni inline con valori di tabella negli schemi diversi da
dbo. - Creazione ed eliminazione degli utenti del database dall'ID Microsoft Entra.
- Aggiunta o rimozione di utenti di database dallo schema
db_datareader.
Altre operazioni non sono consentite nei database Lake.
Nota
Se si crea una vista, una routine o una funzione nello schema dbo (o si omette lo schema e si usa quello predefinito che in genere è dbo), verrà visualizzato il messaggio di errore.
Le tabelle Delta nei database Lake non sono disponibili nel pool SQL serverless
Assicurarsi che l'identità gestita dell'area di lavoro abbia accesso in lettura nell'archiviazione ADLS che contiene la cartella Delta. Il pool SQL serverless legge lo schema della tabella Delta Lake dai log di Delta inseriti in ADLS e usa l'identità gestita dell'area di lavoro per accedere ai log delle transazioni di Delta.
Provare a configurare un'origine dati in un database SQL che fa riferimento ad Azure Data Lake Storage usando le credenziali dell'identità gestita e provare a creare una tabella esterna in aggiunta all'origine dati con identità gestita per verificare che una tabella con l'identità gestita possa accedere all'archiviazione.
Le tabelle Delta nei database Lake non hanno uno schema identico in Spark e nei pool serverless
I pool SQL serverless consentono di accedere alle tabelle Parquet, CSV e Delta create nel database Lake tramite finestra di progettazione di Spark o Synapse. L'accesso alle tabelle Delta è ancora disponibile in anteprima pubblica e attualmente il serverless sincronizza una tabella Delta con Spark al momento della creazione, ma non aggiornerà lo schema se le colonne vengono aggiunte in un secondo momento usando l'istruzione ALTER TABLE in Spark.
Si tratta di una limitazione dell'anteprima pubblica. Per risolvere il problema, eliminare e ricreare la tabella Delta in Spark (se possibile) anziché modificare le tabelle.
Prestazioni
Il pool SQL serverless assegna le risorse alle query in base alle dimensioni del set di dati e alla complessità delle query. Non è possibile cambiare o limitare le risorse fornite alle query. In alcuni casi potrebbero verificarsi riduzioni impreviste delle prestazioni delle query e potrebbe essere necessario identificare le cause radice.
La durata della query è molto lunga
Se le query hanno una durata superiore 30 minuti, i risultati vengono restituiti lentamente al client. Il pool SQL serverless prevede un limite di 30 minuti per l'esecuzione. Il tempo in eccesso viene trascorso nello streaming dei risultati. Attenersi alle soluzioni alternative seguenti:
- Se si usa Synapse Studio, provare a riprodurre i problemi con altre applicazioni come SQL Server Management Studio o Azure Data Studio.
- Se la query è lenta quando viene eseguita usando SQL Server Management Studio, Azure Data Studio, Power BI o altre applicazioni, verificare se esistono problemi di rete e consultare le procedure consigliate.
- Inserire la query nel comando CETAS e misurare la durata della query. Il comando CETAS archivia i risultati in Azure Data Lake Storage e non dipende dalla connessione client. Se il comando CETAS termina più velocemente della query originale, controllare la larghezza di banda di rete tra il client e il pool SQL serverless.
La query è lenta quando viene eseguita tramite Synapse Studio
Se si usa Synapse Studio, provare a usare un client desktop, ad esempio SQL Server Management Studio o Azure Data Studio. Synapse Studio è un client Web che si connette al pool SQL serverless tramite il protocollo HTTP, che in genere è più lento rispetto alle connessioni SQL native usate in SQL Server Management Studio o Azure Data Studio.
La query è lenta quando viene eseguita usando un'applicazione
Controllare i problemi seguenti se si verifica un rallentamento dell'esecuzione delle query:
- Assicurarsi che le applicazioni client siano collocate con l'endpoint del pool SQL serverless. L'esecuzione di una query nell'area può causare una latenza aggiuntiva e uno streaming lento del set di risultati.
- Assicurarsi di non avere problemi di rete che possono causare lo streaming lento del set di risultati
- Assicurarsi che l'applicazione client abbia risorse sufficienti (ad esempio, che non usi la CPU al 100%).
- Assicurarsi che l'account di archiviazione o l'archiviazione analitica di Azure Cosmos DB si trovino nella stessa area dell'endpoint SQL serverless.
Vedere le procedure consigliate per collocare le risorse.
Variazioni elevate nelle durate delle query
Se si esegue la stessa query e si osservano variazioni nelle durate, questo comportamento potrebbe essere dovuto a diversi motivi:
- Controllare se si tratta della prima esecuzione di una query. La prima esecuzione di una query raccoglie le statistiche necessarie per creare un piano. Le statistiche vengono raccolte analizzando i file sottostanti e potrebbero aumentare la durata della query. In Synapse Studio verranno visualizzate le query di creazione di statistiche globali nell'elenco di richieste SQL eseguite prima della query.
- Le statistiche potrebbero scadere dopo un certo periodo di tempo. Periodicamente, è possibile osservare un impatto sulle prestazioni perché il pool serverless deve analizzare e ricompilare le statistiche. Si potrebbero notare altre query di creazione di statistiche globali nell'elenco di richieste SQL eseguite prima della query.
- Controllare se nello stesso endpoint è in esecuzione un altro carico di lavoro quando viene eseguita la query con la durata più lunga. L'endpoint SQL serverless alloca equamente le risorse a tutte le query eseguite in parallelo e la query potrebbe essere ritardata.
Connessioni
Il pool SQL serverless consente di connettersi usando il protocollo TDS e il linguaggio T-SQL per eseguire query sui dati. La maggior parte degli strumenti che possono connettersi a SQL Server o al database SQL di Azure possono connettersi anche al pool SQL serverless.
Il pool SQL si sta avviando
Dopo un periodo di inattività più lungo, il pool SQL serverless verrà disattivato. L'attivazione avviene automaticamente alla prima attività successiva, ad esempio al primo tentativo di connessione. Il messaggio di errore viene visualizzato perché il processo di attivazione potrebbe richiedere più tempo rispetto a un singolo tentativo di connessione. Può essere sufficiente riprovare il tentativo di connessione.
Come procedura consigliata, per i client che lo supportano, usare le parole chiave ConnectionRetryCount e ConnectRetryInterval della stringa di connessione per controllare il comportamento di riconnessione.
Se il messaggio di errore persiste, inviare un ticket di supporto tramite il portale di Azure.
Non è possibile connettersi da Synapse Studio
Vedere la sezione su Synapse Studio.
Non è possibile connettersi al pool di Azure Synapse da uno strumento
Alcuni strumenti potrebbero non avere un'opzione esplicita che è possibile usare per connettersi al pool SQL serverless di Azure Synapse. Usare un'opzione che si userebbe per connettersi a SQL Server o al database SQL. Non è necessario che la finestra di dialogo di connessione sia "Synapse" perché il pool SQL serverless usa lo stesso protocollo di SQL Server o Database SQL.
Anche se uno strumento consente di immettere solo un nome server logico e un dominio database.windows.net predefinito, inserire il nome dell'area di lavoro di Azure Synapse seguito dal suffisso -ondemand e dal dominio database.windows.net.
Sicurezza
Assicurarsi che un utente abbia le autorizzazioni per accedere ai database, le autorizzazioni per eseguire comandi e le autorizzazioni per accedere ad Azure Data Lake o all'archiviazione di Azure Cosmos DB.
Non è possibile accedere a un account Azure Cosmos DB
È necessario usare una chiave di Azure Cosmos DB di sola lettura per accedere all'archiviazione analitica, quindi assicurarsi che non sia scaduta o che non sia stata rigenerata.
Se viene visualizzato l'errore "Risoluzione del percorso di Azure Cosmos DB non riuscita con errore", assicurarsi di aver configurato un firewall.
Non è possibile accedere a lakehouse o al database Spark
Se un utente non riesce ad accedere a un lakehouse o a un database Spark, potrebbe non avere l'autorizzazione per accedere e leggere il database. Un utente con autorizzazione CONTROL SERVER deve avere accesso completo a tutti i database. Come autorizzazione con restrizioni, è possibile provare a usare CONNECT ANY DATABASE e SELECT ALL USER SECURABLES.
L'utente di SQL non può accedere alle tabelle di Dataverse
Le tabelle di Dataverse accedono all'archiviazione usando l'identità Microsoft Entra del chiamante. Un utente di SQL con autorizzazioni elevate potrebbe provare a selezionare i dati da una tabella, ma la tabella non sarà in grado di accedere ai dati di Dataverse. Questo scenario non è supportato.
Errori di accesso dell'entità servizio di Microsoft Entra quando lo SPI crea un'assegnazione di ruolo
Se si vuole creare un'assegnazione di ruolo per un identificatore dell'entità servizio (SPI) o un'app di Microsoft Entra usando un altro SPI oppure se ne è già stato creato uno ma non è possibile eseguire l'accesso, è probabile che venga visualizzato l'errore seguente: Login error: Login failed for user '<token-identified principal>'.
Per le entità servizio, l'account di accesso deve essere creato con un ID applicazione come ID di sicurezza (SID) non con un ID oggetto. Esiste una limitazione nota per le entità servizio, che impedisce ad Azure Synapse di recuperare l'ID applicazione da Microsoft Graph quando crea un'assegnazione di ruolo per un altro SPI o un'altra app.
Soluzione 1
Passare al portale di Azure>Synapse Studio>Gestisci>Controllo di accesso e aggiungere manualmente Amministratore di Synapse o amministratore di Synapse SQL per l'entità servizio desiderata.
Soluzione 2
È necessario creare manualmente un account di accesso appropriato con il codice SQL:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
Soluzione 3
È anche possibile configurare un'entità servizio amministratore di Azure Synapse usando PowerShell. È necessario aver installato il modulo di Az.Synapse.
La soluzione consiste nell'usare il cmdlet New-AzSynapseRoleAssignment con -ObjectId "parameter". Nel campo del parametro specificare l'ID applicazione anziché l'ID oggetto usando le credenziali dell'entità servizio di Azure amministratore dell'area di lavoro.
Script di PowerShell:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
Nota
In questo caso, l'interfaccia utente di Synapse Data Studio non visualizzerà l'assegnazione di ruolo aggiunta dal metodo precedente, pertanto è consigliabile aggiungere l'assegnazione di ruolo sia all'ID oggetto che all'ID applicazione contemporaneamente in modo che possa essere visualizzata anche nell'interfaccia utente.
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<object_id_to_add_as_admin>" [-Debug]
Convalida
Connettersi all'endpoint SQL serverless e verificare che venga creato l'account di accesso esterno con SID (app_id_to_add_as_admin nell'esempio precedente):
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
In alternativa, provare ad accedere all'endpoint SQL serverless usando l'app di amministrazione impostata.
Vincoli
Alcuni vincoli di sistema generali possono influire sul carico di lavoro:
| Proprietà | Limitazione |
|---|---|
| Numero massimo di aree di lavoro di Azure Synapse per sottoscrizione | Vedere i limiti. |
| Numero massimo di database per pool serverless | 100 (non inclusi i database sincronizzati dal pool di Apache Spark). |
| Numero massimo di database sincronizzati dal pool di Apache Spark | Non limitate. |
| Numero massimo di oggetti database per database | La somma del numero di tutti gli oggetti in un database non può essere maggiore di 2.147.483.647. Vedere Limitazioni nel motore di database di SQL Server. |
| Lunghezza massima dell'identificatore in caratteri | 128. Vedere Limitazioni nel motore di database di SQL Server. |
| Durata massima delle query | 30 minuti. |
| Dimensioni massime del set di risultati | Fino a 400 GB condivisi tra query simultanee. |
| Concorrenza massima | Non limitata e dipende dalla complessità delle query e dalla quantità di dati analizzati. Un pool SQL serverless può gestire contemporaneamente 1.000 sessioni attive che eseguono query leggere. I numeri verranno diminuiti se le query sono più complesse o analizzano una quantità maggiore di dati, quindi in tal caso prendere in considerazione la riduzione della concorrenza ed eseguire query in un periodo di tempo più lungo, se possibile. |
| Dimensioni massime del nome della tabella esterna | 100 caratteri. |
Non è possibile creare un database nel pool SQL serverless
I pool SQL serverless presentano limitazioni e non è possibile creare più di 100 database per area di lavoro. Se è necessario separare gli oggetti e isolarli, usare gli schemi.
Se viene visualizzato l'errore CREATE DATABASE failed. User database limit has been already reached, significa che è stato creato il numero massimo di database supportati in un'area di lavoro.
Non è necessario usare database separati per isolare i dati per tenant diversi. Tutti i dati vengono archiviati esternamente in un data lake e in Azure Cosmos DB. I metadati, ad esempio tabelle, viste e definizioni di funzione, possono essere isolati correttamente usando gli schemi. L'isolamento basato su schema viene usato anche in Spark in cui i database e gli schemi sono gli stessi concetti.