Tipi di spiegazione in Microsoft Syntex
Si applica a: ✓ Elaborazione documenti non strutturata
Le spiegazioni consentono di definire le informazioni da etichettare ed estrarre nei modelli di elaborazione dei documenti non strutturati in Microsoft Syntex. Quando si crea una spiegazione, è necessario selezionare un tipo di spiegazione. Questo articolo contiene informazioni utili per comprendere i diversi tipi di spiegazione e come vengono usati.
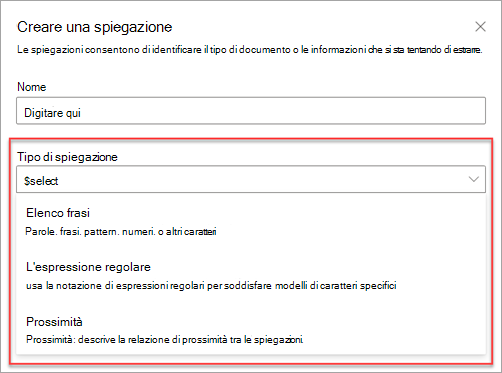
Sono disponibili questi tipi di spiegazione:
Elenco frasi: elenco di parole, frasi, numeri o altri caratteri che è possibile usare nel documento o nelle informazioni che si stanno estraendo. Ad esempio, la stringa di testo medico richiedente è inclusa in tutti i documenti di richiesta di visita specialistica che si stanno identificando. Oppure il numero di telefono del medico richiedente da tutti i documenti di richiesta di visita specialistica che si stanno identificando.
Espressione regolare: usa una notazione di corrispondenza dei criteri per trovare modelli di carattere specifici. Ad esempio, è possibile usare un'espressione regolare per trovare tutte le istanze di un criterio indirizzo di posta elettronica di in un set di documenti.
Prossimità: descrive la relazione di prossimità tra le spiegazioni. Ad esempio, un elenco di frasi di numeri di strada viene visualizzato immediatamente prima dell'elenco di frasi del nome della strada , senza token intermedi (più avanti in questo articolo verranno fornite informazioni sui token). Se si usa il tipo di prossimità, il modello deve includere almeno due spiegazioni, altrimenti l'opzione verrà disabilitata.
Elenco frasi
Il tipo di spiegazione elenco frasi viene usato generalmente per identificare e classificare un documento tramite il modello. Come descritto nell'esempio di etichetta medico richiedente, si tratta di una stringa di parole, frasi, numeri o caratteri presente costantemente nei documenti che si stanno identificando.
Anche se non è necessario, la spiegazione risulta più efficace se la frase acquisita si trova in una posizione ricorrente nel documento. Ad esempio, l'etichetta medico richiedente potrebbe essere situata sempre nel primo paragrafo del documento. È possibile inoltre usare l'impostazione avanzata Configurare la posizione delle frasi nel documento per selezionare aree specifiche in cui è posizionata la frase, soprattutto se la frase può essere presente in più posizioni nel documento.
Se la distinzione tra maiuscole e minuscole è un requisito per identificare l'etichetta, il tipo elenco frasi consente di specificarlo nella spiegazione selezionando la casella di controllo Solo le maiuscole esatte.

Un tipo di frase è utile soprattutto quando si crea una spiegazione che identifichi ed estragga informazioni in formati diversi, come date, numeri di telefono e numeri di carte di credito. Ad esempio, una data può essere visualizzata in molti formati (1/1/2020, 1-1-2020, 01/01/20, 01/01/2020 o 1 gen 2020). La definizione di un elenco frasi rende più efficace la spiegazione attraverso l'acquisizione di tutte le possibili varianti nei dati che si sta provando a identificare ed estrarre.
Per l'esempio relativo al numero di telefono, estrarre il numero di telefono per ogni medico richiedente da tutti i documenti di richiesta di visita specialistica identificati dal modello. Quando si crea la spiegazione, digitare i vari formati in cui può essere visualizzato un numero di telefono nel documento, così da poter acquisire tutte le possibili variabili.
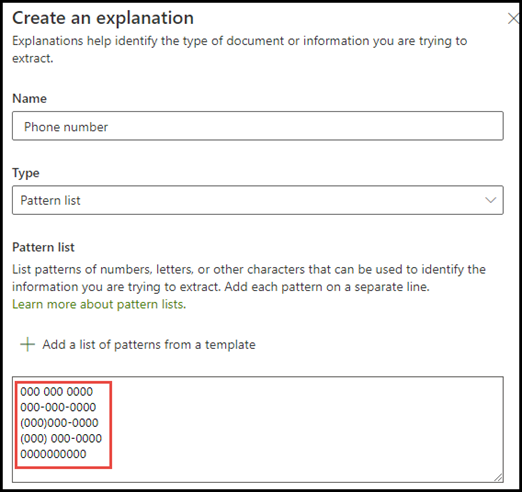
Nel caso di questo esempio, in Impostazioni avanzate selezionare la casella di controllo Qualsiasi cifra da 0 a 9 per riconoscere ogni valore "0" usato nell'elenco frasi come qualsiasi cifra da 0 a 9.

Analogamente, se si crea un elenco frasi che include caratteri di testo, selezionare la casella di controllo Qualsiasi lettera dalla a alla z per riconoscere ogni carattere "a" usato nell'elenco di frasi per essere qualsiasi carattere compreso dalla "a" alla "z".
Ad esempio, se si crea un elenco frasi Data e si vuole fare in modo che venga riconosciuto un formato di data come 1 gen 2020, è necessario:
- Aggiungere 0 aaa 0000 e 00 aaa 0000 all'elenco frasi.
- Assicurarsi che sia selezionata anche l'opzione Qualsiasi lettera dalla a alla z.

Se l'elenco frasi prevede requisiti per le maiuscole, è possibile selezionare la casella di controllo Solo le maiuscole esatte. Per l'esempio relativo alla data, se il mese deve avere l'iniziale minuscola, è necessario:
- Aggiungere 0 aaa 0000 e 00 aaa 0000 all'elenco frasi.
- Assicurarsi che sia selezionata anche l'opzione Solo le maiuscole esatte.

Nota
Anziché creare manualmente una spiegazione elenco frasi, usare la raccolta spiegazioni per usare modelli di elenchi frasi per elenchi frasi comuni, quali data, numero di telefono o numero di carta di credito.
Espressione regolare
Un tipo di spiegazione di espressione regolare consente di creare criteri che consentono di trovare e identificare determinate stringhe di testo nei documenti. È possibile usare le espressioni regolari per analizzare rapidamente grandi quantità di testo per:
- Trovare criteri di caratteri specifici.
- Convalidare il testo per assicurarsi che corrisponda a un criterio predefinito, ad esempio un indirizzo di posta elettronica.
- Estrazione, modifica, sostituzione o eliminazione di sottostringhe di testo.
Un’espressione regolare è utile soprattutto quando si crea una spiegazione che identifichi ed estragga informazioni in formati simili, ad esempio indirizzi di posta elettronica, numeri di conto corrente bancario o URL. Ad esempio, un indirizzo di posta elettronica, ad megan@contoso.comesempio , viene visualizzato in un determinato modello ("megan" è la prima parte e "com" è l'ultima parte).
L'espressione regolare per un indirizzo di posta elettronica è: [A-Za-z0-9._%-]+@[A-Za-z0-9.-]+. [A-Za-z]{2,6}.
Questa espressione è costituita da cinque parti, in questo ordine:
Qualsiasi dei caratteri speciali seguenti:
a. Lettere dalla a alla z
b. Numeri da 0 a 9
c. Punto, trattino basso, percentuale o trattino
Il simbolo @
Qualsiasi quantità di caratteri della prima parte dell'indirizzo di posta elettronica
Un punto
Da due a sei lettere
Per aggiungere un tipo di spiegazione di espressione regolare:
Dal pannello Crea una spiegazione, in Tipo di spiegazione, selezionare Espressione regolare.

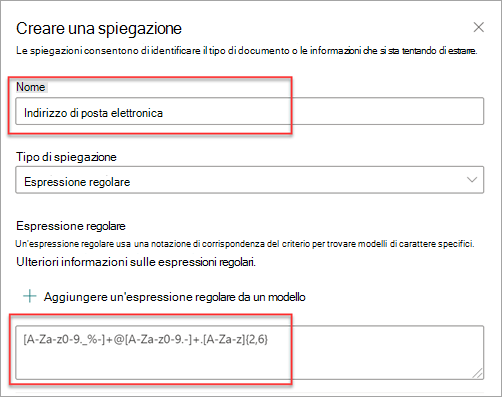
È possibile digitare un'espressione nella casella di testo Espressione regolare o selezionare Aggiungi un'espressione regolare da un modello.
Quando si aggiunge un'espressione regolare usando un modello, il nome e l'espressione regolare vengono aggiunti automaticamente alla casella di testo. Ad esempio, se si sceglie il modello di indirizzo Email, viene popolato il pannello Crea una spiegazione.
Limitazioni
La tabella seguente mostra le opzioni di caratteri inline che attualmente non sono disponibili per l'uso nei modelli di espressione regolare.
| Opzione | Stato | Funzionalità corrente |
|---|---|---|
| Distinzione tra maiuscole e minuscole | Attualmente non supportato. | Per le corrispondenze non viene fatta distinzione tra maiuscole e minuscole. |
| Ancoraggi di riga | Attualmente non supportato. | Non è possibile specificare una posizione specifica in una stringa in cui deve essere trovata una corrispondenza. |
Prossimità
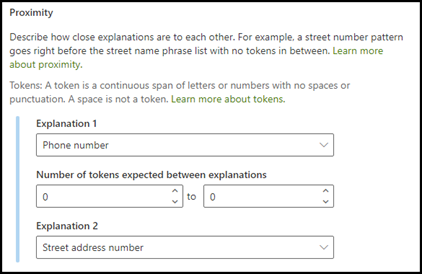
Il tipo di spiegazione prossimità consente al modello di identificare i dati definendo il rapporto di prossimità rispetto ad altri dati. Nel modello, ad esempio, sono state definite due spiegazioni che etichettano il Numero civico e il Numero di telefono del cliente.
Si nota anche che i numeri di telefono del cliente vengono sempre visualizzati sempre prima del numero civico.
Davide Milano
555-555-5555
One Microsoft Way
Redmond, WA 98034
Usare la spiegazione di prossimità per definire quanto è lontana la spiegazione del numero di telefono, per identificare meglio il numero civico nei documenti.
Nota
Le espressioni regolari attualmente non possono essere usate con il tipo di spiegazione di prossimità.
Che cosa sono i token?
Per usare il tipo di spiegazione di prossimità, è necessario comprendere che cos'è un token. Il numero di token è il sistema usato dalla spiegazione di prossimità per misurare la distanza tra una spiegazione e l'altra. Un token è una serie continua di lettere e numeri, senza spazi o punteggiatura.
Nella tabella seguente sono illustrati alcuni esempi per determinare il numero di token in una frase.
| Frase | Numero di token | Spiegazione |
|---|---|---|
Dog |
1 | Una singola parola senza punteggiatura o spazi. |
RMT33W |
1 | Un numero di localizzazione record. Può includere numeri e lettere, ma non include segni di punteggiatura. |
425-555-5555 |
5 | Un numero di telefono. Ogni segno di punteggiatura è un token, quindi 425-555-5555 corrisponde a 5 token:425-555-5555 |
https://luis.ai |
7 | https://luis.ai |
Configurare il tipo di spiegazione di prossimità
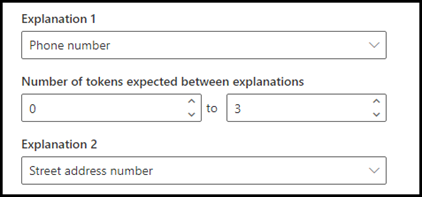
Per questo esempio, configurare l'impostazione di prossimità in modo da poter definire l'intervallo del numero di token di distanza nella spiegazione numero di telefono dalla spiegazione numero civico. Si noti che l'intervallo minimo dovrebbe risultare "0" perché non c'è nessun token tra il numero di telefono e il numero civico.
Dopo alcuni numeri di telefono nei documenti di esempio, invece, è presente la dicitura (cellulare).
Luca Udinesi
111-111-1111 (cellulare)
One Microsoft Way
Redmond, WA 98034
In (cellulare) sono presenti tre token:
| Frase | Numero di token |
|---|---|
| ( | 1 |
| cellulare | 2 |
| ) | 3 |
Configurare l'impostazione di prossimità su un intervallo compreso tra 0 e 3.
Configurare la posizione delle frasi nel documento
Quando si crea una spiegazione, per impostazione predefinita viene cercata nell'intero documento la frase che si vuole estrarre. Tuttavia, è possibile usare l'impostazione avanzata Dove si trovano queste frasi per isolare una posizione specifica nel documento in cui si trova una frase. Questa impostazione è utile nei casi in cui istanze simili di una frase potrebbero comparire in un altro punto del documento e si vuole verificare che sia selezionata quella corretta.
Facendo riferimento all'esempio relativo al documento di richiesta di visita specialistica il medico richiedente viene sempre menzionato nel primo paragrafo del documento. Con l'impostazione Dove si trovano queste frasi, in questo esempio è possibile configurare la spiegazione per la ricerca di questa etichetta solo nella sezione iniziale del documento o in qualsiasi altra posizione in cui potrebbe essere presente.
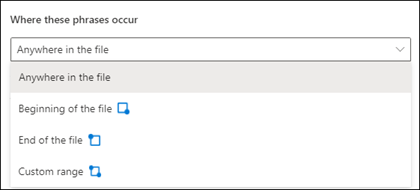
Per questa impostazione è possibile scegliere le opzioni seguenti:
Ovunque nel file: la frase viene cercata nell'intero documento.
Inizio del file: viene eseguita la ricerca nel documento dall'inizio al percorso della frase.
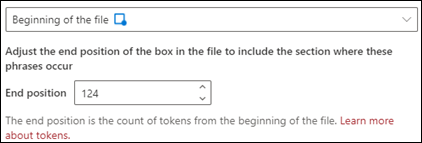
Nel visualizzatore è possibile modificare manualmente la casella di selezione in modo da includere la posizione in cui si trova la fase. Il valore della posizione finale viene aggiornato per mostrare il numero di token inclusi nell'area selezionata. È possibile aggiornare il valore Posizione finale anche per modificare l'area selezionata.
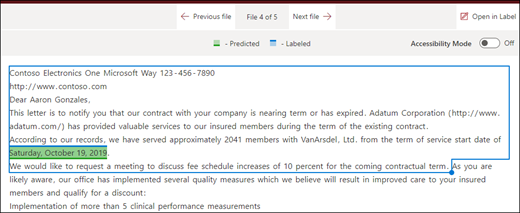
Fine del file: Il documento viene cercato dalla fine alla posizione della frase.
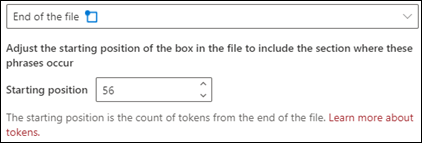
Nel visualizzatore è possibile modificare manualmente la casella di selezione in modo da includere la posizione in cui si trova la fase. Il valore della posizione iniziale viene aggiornato per mostrare il numero di token inclusi nell'area selezionata. È possibile aggiornare il valore Posizione iniziale anche per modificare l'area selezionata.

Intervallo personalizzato: Il documento viene cercato entro uno specifico intervallo per la posizione della frase.
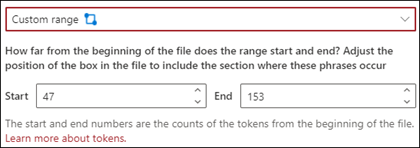
Nel visualizzatore è possibile modificare manualmente la casella di selezione in modo da includere la posizione in cui si trova la fase. Per questa impostazione è necessario selezionare una posizione di Inizio e di Fine. Questi valori rappresentano il numero di token dall'inizio del documento. Anche se è possibile immettere manualmente questi valori, è più facile modificare manualmente la casella di selezione nel visualizzatore.
Considerazioni sulla configurazione delle spiegazioni
Quando si esegue il training di un classificatore, è necessario tenere presente alcuni aspetti che producono risultati più prevedibili:
Più documenti si esegue il training, più accurato sarà il classificatore. Quando possibile, usare più di cinque documenti validi e usare più di un documento non valido. Se le librerie in uso includono diversi tipi di documento, molti di ogni tipo portano a risultati più prevedibili.
L'etichettatura del documento svolge un ruolo importante nel processo di training. Vengono usati insieme alle spiegazioni per eseguire il training del modello. È possibile che vengano visualizzate alcune anomalie durante il training di un classificatore con documenti che non includono molto contenuto. La spiegazione potrebbe non corrispondere a nulla nel documento, ma poiché è stata etichettata come documento "valido", è possibile che si tratti di una corrispondenza durante il training.
Quando si creano spiegazioni, usa la logica OR in combinazione con l'etichetta per determinare se si tratta di una corrispondenza. L'espressione regolare che usa la logica AND potrebbe essere più prevedibile. Ecco un'espressione regolare di esempio da usare nei documenti reali durante il training. Si noti che il testo evidenziato in rosso è la frase o le frasi che si sta cercando.
(?=.*network provider)(?=.*participating providers).*
Le etichette e le spiegazioni interagiscono e vengono usate per il training del modello. Non si tratta di una serie di regole che possono essere deaccoppiati e precisi pesi o stime applicati a ogni variabile configurata. Maggiore sarà la variazione dei documenti usati nel training, maggiore sarà l'accuratezza del modello.