自然言語処理 (NLP) には、感情分析、トピック検出、言語検出、キー フレーズ抽出、ドキュメント分類など、多くのアプリケーションがあります。
具体的には、NLP を使用して次のことができます。
- たとえば、機密またはスパムとしてラベル付けするドキュメントを分類します。
- NLP 出力を使用して後続の処理または検索を実行します。
- ドキュメント内のエンティティを識別してテキストを要約します。
- 識別されたエンティティを使用して、キーワードを使用してドキュメントにタグ付けします。
- タグ付けを使用してコンテンツベースの検索と取得を行います。
- 識別されたエンティティを使用して、ドキュメントの主要なトピックを要約します。
- 検出されたトピックを利用して、ナビゲーション用のドキュメントを分類します。
- 選択したトピックに基づいて関連ドキュメントを列挙します。
- テキストセンチメントを評価して、肯定的または否定的なトーンを理解します。
テクノロジの進歩により、NLP を使用してテキスト データの分類と分析を行うだけでなく、多様なドメインにわたって解釈可能な AI 機能を強化することもできます。 大規模言語モデル (LLM) の統合により、NLP の機能が大幅に強化されます。 GPT や BERT などの LLM は、人間のようなコンテキストに対応したテキストを生成できるため、複雑な言語処理タスクに非常に効果的です。 彼らは、特に Databricks'Dolly 2.0などのモデルで、会話システムと顧客エンゲージメントを向上させる、より広範なコグニティブ タスクを処理することで、既存の NLP 手法を補完します。
言語モデルと NLP の関係と相違点
NLPは、人間の言語を処理するための様々な技術を含む包括的な分野です。 一方、言語モデルは NLP 内の特定のサブセットであり、高度な言語タスクを実行するためのディープ ラーニングに焦点を当てています。 言語モデルは高度なテキスト生成機能と理解機能を提供することで NLP を強化しますが、NLP と同義ではありません。 代わりに、より広範な NLP ドメイン内の強力なツールとして機能し、より高度な言語処理を可能にします。
手記
この記事では、NLP に焦点を当てています。 NLP と言語モデルの関係は、言語モデルが優れた言語理解と生成機能を通じて NLP プロセスを強化することを示しています。
Apache®、 Apache Spark、および炎のロゴは、Apache Software Foundation の米国およびその他の国における登録商標です。 これらのマークを使用することが、Apache Software Foundation による保証を意味するものではありません。
考えられるユース ケース
カスタム NLP のメリットを得られるビジネス シナリオは次のとおりです。
- 財務、医療、小売、政府機関、その他のセクターで手書きまたは機械で作成されたドキュメントのドキュメント インテリジェンス。
- 名前エンティティ認識 (NER)、分類、要約、リレーションシップ抽出などの、テキスト処理のための業界に依存しない NLP タスク。 これらのタスクにより、テキストや非構造化データなどのドキュメント情報を取得、識別、分析するプロセスが自動化されます。 これらのタスクの例としては、リスク階層化モデル、オントロジ分類、小売りの要約などがあります。
- セマンティック検索のための情報取得とナレッジ グラフの作成。 この機能により、創薬や臨床試験をサポートする医療知識グラフを作成できます。
- 小売、金融、旅行、その他の業界にわたる顧客向けアプリケーションでの会話型 AI システムのテキスト翻訳。
- 特にブランドの認識と顧客フィードバック分析を監視するために、分析における感情と感情インテリジェンスの強化。
- レポートの自動生成。 構造化されたデータ入力から包括的なテキスト レポートを合成して生成し、財務やコンプライアンスなどの分野で、徹底的なドキュメントが必要な場合に役立ちます。
- 音声認識と自然な会話機能のために NLP を統合することで、IoT およびスマート デバイス アプリケーションでのユーザー操作を強化する音声アクティブ化インターフェイス。
- さまざまな対象ユーザーの理解レベルに合わせて言語出力を動的に調整する適応言語モデルは、教育コンテンツとアクセシビリティの向上に不可欠です。
- 通信パターンと言語の使用状況をリアルタイムで分析し、デジタル通信における潜在的なセキュリティ上の脅威を特定するためのサイバーセキュリティ テキスト分析により、フィッシング詐欺の試行や誤った情報の検出が向上します。
カスタマイズされた NLP フレームワークとしての Apache Spark
Apache Spark は、メモリ内処理を通じてビッグ データ分析アプリケーションのパフォーマンスを向上させる強力な並列処理フレームワークです。 Azure Synapse Analytics、
カスタマイズされた NLP ワークロードの場合、Spark NLP は膨大な量のテキストを処理できる効率的なフレームワークであり続けます。 このオープンソース ライブラリは、Python、Java、Scala ライブラリを通じて広範な機能を提供します。このライブラリは、spaCy や NLTK などの著名な NLP ライブラリに含まれる高度な機能を提供します。 Spark NLP には、スペル チェック、センチメント分析、ドキュメント分類などの高度な機能が含まれており、常に最新の精度とスケーラビリティを確保します。
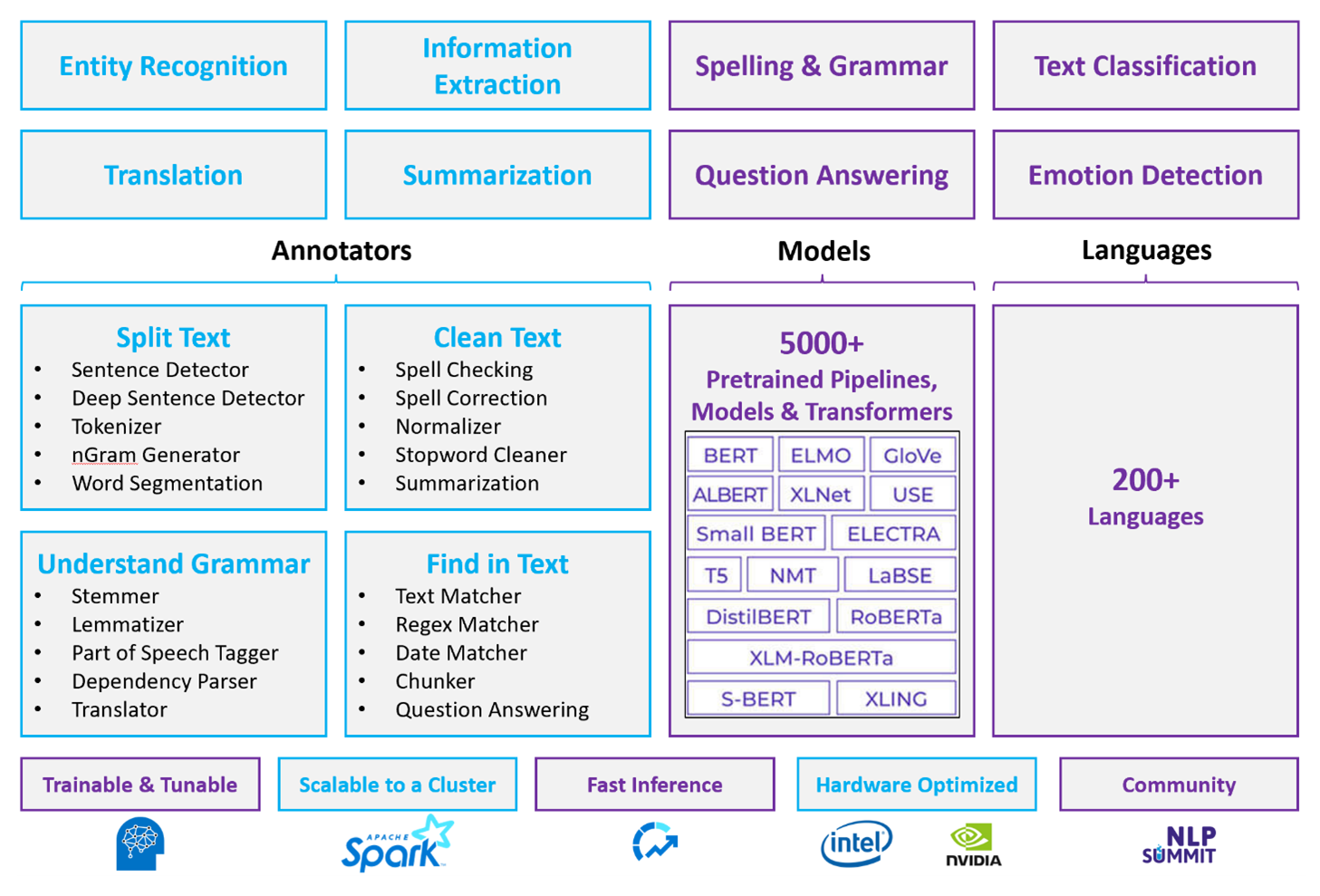
最近のパブリック ベンチマークでは、Spark NLP のパフォーマンスが強調され、カスタム モデルのトレーニングに同等の精度を維持しながら、他のライブラリに比べて大幅な速度の向上が示されています。 特に、Llama-2 モデルと OpenAI ささやきの統合により、会話インターフェイスと多言語音声認識が強化され、最適化された処理機能が大幅に向上します。
一意に、Spark NLP は分散 Spark クラスターを効果的に利用し、データ フレームで直接動作する Spark ML のネイティブ拡張機能として機能します。 この統合では、クラスターのパフォーマンス向上がサポートされ、ドキュメント分類やリスク予測などのタスク用の統合 NLP と機械学習パイプラインの作成が容易になります。 MPNet 埋め込みと広範な ONNX サポートの導入により、これらの機能がさらに強化され、正確でコンテキストに対応した処理が可能になります。
Spark NLP は、パフォーマンス上の利点を超えて、NLP タスクの拡張配列全体で最先端の精度を提供します。 このライブラリには、名前付きエンティティ認識、ドキュメント分類、センチメント検出などの事前構築済みのディープ ラーニング モデルが付属しています。 その機能豊富な設計には、単語、チャンク、文、ドキュメントの埋め込みをサポートする事前トレーニング済みの言語モデルが含まれています。
CPU、GPU、最新の Intel Xeon チップ用に最適化されたビルドにより、Spark NLP のインフラストラクチャはスケーラビリティを実現するように設計されており、トレーニングと推論のプロセスで Spark クラスターを完全に利用できます。 これにより、多様な環境やアプリケーションにわたるNLPタスクの効率的な処理が保証され、NLPイノベーションの最前線での地位を維持します。
課題
処理リソース: 自由形式のテキスト ドキュメントのコレクションを処理するには、大量の計算リソースが必要であり、処理にも時間がかかります。 多くの場合、この種の処理には GPU コンピューティングのデプロイが含まれます。 量子化をサポートする Llama-2 のような Spark NLP アーキテクチャの最適化など、最近の進歩は、これらの集中的なタスクを効率化し、リソースの割り当てを効率的にするのに役立ちます。
標準化の問題: 標準化されたドキュメント形式がないと、自由形式のテキスト処理を使用してドキュメントから特定の事実を抽出するときに、一貫して正確な結果を得るのは困難な場合があります。 たとえば、さまざまな請求書から請求書番号と日付を抽出すると、課題が発生します。 M2M100のような適応可能なNLPモデルの統合により、複数の言語やフォーマットにわたる処理精度が向上し、結果の一貫性が向上しました。
データの多様性と複雑さ: さまざまなドキュメント構造と言語的な微妙な差異に対処することは、依然として複雑です。 MPNet 埋め込みなどのイノベーションにより、コンテキスト理解が強化され、多様なテキスト形式をより直感的に処理でき、全体的なデータ処理の信頼性が向上します。
主要な選択条件
Azure では、Azure Databricks、Microsoft Fabric、Azure HDInsight などの Spark サービスは、Spark NLP と共に使用する場合に NLP 機能を提供します。 Azure AI サービスは、NLP 機能のもう 1 つのオプションです。 使用するサービスを決定するには、次の質問を検討してください。
事前構築済みまたは事前トレーニング済みのモデルを使用しますか。 該当する場合は、Azure AI サービスが提供する API の使用を検討するか、Spark NLP を使用して選択したモデルをダウンロードします。これには、強化された機能のための Llama-2 や MPNet などの高度なモデルが含まれるようになりました。
テキスト データの大規模なコーパスに対してカスタム モデルをトレーニングする必要がありますか。 該当する場合は、Spark NLP で Azure Databricks、Microsoft Fabric、または Azure HDInsight を使用することを検討してください。 これらのプラットフォームは、広範なモデル トレーニングに必要な計算能力と柔軟性を提供します。
トークン化、ステミング、レンマ化、単語の出現頻度/逆文書頻度 (TF/IDF) のような低レベルの NLP 機能が必要ですか。 該当する場合は、Spark NLP で Azure Databricks、Microsoft Fabric、または Azure HDInsight を使用することを検討してください。 または、任意の処理ツールでオープンソースのソフトウェア ライブラリを使用します。
エンティティと意図の識別、トピック検出、スペル チェック、センチメント分析などのシンプルで高レベルの NLP 機能が必要ですか。 "はい" の場合は、Azure AI サービスが提供する API の使用を検討してください。 または、Spark NLP を使用して選択したモデルをダウンロードして、これらのタスクに事前構築済みの関数を利用します。
機能のマトリックス
次の表は、NLP サービスの機能の主な相違点をまとめたものです。
一般的な機能
| 機能 | Spark NLP を使用した Spark サービス (Azure Databricks、Microsoft Fabric、Azure HDInsight) | Azure AI サービス |
|---|---|---|
| サービスとして事前トレーニング済みモデルを提供 | はい | はい |
| REST API | はい | はい |
| プログラミング | Python、Scala | サポートされている言語については、「その他のリソース」を参照してください |
| 大規模なデータ セットとサイズの大きいドキュメントの処理のサポート | はい | いいえ |
低レベルの NLP 機能
アノテーターの機能
| 機能 | Spark NLP を使用した Spark サービス (Azure Databricks、Microsoft Fabric、Azure HDInsight) | Azure AI サービス |
|---|---|---|
| 文検出機能 | はい | いいえ |
| 文のディープ検出機能 | はい | はい |
| Tokenizer | はい | はい |
| N グラム ジェネレーター | はい | いいえ |
| 単語のセグメント化 | はい | はい |
| ステマー | はい | いいえ |
| レンマタイザー | はい | いいえ |
| 品詞のタグ付け | はい | いいえ |
| 依存関係パーサー | はい | いいえ |
| 翻訳 | はい | いいえ |
| ストップワード クリーナー | はい | いいえ |
| スペル修正 | はい | いいえ |
| ノーマライザー | はい | はい |
| テキスト マッチャー | はい | いいえ |
| TF/IDF | はい | いいえ |
| 正規表現マッチャー | はい | Conversational Language Understanding (CLU) への埋め込み |
| 日付マッチャー | はい | DateTime 認識エンジンを介して CLU で可能 |
| Chunker | はい | いいえ |
手記
Microsoft Language Understanding (LUIS) は、2025 年 10 月 1 日に廃止されます。 既存の LUIS アプリケーションは、言語理解機能を強化し、新機能を提供する Azure AI Services for Language の機能である Conversational Language Understanding (CLU) に移行することをお勧めします。
高レベルの NLP 機能
| 機能 | Spark NLP を使用した Spark サービス (Azure Databricks、Microsoft Fabric、Azure HDInsight) | Azure AI サービス |
|---|---|---|
| スペル チェック | はい | いいえ |
| 概要 | はい | はい |
| 質問応答 | はい | はい |
| センチメント検出 | はい | はい |
| 感情検出 | はい | オピニオン マイニングをサポート |
| トークンの分類 | はい | はい (カスタム モデルを使用) |
| テキスト分類 | はい | はい (カスタム モデルを使用) |
| テキスト表現 | はい | いいえ |
| NER | はい | はい - テキスト分析が一連の NER を提供し、カスタム モデルがエンティティ認識内にあります |
| エンティティ認識 | はい | はい (カスタム モデルを使用) |
| 言語検出 | はい | はい |
| 英語以外の言語のサポート | はい、200 を超える言語をサポート | はい、97 を超える言語をサポート |
Azure で Spark NLP を設定する
Spark NLP をインストールするには、次のコードを使用しますが、 <version> を最新のバージョン番号に置き換えます。 詳細については、 Spark NLP のドキュメントを参照してください。
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
NLP パイプラインを開発する
NLP パイプラインの実行順序については、Spark NLP は従来の Spark ML 機械学習モデルと同じ開発概念に従い、特殊な NLP 手法を適用します。
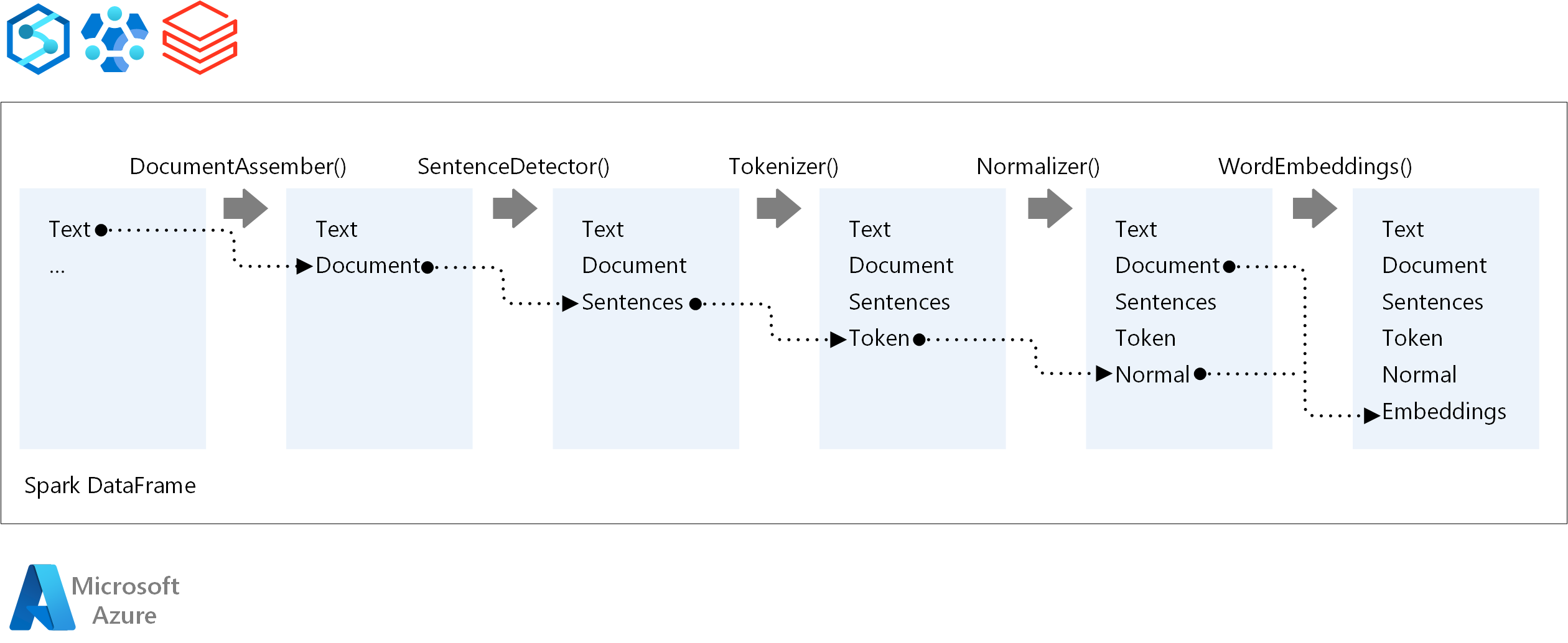
Spark NLP パイプラインのコア コンポーネントは次のとおりです。
DocumentAssembler: Spark NLP で処理できる形式に変換してデータを準備するトランスフォーマー。 このステージは、すべての Spark NLP パイプラインのエントリ ポイントです。 DocumentAssembler は、
String列またはArray[String]を読み取り、既定ではオフになっているsetCleanupModeを使用してテキストを前処理するオプションを指定します。SentenceDetector: 定義済みのアプローチを使用して文の境界を識別するアノテーター。
explodeSentencesが true に設定されている場合は、検出された各文をArrayまたは個別の行に返すことができます。Tokenizer: 未加工のテキストを個別のトークン (単語、数字、記号) に分割し、これらを
TokenizedSentenceとして出力するアノテーターです。 Tokenizer は適合されておらず、RuleFactory内の入力構成を使用してトークン化ルールを作成します。 既定値が不十分な場合は、カスタム ルールを追加できます。ノーマライザー: トークンの絞り込みを行うアノテーター。 ノーマライザーは、正規表現と辞書変換を適用してテキストをクリーンアップし、余分な文字を削除します。
WordEmbeddings: トークンをベクトルにマップするアノテーターを参照し、セマンティック処理を容易にします。
setStoragePathを使用してカスタム埋め込みディクショナリを指定できます。各行には、スペースで区切られたトークンとそのベクターが含まれます。 未解決のトークンの既定値は 0 個のベクトルです。
Spark NLP は Spark MLlib パイプラインを活用し、機械学習のライフサイクルを管理するオープンソース プラットフォームである MLflowからのネイティブ サポートを提供します。 MLflow の主要なコンポーネントは次のとおりです。
MLflow Tracking: 試験的な実行を記録し、結果を分析するための堅牢なクエリ機能を提供します。
MLflow Projects: 多様なプラットフォームでデータ サイエンス コードを実行でき、移植性と再現性が向上します。
MLflow モデル: 一貫性のあるフレームワークを使用して、さまざまな環境にわたる汎用性の高いモデルのデプロイをサポートします。
モデル レジストリ: 包括的なモデル管理を提供し、効率的なアクセスとデプロイのためにバージョンを一元的に格納し、運用の準備を容易にします。
MLflow は Azure Databricks などのプラットフォームと統合されていますが、他の Spark ベースの環境にインストールして実験を管理および追跡することもできます。 この統合により、MLflow モデル レジストリを使用してモデルを運用環境で使用できるようになり、デプロイ プロセスが合理化され、モデル ガバナンスが維持されます。
Spark NLP と共に MLflow を使用することで、NLP パイプラインの効率的な管理とデプロイを確保し、単語埋め込みや大規模な言語モデルの適応などの高度な手法をサポートしながら、スケーラビリティと統合に関する最新の要件に対応できます。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパルの作成者:
- フレディ・アヤラ |クラウド ソリューション アーキテクト
- Moritz Steller | シニア クラウド ソリューション アーキテクト
次のステップ
Spark NLP のドキュメント
Azure コンポーネント
- Microsoft Fabric の
- Azure HDInsight
- Azure Databricks
- Cognitive Services
- Microsoft Fabric の
Learn リソース: