データを統合するために各テーブルの重複を削除します
重複排除ルールのステップでは、各顧客が各テーブルの単一の行で表されるように、ソーステーブルから顧客の重複レコードを検出して削除します。 各テーブルは、特定の顧客のレコードを識別するルールを使用して個別に重複排除されます。
ルールは順番に処理されます。 すべてのルールがテーブル内のすべてのレコードに対して実行された後、共通の行を共有する一致グループが 1 つの一致グループに結合されます。
重複排除ルールを定義する
適切なルールは、固有の顧客を識別します。 データを考慮します。 E メールなどのフィールドに基づいて顧客を識別するだけでも十分かもしれません。 しかし、E メールを共有する顧客を区別したい場合は、2 つの条件を持つルールを選択することができます。 詳細については、重複排除のベストプラクティスのラーニング パスを参照してください。
重複排除ルール ページで、テーブルを選択し、ルールの追加 を選択して重複排除ルールを定義します。
チップ
統合結果を改善するためにデータ ソース レベルでテーブルをエンリッチした場合は、ページ上部でエンリッチされたテーブルを使用するを選択します。 詳細については、データ ソースのエンリッチメント を参照してください。

ルールの追加ウィンドウに、次の情報を入力します。
フィールドを選択: 重複を確認するテーブルの使用可能なフィールドのリストから選択します。 各顧客に固有である可能性が高いフィールドを選択します。 たとえば、電子メール アドレス、または名前、都市、電話番号の組み合わせです。
正規化: 列の正規化オプションを選択します。 正規化は照合ステップにのみ影響し、データは変更されません。
正規化 使用例 数字 数値を表す多くの Unicode 記号を単純な数値に変換します。
例: ❽ と Ⅷ は両方とも数値 8 に正規化されます。
注意: シンボルは Unicode ポイント形式でエンコードする必要があります。シンボル 記号と特殊文字を削除します。
例: !?"#$%&'( )+,.-/:;<=>@^~{}`[ ]テキストから小文字 大文字を小文字に変換します。
例: 「THIS Is aN EXamplE」 は 「this is an example」 に変換されますタイプ – 電話 さまざまな形式の電話を数字に変換し、国番号と内線番号の表示方法の違いを考慮します。 記号と空白は無視されます。 国コードの先頭の「0」は無視され、+1 と +01 が一致します。 文字の接頭辞で示される拡張子は無視されます (X 123)。 正規化された国コードは重要で ある ため、国コードのある電話は、国番号のない電話とは一致しません。
例: +01 425.555.1212 は 1 (425) 555-1212 と一致します。
+01 425.555.1212 は (425) 555-1212 と一致しませんタイプ - 名前 500 を超える一般的な名前のバリエーションとタイトルを変換します。
例 : 「debby」 -> 「deborah」 「prof」 および 「professor」 -> 「Prof.」タイプ - 住所 アドレスの共通部分を変換する
例: 「street」 -> 「st」、「northwest」 -> 「nw」タイプ - 組織 「co」、「corp」、「corporation」、「ltd」 など、約 50 の会社名の「ノイズ ワード」を削除します。 Unicode から ASCII Unicode 文字列を、同等の ASCII 文字に変換する
例: 文字 「à」、「á」、「â」、「À」、「Á」、「Â」、「Ã」、「Ä」、「Ⓐ」、「A」 はすべて 「a」 に変換されます。空白 すべての空白スペースを削除する エイリアス マッピング 常に完全一致とみなされるべき文字列を示すために使用できる文字列ペアのカスタム リストをアップロードできます。
一致する必要があると思われる特定のデータ例があり、他の正規化パターンのいずれかを使用しても一致しない場合は、エイリアス マッピングを使用します。
例: Scott と Scooter、MSFT と Microsoft。カスタムのバイパス 一致すべきではない文字列を示すために使用できる文字列のカスタム リストをアップロードできます。
カスタム バイパスは、ダミーの電話番号やダミーのメールなど、無視する必要がある一般的な値を持つデータがある場合に便利です。
例: 電話番号 555-1212、または test@contoso.com とは決して一致しない
精度: 精度のレベルを設定します。 精度は、完全一致とあいまい一致に使用され、一致と見なされるために 2 つの文字列がどの程度近づく必要があるかを決定します。
- 基本: 低 (30%)、中 (60%)、高 (80%)、完全一致t (100%) から選択します。 100%一致するレコードのみを一致とする場合は 完全一致 を選択します。
- カスタム: レコードが一致する必要がある割合を設定します。 システムは、このしきい値を超えるレコードのみを照合します。
名前: ルールの名前です。
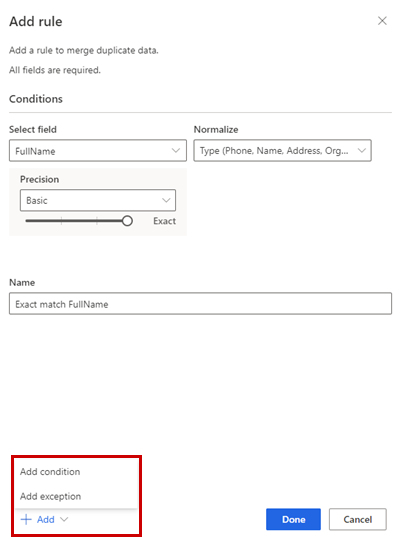
必要に応じて、追加>条件を追加を選択し、ルールに条件を追加します。 条件は論理 AND 演算子で接続されるため、すべての条件が満たされた場合にのみ実行されます。
必要に応じて、追加>例外の追加にルールに例外を追加 します。 例外は、誤検知と擬陰性のまれなケースに対処するために使用されます。
完了を選択してルールを作成します。
オプションで、ルールをさらに追加 します。

マージ設定を選択する
ルールが実行され、顧客の重複レコードが識別されると、マージ ポリシーに基づいて "勝者行" が選択されます。 勝者の行は、テーブル間のレコードを照合する次の統合ステップの顧客を表します。 非勝者 ("代替") 行のデータは、照合ルールの統合ステップで、他のテーブルのレコードを勝者行と照合するために使用されます。 このアプローチでは、以前の電話番号などの情報が一致するレコードの識別に役立つため、照合結果が向上します。 勝者の行は、見つかった重複レコードのうち、最も入力されたもの、最新のもの、または最新でないものになるように構成できます。
テーブルを選択し、次にマージの基本設定を編集するを選択します。 マージの基本設定 ウィンドウが表示されます。
3 つのオプションのいずれかを選択して、重複が見つかった場合に保持するレコードを決定します。
- 最も多く入力された: 最も多くの列が入力されたレコードを優先するレコードとみなします。 既定のマージ オプションです。
- 最も新しい: 最新性に基づいて勝者レコードを識別します。 最新を定義するには、日付または数値フィールドが必要です。
- 最も古い: 最も古いレコードに基づいて勝者レコードを識別します。 最新を定義するには、日付または数値フィールドが必要です。
同点の場合、勝者レコードは MAX(PK) またはより大きな主キー値を持つレコードです。
オプションで、テーブルの個々の列に対するマージ設定を定義するには、ペインの下部にある 詳細設定 を選択します。 たとえば、最新のメールと最も完全なアドレスを異なるレコードから保持することを選択できます。 テーブルを展開してすべての列を表示し、個々の列に使用するオプションを定義します。 最新性に基づくオプションを選択する場合は、最新性を定義する日付/時刻フィールドも指定する必要があります。
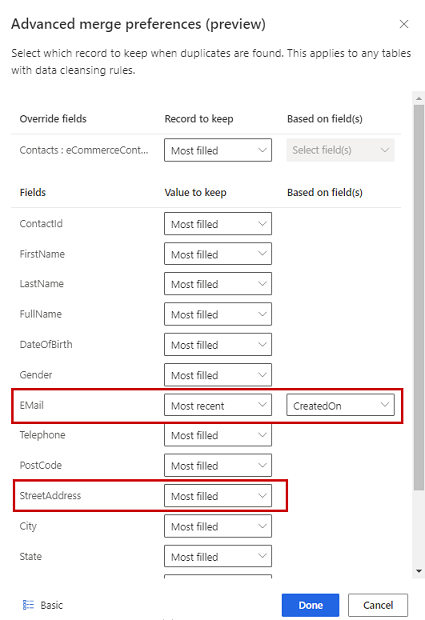
完了を選択して、マージ設定を適用します。
重複排除ルールとマージ設定を定義した後、次へを選択します。