Dataflow Gen2 での増分更新 (プレビュー)
この記事では、Microsoft Fabric の Data Factory 用の Dataflow Gen2 での増分データ更新について説明します。 データ インジェストと変換にデータフローを使用する場合、とりわけデータが増え続けているときは、新しい、または更新されたデータのみを特に更新することが必要になるシナリオがあります。 増分更新はこのニーズに対応する機能であり、更新時間を短縮し、実行時間の長い操作を回避して信頼性を向上させ、リソース使用量を最小限に抑えることができます。
前提条件
Dataflow Gen2 で増分更新を使うには、次の前提条件を満たす必要があります。
- Fabric 容量が必要です。
- データ ソースがフォールディング (推奨) をサポートしており、データのフィルター処理に使用できる Date/DateTime 列を含んでいる必要があります。
- 増分更新をサポートするデータ格納先が必要です。 詳しくは、「格納先のサポート」をご覧ください。
- 始める前に、増分更新の制限事項を確認してください。 詳しくは、「制限事項」をご覧ください。
格納先のサポート
増分更新では、次のデータ格納先がサポートされています。
- Fabric Warehouse
- Azure SQL データベース
- Azure Synapse Analytics
Lakehouse などの他の格納先は、ステージング データを参照する 2 つ目のクエリを使ってデータ格納先を更新することで、増分更新と組み合わせて使用できます。 このようにしてもやはり、増分更新を使って、ソース システムから処理および取得する必要があるデータの量を減らすことができます。 ただし、ステージング データからデータ格納先への完全な更新を行う必要があります。
増分更新を使用する方法
新しい Dataflow Gen2 を作成するか、既存の Dataflow Gen2 を開きます。
データフロー エディターで、増分更新するデータを取得する新しいクエリを作成します。
データのプレビューを調べて、データのフィルター処理に使用できる DateTime、Date、または DateTimeZone 列を含むデータがクエリから返されることを確認します。
クエリが完全にフォールドしていることを確認します。つまり、クエリがソース システムまで完全にプッシュダウンされます。 クエリが完全にフォールドしていない場合は、完全にフォールドするようにクエリを変更する必要があります。 クエリ エディターでクエリ手順を調べて、クエリが完全にフォールドすることを確認できます。
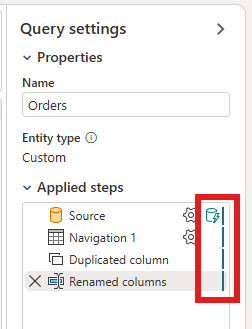
クエリを右クリックして、[増分更新] を選びます。
増分更新に必要な設定を指定します。
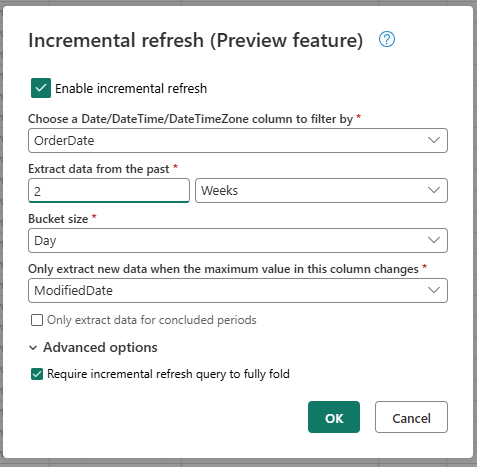
- フィルター処理する DateTime 列を選択する。
- 過去のデータを抽出する。
- バケット サイズ。
- この列の最大値が変更された場合にのみ、新しいデータを抽出する。
必要に応じて詳細設定を構成します。
- 増分更新クエリを完全に折りたたむ必要があります。
[OK] を選択して設定を保存します。
必要に応じて、クエリのデータ格納先を設定できます。 最初の増分更新の前にこの設定を行う必要があります。そうしないと、データの格納先には前回の更新以降に増分変更されたデータのみが含まれます。
データフロー (Gen2) を発行します。
増分更新を構成した後は、指定した設定に基づき、データフローによってデータが自動的に増分更新されます。 データフローでは、前回の更新以降に変更されたデータのみが取得されます。 そのため、データフローの実行速度は速く、消費されるリソースは少なくなります。
増分更新のバックグラウンドでの動作
増分更新は、DateTime 列に基づいてデータをバケットに分割することで機能します。 各バケットには、前回の更新以降に変更されたデータが含まれます。 データフローは、ユーザーが指定した列の最大値を調べて、何が変わったかを認識します。 そのバケットの最大値が変わった場合、データフローはバケット全体を取得して、格納先のデータを置き換えます。 最大値が変わらなかった場合、データフローはデータを何も取得しません。 以降のセクションでは、増分更新のしくみの概要をステップごとに説明します。
最初のステップ: 変化を評価する
データフローは実行すると、最初にデータ ソースの変化を評価します。 この評価では、DateTime 列の最大値と前回の更新での最大値が比較されます。 最大値が変わった場合、または最初の更新の場合、データフローはバケットを変更ありとしてマークし、処理のために一覧を取得します。 最大値が変わっていない場合、データフローはそのバケットをスキップして処理しません。
2 番目のステップ: データを取得する
この段階で、データフローはデータを取得する準備ができています。 変更のあった各バケットのデータを取得します。 データフローは、パフォーマンスを向上させるため、この取得を並列で行います。 データフローは、ソース システムからデータを取得し、ステージング領域に読み込みます。 データフローは、バケットの範囲内のデータのみを取得します。 つまり、データフローは前回の更新以降に変わったデータのみを取得します。
最後のステップ: データ格納先のデータを置き換える
データフローは、格納先のデータを新しいデータに置き換えます。 データフローは、replace メソッドを使って、格納先のデータを置き換えます。 つまり、データフローは最初にそのバケットの格納先のデータを削除してから、新しいデータを挿入します。 データフローは、バケットの範囲外にあるデータには影響を与えません。 そのため、格納先に最初のバケットより古いデータがある場合、このデータは増分更新によってどのような影響も受けません。
増分更新の設定の説明
増分更新を構成するには、次の設定を指定する必要があります。
全般設定
一般的な設定は必須であり、増分更新の基本構成を指定します。
フィルター処理する DateTime 列を選択する
この設定は必須であり、データフローがデータのフィルター処理に使う列を指定します。 この列は、DateTime、Date、DateTimeZone 列のいずれかである必要があります。 データフローは、この列を使ってデータをフィルター処理し、前回の更新以降に変更されたデータのみを取得します。
過去のデータを抽出する
この設定は必須であり、データフローが時間を遡ってデータを抽出する長さを指定します。 この設定は、初期データの読み込みを取得するために使われます。 データフローは、ソース システムから指定された時間範囲内のすべてのデータを取得します。 次のいずれかの値になります。
- x 日
- x 週
- x か月
- x 四半期
- x 年
たとえば、1 か月を指定した場合、データフローはソース システムから過去 1 か月以内の新しいデータをすべて取得します。
バケット サイズ
この設定は必須であり、データフローがデータのフィルター処理に使うバケットのサイズを指定します。 データフローは、DateTime 列に基づいてデータをバケットに分割します。 各バケットには、前回の更新以降に変更されたデータが含まれます。 バケット サイズによって、各繰り返しで処理されるデータの量が決まります。 バケット サイズが小さいほど、各繰り返しで処理されるデータの量は少なくなりますが、すべてのデータを処理するために必要な繰り返しは増えます。 バケット サイズが大きいほど、各繰り返しで処理されるデータの量は多くなりますが、すべてのデータを処理するために必要な繰り返しは減ります。
この列の最大値が変更された場合にのみ、新しいデータを抽出する
この設定は必須であり、データが変わったかどうかをデータフローが判断するために使う列を指定します。 データフローは、この列の最大値と、前回の更新での最大値を比べます。 最大値が変更された場合、データフローは前回の更新以降に変更されたデータを取得します。 最大値が変更されていない場合、データフローはデータを何も取得しません。
終了した期間のデータのみを抽出する
この設定は省略可能であり、データフローが終了した期間のデータのみを抽出するかどうかを指定します。 この設定を有効にすると、データフローは終了した期間のデータのみを抽出します。 そのため、データフローは、完了した期間のデータのみを抽出し、将来のデータは含めません。 この設定を無効にすると、データフローは、完了しておらず将来のデータを含む期間も含めて、すべての期間のデータを抽出します。
たとえば、トランザクションの日付を含む DateTime 列があり、完全な月のみを更新したい場合は、バケット サイズ month と組み合わせてこの設定を有効にします。 そのため、データフローは完全な月のデータのみを抽出し、不完全な月のデータは抽出しません。
詳細設定
一部の設定は詳細と見なされ、ほとんどのシナリオでは必要ありません。
増分更新クエリを完全に折りたたむ必要があります
この設定は省略可能であり、増分更新に使われるクエリが完全にフォールドする必要があるかどうかを指定します。 この設定を有効にすると、増分更新に使われるクエリは完全にフォールドする必要があります。 つまり、クエリをソース システムまで完全にプッシュダウンする必要があります。 この設定を無効にすると、増分更新に使われるクエリは完全にフォールドする必要はありません。 つまり、クエリの一部だけをソース システムまでプッシュダウンしてもかまいません。 不要なフィルター処理されていないデータを取得しないでパフォーマンスを向上させるため、この設定を有効にすることを強くお勧めします。
制限事項
SQL ベースのデータ格納先のみがサポートされている
現在、増分更新では、SQL ベースのデータ格納先のみがサポートされています。 そのため、増分更新のデータ格納先として使用できるのは、Fabric Warehouse、Azure SQL Database、または Azure Synapse Analytics だけです。 このような制限がある理由は、これらのデータ格納先が、増分更新に必要な SQL ベースの操作をサポートしているためです。 データ格納先でのデータの置換には Delete と Insert 操作を使いますが、他のデータ格納先ではこれを並列に実行できません。
データ格納先を固定スキーマに設定する必要がある
データ格納先は固定スキーマに設定する必要があります。つまり、データ格納先のテーブルのスキーマは固定されている必要があり、変更できません。 データ格納先のテーブルのスキーマが動的スキーマに設定されている場合は、増分更新を構成する前に、固定スキーマに変更する必要があります。
データ格納先でサポートされている更新メソッドは replace だけである
データ格納先でサポートされている更新メソッドは replace だけです。つまり、データフローは、データ格納先の各バケットのデータを、新しいデータに置き換えます。 ただし、バケットの範囲外のデータは影響を受けません。 そのため、データ格納先に最初のバケットより古いデータがある場合、このデータは増分更新によってどのような影響も受けません。
バケットの最大数は、1 つのクエリに対して 50 個、データフロー全体で 150 個である
データフローでサポートされるクエリあたりのバケットの最大数は 50 です。 バケットが 50 個を超える場合は、バケットのサイズを大きくするか、バケットの範囲を減らして、バケットの数を少なくする必要があります。 データフロー全体では、バケットの最大数は 150 です。 データフローのバケットが 150 個を超える場合は、増分更新クエリの数を減らすか、バケット サイズを大きくしてバケットの数を減らす必要があります。
Dataflow Gen1 と Dataflow Gen2 での増分更新の違い
Dataflow Gen1 と Dataflow Gen2 では、増分更新のしくみにいくつかの違いがあります。 次の一覧では、Dataflow Gen1 と Dataflow Gen2 での増分更新の主な違いについて説明します。
- 増分更新は、Dataflow Gen2 で優れた機能になりました。 Dataflow Gen1 では、ユーザーはデータフローを発行した後で増分更新を構成する必要がありました。 Dataflow Gen2 での増分更新は、データフロー エディターで直接構成できる優れた機能になりました。 この機能を使うと、増分更新を簡単に構成でき、エラーのリスクが減ります。
- Dataflow Gen1 では、増分更新を構成するときに、履歴データの範囲を指定する必要がありました。 Dataflow Gen2 では、履歴データの範囲を指定する必要はありません。 データフローは、バケット範囲の外側にあるデータを格納先から削除しません。 そのため、格納先に最初のバケットより古いデータがある場合、このデータは増分更新によってどのような影響も受けません。
- Dataflow Gen1 では、増分更新を構成するときに、増分更新のパラメーターを指定する必要がありました。 Dataflow Gen2 では、増分更新のパラメーターを指定する必要はありません。 データフローが、クエリの最後のステップとしてフィルターとパラメーターを自動的に追加します。 そのため、ユーザーは増分更新のパラメーターを手動で指定する必要はありません。
よく寄せられる質問
変更の検出とフィルター処理に同じ列を使用したという警告を受け取りました。 具体的な変更点
変更の検出とフィルター処理に同じ列を使ったという警告を受け取る場合は、変更の検出用に指定した列がデータのフィルター処理にも使われていることを意味します。 予期しない結果につながる可能性があるため、このような使用はお勧めしません。 代わりに、変更の検出とデータのフィルター処理には異なる列を使うことをお勧めします。 データがバケット間を移動すると、データフローは変更を正しく検出できず、格納先に重複データが作成される可能性があります。 変更の検出とデータのフィルター処理に異なる列を使うと、この警告を解決できます。 または、指定した列のデータが更新の間に変わっていないことが確実である場合は、警告を無視してもかまいません。
サポートされていないデータ格納先で増分更新を使用する必要があります。 どうすればよいですか?
サポートされていないデータ格納先で増分更新を使いたい場合は、クエリで増分更新を有効にし、ステージング データを参照する 2 つ目のクエリを使って、データ格納先を更新できます。 このようにしてもやはり、増分更新を使って、ソース システムから処理および取得する必要があるデータの量を減らすことができますが、ステージング データからデータ格納先への完全な更新を行う必要があります。 ステージングのデータがバケットの範囲外に保持されることはシステムによって保証されないため、ユーザーが期間とバケットのサイズを確実に正しく設定してください。
クエリで増分更新が有効になっているかどうかを確認するにはどうすればよいですか?
クエリで増分更新が有効になっているかどうかは、データフロー エディターでクエリの横にあるアイコンを調べて確認できます。 アイコンに青い三角形が含まれている場合、増分更新は有効になっています。 アイコンに青い三角形が含まれない場合は、増分更新は有効ではありません。
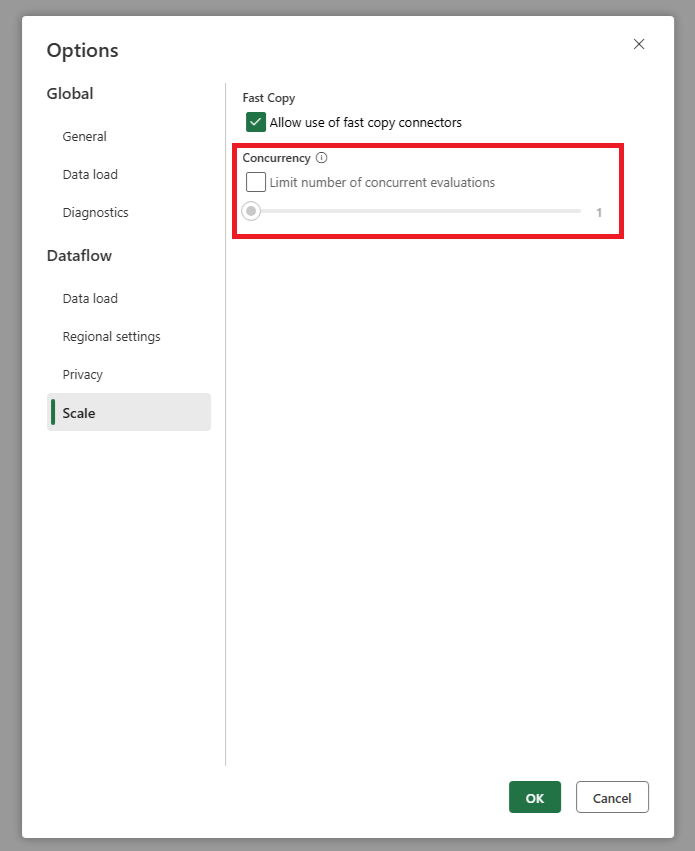
増分更新を使用すると、ソースが非常に多くの要求を受け取ります。 どうすればよいですか?
並列クエリ評価の最大数をユーザーが指定できる設定を追加しました。 この設定は、データフローのグローバル設定にあります。 この値を小さい数に設定すると、ソース システムに送信される要求の数を減らすことができます。 この設定は、同時要求の数を減らし、ソース システムのパフォーマンスを向上させるのに役立ちます。 並列クエリ実行の最大数を設定するには、データフローのグローバル設定の [スケール] タブに移動して、並列クエリ評価の最大数を設定します。 ソース システムで問題が発生していない限り、この制限を有効にしないことをお勧めします。