Delta Lake 形式の Dataverse データのエクスポート
Azure Synapse Link for Dataverse を使用して、自分の Microsoft Dataverse データをDelta Lake 形式で Azure Synapse Analytics にエクスポートします。 次に、データを探索して、洞察を得るまでの時間を短縮します。 この記事では、次の情報を提供し、次のタスクを実行する方法を示します。
- Delta Lake と Parquet、およびこの形式でデータをエクスポートする必要がある理由について説明します。
- Dataverse データを自分の Azure Synapse Analytics ワークスペースに Azure Synapse Link でDelta Lake 形式でエクスポートします。
- Azure Synapse Link とデータ変換を監視します。
- Azure Data Lake Storage Gen2 からデータを表示します。
- Synapse Workspace からデータを表示します。
重要
- 既存のカスタム ビューを使用して CSV から Delta Lake にアップグレードする場合は、スクリプトを更新して、すべての partitioned テーブルを non_partitioned に変更することをお勧めします。 これを行うには、
_partitionedのインスタンスを検索し、空の文字列に置き換えます。 - Dataverse 構成では、追加のみは、
appendonlyモードで CSV データをエクスポートすることをデフォルトにすることによって有効化されます。 ただし、Delta Lake の変換には定期的なマージ プロセスが伴うため、Delta Lake テーブルにはインプレース更新構造があります。 - Spark プールの作成に伴う費用は発生しません。 料金が発生するのは、ターゲットの Spark プールで Spark ジョブが実行され、Spark インスタンスがオンデマンドでインスタンス化された場合のみです。 これらのコストは、 Azure Synapse workspace Spark であり、毎月請求されます。 Spark コンピューティングのコストは、主に増分更新の時間間隔とデータ量によって異なります。 詳細: Azure Synapse Analytics の価格
- これらの追加費用はオプションではなく、この機能を引き続き使用する場合に支払う必要があるため、このテンプレートの利用を決定する際は、これらの追加費用を考慮することが重要です。
- Apache Spark 3.1 用 Azure Synapse ランタイムのサポート終了のお知らせ (EOLA) が、2023 年 1 月 26 日に発表されました。 Apache Spark 用 Synapse ランタイムのライフサイクル ポリシーに従って、Apache Spark 3.1 用 Azure Synapse ランタイムは、2024 年 1 月 26 日に廃止され、無効になります。 EOL の日付の後、廃止されたランタイムは新しい Spark プールで使用できなくなり、既存のワークフローは実行できなくなります。 メタデータは一時的に Synapse ワークスペースに残ります。 詳細: Apache Spark 3.1 用 Azure Synapse Runtime (EOLA). Delta Lake 形式へのエクスポートを使用して Dataverse の Synapse Link を Spark 3.3 にアップグレードするには、既存のプロファイルの一括アップグレードを行います。 詳細: Delta Lake 2.2 を使用した Apache Spark 3.3 への一括アップグレード
- 2024 年 1 月 4 日から、最初にリンクを作成するときは、Spark プール バージョン 3.3 のみがサポートされます。
注意
Power Apps (make.powerapps.com) の Azure Synapse Link のステータスは、Delta Lake の変換状態を反映しています。
Countは、Delta Lake テーブル内のレコードの数を表示します。Last synchronized onDatetimeは、最後に成功した変換のタイムスタンプを表します。Sync statusは、データの同期とデルタ レイクの変換が完了すると、アクティブ として表示され、データを使用できる状態を示します。
Delta Lake とは ?
Delta Lake は、Delta Lake 上にレイクハウス アーキテクチャを構築できるオープンソース プロジェクトです。 Delta Lake は、ACID (原子性、一貫性、分離、耐久性) トランザクション、スケーラブルなメタデータ処理を提供し、既存のDelta Lake 上でストリーミングとバッチ データ処理を統合します。 Azure Synapse Analytics は、Linux Foundation Delta Lake と互換性があります。 Azure Synapse に含まれるDelta Lake の現在のバージョン Scala、PySpark、.NET の言語サポートがあります。 詳細: Delta Lake とは? を参照してください。 デルタ テーブルのご紹介ビデオ からも詳細を学ぶことができます。
Apache Parquet は Delta Lake のベースライン形式であり、この形式にネイティブな効率的な圧縮およびエンコード スキームを活用できます。 Parquet ファイル形式では、列単位の圧縮が使用されます。 効率的で、保管スペースを節約できます。 特定の列の値をフェッチするクエリは、行データ全体を読み取る必要がないため、パフォーマンスが向上します。 したがって、サーバーレス SQL プールでデータを読み取るために必要な時間とストレージ要求が少なくなります。
Delta Lake とは?
- スケーラビリティ: Delta Lake は、大規模なデータ処理ワークロードを処理するための業界標準を満たすように設計されたオープンソース Apache ライセンスの上に構築されています。
- 信頼性: Delta Lake は ACID トランザクションを提供し、エラーや同時アクセスが発生した場合でもデータの一貫性と信頼性を確保します。
- パフォーマンス: Delta Lake は、Parquet の列形式のストレージ形式を活用して、より優れた圧縮およびエンコード技術を提供します。これにより、クエリ CSV ファイルと比較してクエリ パフォーマンスが向上します。
- 費用対効果が高い: Delta Lake ファイル形式は、高度に圧縮されたデータ ストレージ テクノロジーであり、企業のストレージを大幅に節約できる可能性があります。 この形式は、データ処理を最適化し、処理されるデータの総量やオンデマンド コンピューティングに必要な実行時間を潜在的に削減するように特別に設計されています。
- データ保護コンプライアンス: Delta Lakeと Azure Synapse Link は、一般データ保護規則 (GDPR) を含むさまざまなデータ プライバシー規制に準拠するためのソフト削除やハード削除などのツールと機能を提供します。
Delta Lake がどのように Azure Synapse Link for Dataverse と連携するか?
Azure Synapse Link for Dataverse をセットアップするときに、Delta Lake へのエクスポート 機能を有効にして、Synapse ワークスペースと Spark プールに接続できます。 Azure Synapse Link は選択した Dataverse テーブルを指定された時間間隔で CSV 形式でエクスポートし、Delta Lake 変換 Spark ジョブを通じて処理します。 この変換プロセスが完了すると、CSV データはストレージ保存のためにクリーンアップされます。 さらに、一連のメンテナンス ジョブが毎日実行されるようにスケジュールされており、自動的に圧縮およびバキューム プロセスを実行してデータ ファイルをマージおよびクリーンアップし、ストレージをさらに最適化し、クエリ パフォーマンスを向上させます。
前提条件
- Dataverse: Dataverse システム管理者セキュリティ ロールを持っている必要があります。 さらに、Azure Synapse Link 経由でエクスポートするテーブルでは、変更の追跡 プロパティが有効になっている必要があります。 詳細: 詳細オプション
- Azure Data Lake Storage Gen2: Azure Data Lake Storage Gen2 アカウントと所有者およびストレージ BLOB データ共同作成者ロールのアクセス権を持っている必要があります。 ご利用のストレージ アカウントでは、初期セットアップと差分同期の両方で、階層型名前空間とパブリック ネットワーク アクセスを有効にする必要があります。ストレージ アカウント キーへのアクセスを許可する は、初期セットアップの場合にのみ必要です。
- Synapse ワークスペース: Synapse ワークスペースとアクセス コントロール (IAM) の 所有者 ロール、および Synapse Studio 内の Synapse 管理者 ロールにアクセスする必要があります。 Synapse ワークスペースは、Azure Data Lake Storage Gen2 アカウントと同じ領域にある必要があります。 ストレージ アカウントは、Synapse Studio 内のリンクされたサービスとして追加する必要があります。 Synapse ワークスペースを作成するには、Synapse ワークスペースを作成するに移動します。
- この推奨されるSparkプール構成を使用する、接続されたワークスペース内のバージョン3.3のプール Apache Spark 。 Azure Synapse Apache Spark ... Spark プールを作成する方法については、Apache Spark プールの作成 をご覧ください。
- この機能を使用するための Microsoft Dynamics 365 の最小バージョン要件は 9.2.22082 です。 詳細: 早期アクセス更新プログラムへのオプトイン
推奨される Spark プールの構成
この構成は、平均的なユース ケースのブートストラップ ステップと見なすことができます。
- ノード サイズ: 小 (4 vCores / 32 GB)
- 自動スケーリング: 有効
- ノードの数: 5 から 10
- 自動一時停止: 有効化
- アイドルの分数: 5
- Apache Spark: 3.3
- 実行者を動的に割り当てる: 有効
- 実行者の既定数: 1 ~ 9 人
重要
Synapseリンク を使用したDelta Lake会話操作にのみSparkプールを使用します Dataverse。 信頼性とパフォーマンスを最適化するには、同じSparkプールを使用して他のSparkジョブを実行しないでください。
Dataverse を Synapse workspace に接続して、Delta Lake 形式でデータをエクスポートする
Power Apps にサインインして、必要な環境を選択します。
左側のナビゲーション ウィンドウで、Azure Synapse Link を選択します。 項目がサイド パネル ウィンドウに表示されない場合は、…さらに表示 を選択して、目的の項目を選択します。
コマンド バーで、+ 新規リンク を選択します
Azure Synapse Analytics workspace に接続 を選択し、 サブスクリプション、 リソース グループ、ワークスペース名 を選択します。
処理に Spark プールを使う を選択し、事前に作成された Spark プール と ストレージ アカウントを選択します。
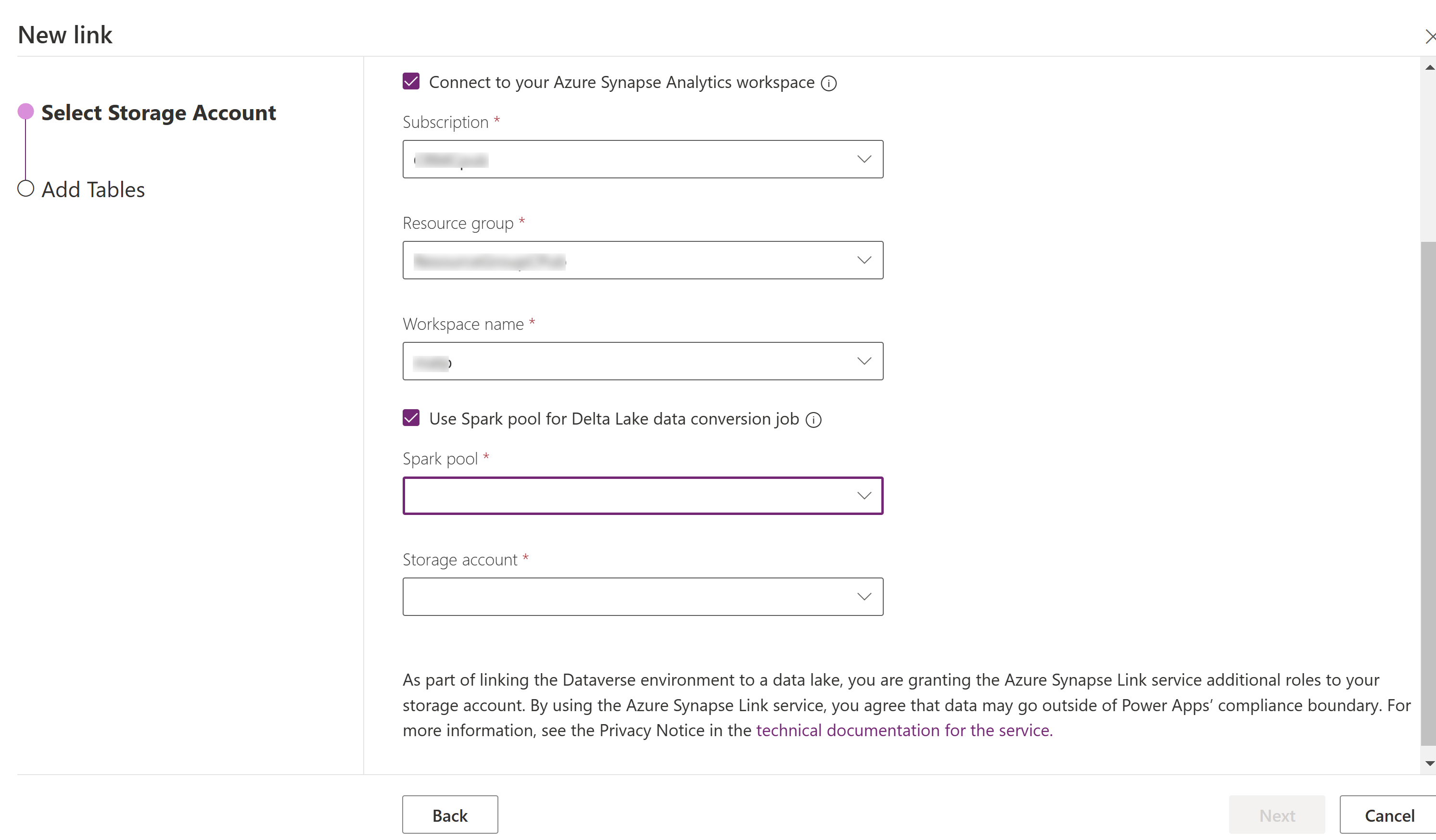
次へ を選択します。
エクスポートするテーブルを追加してから、詳細 を選択します。
オプションとして、詳細構成設定の表示 を選択して、増分更新がどの頻度でキャプチャされるかに対して間隔を分で入力します。
保存 を選択します。
Azure Synapse Link とデータ変換を監視する
- 希望の Azure Synapse Link を選択して、コマンドバーで Azure Synapse Analytics workspace に移動する を選択します。
- 監視 > Apache Spark アプリケーション を選択します。 詳細: Synapse Studio を使用して Apache Spark アプリケーションをモニターする
Synapse workspace からデータを表示します
- 希望の Azure Synapse Link を選択して、コマンドバーで Azure Synapse Analytics workspace に移動する を選択します。
- 左側ウィンドウから Lake Databases を展開し、dataverse-environmentNameorganizationUniqueName を選択してから、テーブル を展開します。 すべての Parquet テーブル は、DataverseTableName という命名規則で一覧表示され、分析に利用できます。 (非パーティション テーブル)。
注意
名前付け規則 _partitioned のテーブルは使用しないでください。 形式として Delta parquet を選択すると、命名規則 _partition を持つテーブルがステージング・テーブルとして使用され、システムで使用された後に削除されます。
Azure Data Lake Storage Gen2 からデータを表示します
- 希望の Azure Synapse Link を選択してから、コマンド バーで Azure Data Lake に移動する を選択します。
- データ ストレージで、コンテナーを選択します。
- *dataverse- *environmentName-organizationUniqueName を選択します。 すべての寄木細工のファイルは、 deltalake フォルダーに保存されます。
Delta Lake 2.2 を使用した Apache Spark 3.3 への一括アップグレード
前提条件
- Synapse Spark バージョン 3.1 で実行している、既存の Azure Synapse Link for Dataverse Delta Lake プロファイルが必要です。
- 同じ Synapse ワークスペース内で、同等かそれ以上のノードのハードウェア構成を使用し、Spark バージョン 3.3 で新しい Synapse Spark プールを作成する必要があります。 Spark プールを作成する方法については、Apache Spark プールの作成 をご覧ください。 この Spark プールは、現在の 3.1 プールから独立して作成する必要があります。
Spark 3.3 への一括アップグレード:
- Power Apps にサインインし、好みの環境を選択します。
- 左側のナビゲーション ウィンドウで、Azure Synapse Link を選択します。 項目が左側のナビゲーション ウィンドウに表示されない場合は、…さらに表示 を選択して、目的の項目を選択します。
- Azure Synapse Link プロファイルを開き、Delta Lake 2.2 を使用した Apache Spark 3.3 へのアップグレード を選択します。
- 一覧から利用可能な Spark プールを選択し、更新するを選択します。
注意
Spark プールのアップグレードは、新しい Delta Lake 変換の Spark ジョブがトリガーされた場合にのみ発生します。 更新するを選択した後、少なくとも 1 つのデータの変更があることを確認しします。