Azure Cosmos DB Java SDK v4에 대한 성능 팁
적용 대상: ![]() NoSQL
NoSQL
Important
이 문서의 성능 팁은 Azure Cosmos DB Java SDK v4 전용입니다. 자세한 내용은 Azure Cosmos DB Java SDK v4 릴리스 정보, Maven 리포지토리 및 Azure Cosmos DB Java SDK v4 문제 해결 가이드를 참조하세요. 현재 v4보다 이전 버전을 사용하는 경우 v4로 업그레이드하는 데 도움이 필요하면 Azure Cosmos DB Java SDK v4로 마이그레이션 가이드를 참조하세요.
Azure Cosmos DB는 보장된 대기 시간 및 처리량으로 매끄럽게 크기가 조정되는 빠르고 유연한 분산 데이터베이스입니다. Azure Cosmos DB를 사용하여 데이터베이스를 스케일링하기 위해 주요 아키텍처를 변경하거나 복잡한 코드를 작성할 필요는 없습니다. 규모를 확장 및 축소하는 것은 단일 API 호출 또는 SDK 메서드 호출을 수행하는 것만큼 쉽습니다. 그러나 네트워크 호출을 통해 Azure Cosmos DB에 액세스하므로 Azure Cosmos DB Java SDK v4를 사용할 때 최대 성능을 얻기 위해 클라이언트 쪽에서 최적화를 수행할 수 있습니다.
"내 데이터베이스 성능을 향상시키는 방법"을 물으면 다음 옵션을 고려합니다.
네트워킹
가능한 경우 Azure Cosmos DB를 호출하는 모든 애플리케이션을 Azure Cosmos DB 데이터베이스와 동일한 지역에 배치합니다. 대략적으로 비교한다면, 동일한 지역 내의 Azure Cosmos DB 호출은 1-2밀리초 내에 완료되지만 미국 서부와 동부 해안 간의 대기 시간은 50밀리초보다 큽니다. 클라이언트에서 Azure 데이터 센터 경계로 요청이 전달되는 경로에 따라 이러한 요청 간 대기 시간은 달라질 수 있습니다. 호출하는 애플리케이션이 프로비전된 Azure Cosmos DB 엔드포인트와 동일한 Azure 지역 내에 있도록 하면 가능한 최저 대기 시간을 얻을 수 있습니다. 사용 가능한 영역 목록은 Azure 지역을 참조하세요.
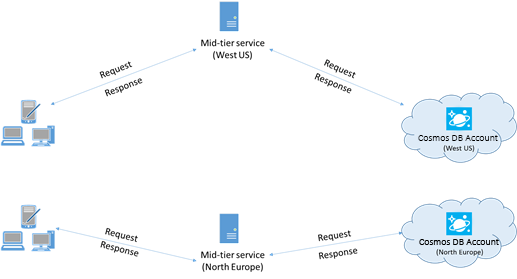
다중 지역 Azure Cosmos DB 계정과 상호 작용하는 앱은 요청이 배치된 지역으로 전달되도록 기본 설정 위치를 구성해야 합니다.
가속화된 네트워킹을 사용하도록 설정하여 대기 시간 및 CPU 지터 줄이기
대기 시간과 CPU 지터를 줄여 성능을 최대화하려면 지침에 따라 Windows(지침을 보려면 선택) 또는 Linux(지침을 보려면 선택) Azure VM에서 가속화된 네트워킹을 사용하도록 설정하는 것이 좋습니다.
가속화된 네트워킹을 사용하지 않으면 Azure VM과 다른 Azure 리소스 간에 전송되는 IO가 VM과 해당 네트워크 카드 사이에 위치한 호스트 및 가상 스위치를 통해 라우팅될 수 있습니다. 데이터 경로에 호스트 및 가상 스위치를 인라인으로 두면 통신 채널의 대기 시간과 jitter가 증가할 뿐만 아니라 VM의 CPU 사이클도 도용합니다. 가속화된 네트워킹을 사용하면 VM이 중개자 없이 NIC와 직접 인터페이스됩니다. 모든 네트워크 정책 세부 정보는 호스트와 가상 스위치를 우회하여 NIC의 하드웨어에서 처리됩니다. 일반적으로 가속화된 네트워킹을 사용하도록 설정하는 경우 대기 시간이 줄어들고 처리량이 향상될 뿐만 아니라 더 일관된 대기 시간이 유지되며 CPU 사용률이 줄어들 수도 있습니다.
제한 사항: 가속화된 네트워킹은 VM OS에서 지원되어야 하며, VM이 중지 및 할당 취소된 경우에만 사용하도록 설정할 수 있습니다. Azure Resource Manager를 사용하여 VM을 배포할 수 없습니다. App Service 가속화된 네트워크를 사용할 수 없습니다.
자세한 내용은 Windows와 Linux 지침을 참조하세요.
고가용성
Azure Cosmos DB에서 고가용성을 구성하는 방법에 대한 일반적인 지침은 Azure Cosmos DB의 고가용성을 참조하세요.
데이터베이스 플랫폼의 우수한 기본 설정 외에도 Java SDK 자체에 구현할 수 있는 특정 기술이 있으며, 이는 중단 시나리오에 도움이 될 수 있습니다. 주목할 만한 두 가지 전략은 임계값 기반 가용성 전략과 파티션 수준 회로 차단기입니다.
이러한 기술은 SDK에 기본적으로 기본 제공된 지역 간 다시 시도 기능을 뛰어넘어 특정 대기 시간 및 가용성 문제를 해결하기 위한 고급 메커니즘을 제공합니다. 요청 및 파티션 수준에서 잠재적인 문제를 적극적으로 관리함으로써 이러한 전략을 통해 애플리케이션의 복원력과 성능을 크게 향상시킬 수 있으며, 특히 부하가 높거나 성능이 저하된 조건에서 더욱 그렇습니다.
임계값 기반 가용성 전략
임계값 기반 가용성 전략은 병렬 읽기 요청을 보조 지역으로 보내고 가장 빠른 응답을 수락함으로써 비상 대기 시간과 가용성을 개선할 수 있습니다. 이러한 방식을 사용하면 지역적 중단이나 장시간 대기 시간 조건이 애플리케이션 성능에 미치는 영향을 크게 줄일 수 있습니다. 또한 자동 관리 연결을 사용하여 현재 읽기 지역 및 기본 원격 지역 모두에서 연결 및 캐시를 준비하여 성능을 더욱 향상시킬 수 있습니다.
예제 구성:
// Proactive Connection Management
CosmosContainerIdentity containerIdentity = new CosmosContainerIdentity("sample_db_id", "sample_container_id");
int proactiveConnectionRegionsCount = 2;
Duration aggressiveWarmupDuration = Duration.ofSeconds(1);
CosmosAsyncClient clientWithOpenConnections = new CosmosClientBuilder()
.endpoint("<account URL goes here")
.key("<account key goes here>")
.endpointDiscoveryEnabled(true)
.preferredRegions(Arrays.asList("sample_region_1", "sample_region_2"))
.openConnectionsAndInitCaches(new CosmosContainerProactiveInitConfigBuilder(Arrays.asList(containerIdentity))
.setProactiveConnectionRegionsCount(proactiveConnectionRegionsCount)
//setting aggressive warmup duration helps in cases where there is a high no. of partitions
.setAggressiveWarmupDuration(aggressiveWarmupDuration)
.build())
.directMode()
.buildAsyncClient();
CosmosAsyncContainer container = clientWithOpenConnections.getDatabase("sample_db_id").getContainer("sample_container_id");
int threshold = 500;
int thresholdStep = 100;
CosmosEndToEndOperationLatencyPolicyConfig config = new CosmosEndToEndOperationLatencyPolicyConfigBuilder(Duration.ofSeconds(3))
.availabilityStrategy(new ThresholdBasedAvailabilityStrategy(Duration.ofMillis(threshold), Duration.ofMillis(thresholdStep)))
.build();
CosmosItemRequestOptions options = new CosmosItemRequestOptions();
options.setCosmosEndToEndOperationLatencyPolicyConfig(config);
container.readItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
// Write operations can benefit from threshold-based availability strategy if opted into non-idempotent write retry policy
// and the account is configured for multi-region writes.
options.setNonIdempotentWriteRetryPolicy(true, true);
container.createItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
작동 방식:
초기 요청: 시간 T1에서 주 지역(예: 미국 동부)에 대한 읽기 요청이 수행됩니다. SDK는 최대 500밀리초(
threshold값) 동안 응답을 기다립니다.두 번째 요청: 주 지역에서 500밀리초 내에 응답이 없으면 병렬 요청이 다음 주 지역(예: 미국 동부 2)으로 전송됩니다.
세 번째 요청: 기본 지역과 보조 지역 모두 600밀리초(500ms + 100ms,
thresholdStep값) 이내에 응답하지 않으면 SDK는 세 번째 기본 지역(예: 미국 서부)에 다른 병렬 요청을 보냅니다.가장 빠른 응답 수락: 먼저 응답한 지역이 해당 응답을 수락하고 다른 병렬 요청은 무시됩니다.
자동 관리 연결 관리는 기본 설정 지역에서 컨테이너에 대한 연결 및 캐시를 예열하여 다중 지역 설정에서 장애 조치(failover) 시나리오 또는 쓰기에 대한 콜드 시작 대기 시간을 줄이는 데 도움이 됩니다.
이 전략을 사용하면 특정 지역이 느리거나 일시적으로 사용할 수 없는 시나리오에서 대기 시간을 크게 개선할 수 있지만, 병렬적인 지역 간 요청이 필요할 때 요청 단위 측면에서 더 많은 비용이 발생할 수 있습니다.
참고 항목
첫 번째 기본 지역에서 일시적이지 않은 오류 상태 코드(예: 문서를 찾을 수 없음, 권한 부여 오류, 충돌 등)가 반환되면 가용성 전략이 이 시나리오에서 아무런 이점이 없으므로 작업 자체가 빠르게 실패하게 됩니다.
파티션 수준 회로 차단기
파티션 수준 회로 차단기는 비정상 실제 파티션에 대한 요청을 추적하고 단락시켜 비상 대기 시간과 쓰기 가용성을 향상합니다. 알려진 문제가 있는 파티션을 피하고, 요청을 더 정상적인 지역으로 리디렉션하여 성능을 개선합니다.
예제 구성:
파티션 수준 회로 차단기를 사용하도록 설정하려면:
System.setProperty(
"COSMOS.PARTITION_LEVEL_CIRCUIT_BREAKER_CONFIG",
"{\"isPartitionLevelCircuitBreakerEnabled\": true, "
+ "\"circuitBreakerType\": \"CONSECUTIVE_EXCEPTION_COUNT_BASED\","
+ "\"consecutiveExceptionCountToleratedForReads\": 10,"
+ "\"consecutiveExceptionCountToleratedForWrites\": 5,"
+ "}");
사용할 수 없는 지역을 확인하기 위한 백그라운드 프로세스 빈도를 설정하려면:
System.setProperty("COSMOS.STALE_PARTITION_UNAVAILABILITY_REFRESH_INTERVAL_IN_SECONDS", "60");
파티션을 사용할 수 없는 기간을 설정하려면:
System.setProperty("COSMOS.ALLOWED_PARTITION_UNAVAILABILITY_DURATION_IN_SECONDS", "30");
작동 방식:
실패 추적: SDK는 특정 지역의 개별 파티션에 대한 터미널 오류(예: 503, 500, 시간 제한)를 추적합니다.
사용할 수 없음으로 표시: 지역의 파티션이 구성된 실패 임계값을 초과하면 "사용할 수 없음"으로 표시됩니다. 이 파티션에 대한 후속 요청은 단락되어 다른 더 정상적인 지역으로 리디렉션됩니다.
자동 복구: 백그라운드 스레드가 주기적으로 사용할 수 없는 파티션을 확인합니다. 일정 기간이 지나면 이러한 파티션은 "HealthyTentative"로 미정 표시되고 복구 유효성 검사를 위한 테스트 요청을 받게 됩니다.
상태 승격/강등: 이러한 테스트 요청의 성공 또는 실패에 따라 파티션 상태가 "정상"으로 다시 승격되거나 "사용할 수 없음"으로 다시 강등됩니다.
이 메커니즘은 파티션 상태를 지속적으로 모니터링하고 문제가 있는 파티션으로 인해 속도가 느려지지 않고 요청이 최소 대기 시간과 최대 가용성으로 처리되도록 보장합니다.
참고 항목
회로 차단기는 다중 지역 쓰기 계정에만 적용됩니다. 파티션이 Unavailable로 표시되면 읽기와 쓰기가 모두 다음 기본 지역으로 이동됩니다. 이는 서로 다른 지역의 읽기 및 쓰기가 동일한 클라이언트 인스턴스에서 처리되는 것을 방지하기 위한 것입니다. 이는 안티 패턴이기 때문입니다.
Important
파티션 수준 회로 차단기를 활성화하려면 Java SDK 4.63.0 버전 이상을 사용해야 합니다.
가용성 최적화 비교
임계값 기반 가용성 전략:
- 이점: 보조 지역에 병렬 읽기 요청을 전송하여 비상 대기 시간을 줄이고 네트워크 시간 제한을 초래하는 요청을 선점하여 가용성을 향상합니다.
- 단점: 추가적인 병렬 지역 간 요청으로 인해 회로 차단기에 비해 추가 RU(요청 단위) 비용이 발생합니다(임계값이 위반된 기간 동안에만 해당).
- 사용 사례: 대기 시간을 줄이는 것이 중요하고 추가 비용(RU 요금 및 클라이언트 CPU 압력 측면 모두)이 허용되는 읽기 중심 워크로드에 적합합니다. 멱등적(idempotent)이지 않은 쓰기 재시도 정책을 선택하고 계정에 여러 지역에 대한 쓰기가 있는 경우, 쓰기 작업도 이점을 얻을 수 있습니다.
파티션 수준 회로 차단기:
- 이점: 비정상 파티션을 방지하여 쓰기 가용성과 대기 시간을 개선하고 요청이 좀 더 양호한 지역으로 라우팅되도록 보장합니다.
- 단점: 추가 RU 비용이 발생하지 않지만 네트워크 시간 제한을 야기하는 요청에 대한 초기 가용성 손실을 허용할 수 있습니다.
- 사용 사례: 일관된 성능이 필수적인 쓰기 작업이나 혼합 워크로드에 적합하며, 특히 일시적으로 비정상 상태가 될 수 있는 파티션을 처리하는 경우에 적합합니다.
두 가지 전략 모두 읽기/쓰기 가용성을 향상하고 비상 대기 시간을 줄이는 데 사용할 수 있습니다. 파티션 수준 회로 차단기는 병렬 요청을 수행할 필요 없이, 복제본 성능 저하를 초래할 수 있는 상황을 포함하여 다양한 일시적인 오류 시나리오를 처리할 수 있습니다. 또한 임계값 기반 가용성 전략을 추가하면 추가 RU 비용이 허용되는 경우 비상 대기 시간이 최소화되고 가용성 손실이 제거됩니다.
이러한 전략을 구현하면 개발자는 지역적 중단이나 높은 대기 시간 조건에서도 애플리케이션의 복원력 및 고성능을 유지하며, 더 나은 사용자 환경을 제공할 수 있습니다.
지역 범위 세션 일관성
개요
일관성 설정에 대한 일반적인 자세한 내용은 Azure Cosmos DB의 일관성 수준을 참조하세요. Java SDK는 지역 범위를 지정하여 다중 지역 쓰기 계정에 대한 세션 일관성을 최적화합니다. 이를 통해 클라이언트 쪽 다시 시도를 최소화하여 지역 간 복제 지연을 완화하고 성능을 향상합니다. 이는 글로벌 단위가 아닌 지역 단위에서 세션 토큰을 관리하여 달성됩니다. 애플리케이션의 일관성을 더 적은 수의 지역으로만 범위를 지정할 수 있는 경우 지역 범위 세션 일관성을 구현하면 지역 간 복제 지연 및 다시 시도를 최소화하여 다중 쓰기 계정에서 읽기 및 쓰기 작업의 성능과 안정성을 더 높일 수 있습니다.
이점
- 대기 시간 단축: 세션 토큰 유효성 검사를 지역 수준으로 지역화함으로써 비용이 많이 드는 지역 간 다시 시도 가능성이 줄어듭니다.
- 성능 향상: 지역 장애 조치(failover) 및 복제 지연의 영향을 최소화하여 더 높은 읽기/쓰기 일관성과 더 낮은 CPU 사용률을 제공합니다.
- 최적화된 리소스 사용률: 다시 시도 및 지역 간 호출 필요성을 제한하여 클라이언트 애플리케이션의 CPU 및 네트워크 오버헤드를 줄이고 리소스 사용률을 최적화합니다.
- 고가용성: 지역 범위 세션 토큰을 유지함으로써 특정 지역에서 대기 시간이 길어지거나 일시적인 오류가 발생하더라도 애플리케이션은 원활하게 작동할 수 있습니다.
- 일관성 보장: 불필요한 다시 시도 없이 세션 일관성(읽기, 쓰기, 단조로운 읽기) 보장이 보다 안정적으로 충족되도록 합니다.
- 비용 효율성: 지역 간 통화 수를 줄여 지역 간 데이터 전송과 관련된 비용을 잠재적으로 낮출 수 있습니다.
- 확장성: 특히 다중 지역 설정에서 글로벌 세션 토큰을 유지하는 데 관련된 경합 및 오버헤드를 줄임으로써 애플리케이션이 더 효율적으로 크기 조정될 수 있도록 합니다.
장단점
- 메모리 사용량 증가: 블룸 필터와 지역별 세션 토큰 스토리지에는 추가 메모리가 필요하므로 리소스가 제한된 애플리케이션의 경우 이를 고려해야 할 수 있습니다.
- 구성 복잡성: 블룸 필터의 예상 삽입 횟수와 가양성 비율을 미세 조정하면 구성 프로세스에 복잡성이 한 단계 더 추가됩니다.
- 가양성 가능성: 블룸 필터는 지역 간 다시 시도를 최소화하지만 세션 토큰 유효성 검사에 영향을 미치는 가양성 가능성이 약간은 있습니다. 하지만 이 비율은 제어할 수 있습니다. 가양성은 글로벌 세션 토큰이 확인되었다는 것을 의미하며, 이로 인해 로컬 지역이 이 글로벌 세션을 따라잡지 못할 경우 지역 간 다시 시도 가능성이 높아집니다. 가양성이 있는 경우에도 세션 보장이 충족됩니다.
- 적용 가능성: 이 기능은 논리 파티션의 높은 카디널리티와 정기적인 다시 시작이 필요한 애플리케이션에 가장 유용합니다. 논리적 파티션이 적거나 다시 시작이 드물게 이루어지는 애플리케이션의 경우 큰 이점을 얻지 못할 수도 있습니다.
작동 방식
세션 토큰 설정
- 요청 완료: 요청이 완료되면 SDK는 세션 토큰을 캡처하여 지역 및 파티션 키와 연결합니다.
- 지역 수준 스토리지: 세션 토큰은 파티션 키 범위와 지역 수준 진행률 간 매핑을 유지하는 중첩된
ConcurrentHashMap에 저장됩니다. - 블룸 필터: 블룸 필터는 각 논리적 파티션이 액세스한 영역을 추적하여 세션 토큰 유효성 검사를 지역화하는 데 도움이 됩니다.
세션 토큰 확인
- 요청 초기화: 요청이 전송되기 전에 SDK는 해당 지역에 대한 세션 토큰을 확인하려고 시도합니다.
- 토큰 확인: 토큰은 지역별 데이터와 비교 검사되어 요청이 최신 복제본으로 라우팅되는지 확인합니다.
- 다시 시도 논리: 세션 토큰이 현재 셀이 있는 영역 내에서 유효성 검사되지 않으면 SDK는 다른 지역으로 다시 시도하지만 지역화된 스토리지가 주어지면 이 빈도는 줄어듭니다.
SDK 사용
지역 범위 세션 일관성을 사용하여 CosmosClient를 초기화하는 방법은 다음과 같습니다.
CosmosClient client = new CosmosClientBuilder()
.endpoint("<your-endpoint>")
.key("<your-key>")
.consistencyLevel(ConsistencyLevel.SESSION)
.buildClient();
// Your operations here
지역 범위 세션 일관성 사용
애플리케이션에서 지역 범위 세션 캡처를 사용하도록 설정하려면 다음 시스템 속성을 설정합니다.
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
블룸 필터 구성
블룸 필터에 대한 예상 삽입 및 가양성 비율을 구성하여 성능을 미세 조정합니다.
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "5000000"); // adjust as needed
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.001"); // adjust as needed
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "1000000");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.01");
메모리 영향
아래는 SDK에서 관리하는 내부 세션 컨테이너의 보존 크기(개체의 크기와 그에 따라 달라지는 것)와 블룸 필터에 대한 다양한 예상 삽입 내용입니다.
| 예상된 삽입 | 거짓 긍정 비율 | 보존 크기 |
|---|---|---|
| 10,000 | 0.001 | 21KB |
| 100,000 | 0.001 | 183KB |
| 1백만 | 0.001 | 1.8MB |
| 1천만 | 0.001 | 17.9MB |
| 1억 | 0.001 | 179MB |
| 10억 | 0.001 | 1.8GB |
Important
지역 범위 세션 일관성을 활성화하려면 Java SDK 4.60.0 버전 이상을 사용해야 합니다.
직접 및 게이트웨이 연결 구성 조정
직접 및 게이트웨이 모드 연결 구성을 최적화하려면 Java SDK v4에 대한 연결 구성을 조정하는 방법을 참조하세요.
SDK 사용
- 최신 SDK 설치
Azure Cosmos DB SDK는 최상의 성능을 제공하기 위해 지속적으로 향상됩니다. 최신 SDK 개선 사항을 확인하려면 Azure Cosmos DB SDK를 방문하세요.
각 Azure Cosmos DB 클라이언트 인스턴스는 스레드로부터 안전하며 연결 관리와 주소 캐싱을 효율적으로 수행합니다. Azure Cosmos DB 클라이언트에서 연결을 효율적으로 관리하고 성능을 향상하려면 애플리케이션 수명 동안 단일 Azure Cosmos DB 클라이언트 인스턴스를 사용하는 것이 좋습니다.
CosmosClient를 만들 때 명시적으로 설정되지 않은 경우 사용되는 기본 일관성은 세션입니다. 애플리케이션 논리에 세션 일관성이 필요하지 않으면 일관성을 최종으로 설정합니다. 참고: Azure Cosmos DB 변경 피드 프로세서를 사용하는 애플리케이션에서는 세션 이상의 일관성을 사용하는 것이 좋습니다.
- Async API를 사용하여 프로비저닝된 처리량 최대화
Azure Cosmos DB Java SDK v4는 Sync 및 Async라는 두 개의 API를 번들로 묶습니다. 대략적으로 말하면 Async API는 SDK 기능을 구현하지만, Sync API는 Async API에 대한 호출을 차단하는 씬 래퍼입니다. 이는 비동기 전용인 이전의 Azure Cosmos DB Async Java SDK v2 및 동기 전용이고 분리된 이전의 Azure Cosmos DB Sync Java SDK v2와는 대조적입니다.
API 선택은 클라이언트 초기화 중에 결정됩니다. CosmosAsyncClient는 Async API를 지원하지만, CosmosClient는 Sync API를 지원합니다.
비차단 IO를 구현하며, Azure Cosmos DB에 대한 요청을 실행할 때 처리량을 최대화하는 것이 목표인 경우 Async API를 선택하는 것이 가장 좋습니다.
각 요청에 대한 응답을 차단하는 API가 필요하거나 동기 작업이 애플리케이션의 주요 패러다임인 경우 Sync API를 사용하는 것이 올바른 선택일 수 있습니다. 예를 들어 처리량이 중요하지 않으면 마이크로서비스 애플리케이션에서 Azure Cosmos DB에 대한 데이터를 유지할 때 Sync API를 사용할 수 있습니다.
요청 응답 시간이 증가함에 따라 Sync API 처리량이 저하되지만, Async API는 하드웨어의 전체 대역폭 기능을 포화 상태로 만들 수 있습니다.
지리적 배치를 사용하면 Sync API를 사용할 때 더 높고 일관된 처리량을 제공할 수 있습니다(성능을 위해 동일한 Azure 지역에 클라이언트 배치 참조). 그러나 여전히 달성 가능한 Async API 처리량을 초과하지는 않습니다.
또한 일부 사용자는 Azure Cosmos DB Java SDK v4 Async API를 구현하는 데 사용되는 Reactive Streams 프레임워크인 Project Reactor에 익숙하지 않을 수 있습니다. 문제가 되는 경우 Reactor 패턴 가이드 소개를 읽은 다음, 이 반응성 프로그래밍 소개를 살펴보고 숙지합니다. 이미 비동기 인터페이스를 통해 Azure Cosmos DB를 사용했고 사용한 SDK가 Azure Cosmos DB Async Java SDK v2인 경우 ReactiveX/RxJava에는 익숙하지만 Project Reactor에서 변경된 내용을 확실히 알지 못할 수 있습니다. 이 경우 Reactor 및 RxJava 가이드를 살펴보고 숙지합니다.
다음 코드 조각에서는 각각 Async API 또는 Sync API 작업을 위해 Azure Cosmos DB 클라이언트를 초기화하는 방법을 보여 줍니다.
Java SDK V4(Maven com.azure::azure-cosmos) Async API
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint(HOSTNAME)
.key(MASTERKEY)
.consistencyLevel(CONSISTENCY)
.buildAsyncClient();
- 클라이언트 워크로드 규모 확장
높은 처리량 수준에서 테스트하는 경우 컴퓨터에서 CPU 또는 네트워크 사용률 제한을 초과하여 클라이언트 애플리케이션에서 병목 상태가 발생할 수 있습니다. 이 시점에 도달하면 여러 서버에 걸쳐 클라이언트 애플리케이션을 확장하여 Azure Cosmos DB 계정을 계속 추가할 수 있습니다.
대기 시간을 짧게 유지하려면 지정된 서버에서 CPU 사용률이 50%를 초과하지 않는 것이 좋습니다.
- 적절한 스케줄러 사용(이벤트 루프 IO Netty 스레드 도용 방지)
Azure Cosmos DB Java SDK의 비동기 기능은 netty 비차단 IO를 기반으로 합니다. SDK는 IO 작업을 실행하기 위해 고정된 수의 IO netty 이벤트 루프 스레드(시스템에 있는 CPU 코어 수만큼)를 사용합니다. API에서 반환되는 Flux는 공유 IO 이벤트 반복 netty 스레드 중 하나에 대한 결과를 내보냅니다. 따라서 이 공유 IO 이벤트 루프 netty 스레드를 차단하지 않는 것이 중요합니다. IO 이벤트 루프 netty 스레드에서 CPU 집약적인 작업 또는 차단 작업을 수행하면 교착 상태가 발생하거나 SDK 처리량이 크게 저하될 수 있습니다.
예를 들어 다음 코드는 이벤트 루프 IO netty 스레드에서 CPU 집약적인 작업을 실행합니다.
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
결과를 받은 후에는 이벤트 루프 IO netty 스레드의 결과에 대한 CPU 집약적인 작업을 수행하지 않아야 합니다. 대신 사용자 고유의 스케줄러를 제공하여 아래와 같이 작업을 실행하기 위한 사용자 고유의 스레드를 제공할 수 있습니다(import reactor.core.scheduler.Schedulers 필요).
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub
.publishOn(Schedulers.parallel())
.subscribe(
itemResponse -> {
//this is now executed on reactor scheduler's parallel thread.
//reactor scheduler's parallel thread is meant for CPU intensive work.
veryCpuIntensiveWork();
});
작업 유형에 따라 적절한 Reactor Scheduler를 작업에 사용해야 합니다. 여기 Schedulers를 읽으세요.
프로젝트 반응기의 스레딩 및 일정 모델을 더 자세히 이해하려면 프로젝트 반응기의 이 블로그 게시물을 참조하세요.
Azure Cosmos DB Java SDK v4에 관한 자세한 내용은 GitHub에 있는 Java용 Azure SDK에 대한 Azure Cosmos DB 디렉터리 단일 리포지토리를 참조하세요.
- 애플리케이션의 로깅 설정 최적화
다양한 이유로 높은 요청 처리량을 생성하는 스레드에 로깅을 추가해야 합니다. 이 스레드에서 생성된 요청을 사용하여 프로비저닝된 컨테이너의 처리량을 완전한 포화 상태로 만드는 것이 목표인 경우 로깅 최적화는 성능을 크게 향상시킬 수 있습니다.
- 비동기 로거 구성
동기 로거의 대기 시간은 반드시 요청 생성 스레드의 전체 대기 시간 계산에 영향을 미칩니다. 고성능 애플리케이션 스레드에서 로깅 오버헤드를 분리하려면 log4j2와 같은 비동기 로거를 사용하는 것이 좋습니다.
- Netty 로깅 사용 안 함
Netty 라이브러리 로깅은 대화량이 많으므로 추가 CPU 비용을 피하려면 꺼두어야 합니다(구성 로그인을 억제하는 것으로 충분하지 않음). 디버깅 모드가 아니라면 netty의 로깅을 모두 해제합니다. 따라서 log4j를 사용하여 netty에서 org.apache.log4j.Category.callAppenders()에 의한 추가 CPU 비용이 발생하지 않도록 하려면 코드베이스에 다음 행을 추가합니다.
org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);
- OS 파일 열기 리소스 제한
일부 Linux 시스템(Red Hat 등)에는 열린 파일 수와 총 연결 수에 대한 상한이 있습니다. 현재 한도를 보려면 다음을 실행합니다.
ulimit -a
열린 파일(nofile)의 수는 OS에 의해 구성된 연결 풀 크기와 다른 열린 파일을 위한 공간이 충분할 만큼 커야 합니다. 연결 풀 크기를 더 크게 수정할 수 있습니다.
limits.conf 파일을 엽니다.
vim /etc/security/limits.conf
다음 줄을 추가/수정합니다.
* - nofile 100000
- 지점 쓰기에서 파티션 키 지정
지점 쓰기의 성능을 향상시키려면 아래와 같이 지점 쓰기 API 호출에서 항목 파티션 키를 지정합니다.
Java SDK V4(Maven com.azure::azure-cosmos) Async API
asyncContainer.createItem(item,new PartitionKey(pk),new CosmosItemRequestOptions()).block();
아래와 같이 항목 인스턴스만 제공하는 대신:
Java SDK V4(Maven com.azure::azure-cosmos) Async API
asyncContainer.createItem(item).block();
후자는 지원되지만 대기 시간을 애플리케이션에 추가합니다. SDK는 항목을 구문 분석하여 파티션 키를 추출해야 합니다.
쿼리 작업
쿼리 작업은 쿼리에 대한 성능 팁을 참조하세요.
인덱싱 정책
- 쓰기 속도를 높이기 위해 인덱싱에서 사용하지 않는 경로 제외
Azure Cosmos DB의 인덱싱 정책을 통해 인덱싱 경로(setIncludedPaths 및 setExcludedPaths)를 사용하여 인덱싱에 포함하거나 제외할 문서 경로를 지정할 수 있습니다. 인덱싱 비용이 인덱싱된 고유 경로 수와 직접 관련이 있기 때문에, 인덱싱 경로를 사용하면 사전에 알려진 쿼리 패턴의 시나리오에 대해 쓰기 성능을 향상시키고 인덱스 스토리지를 낮출 수 있습니다. 예를 들어 다음 코드에서는 "*" 와일드카드를 사용하여 인덱싱에서 문서의 전체 섹션(하위 트리라고도 함)을 포함 및 제외하는 방법을 보여 줍니다.
CosmosContainerProperties containerProperties = new CosmosContainerProperties(containerName, "/lastName");
// Custom indexing policy
IndexingPolicy indexingPolicy = new IndexingPolicy();
indexingPolicy.setIndexingMode(IndexingMode.CONSISTENT);
// Included paths
List<IncludedPath> includedPaths = new ArrayList<>();
includedPaths.add(new IncludedPath("/*"));
indexingPolicy.setIncludedPaths(includedPaths);
// Excluded paths
List<ExcludedPath> excludedPaths = new ArrayList<>();
excludedPaths.add(new ExcludedPath("/name/*"));
indexingPolicy.setExcludedPaths(excludedPaths);
containerProperties.setIndexingPolicy(indexingPolicy);
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
database.createContainerIfNotExists(containerProperties, throughputProperties);
CosmosAsyncContainer containerIfNotExists = database.getContainer(containerName);
자세한 내용은 Azure Cosmos DB 인덱싱 정책을 참조하세요.
처리량
- 낮은 요청 단위/초 사용량 측정 및 튜닝
Azure Cosmos DB는 관계형 쿼리와 계층형 쿼리 등 다양한 데이터베이스 작업에 데이터베이스 컬렉션 내부의 문서에서 적용되는 UDF, 저장 프로시저 및 트리거를 제공합니다. 이러한 작업 각각과 관련된 비용은 작업을 완료하는 데 필요한 CPU, IO 및 메모리에 따라 달라집니다. 하드웨어 리소스를 고려하고 관리하는 대신 다양한 데이터베이스 작업을 수행하고 애플리케이션 요청을 처리하는 데 필요한 리소스의 단일 측정값으로 RU(요청 단위)를 고려할 수 있습니다.
처리량은 각 컨테이너에 설정된 요청 단위 수에 따라 프로비전됩니다. 요청 단위 소비는 초당 비율로 평가됩니다. 해당 컨테이너에 프로비전된 요청 단위 비율을 초과하는 애플리케이션은 비율이 컨테이너에 프로비전된 수준 아래로 떨어질 때까지 제한됩니다. 애플리케이션에 더 높은 수준의 처리량이 필요한 경우 추가 요청 단위를 프로비전하여 처리량을 늘릴 수 있습니다.
쿼리의 복잡성은 작업에 사용되는 요청 단위의 양에 영향을 줍니다. 조건자의 수, 조건자의 특성, UDF 수 및 원본 데이터 집합의 크기는 모두 쿼리 작업의 비용에 영향을 줍니다.
모든 작업(만들기, 업데이트 또는 삭제)에 대한 오버헤드를 측정하려면 x-ms-request-charge 헤더를 검사하여 이 작업에 사용된 요청 단위 수를 측정합니다. 동일한 RequestCharge 속성은 ResourceResponse<T> 또는 FeedResponse<T>에서 확인할 수도 있습니다.
Java SDK V4(Maven com.azure::azure-cosmos) Async API
CosmosItemResponse<CustomPOJO> response = asyncContainer.createItem(item).block();
response.getRequestCharge();
이 헤더에서 반환된 요청 비용은 프로비전된 처리량의 일부입니다. 예를 들어 RU 2,000개를 프로비전했고 앞의 쿼리에서 1,000개의 1KB 문서를 반환하는 경우 작업 비용은 1,000입니다. 따라서 1초 이내에 서버는 후속 요청의 속도를 제한하기 전에 이러한 두 가지 요청만 인식합니다. 자세한 내용은 요청 단위와 요청 단위 계산기를 참조하세요.
- 너무 큰 속도 제한/요청 속도 처리
클라이언트가 계정에 대해 예약된 처리량을 초과하려 할 때도 서버의 성능이 저하되거나 예약된 수준 이상의 처리량이 사용되지 않습니다. 서버에서 RequestRateTooLarge(HTTP 상태 코드 429)를 사용하여 선제적으로 요청을 종료하고, 사용자가 요청을 다시 시도할 수 있을 때까지 기다려야 하는 시간을 밀리초 단위로 표시하는 x-ms-retry-after-ms 헤더를 반환합니다.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
SDK는 이 응답을 암시적으로 모두 catch하고, server-specified retry-after 헤더를 준수하고 요청을 다시 시도합니다. 동시에 여러 클라이언트가 계정에 액세스하지만 않으면 다음 재시도가 성공할 것입니다.
하나 이상의 클라이언트에서 요청 속도가 점증적으로 일관되게 초과하여 작동하는 경우 클라이언트에서 현재 내부적으로 9로 설정한 기본 재시도 횟수가 충분하지 않을 수 있습니다. 이 경우 클라이언트에서 상태 코드가 429인 CosmosClientException을 애플리케이션에 throw합니다. 기본 재시도 횟수는 ThrottlingRetryOptions 인스턴스에서 setMaxRetryAttemptsOnThrottledRequests()를 사용하여 변경할 수 있습니다. 기본적으로 요청이 요청 속도 이상으로 계속 작동하는 경우 상태 코드가 429인 CosmosClientException은 30초의 누적 대기 시간 후에 반환됩니다. 현재 재시도 횟수가 최대 재시도 횟수보다 작은 경우에도 이러한 현상이 발생하기 때문에 기본값인 9 또는 사용자 정의 값으로 두세요.
자동화된 재시도 동작은 대부분의 애플리케이션에 대한 복원력 및 유용성을 개선하는 데 도움이 되는 반면, 성능 벤치마크 수행 시 특히 대기 시간을 측정할 때 방해가 될 수 있습니다. 실험이 서버 제한에 도달하고 클라이언트 SDK를 자동으로 재시도하는 경우 클라이언트 관찰 대기 시간이 급증합니다. 성능 실험 중 대기 시간 급증을 방지하려면, 각 작업에 의해 반환된 비용을 측정하고 요청이 예약된 요청 속도 이하로 작동하고 있는지 확인합니다. 자세한 내용은 요청 단위를 참조하세요.
- 처리량을 높이기 위해 문서 크기를 줄이도록 설계
주어진 작업의 요청 비용(요청 처리 비용)은 문서 크기와 직접 관련이 있습니다. 큰 문서에서 작업하는 경우 작은 문서 작업에 비해 비용이 많이 듭니다. 항목 크기가 최대 1KB이거나 비슷한 순서 또는 크기가 되도록 애플리케이션과 워크플로를 설계하는 것이 가장 좋습니다. 대기 시간이 중요한 애플리케이션의 경우 많은 항목을 사용하지 않도록 방지합니다. 다중 MB 크기의 문서는 애플리케이션 속도를 낮춥니다.
다음 단계
확장성 및 고성능을 위한 애플리케이션 설계 방법에 대한 자세한 내용은 Azure Cosmos DB의 분할 및 크기 조정을 참조하세요.
Azure Cosmos DB로 마이그레이션하기 위한 용량 계획을 수행하려고 하시나요? 용량 계획을 위해 기존 데이터베이스 클러스터에 대한 정보를 사용할 수 있습니다.
- 기존 데이터베이스 클러스터의 vCore 및 서버의 수만 알고 있는 경우 vCore 또는 vCPU를 사용하여 요청 단위 예측을 참조하세요
- 현재 데이터베이스 워크로드에 대한 일반적인 요청 비율을 알고 있는 경우 Azure Cosmos DB 용량 계획 도구를 사용하여 요청 단위 예측에 대해 읽어보세요.