데이터 수집은 하나 이상의 원본에서 Azure Data Explorer의 테이블로 데이터를 로드하는 데 사용되는 프로세스입니다. 수집한 데이터는 쿼리용으로 사용하실 수 있게 됩니다. 이 문서에서는 Amazon S3에서 새로운 테이블 혹은 기존 테이블로 데이터를 가져오는 방법을 알아보세요.
일부 데이터 형식 매핑(Parquet, JSON 및 Avro)은 간단한 수집 시간 변환을 지원합니다. 매핑 변환을 적용하기 위해서는 열을 편집해 보세요창에서 열을 만들어 보시거나 업데이트 해보세요.
매핑 변환은 형식 문자열 혹은 날짜/시간 형식의 열에서 실행해 보실 수 있으며 소스의 데이터 형식이 int 혹은 long입니다. 지원되는 매핑 변환은 다음과 같습니다.
DateTimeFromUnixSeconds
DateTimeFromUnixMilliseconds
DateTimeFromUnixMicroseconds
DateTimeFromUnixNanoseconds
데이터 형식을 기반으로 한 고급 옵션
테이블 형식 (CSV, TSV, PSV):
기존 테이블에서 테이블 형식을 수집하는 경우 고급>유지 현재 테이블 스키마를 선택할 수 있습니다. 테이블 형식 데이터에는 원본 데이터를 기존 열에 매핑하는 데 사용되는 열 이름이 반드시 포함되지는 않습니다. 이 옵션을 선택하실 때 매핑은 순서대로 실행이 되며 테이블 스키마는 동일하게 유지됩니다. 이 옵션을 선택하지 않으시는 경우에 데이터 구조와는 상관없이 수신 데이터에 대한 새로운 열이 만들어 지게 됩니다.
첫 번째 행을 열 이름으로 사용하기 위해서는 고급>첫 번째 행을 열 머리글로 선택해 주세요.
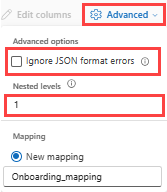
JSON:
JSON 데이터의 열 분할을 확인하기 위해서는 1에서 100까지의 고급>중첩된 수준을 선택해 주세요.
고급>데이터 무시 데이터 형식 오류를 선택하면 데이터가 JSON 형식으로 수집됩니다. 이 확인란을 선택하지 않으신 상태로 두게 되시는 경우에 데이터가 multijson 형식으로 수집되어 집니다.
요약
데이터 준비 창에서 데이터 수집이 성공적으로 완료되셨을 때 세 단계 모두 녹색 확인 표시가 나타납니다. 각 단계에 사용된 명령을 보거나 수집된 데이터를 쿼리, 시각화 또는 삭제할 카드를 선택할 수 있습니다.