싱크 최적화
데이터 흐름이 싱크에 기록되면 모든 사용자 지정 분할은 쓰기 직전에 발생합니다. 원본과 마찬가지로 대부분의 경우 현재 분할 사용을 파티션 옵션으로 계속 유지하는 것이 좋습니다. 분할된 데이터는 분할되지 않은 데이터보다 훨씬 빠르게 작성되며 대상이 분할되지 않은 경우에도 마찬가지입니다. 다음은 다양한 싱크 형식에 대한 개별 고려 사항입니다.
Azure SQL Database 싱크
Azure SQL Database를 사용하면 대부분의 경우 기본 분할이 작동합니다. 싱크에 SQL 데이터베이스가 처리하기에는 너무 많은 파티션이 있을 가능성이 있습니다. 이 경우 SQL Database 싱크에서 출력하는 파티션 수를 줄입니다.
원본에서 누락된 행을 기반으로 싱크에서 행을 삭제하는 모범 사례
다음은 기존 데이터 흐름, 변경 행 및 싱크 변환을 사용하여 이러한 일반적인 패턴을 달성하는 방법에 대한 비디오 연습입니다.
오류 행 처리가 성능에 미치는 영향
싱크 변환에서 오류 행 처리("오류 발생 시 계속")를 사용하도록 설정하면 서비스는 호환되는 행을 대상 테이블에 쓰기 전에 추가 단계를 수행합니다. 이 추가 단계에는 이 단계에 대해 5% 범위에 추가될 수 있는 작은 성능 저하가 있으며, 호환되지 않는 행을 로그 파일에 기록하도록 옵션을 설정한 경우 추가로 작은 성능 저하도 추가됩니다.
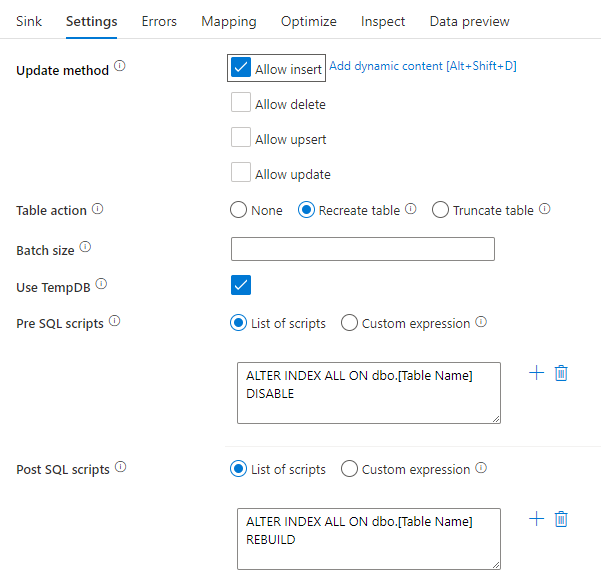
SQL 스크립트를 사용하여 인덱스 비활성화
SQL 데이터베이스에 로드하기 전에 인덱스를 비활성화하면 테이블에 쓰기 성능이 크게 향상됩니다. SQL 싱크에 쓰기 전에 아래 명령을 실행합니다.
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
쓰기가 완료되면 다음 명령을 사용하여 인덱스를 다시 작성합니다.
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
두 가지 작업 모두 매핑 데이터 흐름의 Azure SQL Database 또는 Synapse 싱크 내에서 SQL 사전 및 사후 SQL 스크립트를 사용하여 수행할 수 있습니다.
Warning
인덱스를 사용하지 않도록 설정하면 데이터 흐름이 데이터베이스를 효과적으로 제어하며 이 시점에는 쿼리가 성공할 가능성이 거의 없습니다. 결과적으로 이 충돌을 방지하기 위해 많은 ETL 작업이 야간에 트리거됩니다. 자세한 내용은 SQL 인덱스를 사용하지 않도록 설정하는 제약 조건을 참조하세요.
데이터베이스 스케일 업
일단 DTU 한도에 도달하면, 파이프라인 실행 전에 원본 크기 조정을 예약하고 Azure SQL DB 및 DW를 싱크하여 처리량을 늘리고 Azure 제한을 최소화합니다. 파이프라인 실행이 완료되면 데이터베이스를 다시 일반 실행 속도로 조정합니다.
Azure Synapse Analytics 싱크
Azure Synapse Analytics에 쓸 때 준비 사용을 true로 설정해야 합니다. 이렇게 하면 서비스가 대량의 데이터를 효과적으로 로드하는 SQL COPY 명령을 사용하여 쓸 수 있습니다. 준비를 사용하는 경우 데이터 준비를 위해 Azure Data Lake Storage gen2 또는 Azure Blob Storage 계정을 참조해야 합니다.
준비 외에도, Azure SQL Database와 동일한 모범 사례가 Azure Synapse Analytics에 적용됩니다.
파일 기반 싱크
데이터 흐름은 다양한 파일 형식을 지원하지만 최적의 읽기 및 쓰기 시간을 위해서는 Spark 네이티브 Parquet 형식이 권장됩니다.
데이터가 균등하게 분산된 경우 현재 파티션 나누기 사용이 파일 쓰기에 가장 빠른 파티션 나누기 옵션입니다.
파일 이름 옵션
파일을 작성할 때 성능에 영향을 미치는 명명 옵션을 선택할 수 있습니다.
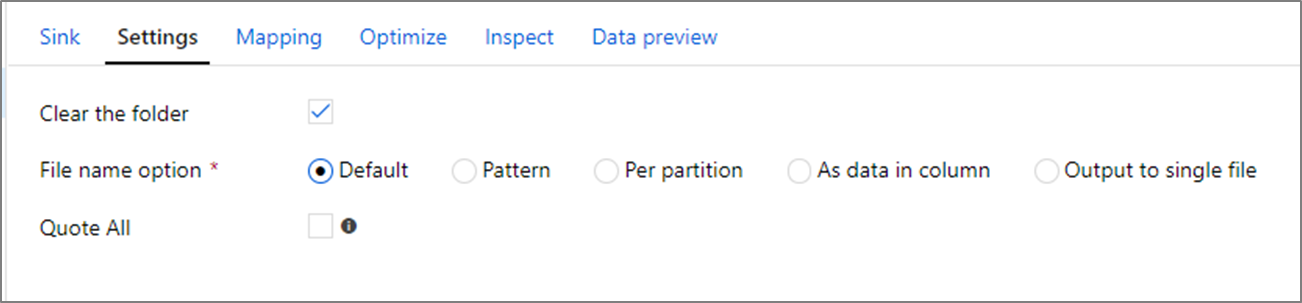
기본값 옵션을 선택하면 가장 빠르게 기록됩니다. 각 파티션은 Spark 기본 이름을 가진 파일과 동일합니다. 이는 데이터 폴더에서 읽기만 하는 경우에 유용합니다.
명명 패턴을 설정하면 각 파티션 파일의 식별 이름이 보다 사용자에게 식별 이름으로 변경됩니다. 이 작업은 쓰기 후에 수행되며 기본값을 선택할 때보다 약간 느립니다.
파티션당을 통해 개별 파티션의 이름을 수동으로 지정할 수 있습니다.
열이 데이터를 출력하는 방법에 해당하는 경우 열 데이터로 파일 이름 지정을 선택할 수 있습니다. 이렇게 하면 데이터가 다시 섞이고 열이 균등하게 분산되지 않으면 성능에 영향을 미칠 수 있습니다.
열이 폴더 이름을 생성하는 방법에 해당하는 경우 열 데이터로 폴더 이름 지정을 선택합니다.
단일 파일로 출력은 모든 데이터를 단일 파티션에 결합합니다. 이렇게 하면 데이터 세트의 크기가 클수록 쓰기 시간이 오래 걸립니다. 이 옵션을 사용해야 하는 명시적인 비즈니스 이유가 없는 한 권장되지 않습니다.
Azure Cosmos DB 싱크
Azure Cosmos DB에 쓸 때 데이터 흐름이 실행되는 동안 처리량과 일괄 처리 크기를 변경하면 성능이 향상될 수 있습니다. 이러한 변경 내용은 데이터 흐름 활동 실행 중에만 적용되며 완료 후에 원래 컬렉션 설정으로 돌아갑니다.
일괄 처리 크기: 일반적으로 기본 일괄 처리 크기로 시작하는 것으로 충분합니다. 이 값을 추가로 튜닝하려면 데이터의 대략적인 개체 크기를 계산하고, 개체 크기 * 일괄 처리 크기가 2MB 미만인지 확인합니다. 미만이면 일괄 처리 크기를 늘려서 처리량을 높일 수 있습니다.
처리량: 여기서 더 높은 처리량을 설정하여 Azure Cosmos DB에 문서를 더 빨리 쓸 수 있습니다. 처리량을 높게 설정하면 더 많은 RU 비용이 발생합니다.
쓰기 처리량 예산: 분당 총 RU보다 작은 값을 사용합니다. Spark 파티션 수가 많은 데이터 흐름이 있는 경우 예산 처리량을 설정하면 해당 파티션 간에 더 많은 균형을 유지할 수 있습니다.
관련 콘텐츠
성능과 관련된 다음과 같은 다른 데이터 흐름 문서를 참조하세요.