변환 최적화
다음 전략을 사용하여 Azure Data Factory 및 Azure Synapse Analytics 파이프라인의 매핑 데이터 흐름에서 변환 성능을 최적화합니다.
조인, 존재 및 조회 최적화
브로드캐스팅
조인, 조회 및 존재 변환에서 하나 또는 두 데이터 스트림이 작업자 노드 메모리에 적합한 작은 크기인 경우 브로드캐스트를 사용하도록 설정하여 성능을 최적화할 수 있습니다. 브로드캐스트를 사용하면 클러스터의 모든 노드에 작은 데이터 프레임을 보내게 됩니다. 그러면 Spark 엔진은 대규모 스트림의 데이터를 다시 섞지 않고도 조인을 수행할 수 있습니다. 기본적으로 Spark 엔진은 조인의 한쪽을 브로드캐스트할지 여부를 자동으로 결정합니다. 수신 데이터에 대해 잘 알고 있고 한 스트림이 다른 스트림보다 작다는 것을 알고 있다면 고정 브로드캐스트를 선택할 수 있습니다. 고정 브로드캐스트는 선택한 스트림을 Spark에서 브로드캐스트하게 합니다.
브로드캐스트된 데이터의 크기가 Spark 노드에 비해 너무 크면 메모리 부족 오류가 발생할 수 있습니다. 메모리 부족 오류를 방지하려면 메모리 최적화 클러스터를 사용합니다. 데이터 흐름을 실행하는 동안 브로드캐스트 시간 제한이 발생하는 경우 브로드캐스트 최적화를 해제하면 됩니다. 그러나 이로 인해 데이터 흐름 성능이 저하됩니다.
큰 데이터베이스 쿼리와 같이 쿼리하는 데 더 오래 걸릴 수 있는 데이터 원본으로 작업하는 경우 조인에 대해 브로드캐스트를 끄는 것이 좋습니다. 원본의 쿼리 시간이 길면 클러스터가 컴퓨팅 노드에 브로드캐스트를 시도할 때 Spark 시간 초과가 발생할 수 있습니다. 나중에 조회 변환에 사용하기 위해 값을 집계하는 스트림이 데이터 흐름에 있는 경우에도 브로드캐스트를 끄는 것이 좋습니다. 이 패턴은 Spark 최적화 프로그램을 혼동시키고 시간 초과를 일으킬 수 있습니다.
크로스 조인
조인 조건에 리터럴 값을 사용하거나 조인의 양쪽에 일치 항목이 여러 개 있는 경우 Spark는 조인을 크로스 조인으로 실행합니다. 크로스 조인은 조인된 값을 필터링하는 완전한 카티전 곱입니다. 이는 다른 조인 형식보다 느립니다. 성능에 영향을 주지 않도록 조인 조건의 양쪽에 열 참조가 있어야 합니다.
조인 전 정렬
SSIS와 같은 도구의 병합 조인과 달리, 조인 변환은 필수 병합 조인 작업이 아닙니다. 조인 키를 변환하기 전에 정렬할 필요가 없습니다. 매핑 데이터 흐름에서 정렬 변환을 사용하는 것은 권장되지 않습니다.
창 변환 성능
매핑 데이터 흐름의 창 변환은 변환 설정의 over() 절에서 선택하는 열 값을 기준으로 데이터를 분할합니다. Windows 변환에는 널리 사용되는 집계 및 분석 함수가 많이 있습니다. 그러나 사용 사례가 순위 지정 rank() 또는 행 번호 rowNumber()에 대해 전체 데이터 세트에 대한 창을 생성하는 것이라면 대신 순위 지정 변환 및 서로게이트 키 변환을 사용하는 것이 좋습니다. 이러한 변환은 해당 함수를 사용하여 전체 데이터 세트 작업을 더 잘 수행합니다.
기울어진 데이터 다시 분할
조인 및 집계와 같은 특정 변환은 데이터 파티션을 다시 섞으며, 이로 인해 경우에 따라 데이터가 기울어질 수 있습니다. 왜곡된 데이터는 데이터가 파티션 전체에 균등하게 분산되지 않음을 의미합니다. 데이터가 많이 기울어지면 다운스트림 변환 및 싱크 쓰기 속도가 저하될 수 있습니다. 데이터 흐름 실행의 모든 시점에서 모니터링 표시의 변환을 클릭하여 데이터 왜도를 확인할 수 있습니다.
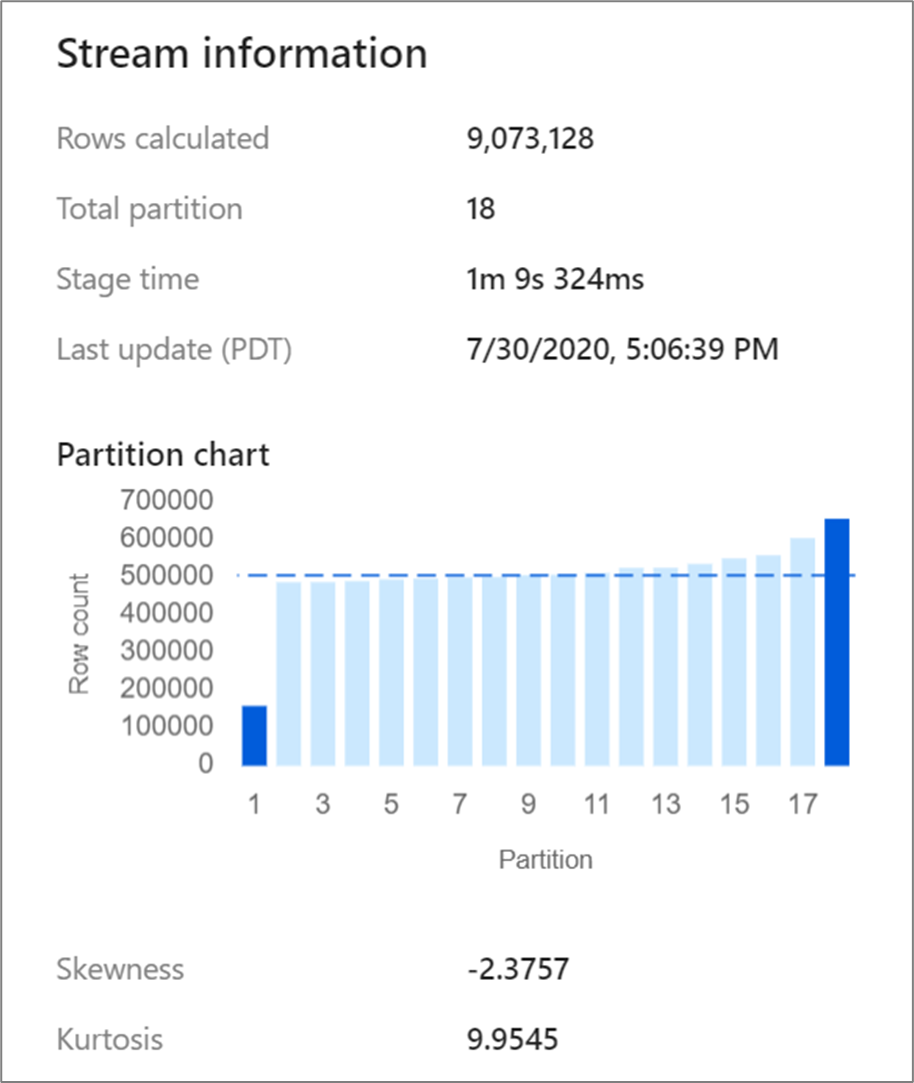
모니터링 표시에는 왜도 및 첨도라는 두 가지 메트릭과 함께 데이터가 각 파티션에 어떻게 분산되어 있는지 표시됩니다. 왜도는 데이터에 허용되는 비대칭성과 데이터가 양수, 0, 음수 또는 정의되지 않은 값을 가질 수 있는지 여부를 측정하는 방법입니다. 음수 기울이기는 왼쪽 꼬리가 오른쪽보다 긴 것을 의미합니다. 첨도는 데이터 꼬리가 굵은지 아니면 얇은지 측정하는 방법입니다. 높은 첨도 값은 바람직하지 않습니다. 적절한 왜도 범위는 -3에서 3 사이이고 첨도 범위는 10 미만입니다. 이 숫자를 해석하는 쉬운 방법은 파티션 차트를 보고 막대 1개가 나머지 막대보다 큰지 확인하는 것입니다.
변환 후 데이터가 균등하게 분할되지 않으면 최적화 탭을 사용하여 다시 분할할 수 있습니다. 데이터를 다시 섞는 데는 시간이 걸리며 데이터 흐름 성능이 개선되지 않을 수 있습니다.
팁
데이터를 다시 분할하지만 데이터를 다시 섞는 다운스트림 변환이 있는 경우 조인 키로 사용되는 열에서 해시 분할을 사용합니다.
참고 항목
싱크 변환을 제외하고 데이터 흐름 내의 변환은 미사용 데이터의 파일 및 폴더 분할을 수정하지 않습니다. 각 변환에서 분할하면 ADF가 각 데이터 흐름 실행에 대해 관리하는 임시 서버리스 Spark 클러스터의 데이터 프레임 내 데이터가 다시 분할됩니다.
관련 콘텐츠
성능과 관련된 다음과 같은 다른 데이터 흐름 문서를 참조하세요.