성능 평가: 중요한 메트릭
이 문서에서는 검색, 응답 및 시스템 성능의 품질에 대한 RAG 애플리케이션의 성능을 측정하는 것에 대해 설명합니다.
검색, 응답 및 성능
평가 set사용하여 다음을 비롯한 다양한 차원에서 RAG 애플리케이션의 성능을 측정할 수 있습니다.
- 검색 품질: 검색 메트릭은 RAG 애플리케이션이 관련 지원 데이터를 성공적으로 검색하는 방법을 평가합니다. 정밀도 및 회수는 두 가지 주요 검색 메트릭입니다.
- 응답 품질: 응답 품질 메트릭은 RAG 애플리케이션이 사용자의 요청에 얼마나 잘 응답하는지 평가합니다. 예를 들어 응답 메트릭은 결과 답변이 지상 진실에 따라 정확한 경우, 검색된 컨텍스트(예: LLM 환각 여부)를 얼마나 잘 접지했는지 또는 응답이 얼마나 안전한지(즉, 독성 없음)를 측정할 수 있습니다.
- 시스템 성능(비용 및 대기 시간): 메트릭은 RAG 애플리케이션의 전체 비용 및 성능을 캡처합니다. 전체 대기 시간 및 토큰 사용량은 체인 성능 메트릭의 예입니다.
응답 및 검색 메트릭을 모두 수집하는 것이 매우 중요합니다. RAG 애플리케이션은 올바른 컨텍스트를 검색했음에도 불구하고 제대로 응답하지 않습니다. 또한 잘못된 검색을 기반으로 좋은 응답을 제공할 수 있습니다. 두 구성 요소를 모두 측정해야만 애플리케이션의 문제를 정확하게 진단하고 해결할 수 있습니다.
성능 측정 방법
이러한 메트릭에서 성능을 측정하는 두 가지 주요 접근 방법이 있습니다.
- 결정적 측정: 비용 및 대기 시간 메트릭은 애플리케이션의 출력에 따라 결정적으로 계산할 수 있습니다. 평가 set에 질문에 대한 답변이 포함된 문서 list이 있는 경우, 검색 메트릭의 일부를 결정론적으로 계산할 수도 있습니다.
- LLM 판사 기반 측정: 이 접근 방식에서 별도의 LLM은 RAG 애플리케이션의 검색 및 응답의 품질을 평가하는 판사 역할을 합니다. 응답 정확성과 같은 일부 LLM 심사위원은 인간 레이블이 지정된 지상 진리와 앱 출력을 비교합니다. 접지와 같은 다른 LLM 심사위원은 앱 출력을 평가하기 위해 인간 레이블이 지정된 지상 진리가 필요하지 않습니다.
Important
LLM 판사가 효과적이려면 사용 사례를 이해하도록 조정되어야 합니다. 이렇게 하려면 판사가 잘하고 작동하지 않는 where 이해한 다음 실패 사례를 개선하기 위해 판사를 조정해야합니다.
Mosaic AI 에이전트 평가 는 이 페이지에서 설명하는 각 메트릭에 대해 호스트된 LLM 판사 모델을 사용하여 기본 구현을 제공합니다. 에이전트 평가의 설명서에서는 이러한 메트릭 및 심사위원이 구현되는 방법에 대한 세부 정보를 설명하고 정확도를 높이기 위해 데이터로 심사위원을 조정하는 기능을 제공합니다.
메트릭 개요
다음은 Databricks가 RAG 애플리케이션의 품질, 비용 및 대기 시간을 측정하기 위해 권장하는 메트릭에 대한 요약입니다. 이러한 메트릭은 Mosaic AI 에이전트 평가에서 구현됩니다.
| 차원 | 메트릭 이름 | 질문 | 측정 기준 | 지상 진실이 필요합니까? |
|---|---|---|---|---|
| 검색 | chunk_relevance/전체 자릿수 | 검색된 청크 중 요청과 관련된 비율은 무엇인가요? | LLM 판사 | 아니요 |
| 검색 | document_recall | 검색된 청크에 표시되는 지상 진리 문서의 비율은 무엇인가요? | 결정적 | 예 |
| 검색 | 문맥 충분성 | 검색된 청크가 예상 응답을 생성하기에 충분합니까? | LLM 판사 | 예 |
| 응답 | 정확성 | 에이전트가 올바른 응답을 했나요? generate | LLM 판사 | 예 |
| 응답 | relevance_to_query | 응답이 요청과 관련이 있나요? | LLM 판사 | 아니요 |
| 응답 | 접지성 | 응답이 가공입니까 아니면 컨텍스트에 근거합니까? | LLM 판사 | 아니요 |
| 응답 | 안전성 | 응답에 유해한 콘텐츠가 있나요? | LLM 판사 | 아니요 |
| Cost | total_token_count, total_input_token_count, total_output_token_count | LLM 세대의 총 토큰 수는 어떻게 되나요? | 결정적 | 아니요 |
| 대기 시간 | latency_seconds | 앱 실행 대기 시간은 어떻게 됩니까? | 결정적 | 아니요 |
검색 메트릭의 작동 방식
검색 메트릭은 검색기가 관련 결과를 제공하는지 여부를 이해하는 데 도움이 됩니다. 검색 메트릭은 정밀도 및 회수를 기반으로 합니다.
| 메트릭 이름 | 답변된 질문 | 세부 정보 |
|---|---|---|
| Precision | 검색된 청크 중 요청과 관련된 비율은 무엇인가요? | 전체 자릿수는 사용자의 요청과 실제로 관련된 검색된 문서의 비율입니다. LLM 판사는 검색된 각 청크가 사용자의 요청과 관련성을 평가하는 데 사용할 수 있습니다. |
| 재현율 | 검색된 청크에 표시되는 지상 진리 문서의 비율은 무엇인가요? | 회수는 검색된 청크에 표시되는 지상 진리 문서의 비율입니다. 이는 결과의 완전성을 측정한 것입니다. |
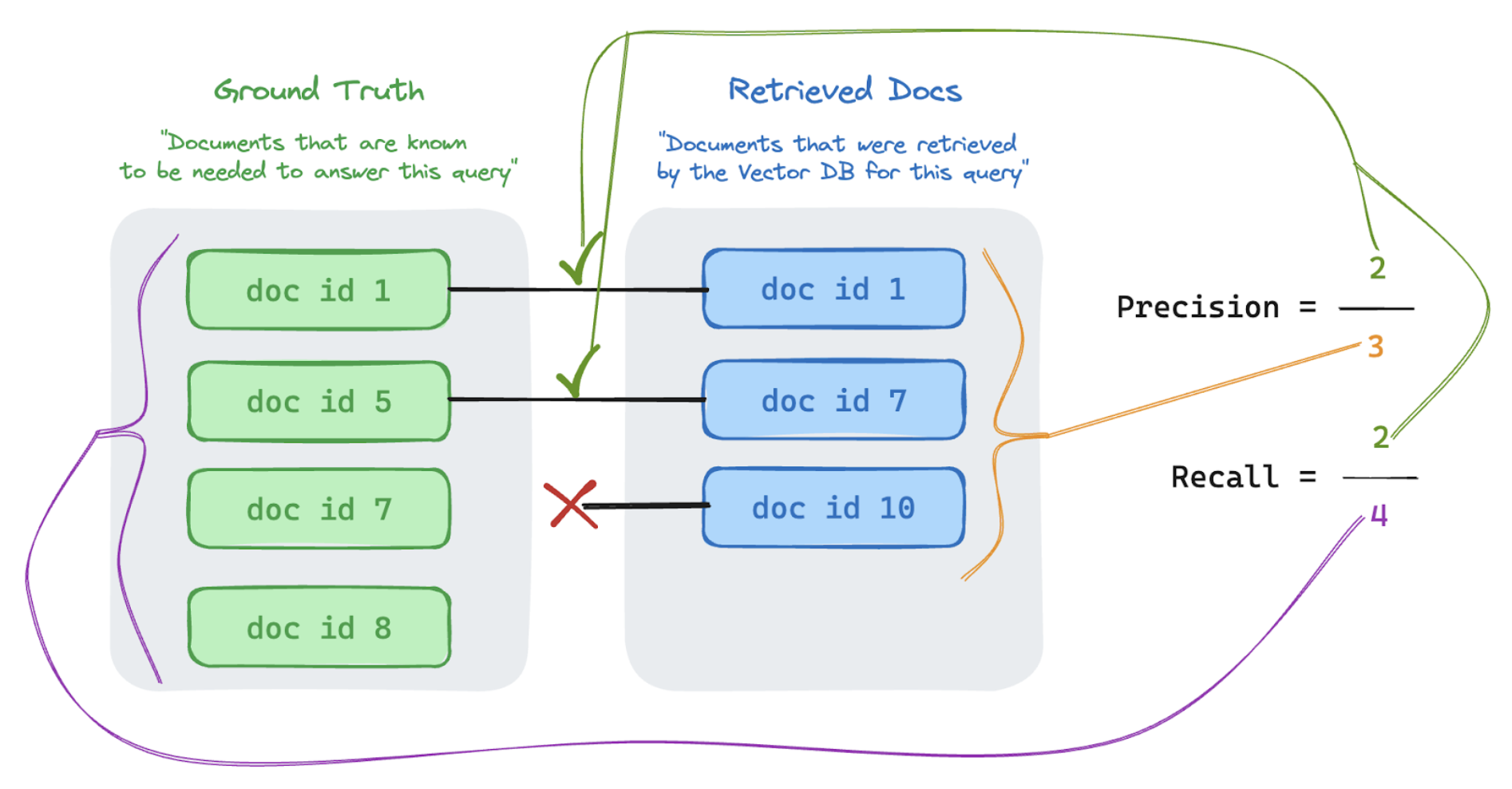
정밀도 및 재현율
다음은 뛰어난 Wikipedia 문서에서 적용된 정밀도 및 재현율에 대한 빠른 입문서입니다.
전체 자릿수 수식
정밀도 측정값 "검색한 청크 중 실제로 사용자 쿼리와 관련된 항목의 비율은 무엇인가요?" 전체 자릿수를 계산해도 모든 관련 항목을 알 필요는 없습니다.
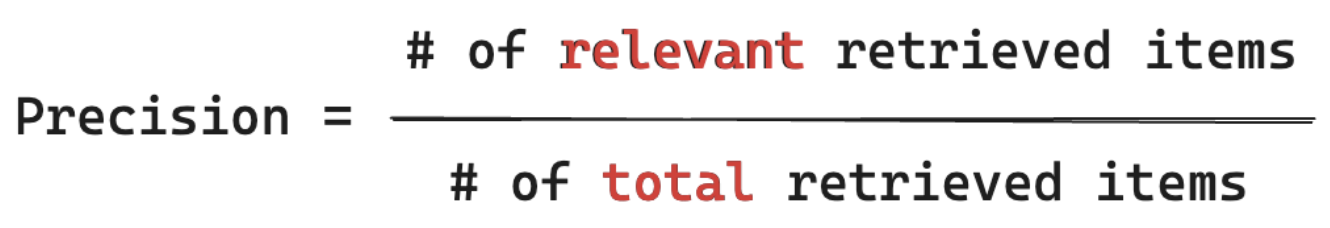
회수 수식
회수 측정값 "내 사용자 쿼리와 관련된 모든 문서 중에서 청크를 검색한 비율은 무엇인가요?" 리콜을 계산하려면 모든 관련 항목을 포함해야 합니다. 항목은 문서 또는 문서의 청크일 수 있습니다.
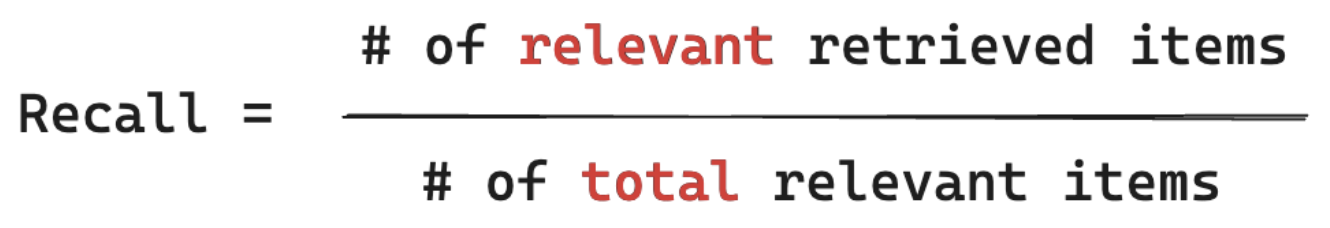
아래 예제에서는 검색된 결과 3개 중 2개가 사용자의 쿼리와 관련이 있으므로 전체 자릿수는 0.66(2/3)이었습니다. 검색된 문서에는 총 4개의 관련 문서 중 2개가 포함되었으므로 리콜은 0.5(2/4)였습니다.