Azure Toolkit for IntelliJ를 사용하여 SSH를 통해 HDInsight 클러스터에서 Apache Spark 애플리케이션 디버그
이 문서에서는 Azure Toolkit for IntelliJ의 HDInsight 도구를 사용하여 HDInsight 클러스터에서 애플리케이션을 원격으로 디버그하는 방법에 대한 단계별 지침을 제공합니다.
필수 조건
HDInsight의 Apache Spark. Apache Spark 클러스터 만들기를 참조하세요.
Windows 컴퓨터에서 로컬 Spark Scala 응용 프로그램을 실행하는 동안 SPARK-2356에서 설명한 예외가 발생할 수 있습니다. 이 예외는 Windows에 WinUtils.exe가 없기 때문에 발생합니다.
이 오류를 해결하려면 Winutils.exe 파일을 C:\WinUtils\bin 등의 위치에 다운로드합니다. 그런 다음 HADOOP_HOME 환경 변수를 추가하고 이 변수 값을 C:\WinUtils로 설정합니다.
IntelliJ IDEA(커뮤니티 버전은 무료입니다.).
SSH 클라이언트. 자세한 내용은 SSH를 사용하여 HDInsight(Apache Hadoop)에 연결을 참조하세요.
Spark Scala 애플리케이션 만들기
IntelliJ IDEA를 시작하고 새 프로젝트 만들기를 선택하여 새 프로젝트 창을 엽니다.
왼쪽 창에서 Apache Spark/HDInsight를 선택합니다.
주 창에서 샘플(Scala)이 포함된 Spark 프로젝트 를 선택합니다.
빌드 도구 드롭다운 목록에서 다음 중 하나를 선택합니다.
- Maven: Scala 프로젝트 만들기 마법사 지원의 경우
- SBT - 종속성 관리 및 Scala 프로젝트용 빌드의 경우
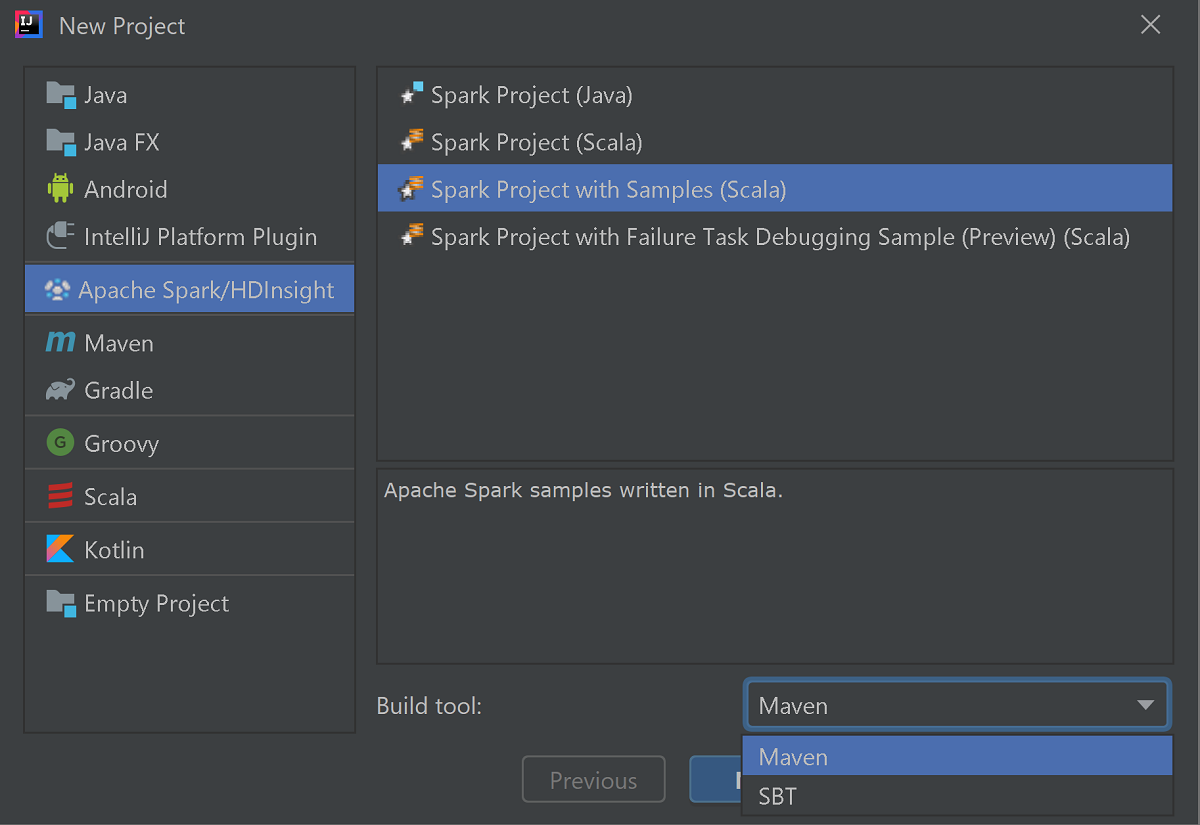
다음을 선택합니다.
다음 새 프로젝트 창에서 다음 정보를 입력합니다.
속성 설명 프로젝트 이름 이름을 입력합니다. 이 연습에서는 myApp를 사용합니다.프로젝트 위치 프로젝트를 저장하기를 원하는 위치를 입력합니다. 프로젝트 SDK 비어 있는 경우 새로 만들기... 를 선택하고 JDK로 이동합니다. Spark 버전 만들기 마법사는 Spark SDK 및 Scala SDK에 대해 적합한 버전을 통합합니다. Spark 클러스터 버전이 2.0 이전인 경우 Spark 1.x를 선택합니다. 그렇지 않은 경우 Spark 2.x.를 선택합니다. 이 예제에서는 Spark 2.3.0(Scala 2.11.8)을 사용합니다. 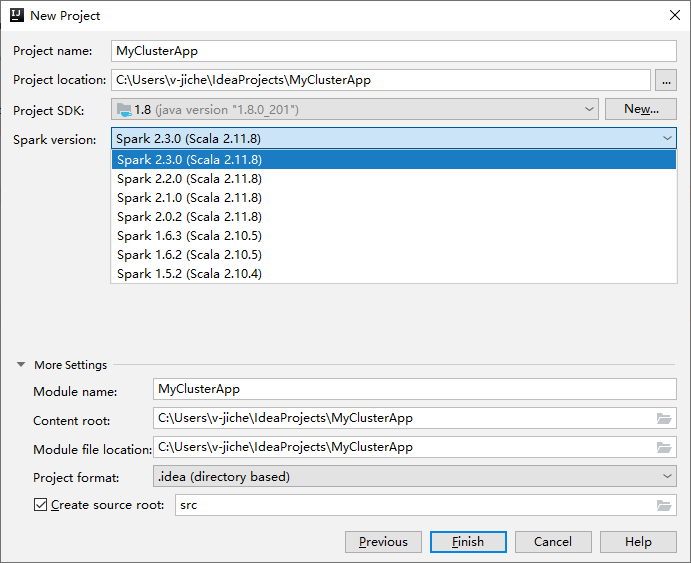
마침을 선택합니다. 프로젝트를 사용할 수 있게 되기까지 몇 분 정도 걸릴 수 있습니다. 오른쪽 아래 모퉁이에 진행률이 표시됩니다.
프로젝트를 확장하고 src>main>scala>sample로 이동합니다. SparkCore_WasbIOTest를 두 번 클릭합니다.
로컬 실행 수행
SparkCore_WasbIOTest 스크립트에서 스크립트 편집기를 마우스 오른쪽 단추로 클릭한 다음 'SparkCore_WasbIOTest' 실행 옵션을 선택하여 로컬 실행을 수행합니다.
로컬 실행이 완료되면 현재 프로젝트 탐색기 data>default에 저장된 출력 파일을 볼 수 있습니다.
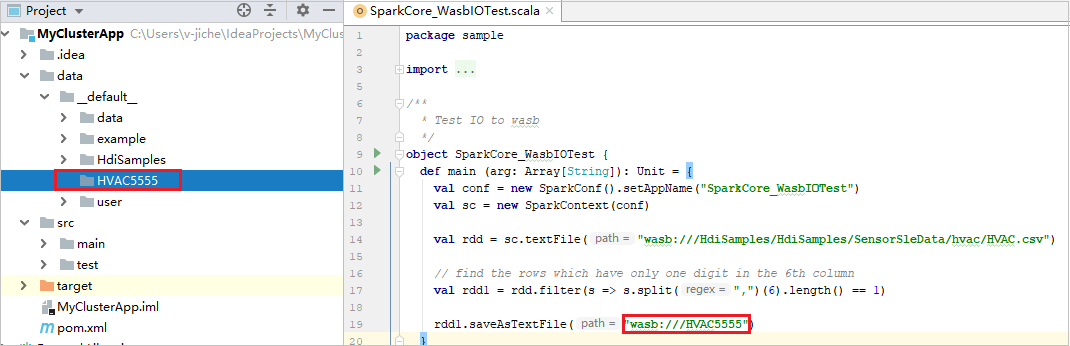
해당 도구는 로컬 실행 및 로컬 디버그를 수행하면 기본 로컬 실행 구성을 자동으로 설정합니다. 오른쪽 위 모서리에서 [Spark on HDInsight] XXX 구성을 엽니다. [Spark on HDInsight]XXX 가 이미 HDInsight의 Apache Spark에 생성되었음을 확인할 수 있습니다. 로컬로 실행 탭으로 전환합니다.
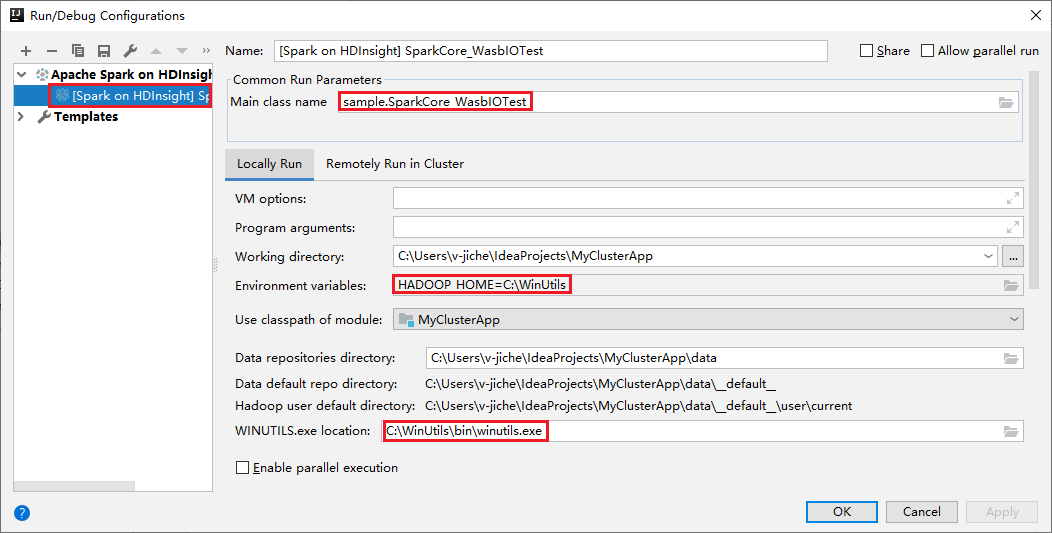
- 환경 변수: 시스템 환경 변수 HADOOP_HOME을 C:\WinUtils로 이미 설정한 경우 자동으로 감지되므로 수동으로 추가할 필요가 없습니다.
- WinUtils.exe 위치: 시스템 환경 변수를 설정하지 않은 경우 해당 단추를 클릭하여 위치를 찾을 수 있습니다.
- 두 가지 옵션 중 하나를 선택하기만 하면 macOS 및 Linux에서는 필요하지 않습니다.
또한 로컬 실행 및 로컬 디버그를 수행하기 전에 수동으로 구성을 설정할 수 있습니다. 이전 스크린샷에서 더하기 기호(+)를 선택합니다. 다음으로 HDInsight의 Apache Spark 옵션을 선택합니다. 저장할 이름, 주 클래스 이름에 대한 정보를 입력하고 로컬 실행 단추를 클릭합니다.
로컬 디버깅 수행
SparkCore_wasbloTest 스크립트를 열고 중단점을 설정합니다.
스크립트 편집기를 마우스 오른쪽 단추로 클릭한 다음 Debug '[Spark on HDInsight]XXX' 옵션을 선택하여 로컬 디버깅을 수행합니다.
원격 실행 수행
실행>구성 편집...으로 이동합니다. 이 메뉴에서 원격 디버깅에 대한 구성을 만들거나 편집할 수 있습니다.
실행/디버깅 구성 대화 상자에서 더하기 기호(+)를 선택합니다. 다음으로 HDInsight의 Apache Spark 옵션을 선택합니다.
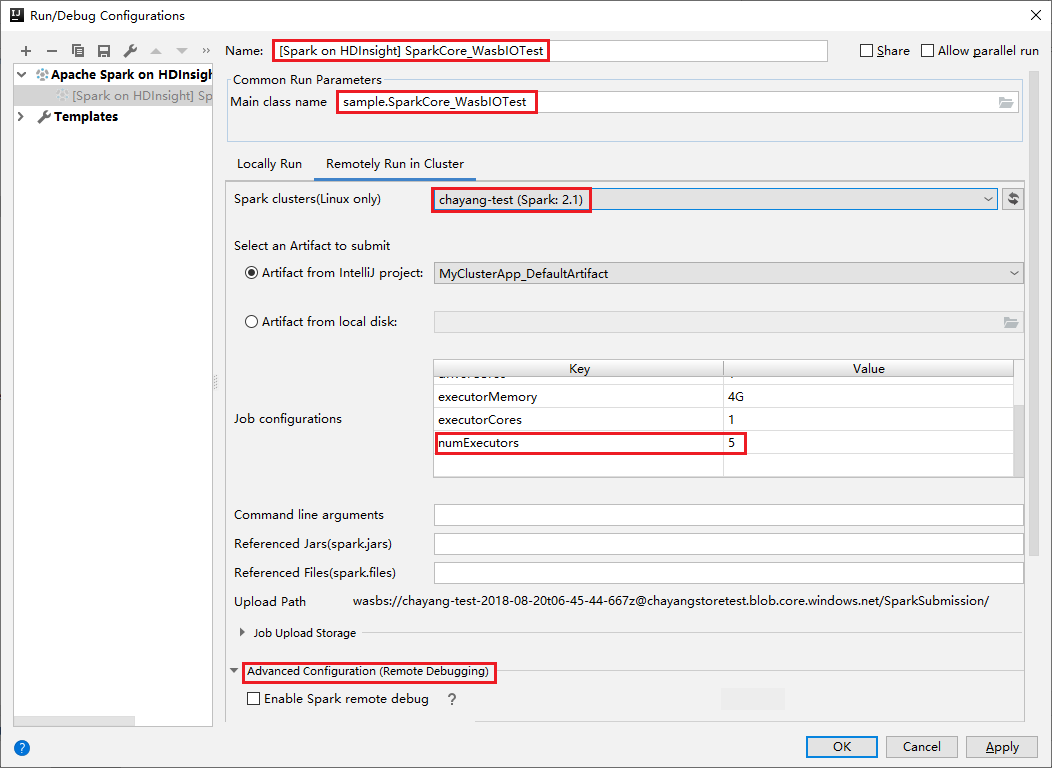
클러스터에서 원격으로 실행 탭으로 전환합니다. 이름, Spark 클러스터, 주 클래스 이름에 정보를 입력합니다. 그런 다음 고급 구성(원격 디버깅)을 클릭합니다. 이 도구는 실행기를 사용하여 디버그를 지원합니다. numExecutors, 기본값은 5입니다. 3보다 큰 값을 설정하지 않는 것이 좋습니다.
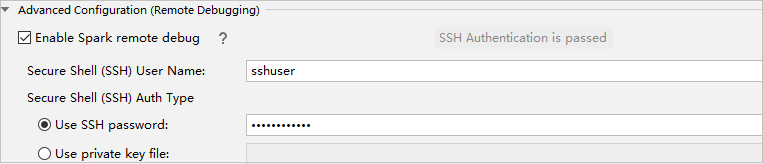
고급 구성(원격 디버깅) 파트에서 Spark 원격 디버그 사용을 선택합니다. SSH 사용자 이름을 입력하고 암호를 입력하거나 프라이빗 키 파일을 사용합니다. 원격 디버그를 수행하려는 경우 설정해야 합니다. 원격 실행만 사용하려는 경우는 설정할 필요가 없습니다.
이제 사용자가 입력한 이름으로 구성이 저장됩니다. 구성 세부 정보를 보려면 구성 이름을 선택합니다. 변경하려면 구성 편집을 선택합니다.
구성 설정을 완료한 후에 원격 클러스터에 대해 프로젝트를 실행하거나 원격 디버깅을 수행할 수 있습니다.

연결 해제 단추를 클릭하면 제출 로그가 왼쪽 패널에 나타나지 않습니다. 그러나 백 엔드에서는 계속 실행되고 있습니다.
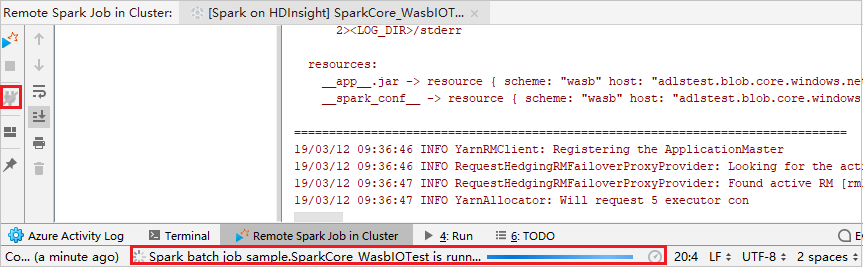
원격 디버깅 수행
중단점을 설정한 다음 원격 디버그 아이콘을 클릭합니다. 원격 제출과의 차이점은 SSH 사용자 이름/암호를 구성해야 한다는 것입니다.

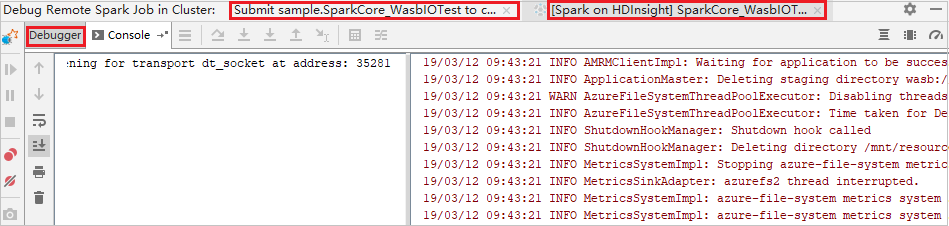
프로그램 실행이 중단점에 도달하면 디버거 창에 1개의 드라이버 탭과 2개의 실행기 탭이 표시됩니다. 프로그램 다시 시작 아이콘을 선택하여 코드를 계속 실행합니다. 그러면 다음 중단점에 도달합니다. 디버깅할 대상 실행기를 찾으려면 올바른 실행기 탭으로 전환해야 합니다. 해당 콘솔 탭에서 실행 로그를 검토할 수 있습니다.
원격 디버깅 및 버그 수정 수행
두 개의 중단점을 설정하고 디버그 아이콘을 선택하여 원격 디버깅 프로세스를 시작합니다.
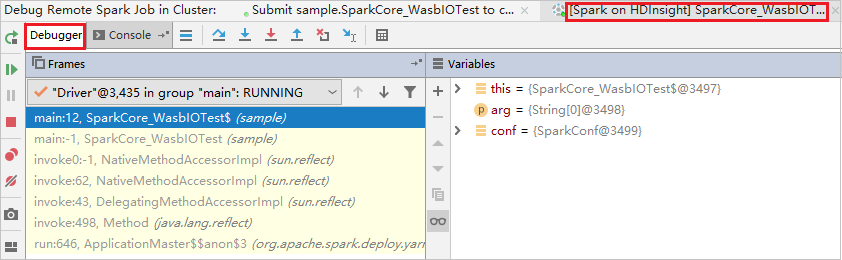
첫 번째 중단점에서 코드가 중지되고 변수 창에 매개 변수 및 변수 정보가 표시됩니다.
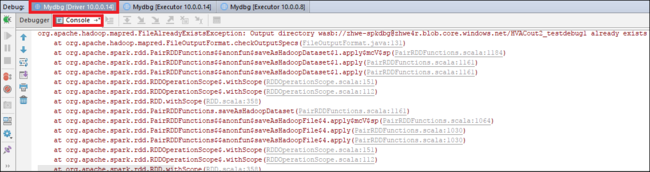
프로그램 다시 시작 아이콘을 선택하여 계속합니다. 두 번째 지점에서 코드가 중지됩니다. 예상대로 예외가 catch됩니다.
프로그램 다시 시작 아이콘을 다시 선택합니다. HDInsight Spark 제출 창에 “작업 실행 실패” 오류가 표시됩니다.
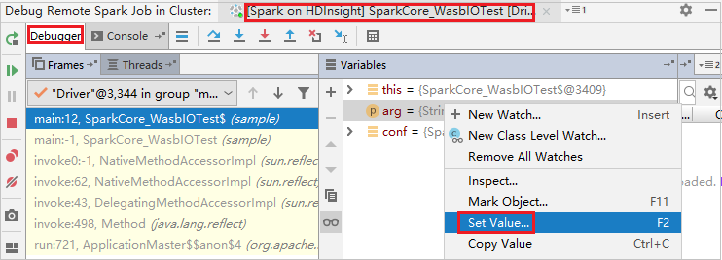
IntelliJ 디버깅 기능을 사용하여 변수 값을 동적으로 업데이트하려면 디버그를 다시 선택합니다. 변수 창이 다시 나타납니다.
디버그 탭에서 대상을 마우스 오른쪽 단추로 클릭한 다음 값 설정을 선택합니다. 다음으로 변수의 새 값을 입력합니다. 그런 다음 Enter 키를 선택하여 값을 저장합니다.
프로그램 다시 시작 아이콘을 선택하여 프로그램을 계속 실행합니다. 이번에는 예외가 catch되지 않습니다. 예외 없이 프로젝트가 성공적으로 실행되는지 확인할 수 있습니다.
다음 단계
시나리오
- BI와 Apache Spark: BI 도구와 함께 HDInsight의 Spark를 사용하여 대화형 데이터 분석 수행
- Machine Learning과 Apache Spark: HVAC 데이터를 사용하여 건물 온도를 분석하는 데 HDInsight의 Spark 사용
- Machine Learning과 Apache Spark: HDInsight의 Spark를 사용하여 식품 검사 결과 예측
- HDInsight의 Apache Spark를 사용한 웹 사이트 로그 분석
애플리케이션 만들기 및 실행
도구 및 확장
- Azure Toolkit for IntelliJ를 사용하여 HDInsight 클러스터용 Apache Spark 애플리케이션 만들기
- Azure Toolkit for IntelliJ를 사용하여 VPN을 통해 원격으로 Apache Spark 애플리케이션 디버그
- Azure Toolkit for Eclipse의 HDInsight 도구를 사용하여 Apache Spark 애플리케이션 만들기
- HDInsight에서 Apache Spark 클러스터와 함께 Apache Zeppelin Notebook 사용
- HDInsight의 Apache Spark 클러스터에서 Jupyter Notebook에 사용할 수 있는 커널
- Jupyter Notebook에서 외부 패키지 사용
- 컴퓨터에 Jupyter를 설치하고 HDInsight Spark 클러스터에 연결