Azure Logic Apps에서 예외 및 오류 처리
적용 대상: Azure Logic Apps(사용량 + 표준)
통합 아키텍처가 가동 중지 시간 또는 종속 시스템에 의해 발생한 문제를 적절하게 처리하는 일은 어려울 수 있습니다. Azure Logic Apps는 문제와 실패에서 정상적으로 처리하는 강력하고 복원 가능한 통합을 구현하기 위해 오류와 예외를 처리하는 최상의 환경을 제공합니다.
재시도 정책
가장 기본적인 예외 및 오류 처리의 경우 트리거 또는 작업에서 지원되면 HTTP 작업과 같은 재시도 정책을 사용할 수 있습니다. 트리거 또는 작업의 원래 요청 시간이 초과되거나 실패하여 408, 429 또는 5xx 응답이 발생하는 경우 재시도 정책은 트리거 또는 작업이 정책 설정별로 요청을 다시 보내도록 지정합니다.
재시도 정책 한도
재시도 정책, 설정, 한도 및 기타 옵션에 대한 자세한 내용은 재시도 정책 한도를 검토하세요.
재시도 정책 유형
재시도 정책을 지원하는 커넥터 작업은 다른 재시도 정책을 선택하지 않는 한 기본 정책을 사용합니다.
| 다시 시도 정책 | 설명 |
|---|---|
| 기본값 | 대부분의 작업에서 기본 재시도 정책은 기하급수적으로 증가하는 간격으로 최대 4번의 재시도를 보내는 지수 간격 정책입니다. 이 간격은 7.5초 단위로 조정되지만 5초에서 45초 사이로 제한됩니다. 여러 작업에서 고정 간격 정책과 같은 다른 기본 재시도 정책을 사용합니다. 자세한 내용은 기본 재시도 정책 형식을 참조하세요. |
| 없음 | 요청을 다시 보내지 않습니다. 자세한 내용은 없음 - 재시도 정책 없음을 참조하세요. |
| 기하급수적 간격 | 이 정책은 다음 요청을 보내기 전에 기하급수적으로 증가하는 범위에서 선택된 임의의 간격만큼 대기합니다. 자세한 내용은 기하급수적 간격 정책 유형을 검토하세요. |
| 고정 간격 | 이 정책은 다음 요청을 보내기 전에 지정된 간격만큼 대기합니다. 자세한 내용은 고정 간격 정책 유형을 검토하세요. |
디자이너에서 재시도 정책 유형 변경
Azure Portal의 디자이너에서 논리 앱 워크플로를 엽니다.
사용량 또는 표준 워크플로에서 작업하는지 여부에 따라 트리거 또는 작업의 설정을 엽니다.
소비: 작업 셰이프에서 줄임표 메뉴(...)를 열고 설정을 선택합니다.
표준: 디자이너에서 작업을 선택합니다. 세부 정보 창에서 설정를 선택합니다.
트리거 또는 작업이 재시도 정책을 지원하는 경우 재시도 정책에서 원하는 정책 유형을 선택합니다.
코드 뷰 편집기에서 재시도 정책 유형 변경
필요한 경우 디자이너의 이전 단계를 완료하여 트리거 또는 작업이 재시도 정책을 지원하는지 확인합니다.
코드 뷰 편집기에서 논리 앱 워크플로를 엽니다.
트리거 또는 작업 정의에서 해당 트리거 또는 작업의
inputs개체에retryPolicyJSON 개체를 추가합니다. 그렇지 않으면retryPolicy개체가 없을 경우 트리거 또는 작업에서default재시도 정책을 사용합니다."inputs": { <...>, "retryPolicy": { "type": "<retry-policy-type>", // The following properties apply to specific retry policies. "count": <retry-attempts>, "interval": "<retry-interval>", "maximumInterval": "<maximum-interval>", "minimumInterval": "<minimum-interval>" }, <...> }, "runAfter": {}Required
속성 값 형식 설명 type<retry-policy-type> 문자열 사용할 재시도 정책 유형: default,none,fixed또는exponentialcount<retry-attempts> 정수 fixed및exponential정책 유형에 대한 재시도 횟수(1-90의 값)입니다. 자세한 내용은 고정 간격 및 기하급수적 간격을 검토하세요.interval<retry-interval> 문자열 fixed및exponential정책 유형에 대한 ISO 8601 형식의 재시도 간격 값입니다.exponential정책의 경우 선택적 최대 및 최소 간격을 지정할 수도 있습니다. 자세한 내용은 고정 간격 및 기하급수적 간격을 검토하세요.
소비: 5초(PT5S)~1일(P1D)입니다.
표준: 상태 저장 워크플로의 경우 5초(PT5S)~1일(P1D)입니다. 상태 비저장 워크플로의 경우 1초(PT1S)~1분(PT1M)입니다.선택 사항
속성 값 형식 설명 maximumInterval<maximum-interval> 문자열 exponential정책에 대해 임의로 선택한 간격의 최대 간격(ISO 8601 형식)입니다. 기본값은 1일입니다(P1D). 자세한 내용은 기하급수적 간격을 검토하세요.minimumInterval<minimum-interval> 문자열 exponential정책에 대해 임의로 선택한 간격의 최소 간격(ISO 8601 형식)입니다. 기본값은 5초입니다(PT5S). 자세한 내용은 기하급수적 간격을 검토하세요.
기본 재시도 정책
재시도 정책을 지원하는 커넥터 작업은 다른 재시도 정책을 선택하지 않는 한 기본 정책을 사용합니다. 대부분의 작업에서 기본 재시도 정책은 기하급수적으로 증가하는 간격으로 최대 4번의 재시도를 보내는 지수 간격 정책입니다. 이 간격은 7.5초 단위로 조정되지만 5초에서 45초 사이로 제한됩니다. 여러 작업에서 고정 간격 정책과 같은 다른 기본 재시도 정책을 사용합니다.
워크플로 정의에서 트리거 또는 작업 정의는 기본 정책을 명시적으로 정의하지 않지만 다음 예에서는 HTTP 작업에 대해 기본 재시도 정책이 작동하는 방식을 보여 줍니다.
"HTTP": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "http://myAPIendpoint/api/action",
"retryPolicy" : {
"type": "exponential",
"interval": "PT7S",
"count": 4,
"minimumInterval": "PT5S",
"maximumInterval": "PT1H"
}
},
"runAfter": {}
}
None - 재시도 정책 없음
작업 또는 트리거가 실패한 요청을 다시 시도하지 않도록 지정하려면 <retry-policy-type>을 none으로 설정합니다.
고정 간격 재시도 정책
작업 또는 트리거가 다음 요청을 보내기 전에 지정된 간격 동안 대기하도록 지정하려면 <retry-policy-type>을 fixed로 설정합니다.
예제
이 재시도 정책은 각 시도 간에 30초를 지연하면서 실패한 첫 번째 요청 후에 최신 뉴스를 두 번 더 가져오려고 합니다.
"Get_latest_news": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "https://mynews.example.com/latest",
"retryPolicy": {
"type": "fixed",
"interval": "PT30S",
"count": 2
}
}
}
기하급수적 간격 재시도 정책
기하급수적 간격 재시도 정책은 트리거 또는 작업이 다음 요청을 보내기 전에 임의 간격 동안 대기하도록 지정합니다. 임의 간격은 기하급수적으로 증가하는 범위에서 선택됩니다. 선택적으로 소비 또는 표준 논리 앱 워크플로가 있는지를 기준으로 고유한 최소 및 최대 간격을 지정하여 기본 최소 및 최대 간격을 재정의할 수 있습니다.
| 이름 | 소비 제한 | 표준 제한 | 주의 |
|---|---|---|---|
| 최소 지연 | 기본값: 1일 | 기본값: 1시간 | 소비 논리 앱 워크플로의 기본 제한을 변경하려면 재시도 정책 매개 변수를 사용합니다. 표준 논리 앱 워크플로에서 기본값을 변경하려면 단일 테넌트 Azure Logic Apps에서 논리 앱에 대한 호스트 및 앱 설정 편집을 검토하세요. |
| 최소 지연 | 기본값: 5초 | 기본값: 5초 | 소비 논리 앱 워크플로의 기본 제한을 변경하려면 재시도 정책 매개 변수를 사용합니다. 표준 논리 앱 워크플로에서 기본값을 변경하려면 단일 테넌트 Azure Logic Apps에서 논리 앱에 대한 호스트 및 앱 설정 편집을 검토하세요. |
임의 변화 범위
기하급수적 간격 재시도 정책에 대해 다음 표에는 Azure Logic Apps이 각 재시도에 대해 지정된 범위에서 균일한 임의 변수를 생성하는 데 사용하는 일반 알고리즘이 나와 있습니다. 지정된 범위는 최대 재시도 횟수가 될 수 있습니다.
| 재시도 횟수 | 최소 간격 | 최대 간격 |
|---|---|---|
| 1 | max(0, <minimum-interval>) | min(interval, <maximum-interval>) |
| 2 | max(interval, <minimum-interval>) | min(2 * interval, <maximum-interval>) |
| 3 | max(2 * interval, <minimum-interval>) | min(4 * interval, <maximum-interval>) |
| 4 | max(4 * interval, <minimum-interval>) | min(8 * interval, <maximum-interval>) |
| .... | .... | .... |
“이후 실행” 동작 관리
워크플로 디자이너에 작업을 추가할 때 암시적으로 해당 작업을 실행할 때 사용할 순서를 선언합니다. 어느 작업이 실행을 완료한 뒤, 해당 작업은 Succeeded, Failed, Skipped 또는 TimedOut 등의 상태로 표시됩니다. 기본적으로, 디자이너에 추가한 작업은 선행 작업이 Succeeded 상태로 완료된 이후에만 실행됩니다. 작업의 기본 정의에서 runAfter 속성은 먼저 완료하여야 하는 선행 작업을 지정하고 후속 작업을 실행할 수 있게 되기 전에 해당 선행 작업에 대한 허용 상태를 지정합니다.
어떤 작업이 처리되지 않은 오류나 예외가 되면 해당 작업은 Failed로 표시되며, 모든 후속 작업은 Skipped로 표시됩니다. 병렬 분기가 있는 작업에 대하여 이런 동작이 발생하면 Azure Logic Apps 엔진은 완료 상태를 판단하기 위하여 다른 분기를 따릅니다. 예를 들어 어떤 분기가 Skipped 작업으로 마무리되면, 해당 분기의 완료 상태는 건너뛴 작업의 선행 작업 상태를 기준으로 합니다. 워크플로 실행이 완료되면, 엔진에서 모든 분기의 상태를 평가하여 전체 실행의 상태를 확인합니다. 실패하는 분기가 생기면 전체 논리 앱의 실행은 Failed로 표시됩니다.
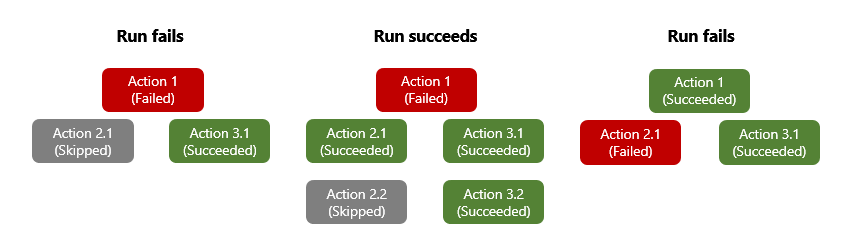
선행 작업의 상태에도 불구하고 작업을 여전히 실행할 수 있도록 하려면, 작업의 “이후 실행” 동작을 변경하여 선행 작업의 실패 상태를 처리할 수 있습니다. 이렇게 하면 선행 작업의 상태가 Succeeded, Failed, Skipped, TimedOut 또는 모든 이러한 상태에 해당할 때 작업이 실행됩니다.
예를 들어 Excel Online에서 행을 테이블에 추가 선행 작업이 Succeeded가 아닌 Failed로 표시된 후 Office 365 Outlook 메일 보내기 작업을 실행하려면 디자이너 또는 코드 뷰 편집기를 사용하여 “이후 실행” 동작을 변경합니다.
참고 항목
디자이너에서 첫 번째 작업을 실행하기 전에 트리거가 성공적으로 실행되어야 하므로 트리거 바로 뒤에 있는 작업에는 “이후 실행” 설정이 적용되지 않습니다.
디자이너에서 “이후 실행” 동작 변경
Azure Portal의 디자이너에서 논리 앱 워크플로를 엽니다.
디자이너에서 작업 셰이프를 선택합니다. 세부 정보 창에서 설정를 선택합니다.
설정 창의 실행 후 섹션에는 현재 선택한 작업에 대한 선행 작업이 표시됩니다.
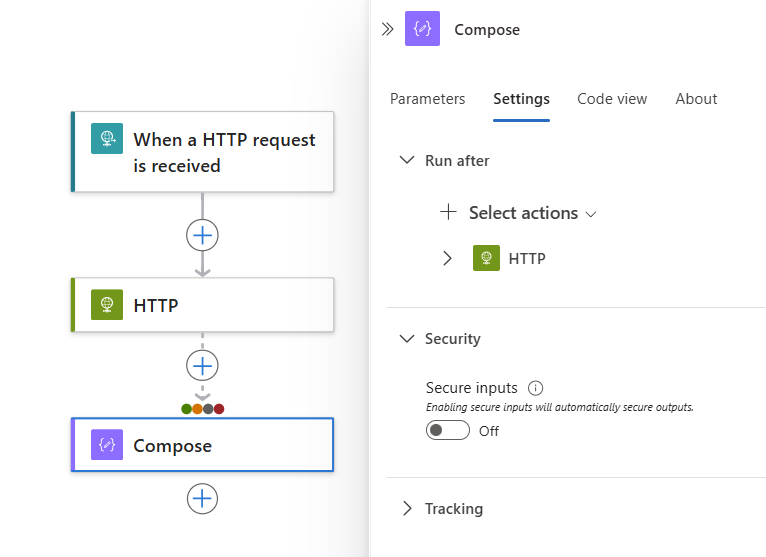
선행 작업을 확장하여 가능한 모든 선행 작업 상태를 확인합니다.
기본적으로 "실행 후" 상태는 Is 성공으로 설정됩니다. 따라서 현재 선택한 작업을 실행하기 전에 선행 작업 완료가 완료되어야 합니다.
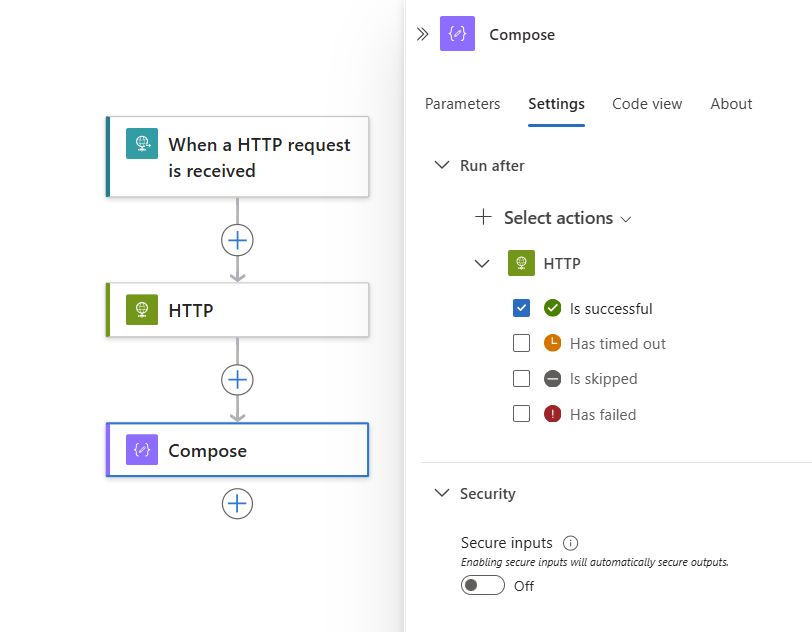
"실행 후" 동작을 원하는 상태로 변경하려면 해당 상태를 선택합니다. 기본 옵션을 지우기 전에 먼저 옵션을 선택해야 합니다. 항상 하나 이상의 옵션을 선택해야 합니다.
다음 예제에서는 실패를 선택합니다.
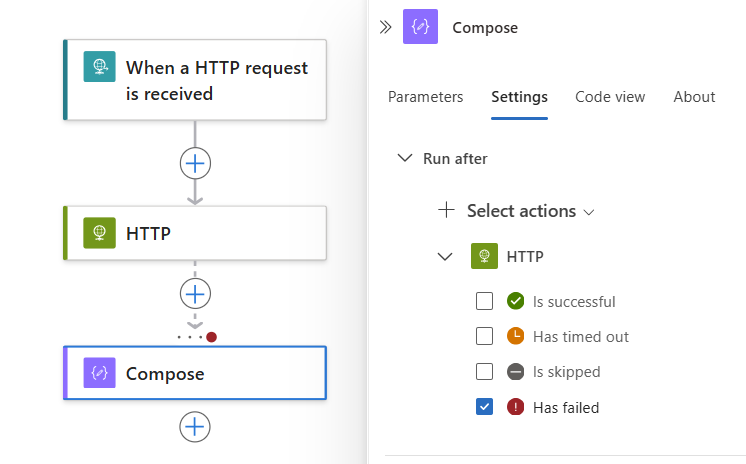
선행 작업이 실패, 건너뛰기 또는 TimedOut 상태로 완료될 때 현재 작업이 실행되도록 지정하려면 다음 상태를 선택합니다.
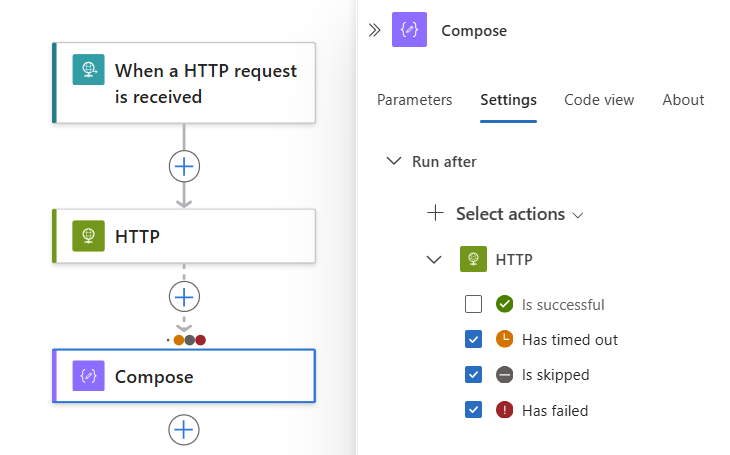
각각 고유한 “이후 실행” 상태가 있는 둘 이상의 선행 작업 실행을 요구하려면 작업 선택 목록을 확장합니다. 원하는 선행 작업을 선택하고 필요한 “이후 실행” 상태를 지정합니다.
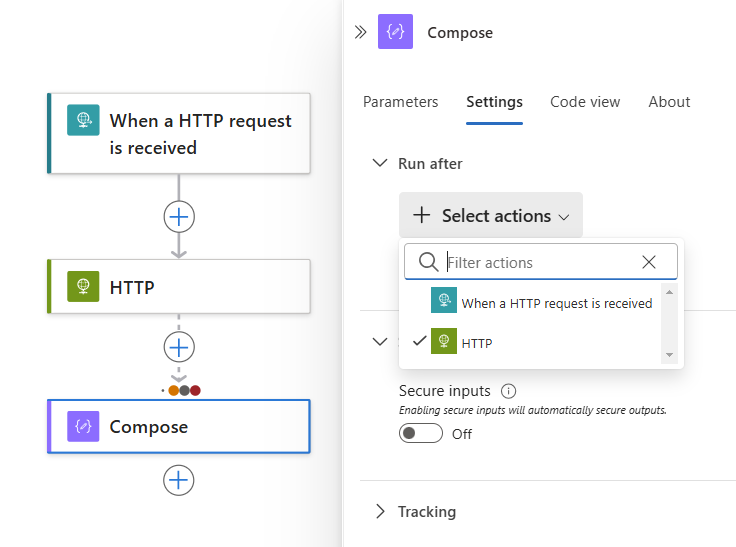
준비가 되면 완료를 선택합니다.
코드 뷰 편집기에서 “이후 실행” 동작 변경
Azure Portal의 코드 뷰 편집기에서 논리 앱 워크플로를 엽니다.
작업의 JSON 정의에서, 다음 구문을 따르는
runAfter속성을 편집합니다."<action-name>": { "inputs": { "<action-specific-inputs>" }, "runAfter": { "<preceding-action>": [ "Succeeded" ] }, "type": "<action-type>" }본 예제에서는
runAfter속성을Succeeded에서Failed로 변경합니다."Send_an_email_(V2)": { "inputs": { "body": { "Body": "<p>Failed to add row to table: @{body('Add_a_row_into_a_table')?['Terms']}</p>", "Subject": "Add row to table failed: @{body('Add_a_row_into_a_table')?['Terms']}", "To": "Sophia.Owen@fabrikam.com" }, "host": { "connection": { "name": "@parameters('$connections')['office365']['connectionId']" } }, "method": "post", "path": "/v2/Mail" }, "runAfter": { "Add_a_row_into_a_table": [ "Failed" ] }, "type": "ApiConnection" }선행 작업이
Failed,Skipped또는TimedOut으로 표시될 때 실행할 작업을 지정하려면 다른 상태를 추가합니다."runAfter": { "Add_a_row_into_a_table": [ "Failed", "Skipped", "TimedOut" ] },
범위 및 해당 결과를 사용하여 작업 평가
“이후 실행” 설정으로 개별 작업 이후에 단계를 실행하는 것과 유사하게 범위 내의 작업을 모두 그룹화할 수 있습니다. 작업을 논리적으로 그룹화하고, 범위의 집계 상태를 평가하고, 해당 상태에 따라 작업을 수행하려는 경우 범위를 사용할 수 있습니다. 범위 내 모든 작업의 실행이 완료되면 범위 자체에서 자체의 상태를 가져옵니다.
범위의 상태를 확인하려면 성공, 실패 등과 같이 워크플로의 실행 상태를 확인하는 데 사용하는 것과 동일한 기준을 사용할 수 있습니다.
기본적으로 범위의 모든 작업이 성공하면 범위 상태가 성공으로 표시됩니다. 범위의 마지막 작업이 Failed 또는 Aborted로 표시되는 경우 범위 상태는 Failed로 표시됩니다.
Failed 범위의 예외를 catch하고 해당 오류를 처리하는 작업을 실행하려면 해당 Failed 범위에 대해 “이후 실행” 설정을 사용할 수 있습니다. 이렇게 하는 경우 범위의 모든 작업이 실패하고 해당 범위에 대해 “이후 실행” 설정을 사용하면 실패를 catch하는 단일 작업을 만들 수 있습니다.
범위에 대한 제한은 제한 및 구성을 참조하세요.
예외 처리를 위해 "실행 후"로 범위 설정
Azure Portal의 디자이너에서 논리 앱 워크플로를 엽니다.
워크플로에 워크플로를 시작하는 트리거가 이미 있어야 합니다.
디자이너에서 다음 일반 단계에 따라 범위라는 Control 작업을 워크플로에 추가합니다.
범위 작업에서 다음 제네릭 단계에 따라 실행할 작업 추가(예:
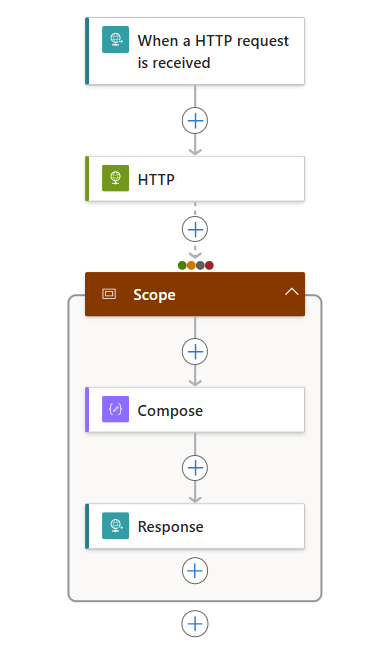
다음 목록에서는 범위 작업 내에 포함할 수 있는 몇 가지 예제 작업을 보여 줍니다.
- API에서 데이터를 가져옵니다.
- 데이터를 처리합니다.
- 데이터를 데이터베이스에 저장합니다.
이제 범위에서 작업을 실행하기 위한 "실행 후" 규칙을 정의합니다.
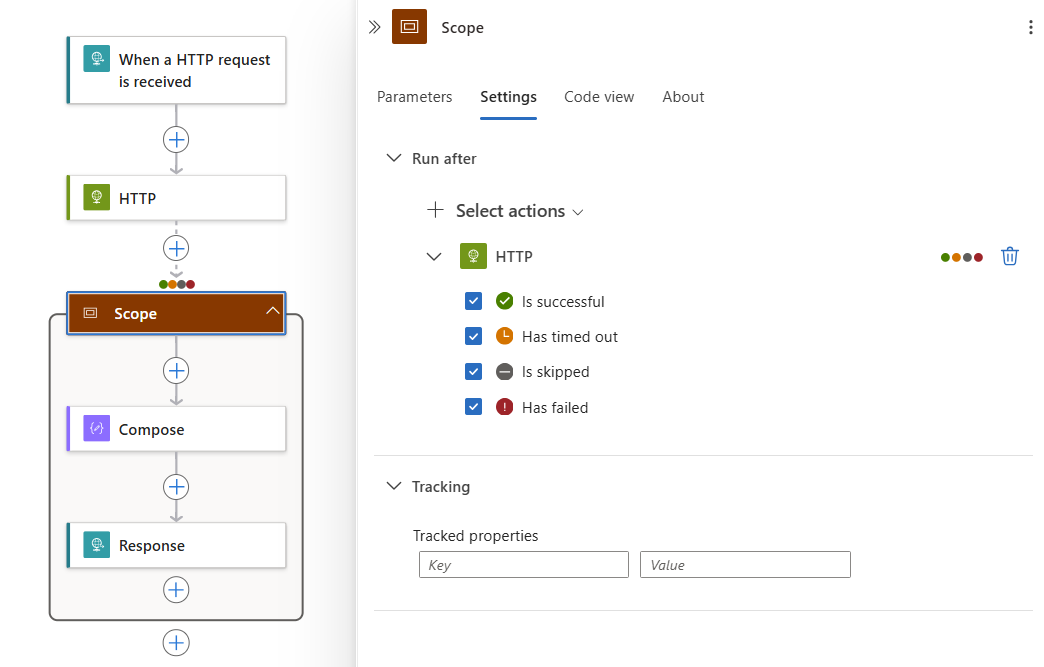
디자이너에서 범위 제목을 선택합니다. 범위의 정보 창이 열리면 설정을 선택합니다.
워크플로 에 이전 작업이 두 개 이상 있는 경우 작업 선택 목록에서 범위가 지정된 작업을 실행하려는 작업을 선택합니다.
선택한 작업의 경우 범위가 지정된 작업을 실행할 수 있는 모든 작업 상태를 선택합니다.
즉, 선택한 작업으로 인해 선택한 상태 중에서 범위 내의 작업이 실행되도록 합니다.
다음 예제에서는 HTTP 작업이 완료된 후 선택한 상태와 함께 범위가 지정된 작업이 실행됩니다.
실패에 대한 컨텍스트 및 결과 가져오기
범위에서 실패를 catch하는 것이 유용하지만, 실패한 작업과 반환된 오류 또는 상태 코드를 정확히 파악하는 데 더 많은 컨텍스트가 필요할 수 있습니다. 이 함수result()가 지정된 작업에서 최상위 작업의 결과를 반환합니다. 이 함수는 범위의 이름을 단일 매개 변수로 허용하고 해당 최상위 작업의 결과가 포함된 배열을 반환합니다. 이러한 작업 개체에는 actions() 함수로 인하여 반환된 해당 작업의 시작 시간, 종료 시간, 상태, 입력, 상관 관계 ID, 출력 등의 특성이 있습니다.
참고 항목
result() 함수는 결과를 오로지 최상위 수준 작업에서만 반환하며 변환이나 조건 작업처럼 더 깊이 중첩된 작업에서 반환하지 않습니다.
범위에서 실패한 작업에 대한 컨텍스트를 가져오려면 해당 범위의 이름과 “이후 실행” 설정을 통하여 @result() 식을 사용할 수 있습니다. 반환한 배열을 Failed 상태인 작업으로 필터링하기 위하여 배열 필터링 작업을 추가할 수 있습니다. 반환한 실패 작업에 대한 작업을 실행하려면 필터링하여 반환한 배열을 가져와 For each 반복을 사용합니다.
다음 JSON 예제에서는 My_Scope 범위 작업 내에서 실패한 작업의 응답 본문이 포함된 HTTP POST 요청을 보냅니다. 자세한 설명은 예제를 따릅니다.
"Filter_array": {
"type": "Query",
"inputs": {
"from": "@result('My_Scope')",
"where": "@equals(item()['status'], 'Failed')"
},
"runAfter": {
"My_Scope": [
"Failed"
]
}
},
"For_each": {
"type": "foreach",
"actions": {
"Log_exception": {
"type": "Http",
"inputs": {
"method": "POST",
"body": "@item()['outputs']['body']",
"headers": {
"x-failed-action-name": "@item()['name']",
"x-failed-tracking-id": "@item()['clientTrackingId']"
},
"uri": "http://requestb.in/"
},
"runAfter": {}
}
},
"foreach": "@body('Filter_array')",
"runAfter": {
"Filter_array": [
"Succeeded"
]
}
}
다음 단계에서는 이 예제에서 발생하는 상황을 설명합니다.
My_Scope 내의 모든 작업에서 결과를 가져오기 위해 배열 필터링 작업은 필터 식
@result('My_Scope')를 사용합니다.배열 필터링의 조건은 상태가
Failed와 같은 모든@result()항목입니다. 이 조건은 My_Scope의 모든 작업 결과에 대한 배열을 실패한 작업 결과만 있는 배열로 필터링합니다.필터링된 배열 출력에서
For_each반복 작업을 실행합니다. 이 단계는 이전에 필터링된 실패한 작업 결과 각각에 대해 작업을 수행합니다.범위에서 단일 작업이 실패한 경우
For_each반복의 작업은 한 번만 실행됩니다. 여러 실패한 작업에서 오류당 하나의 작업이 발생합니다.@item()['outputs']['body']식인For_each항목 응답 본문에 HTTP POST를 보냅니다.@result()항목 모양은@actions()모양과 같으며 동일한 방식으로 구문 분석할 수 있습니다.실패한 작업 이름(
@item()['name']) 및 실패한 실행 클라이언트 추적 ID(@item()['clientTrackingId'])가 있는 두 개의 사용자 지정 헤더를 포함됩니다.
참고로 이전 예제에서 구문 분석하는 name, body 및 clientTrackingId 속성을 보여 주는 단일 @result() 항목의 예제는 다음과 같습니다. For_each 작업 외부에서 @result()는 해당 개체의 배열을 반환합니다.
{
"name": "Example_Action_That_Failed",
"inputs": {
"uri": "https://myfailedaction.azurewebsites.net",
"method": "POST"
},
"outputs": {
"statusCode": 404,
"headers": {
"Date": "Thu, 11 Aug 2016 03:18:18 GMT",
"Server": "Microsoft-IIS/8.0",
"X-Powered-By": "ASP.NET",
"Content-Length": "68",
"Content-Type": "application/json"
},
"body": {
"code": "ResourceNotFound",
"message": "/docs/folder-name/resource-name does not exist"
}
},
"startTime": "2016-08-11T03:18:19.7755341Z",
"endTime": "2016-08-11T03:18:20.2598835Z",
"trackingId": "bdd82e28-ba2c-4160-a700-e3a8f1a38e22",
"clientTrackingId": "08587307213861835591296330354",
"code": "NotFound",
"status": "Failed"
}
다른 예외 처리 패턴을 수행하려면 이 문서의 앞부분에서 설명한 식을 사용할 수 있습니다. 실패를 전부 필터한 배열을 허용하는 범위 외부의 작업을 처리하는 단일 예외를 실행하고 For_each 작업을 제거하도록 선택할 수 있습니다. 또한 앞에서 설명한 대로 \@result() 응답의 다른 유용한 속성을 포함할 수도 있습니다.
Azure Monitor 로그 설정
이전 패턴은 실행 내에서 발생하는 오류 및 예외를 처리하는 유용한 방법입니다. 그러나 실행과 독립적으로 발생하는 오류를 식별하고 대응할 수도 있습니다. 실행 상태를 평가하기 위해 실행에 대한 로그 및 메트릭을 모니터링하거나 원하는 모니터링 도구에 게시할 수 있습니다.
예를 들어 Azure Monitor는 모든 실행 및 작업 상태를 포함한 모든 워크플로 이벤트를 대상으로 보내는 간소화된 방법을 제공합니다. Azure Monitor에서 특정 메트릭 및 임계값에 대한 경고를 설정할 수 있습니다. 워크플로 이벤트를 Log Analytics 작업 영역 또는 Azure 스토리지 계정에 보낼 수도 있습니다. 또는 Azure Event Hubs를 통해 모든 이벤트를 Azure Stream Analytics로 스트림할 수 있습니다. Stream Analytics에서는 진단 로그의 모든 잘못된 부분, 평균 또는 오류를 기반으로 라이브 쿼리를 작성할 수 있습니다. Stream Analytics를 사용하여 큐, 토픽, SQL, Azure Cosmos DB 및 Power BI와 같은 다른 데이터 원본에 정보를 보낼 수 있습니다.
자세한 내용은 Azure Monitor 로그 설정 및 Azure Logic Apps에 대한 진단 데이터 수집을 검토하세요.