이 빠른 시작에는 다음 SDK에 대한 단계가 있습니다.
다음 단계에 사용할 프로그래밍 언어를 선택합니다. Azure.Search.Documents 클라이언트 라이브러리는 .NET, Python, Java 및 JavaScript/Typescript용 Azure SDK에서 사용할 수 있습니다.
Azure.Search.Documents 클라이언트 라이브러리를 사용하여 콘솔 애플리케이션을 빌드하여 검색 인덱스를 만들고 로드하며 쿼리합니다.
또는 소스 코드를 다운로드하여 완성된 프로젝트로 시작하거나 다음 단계를 수행하여 새 프로젝트를 직접 만들 수 있습니다.
환경 설정
Visual Studio를 시작하고 콘솔 앱용 새 프로젝트를 만듭니다.
도구>NuGet 패키지 관리자에서 솔루션의 NuGet 패키지 관리...를 선택합니다.
찾아보기를 선택합니다.
Azure.Search.Documents 패키지를 검색하고 버전 11.0 이상을 선택합니다.
설치를 선택하여 프로젝트 및 솔루션에 어셈블리를 추가합니다.
검색 클라이언트 만들기
Program.cs에서 네임스페이스를 AzureSearch.SDK.Quickstart.v11로 변경하고 다음 using 지시문을 추가합니다.
using Azure;
using Azure.Search.Documents;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Azure.Search.Documents.Models;
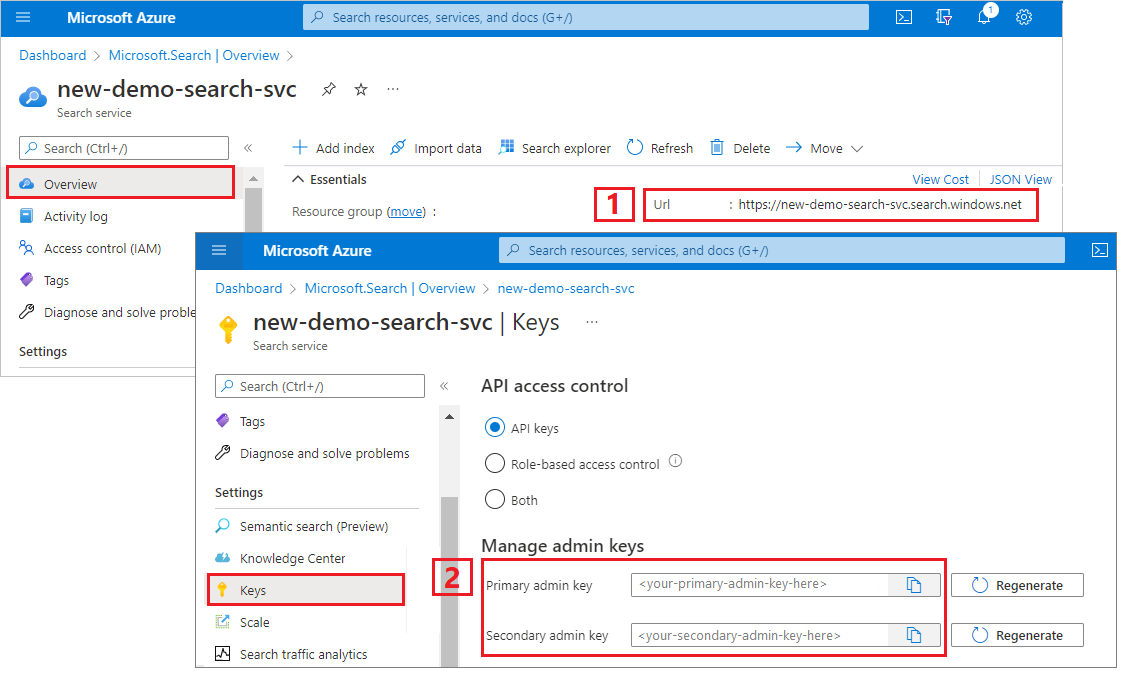
다음 코드를 복사하여 두 개의 클라이언트를 만듭니다. SearchIndexClient는 인덱스를 만들고, SearchClient는 기존 인덱스를 로드하고 쿼리합니다. 둘 다 만들기/삭제 권한 인증을 위한 서비스 엔드포인트와 관리 API 키가 필요합니다.
코드가 URI를 작성하므로 속성에 serviceName 검색 서비스 이름만 지정합니다.
static void Main(string[] args)
{
string serviceName = "<your-search-service-name>";
string apiKey = "<your-search-service-admin-api-key>";
string indexName = "hotels-quickstart";
// Create a SearchIndexClient to send create/delete index commands
Uri serviceEndpoint = new Uri($"https://{serviceName}.search.windows.net/");
AzureKeyCredential credential = new AzureKeyCredential(apiKey);
SearchIndexClient adminClient = new SearchIndexClient(serviceEndpoint, credential);
// Create a SearchClient to load and query documents
SearchClient srchclient = new SearchClient(serviceEndpoint, indexName, credential);
. . .
}
인덱스 만들기
이 빠른 시작에서는 호텔 데이터와 함께 로드하고 쿼리를 실행할 호텔 인덱스를 작성합니다. 이 단계에서는 인덱스의 필드를 정의합니다. 각 필드 정의에는 이름, 데이터 형식 및 필드가 사용되는 방식을 결정하는 특성이 포함됩니다.
이 예제에서는 단순성과 가독성을 위해 Azure.Search.Documents 라이브러리의 동기 메서드를 사용합니다. 그러나 프로덕션 시나리오의 경우 비동기 메서드를 사용하여 앱의 확장성 및 응답성을 유지해야 합니다. 예를 들어 CreateIndex 대신 CreateIndexAsync를 사용해야 합니다.
다음과 같이 프로젝트에 빈 클래스 정의를 추가합니다. Hotel.cs
Hotel.cs에 다음 코드를 복사하여 호텔 문서의 구조를 정의합니다. 필드의 특성은 필드가 애플리케이션에서 사용되는 방식을 결정합니다. 예를 들어 IsFilterable 특성은 필터 식을 지원하는 모든 필드에 할당해야 합니다.
using System;
using System.Text.Json.Serialization;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
namespace AzureSearch.Quickstart
{
public partial class Hotel
{
[SimpleField(IsKey = true, IsFilterable = true)]
public string HotelId { get; set; }
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
[SearchableField(AnalyzerName = LexicalAnalyzerName.Values.EnLucene)]
public string Description { get; set; }
[SearchableField(AnalyzerName = LexicalAnalyzerName.Values.FrLucene)]
[JsonPropertyName("Description_fr")]
public string DescriptionFr { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string Category { get; set; }
[SearchableField(IsFilterable = true, IsFacetable = true)]
public string[] Tags { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public bool? ParkingIncluded { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public DateTimeOffset? LastRenovationDate { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public double? Rating { get; set; }
[SearchableField]
public Address Address { get; set; }
}
}
Azure.Search.Documents 클라이언트 라이브러리에서 SearchableField 및 SimpleField를 사용하여 필드 정의를 간소화할 수 있습니다. 둘 다 SearchField의 파생물이며 잠재적으로 코드를 단순화할 수 있습니다.
SimpleField는 모든 데이터 형식일 수 있으며, 항상 검색할 수 없지만(전체 텍스트 검색 쿼리에서 무시됨) 조회할 수는 있습니다(숨겨지지 않음). 다른 특성은 기본적으로 꺼져 있지만 사용하도록 설정할 수 있습니다. 필터, 패싯 또는 점수 매기기 프로필에만 사용되는 문서 ID 또는 필드에는 SimpleField를 사용할 수 있습니다. 그렇다면 문서 ID에 대한 IsKey = true와 같이 시나리오에 필요한 특성을 적용해야 합니다. 자세한 내용은 소스 코드의 SimpleFieldAttribute.cs를 참조하세요.
SearchableField는 문자열이어야 하며, 항상 검색할 수 있고 조회할 수 있습니다. 다른 특성은 기본적으로 꺼져 있지만 사용하도록 설정할 수 있습니다. 이 필드 형식은 검색할 수 있으므로 동의어와 분석기 속성의 전체 보충을 지원합니다. 자세한 내용은 소스 코드의 SearchableFieldAttribute.cs를 참조하세요.
기본 SearchField API를 사용하든지 도우미 모델 중 하나를 사용하든지 간에 필터, 패싯 및 정렬 특성을 명시적으로 사용하도록 설정해야 합니다. 예를 들어 이전 샘플과 같이 IsFilterable, IsSortable 및 IsFacetable 은 명시적으로 특성을 지정해야 합니다.
두 번째 빈 클래스 정의를 프로젝트에 추가합니다. Address.cs. 다음 코드를 클래스에 복사합니다.
using Azure.Search.Documents.Indexes;
namespace AzureSearch.Quickstart
{
public partial class Address
{
[SearchableField(IsFilterable = true)]
public string StreetAddress { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string City { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string StateProvince { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string PostalCode { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string Country { get; set; }
}
}
재정의에 대한 Hotel.Methods.cs 및 Address.Methods.cs 두 개의 클래스를 ToString() 더 만듭니다. 이러한 클래스는 콘솔 출력에서 검색 결과를 렌더링하는 데 사용됩니다. 이러한 클래스의 콘텐츠는 이 문서에서 제공되지 않지만 GitHub의 파일에서 코드를 복사할 수 있습니다.
Program.cs에서 SearchIndex 개체를 만든 다음, CreateIndex 메서드를 호출하여 검색 서비스에서 인덱스를 표시합니다. 인덱스에는 지정된 필드에서 자동 완성을 사용하도록 설정하는 SearchSuggester도 포함되어 있습니다.
// Create hotels-quickstart index
private static void CreateIndex(string indexName, SearchIndexClient adminClient)
{
FieldBuilder fieldBuilder = new FieldBuilder();
var searchFields = fieldBuilder.Build(typeof(Hotel));
var definition = new SearchIndex(indexName, searchFields);
var suggester = new SearchSuggester("sg", new[] { "HotelName", "Category", "Address/City", "Address/StateProvince" });
definition.Suggesters.Add(suggester);
adminClient.CreateOrUpdateIndex(definition);
}
문서 로드
Azure AI 검색은 서비스에 저장된 콘텐츠를 검색합니다. 이 단계에서는 방금 만든 호텔 인덱스를 따르는 JSON 문서를 로드합니다.
Azure AI 검색에서 검색 문서는 인덱싱에 대한 입력과 쿼리의 출력 모두에 해당하는 데이터 구조입니다. 외부 데이터 소스에서 가져온, 문서 입력은 데이터베이스의 행, Blob Storage의 Blob 또는 디스크의 JSON 문서일 수 있습니다. 이 예에서는 손쉬운 방법을 사용하여 4개 호텔에 대한 JSON 문서를 코드 자체에 포함합니다.
문서를 업로드할 때 IndexDocumentsBatch 개체를 사용해야 합니다. IndexDocumentsBatch 개체에는 Actions 컬렉션이 포함되며 컬렉션마다 수행할 작업(upload, merge, delete 및 mergeOrUpload)을 Azure AI 검색에 알려주는 속성과 문서가 포함됩니다.
Program.cs에서 문서 및 인덱스 작업의 배열을 만든 다음, 배열을 IndexDocumentsBatch에 전달합니다. 다음 문서는 호텔 클래스에서 정의한 대로 호텔 빠른 시작 인덱스(호텔 빠른 시작 인덱스)를 준수합니다.
// Upload documents in a single Upload request.
private static void UploadDocuments(SearchClient searchClient)
{
IndexDocumentsBatch<Hotel> batch = IndexDocumentsBatch.Create(
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "1",
HotelName = "Stay-Kay City Hotel",
Description = "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
DescriptionFr = "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
Category = "Boutique",
Tags = new[] { "pool", "air conditioning", "concierge" },
ParkingIncluded = false,
LastRenovationDate = new DateTimeOffset(1970, 1, 18, 0, 0, 0, TimeSpan.Zero),
Rating = 3.6,
Address = new Address()
{
StreetAddress = "677 5th Ave",
City = "New York",
StateProvince = "NY",
PostalCode = "10022",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "2",
HotelName = "Old Century Hotel",
Description = "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
DescriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
Category = "Boutique",
Tags = new[] { "pool", "free wifi", "concierge" },
ParkingIncluded = false,
LastRenovationDate = new DateTimeOffset(1979, 2, 18, 0, 0, 0, TimeSpan.Zero),
Rating = 3.60,
Address = new Address()
{
StreetAddress = "140 University Town Center Dr",
City = "Sarasota",
StateProvince = "FL",
PostalCode = "34243",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "3",
HotelName = "Gastronomic Landscape Hotel",
Description = "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
DescriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
Category = "Resort and Spa",
Tags = new[] { "air conditioning", "bar", "continental breakfast" },
ParkingIncluded = true,
LastRenovationDate = new DateTimeOffset(2015, 9, 20, 0, 0, 0, TimeSpan.Zero),
Rating = 4.80,
Address = new Address()
{
StreetAddress = "3393 Peachtree Rd",
City = "Atlanta",
StateProvince = "GA",
PostalCode = "30326",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "4",
HotelName = "Sublime Palace Hotel",
Description = "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
DescriptionFr = "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
Category = "Boutique",
Tags = new[] { "concierge", "view", "24-hour front desk service" },
ParkingIncluded = true,
LastRenovationDate = new DateTimeOffset(1960, 2, 06, 0, 0, 0, TimeSpan.Zero),
Rating = 4.60,
Address = new Address()
{
StreetAddress = "7400 San Pedro Ave",
City = "San Antonio",
StateProvince = "TX",
PostalCode = "78216",
Country = "USA"
}
})
);
try
{
IndexDocumentsResult result = searchClient.IndexDocuments(batch);
}
catch (Exception)
{
// If for some reason any documents are dropped during indexing, you can compensate by delaying and
// retrying. This simple demo just logs the failed document keys and continues.
Console.WriteLine("Failed to index some of the documents: {0}");
}
}
IndexDocumentsBatch 개체를 초기화 한 후에는 SearchClient 개체에서 IndexDocuments를 호출하여 이 개체를 인덱스에 전송할 수 있습니다.
Main()에 다음 줄을 추가합니다. 문서 로드는 SearchClient를 사용하여 수행되지만 작업에는 일반적으로 SearchIndexClient와 관련된 서비스에 대한 관리자 권한도 있어야 합니다. 이 작업을 설정하는 한 가지 방법은 SearchClient를 통해 SearchIndexClient 가져오는 것입니다(adminClient 이 예제에서는).
SearchClient ingesterClient = adminClient.GetSearchClient(indexName);
// Load documents
Console.WriteLine("{0}", "Uploading documents...\n");
UploadDocuments(ingesterClient);
이 앱은 모든 명령을 순차적으로 실행하는 콘솔 앱이므로 인덱싱과 쿼리 사이에 2초 대기 시간을 추가합니다.
// Wait 2 seconds for indexing to complete before starting queries (for demo and console-app purposes only)
Console.WriteLine("Waiting for indexing...\n");
System.Threading.Thread.Sleep(2000);
2초 지연은 비동기식 인덱싱을 보정합니다. 따라서 쿼리가 실행되기 전에 모든 문서를 인덱싱할 수 있습니다. 지연 시 코딩은 일반적으로 데모, 테스트, 샘플 애플리케이션에서만 필요합니다.
인덱스 검색
첫 번째 문서의 인덱싱이 완료되는 즉시 쿼리 결과를 얻을 수 있지만 인덱스에 대한 실제 테스트는 모든 문서의 인덱싱이 완료될 때까지 기다려야 합니다.
이 섹션에서는 쿼리 논리 및 결과라는 두 가지 기능을 추가합니다. 쿼리에는 Search 메서드를 사용합니다. 이 메서드는 검색 텍스트(쿼리 문자열)뿐 아니라 다른 옵션을 사용합니다.
SearchResults 클래스는 결과를 나타냅니다.
Program.cs 검색 결과를 콘솔에 출력하는 메서드를 만듭니 WriteDocuments 다.
// Write search results to console
private static void WriteDocuments(SearchResults<Hotel> searchResults)
{
foreach (SearchResult<Hotel> result in searchResults.GetResults())
{
Console.WriteLine(result.Document);
}
Console.WriteLine();
}
private static void WriteDocuments(AutocompleteResults autoResults)
{
foreach (AutocompleteItem result in autoResults.Results)
{
Console.WriteLine(result.Text);
}
Console.WriteLine();
}
쿼리를 실행하고 결과를 반환하는 RunQueries 메서드를 만듭니다. 결과는 Hotel 개체입니다. 이 샘플에서는 메서드 서명과 첫 번째 쿼리를 보여줍니다. 이 쿼리는 문서에서 선택한 필드를 사용하여 결과를 작성할 수 있도록 하는 Select 매개 변수를 보여줍니다.
// Run queries, use WriteDocuments to print output
private static void RunQueries(SearchClient srchclient)
{
SearchOptions options;
SearchResults<Hotel> response;
// Query 1
Console.WriteLine("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n");
options = new SearchOptions()
{
IncludeTotalCount = true,
Filter = "",
OrderBy = { "" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Address/City");
response = srchclient.Search<Hotel>("*", options);
WriteDocuments(response);
두 번째 쿼리에서 용어를 검색하고 등급이 4보다 큰 문서를 선택하는 필터를 추가한 다음 등급별로 내림차순으로 정렬합니다. 필터는 인덱스의 IsFilterable 필드를 통해 평가되는 부울 식입니다. 필터는 포함 또는 제외 값을 쿼리합니다. 따라서 필터 쿼리와 관련된 관련성 점수가 없습니다.
// Query 2
Console.WriteLine("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n");
options = new SearchOptions()
{
Filter = "Rating gt 4",
OrderBy = { "Rating desc" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Rating");
response = srchclient.Search<Hotel>("hotels", options);
WriteDocuments(response);
세 번째 쿼리는 전체 텍스트 검색 작업의 범위를 특정 필드로 지정하는 데 사용되는 searchFields를 보여 줍니다.
// Query 3
Console.WriteLine("Query #3: Limit search to specific fields (pool in Tags field)...\n");
options = new SearchOptions()
{
SearchFields = { "Tags" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Tags");
response = srchclient.Search<Hotel>("pool", options);
WriteDocuments(response);
네 번째 쿼리는 facets패싯 탐색 구조를 구성하는 데 사용할 수 있는 방법을 보여 줍니다.
// Query 4
Console.WriteLine("Query #4: Facet on 'Category'...\n");
options = new SearchOptions()
{
Filter = ""
};
options.Facets.Add("Category");
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Category");
response = srchclient.Search<Hotel>("*", options);
WriteDocuments(response);
다섯 번째 쿼리에서 특정 문서를 반환합니다. 문서 조회는 결과 집합의 이벤트에 대한 일반적인 응답 OnClick 입니다.
// Query 5
Console.WriteLine("Query #5: Look up a specific document...\n");
Response<Hotel> lookupResponse;
lookupResponse = srchclient.GetDocument<Hotel>("3");
Console.WriteLine(lookupResponse.Value.HotelId);
마지막 쿼리는 자동 완성 구문을 보여 줍니다. 이 구문은 인덱스에 정의한 제안기와 연결된 sourceFields에서 가능한 두 일치 항목으로 확인되는 sa의 부분 사용자 입력을 시뮬레이트합니다.
// Query 6
Console.WriteLine("Query #6: Call Autocomplete on HotelName that starts with 'sa'...\n");
var autoresponse = srchclient.Autocomplete("sa", "sg");
WriteDocuments(autoresponse);
RunQueries를 Main()에 추가합니다.
// Call the RunQueries method to invoke a series of queries
Console.WriteLine("Starting queries...\n");
RunQueries(srchclient);
// End the program
Console.WriteLine("{0}", "Complete. Press any key to end this program...\n");
Console.ReadKey();
이전 쿼리는 전체 텍스트 검색, 필터 및 자동 완성과 같은 쿼리에서 용어를 일치시키는 여러 방법을 보여줍니다.
전체 텍스트 검색 및 필터는 SearchClient.Search 메서드를 사용하여 수행됩니다. 검색 쿼리는 searchText 문자열로 전달할 수 있는 반면, 필터 식은 SearchOptions 클래스의 Filter 속성으로 전달할 수 있습니다. 검색하지 않고 필터링하려면 Search 메서드의 searchText 매개 변수에 대한 "*"를 전달합니다. 필터링하지 않고 검색하려면 Filter 속성을 설정하지 않고 그대로 두거나 SearchOptions 인스턴스에 전달하지 않아야 합니다.
프로그램 실행
F5 키를 눌러 앱을 다시 빌드하고 프로그램을 완전히 실행합니다.
출력에는 쿼리 정보 및 결과가 추가된 Console.WriteLine의 메시지가 포함됩니다.
Python용 Azure SDK의 Jupyter Notebook 및 azure-search-documents 라이브러리를 사용하여 검색 인덱스 만들기, 로드 및 쿼리를 할 수 있습니다.
또는 완성된 전자 필기장을 다운로드하고 실행할 수 있습니다.
환경 설정
Python 3.10 이상에서 Python 확장 또는 동등한 IDE와 함께 Visual Studio Code를 사용합니다.
이 빠른 시작에서는 가상 환경을 사용하는 것이 좋습니다.
Visual Studio Code 시작
명령 팔레트를 엽니다(Ctrl+Shift+P).
Python: 환경 만들기를 검색합니다.
Venv. 선택
Python 인터프리터를 선택합니다. 버전 3.10 이상을 선택합니다.
설정하는 데 1분 정도 걸릴 수 있습니다. 문제가 발생하면 VS Code의 Python 환경을 참조하세요.
패키지 설치 및 변수 설정
azure-search-documents를 포함한 패키지를 설치합니다.
! pip install azure-search-documents==11.6.0b1 --quiet
! pip install azure-identity --quiet
! pip install python-dotenv --quiet
서비스에 대한 엔드포인트 및 API 키를 제공합니다.
search_endpoint: str = "PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE"
search_api_key: str = "PUT-YOUR-SEARCH-SERVICE-ADMIN-API-KEY-HERE"
index_name: str = "hotels-quickstart"
인덱스 만들기
from azure.core.credentials import AzureKeyCredential
credential = AzureKeyCredential(search_api_key)
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents import SearchClient
from azure.search.documents.indexes.models import (
ComplexField,
SimpleField,
SearchFieldDataType,
SearchableField,
SearchIndex
)
# Create a search schema
index_client = SearchIndexClient(
endpoint=search_endpoint, credential=credential)
fields = [
SimpleField(name="HotelId", type=SearchFieldDataType.String, key=True),
SearchableField(name="HotelName", type=SearchFieldDataType.String, sortable=True),
SearchableField(name="Description", type=SearchFieldDataType.String, analyzer_name="en.lucene"),
SearchableField(name="Description_fr", type=SearchFieldDataType.String, analyzer_name="fr.lucene"),
SearchableField(name="Category", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="Tags", collection=True, type=SearchFieldDataType.String, facetable=True, filterable=True),
SimpleField(name="ParkingIncluded", type=SearchFieldDataType.Boolean, facetable=True, filterable=True, sortable=True),
SimpleField(name="LastRenovationDate", type=SearchFieldDataType.DateTimeOffset, facetable=True, filterable=True, sortable=True),
SimpleField(name="Rating", type=SearchFieldDataType.Double, facetable=True, filterable=True, sortable=True),
ComplexField(name="Address", fields=[
SearchableField(name="StreetAddress", type=SearchFieldDataType.String),
SearchableField(name="City", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="StateProvince", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="PostalCode", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="Country", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
])
]
scoring_profiles = []
suggester = [{'name': 'sg', 'source_fields': ['Tags', 'Address/City', 'Address/Country']}]
# Create the search index
index = SearchIndex(name=index_name, fields=fields, suggesters=suggester, scoring_profiles=scoring_profiles)
result = index_client.create_or_update_index(index)
print(f' {result.name} created')
문서 페이로드 만들기
업로드 또는 병합 및 업로드와 같은 작업 유형에 대한 인덱스 작업을 사용합니다. 문서는 GitHub의 HotelsData 샘플에서 시작됩니다.
# Create a documents payload
documents = [
{
"@search.action": "upload",
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": [ "pool", "air conditioning", "concierge" ],
"ParkingIncluded": "false",
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.60,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "2",
"HotelName": "Old Century Hotel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": [ "pool", "free wifi", "concierge" ],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.60,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "3",
"HotelName": "Gastronomic Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel's restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": [ "air conditioning", "bar", "continental breakfast" ],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.80,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "4",
"HotelName": "Sublime Palace Hotel",
"Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
"Description_fr": "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": [ "concierge", "view", "24-hour front desk service" ],
"ParkingIncluded": "true",
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.60,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216",
"Country": "USA"
}
}
]
문서 업로드
# Upload documents to the index
search_client = SearchClient(endpoint=search_endpoint,
index_name=index_name,
credential=credential)
try:
result = search_client.upload_documents(documents=documents)
print("Upload of new document succeeded: {}".format(result[0].succeeded))
except Exception as ex:
print (ex.message)
index_client = SearchIndexClient(
endpoint=search_endpoint, credential=credential)
첫 번째 쿼리 실행
search.client 클래스의 search 메서드를 사용합니다.
이 예제는 빈 검색(search=*)을 실행하여 순위가 없는 임의 문서 목록(검색 점수 = 1.0)을 반환합니다. 조건이 없으므로 모든 문서가 결과에 포함됩니다.
# Run an empty query (returns selected fields, all documents)
results = search_client.search(query_type='simple',
search_text="*" ,
select='HotelName,Description',
include_total_count=True)
print ('Total Documents Matching Query:', results.get_count())
for result in results:
print(result["@search.score"])
print(result["HotelName"])
print(f"Description: {result['Description']}")
용어 쿼리 실행
다음 쿼리는 전체 용어를 검색 식("wifi")에 추가합니다. 이 쿼리는 select 문의 해당 필드만 결과에 포함되도록 지정합니다. 반환되는 필드를 제한하면 유선을 통해 다시 보내지는 데이터의 양이 최소화되고 검색 대기 시간이 줄어듭니다.
results = search_client.search(query_type='simple',
search_text="wifi" ,
select='HotelName,Description,Tags',
include_total_count=True)
print ('Total Documents Matching Query:', results.get_count())
for result in results:
print(result["@search.score"])
print(result["HotelName"])
print(f"Description: {result['Description']}")
필터 추가
내림차순으로 정렬된 등급이 4보다 큰 호텔만 반환하는 필터 식을 추가합니다.
# Add a filter
results = search_client.search(
search_text="hotels",
select='HotelId,HotelName,Rating',
filter='Rating gt 4',
order_by='Rating desc')
for result in results:
print("{}: {} - {} rating".format(result["HotelId"], result["HotelName"], result["Rating"]))
필드 범위 지정 추가
search_fields을(를) 추가하여 쿼리 실행 범위를 특정 필드로 지정합니다.
# Add search_fields to scope query matching to the HotelName field
results = search_client.search(
search_text="sublime",
search_fields=['HotelName'],
select='HotelId,HotelName')
for result in results:
print("{}: {}".format(result["HotelId"], result["HotelName"]))
패싯 추가
패싯은 검색 결과에서 찾은 양수 일치에 대해 생성됩니다. 일치하는 항목이 0개도 없습니다. 검색 결과에 wifi라는 용어가 포함되어 있지 않으면 패싯 탐색 구조에 wifi가 나타나지 않습니다.
# Return facets
results = search_client.search(search_text="*", facets=["Category"])
facets = results.get_facets()
for facet in facets["Category"]:
print(" {}".format(facet))
문서 조회
키에 따라 문서를 반환합니다. 이 작업은 사용자가 검색 결과에서 항목을 선택할 때 드릴스루를 제공하려는 경우에 유용합니다.
# Look up a specific document by ID
result = search_client.get_document(key="3")
print("Details for hotel '3' are:")
print("Name: {}".format(result["HotelName"]))
print("Rating: {}".format(result["Rating"]))
print("Category: {}".format(result["Category"]))
자동 완성 추가
자동 완성은 검색 상자에 사용자 유형으로 잠재적 일치 항목을 제공할 수 있습니다.
자동 완성은 제안기(sg)를 사용하여 제안기 요청에 대한 잠재적 일치 항목이 포함된 필드를 파악합니다. 이 빠른 시작에서는 이러한 필드가 Tags, Address/City, Address/Country입니다.
자동 완성을 시뮬레이션하려면 sa 문자를 부분 문자열로 전달합니다. SearchClient의 자동 완성 메서드는 잠재적으로 일치하는 용어 항목을 다시 보냅니다.
# Autocomplete a query
search_suggestion = 'sa'
results = search_client.autocomplete(
search_text=search_suggestion,
suggester_name="sg",
mode='twoTerms')
print("Autocomplete for:", search_suggestion)
for result in results:
print (result['text'])
Azure.Search.Documents 라이브러리를 사용하여 Java 콘솔 애플리케이션을 빌드하여 검색 인덱스를 만들고 로드하며 쿼리합니다.
또는 소스 코드를 다운로드하여 완성된 프로젝트로 시작하거나 다음 단계를 수행하여 새 프로젝트를 직접 만들 수 있습니다.
환경 설정
다음 도구를 사용하여 이 빠른 시작을 만듭니다.
프로젝트 만들기
Visual Studio Code 시작
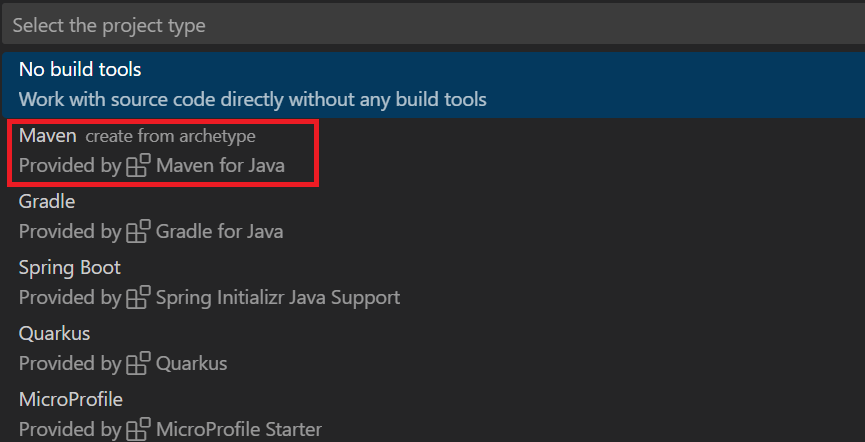
Ctrl+Shift+P를 사용하여 명령 팔레트를 엽니다. Java 프로젝트 만들기를 검색합니다.

Maven을 선택합니다.
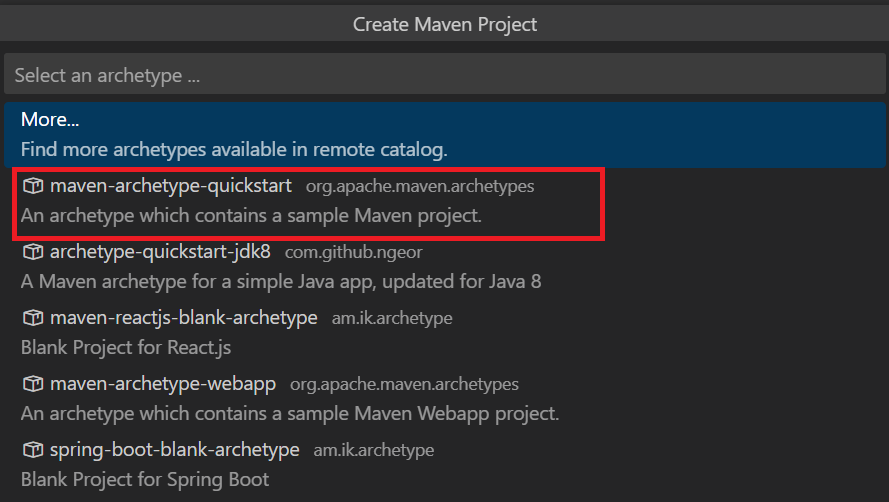
maven-archetype-quickstart를 선택합니다.
최신 버전(현재 1.4)을 선택합니다.

그룹 ID로 azure.search.sample을 입력합니다.
아티팩트 ID로 azuresearchquickstart를 입력합니다.

프로젝트를 만들 폴더를 선택합니다.
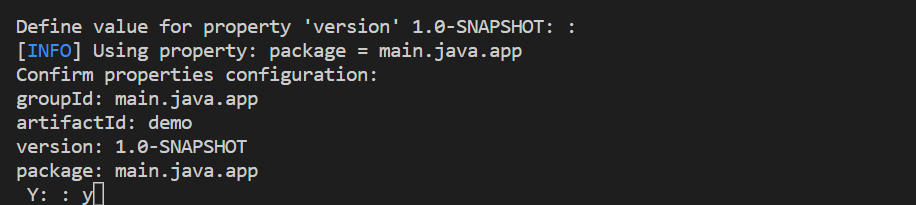
통합 터미널에서 프로젝트 만들기를 완료합니다. Enter 키를 눌러 "1.0-SNAPSHOT"의 기본값을 적용한 다음, "y"를 입력하여 프로젝트의 속성을 확인합니다.
프로젝트를 만든 폴더를 엽니다.
Maven 종속성 지정
pom.xml 파일을 열고 다음 종속성을 추가합니다.
<dependencies>
<dependency>
<groupId>com.azure</groupId>
<artifactId>azure-search-documents</artifactId>
<version>11.7.3</version>
</dependency>
<dependency>
<groupId>com.azure</groupId>
<artifactId>azure-core</artifactId>
<version>1.53.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
컴파일러 Java 버전을 11로 변경합니다.
<maven.compiler.source>1.11</maven.compiler.source>
<maven.compiler.target>1.11</maven.compiler.target>
검색 클라이언트 만들기
src, main, java, azure, search, sample 아래에서 App 클래스를 엽니다. 다음 가져오기 지시문을 추가합니다.
import java.util.Arrays;
import java.util.ArrayList;
import java.time.OffsetDateTime;
import java.time.ZoneOffset;
import java.time.LocalDateTime;
import java.time.LocalDate;
import java.time.LocalTime;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.Context;
import com.azure.search.documents.SearchClient;
import com.azure.search.documents.SearchClientBuilder;
import com.azure.search.documents.models.SearchOptions;
import com.azure.search.documents.indexes.SearchIndexClient;
import com.azure.search.documents.indexes.SearchIndexClientBuilder;
import com.azure.search.documents.indexes.models.IndexDocumentsBatch;
import com.azure.search.documents.indexes.models.SearchIndex;
import com.azure.search.documents.indexes.models.SearchSuggester;
import com.azure.search.documents.util.AutocompletePagedIterable;
import com.azure.search.documents.util.SearchPagedIterable;
다음 예제에는 검색 서비스 이름에 대한 자리 표시자, 만들기 및 삭제 권한을 부여하는 관리자 API 키, 인덱스 이름이 포함됩니다. 세 자리 표시자를 유효한 값을 대체합니다. 두 개의 클라이언트를 만듭니다. SearchIndexClient는 인덱스를 만들고, SearchClient는 기존 인덱스를 로드하고 쿼리합니다. 둘 다 만들기 및 삭제 권한 인증을 위한 서비스 엔드포인트와 관리 API 키가 필요합니다.
public static void main(String[] args) {
var searchServiceEndpoint = "<YOUR-SEARCH-SERVICE-URL>";
var adminKey = new AzureKeyCredential("<YOUR-SEARCH-SERVICE-ADMIN-KEY>");
String indexName = "<YOUR-SEARCH-INDEX-NAME>";
SearchIndexClient searchIndexClient = new SearchIndexClientBuilder()
.endpoint(searchServiceEndpoint)
.credential(adminKey)
.buildClient();
SearchClient searchClient = new SearchClientBuilder()
.endpoint(searchServiceEndpoint)
.credential(adminKey)
.indexName(indexName)
.buildClient();
}
인덱스 만들기
이 빠른 시작에서는 호텔 데이터와 함께 로드하고 쿼리를 실행할 호텔 인덱스를 작성합니다. 이 단계에서는 인덱스의 필드를 정의합니다. 각 필드 정의에는 이름, 데이터 형식 및 필드가 사용되는 방식을 결정하는 특성이 포함됩니다.
이 예제에서는 간단한 설명과 가독성을 위해 azure-search-documents 라이브러리의 동기 메서드를 사용합니다. 그러나 프로덕션 시나리오의 경우 비동기 메서드를 사용하여 앱의 확장성 및 응답성을 유지해야 합니다. 예를 들어 SearchClient 대신 SearchAsyncClient를 사용합니다.
프로젝트에 빈 클래스 정의를 추가합니다. Hotel.java
다음 코드를 Hotel.java 복사하여 호텔 문서의 구조를 정의합니다. 필드의 특성은 필드가 애플리케이션에서 사용되는 방식을 결정합니다. 예를 들어 IsFilterable 주석을 필터 식을 지원하는 모든 필드에 할당해야 합니다.
// Copyright (c) Microsoft Corporation. All rights reserved.
// Licensed under the MIT License.
package azure.search.sample;
import com.azure.search.documents.indexes.SearchableField;
import com.azure.search.documents.indexes.SimpleField;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonProperty;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import java.time.OffsetDateTime;
/**
* Model class representing a hotel.
*/
@JsonInclude(Include.NON_NULL)
public class Hotel {
/**
* Hotel ID
*/
@JsonProperty("HotelId")
@SimpleField(isKey = true)
public String hotelId;
/**
* Hotel name
*/
@JsonProperty("HotelName")
@SearchableField(isSortable = true)
public String hotelName;
/**
* Description
*/
@JsonProperty("Description")
@SearchableField(analyzerName = "en.microsoft")
public String description;
/**
* French description
*/
@JsonProperty("DescriptionFr")
@SearchableField(analyzerName = "fr.lucene")
public String descriptionFr;
/**
* Category
*/
@JsonProperty("Category")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String category;
/**
* Tags
*/
@JsonProperty("Tags")
@SearchableField(isFilterable = true, isFacetable = true)
public String[] tags;
/**
* Whether parking is included
*/
@JsonProperty("ParkingIncluded")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public Boolean parkingIncluded;
/**
* Last renovation time
*/
@JsonProperty("LastRenovationDate")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public OffsetDateTime lastRenovationDate;
/**
* Rating
*/
@JsonProperty("Rating")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public Double rating;
/**
* Address
*/
@JsonProperty("Address")
public Address address;
@Override
public String toString()
{
try
{
return new ObjectMapper().writeValueAsString(this);
}
catch (JsonProcessingException e)
{
e.printStackTrace();
return "";
}
}
}
Azure.Search.Documents 클라이언트 라이브러리에서 SearchableField 및 SimpleField를 사용하여 필드 정의를 간소화할 수 있습니다.
SimpleField는 모든 데이터 형식일 수 있으며, 항상 검색할 수 없지만(전체 텍스트 검색 쿼리에서 무시됨) 조회할 수는 있습니다(숨겨지지 않음). 다른 특성은 기본적으로 꺼져 있지만 사용하도록 설정할 수 있습니다. 필터, 패싯 또는 점수 매기기 프로필에만 사용되는 문서 ID 또는 필드에는 SimpleField를 사용할 수 있습니다. 그렇다면 문서 ID에 대한 IsKey = true와 같이 시나리오에 필요한 특성을 적용해야 합니다.SearchableField는 문자열이어야 하며, 항상 검색할 수 있고 조회할 수 있습니다. 다른 특성은 기본적으로 꺼져 있지만 사용하도록 설정할 수 있습니다. 이 필드 형식은 검색할 수 있으므로 동의어와 분석기 속성의 전체 보충을 지원합니다.
기본 SearchField API를 사용하든지 도우미 모델 중 하나를 사용하든지 간에 필터, 패싯 및 정렬 특성을 명시적으로 사용하도록 설정해야 합니다. 예를 들어 isFilterable이전 isSortable샘플과 isFacetable 같이 명시적으로 특성을 지정해야 합니다.
프로젝트에 Address.java두 번째 빈 클래스 정의를 추가합니다. 다음 코드를 클래스에 복사합니다.
// Copyright (c) Microsoft Corporation. All rights reserved.
// Licensed under the MIT License.
package azure.search.sample;
import com.azure.search.documents.indexes.SearchableField;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonProperty;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
/**
* Model class representing an address.
*/
@JsonInclude(Include.NON_NULL)
public class Address {
/**
* Street address
*/
@JsonProperty("StreetAddress")
@SearchableField
public String streetAddress;
/**
* City
*/
@JsonProperty("City")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String city;
/**
* State or province
*/
@JsonProperty("StateProvince")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String stateProvince;
/**
* Postal code
*/
@JsonProperty("PostalCode")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String postalCode;
/**
* Country
*/
@JsonProperty("Country")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String country;
}
에서 App.java메서드에서 개체를 SearchIndex main 만든 다음 메서드를 createOrUpdateIndex 호출하여 검색 서비스에서 인덱스 만들기 인덱스에는 지정된 필드에서 자동 완성을 사용하도록 설정하는 SearchSuggester도 포함되어 있습니다.
// Create Search Index for Hotel model
searchIndexClient.createOrUpdateIndex(
new SearchIndex(indexName, SearchIndexClient.buildSearchFields(Hotel.class, null))
.setSuggesters(new SearchSuggester("sg", Arrays.asList("HotelName"))));
문서 로드
Azure AI 검색은 서비스에 저장된 콘텐츠를 검색합니다. 이 단계에서는 방금 만든 호텔 인덱스를 따르는 JSON 문서를 로드합니다.
Azure AI 검색에서 검색 문서는 인덱싱에 대한 입력과 쿼리의 출력 모두에 해당하는 데이터 구조입니다. 외부 데이터 소스에서 가져온, 문서 입력은 데이터베이스의 행, Blob Storage의 Blob 또는 디스크의 JSON 문서일 수 있습니다. 이 예에서는 손쉬운 방법을 사용하여 4개 호텔에 대한 JSON 문서를 코드 자체에 포함합니다.
문서를 업로드할 때 IndexDocumentsBatch 개체를 사용해야 합니다. IndexDocumentsBatch 개체에는 IndexActions 컬렉션이 포함되며 컬렉션마다 수행할 작업(upload, merge, delete 및 mergeOrUpload)을 Azure AI 검색에 알려주는 속성과 문서가 포함됩니다.
에서 App.java문서 및 인덱스 작업을 만든 다음 에 전달합니다 IndexDocumentsBatch. 다음 문서는 호텔 클래스에서 정의한 대로 호텔 빠른 시작 인덱스(호텔 빠른 시작 인덱스)를 준수합니다.
// Upload documents in a single Upload request.
private static void uploadDocuments(SearchClient searchClient)
{
var hotelList = new ArrayList<Hotel>();
var hotel = new Hotel();
hotel.hotelId = "1";
hotel.hotelName = "Stay-Kay City Hotel";
hotel.description = "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.";
hotel.descriptionFr = "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.";
hotel.category = "Boutique";
hotel.tags = new String[] { "pool", "air conditioning", "concierge" };
hotel.parkingIncluded = false;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1970, 1, 18), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 3.6;
hotel.address = new Address();
hotel.address.streetAddress = "677 5th Ave";
hotel.address.city = "New York";
hotel.address.stateProvince = "NY";
hotel.address.postalCode = "10022";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "2";
hotel.hotelName = "Old Century Hotel";
hotel.description = "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.";
hotel.descriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.";
hotel.category = "Boutique";
hotel.tags = new String[] { "pool", "free wifi", "concierge" };
hotel.parkingIncluded = false;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1979, 2, 18), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 3.60;
hotel.address = new Address();
hotel.address.streetAddress = "140 University Town Center Dr";
hotel.address.city = "Sarasota";
hotel.address.stateProvince = "FL";
hotel.address.postalCode = "34243";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "3";
hotel.hotelName = "Gastronomic Landscape Hotel";
hotel.description = "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.";
hotel.descriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.";
hotel.category = "Resort and Spa";
hotel.tags = new String[] { "air conditioning", "bar", "continental breakfast" };
hotel.parkingIncluded = true;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(2015, 9, 20), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 4.80;
hotel.address = new Address();
hotel.address.streetAddress = "3393 Peachtree Rd";
hotel.address.city = "Atlanta";
hotel.address.stateProvince = "GA";
hotel.address.postalCode = "30326";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "4";
hotel.hotelName = "Sublime Palace Hotel";
hotel.description = "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.";
hotel.descriptionFr = "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.";
hotel.category = "Boutique";
hotel.tags = new String[] { "concierge", "view", "24-hour front desk service" };
hotel.parkingIncluded = true;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1960, 2, 06), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 4.60;
hotel.address = new Address();
hotel.address.streetAddress = "7400 San Pedro Ave";
hotel.address.city = "San Antonio";
hotel.address.stateProvince = "TX";
hotel.address.postalCode = "78216";
hotel.address.country = "USA";
hotelList.add(hotel);
var batch = new IndexDocumentsBatch<Hotel>();
batch.addMergeOrUploadActions(hotelList);
try
{
searchClient.indexDocuments(batch);
}
catch (Exception e)
{
e.printStackTrace();
// If for some reason any documents are dropped during indexing, you can compensate by delaying and
// retrying. This simple demo just logs failure and continues
System.err.println("Failed to index some of the documents");
}
}
IndexDocumentsBatch 개체를 초기화하면 SearchClient 개체에서 indexDocuments를 호출하여 인덱스로 보낼 수 있습니다.
Main()에 다음 줄을 추가합니다. 문서를 로드하는 작업은 SearchClient를 사용하여 수행됩니다.
// Upload sample hotel documents to the Search Index
uploadDocuments(searchClient);
이 앱은 모든 명령을 순차적으로 실행하는 콘솔 앱이므로 인덱싱과 쿼리 사이에 2초 대기 시간을 추가합니다.
// Wait 2 seconds for indexing to complete before starting queries (for demo and console-app purposes only)
System.out.println("Waiting for indexing...\n");
try
{
Thread.sleep(2000);
}
catch (InterruptedException e)
{
}
2초 지연은 비동기식 인덱싱을 보정합니다. 따라서 쿼리가 실행되기 전에 모든 문서를 인덱싱할 수 있습니다. 지연 시 코딩은 일반적으로 데모, 테스트, 샘플 애플리케이션에서만 필요합니다.
인덱스 검색
첫 번째 문서의 인덱싱이 완료되는 즉시 쿼리 결과를 얻을 수 있지만 인덱스에 대한 실제 테스트는 모든 문서의 인덱싱이 완료될 때까지 기다려야 합니다.
이 섹션에서는 쿼리 논리 및 결과라는 두 가지 기능을 추가합니다. 쿼리에는 Search 메서드를 사용합니다. 이 메서드는 검색 텍스트(쿼리 문자열)뿐 아니라 다른 옵션을 사용합니다.
에서 App.java검색 결과를 콘솔에 출력하는 메서드를 만듭니 WriteDocuments 다.
// Write search results to console
private static void WriteSearchResults(SearchPagedIterable searchResults)
{
searchResults.iterator().forEachRemaining(result ->
{
Hotel hotel = result.getDocument(Hotel.class);
System.out.println(hotel);
});
System.out.println();
}
// Write autocomplete results to console
private static void WriteAutocompleteResults(AutocompletePagedIterable autocompleteResults)
{
autocompleteResults.iterator().forEachRemaining(result ->
{
String text = result.getText();
System.out.println(text);
});
System.out.println();
}
쿼리를 실행하고 결과를 반환하는 RunQueries 메서드를 만듭니다. 결과는 Hotel 개체입니다. 이 샘플에서는 메서드 서명과 첫 번째 쿼리를 보여줍니다. 이 쿼리는 문서에서 선택한 필드를 사용하여 결과를 작성할 수 있도록 하는 Select 매개 변수를 보여 줍니다.
// Run queries, use WriteDocuments to print output
private static void RunQueries(SearchClient searchClient)
{
// Query 1
System.out.println("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n");
SearchOptions options = new SearchOptions();
options.setIncludeTotalCount(true);
options.setFilter("");
options.setOrderBy("");
options.setSelect("HotelId", "HotelName", "Address/City");
WriteSearchResults(searchClient.search("*", options, Context.NONE));
}
두 번째 쿼리에서 용어를 검색하고 등급이 4보다 큰 문서를 선택하는 필터를 추가한 다음 등급별로 내림차순으로 정렬합니다. 필터는 인덱스의 isFilterable 필드를 통해 평가되는 부울 식입니다. 필터는 포함 또는 제외 값을 쿼리합니다. 따라서 필터 쿼리와 관련된 관련성 점수가 없습니다.
// Query 2
System.out.println("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n");
options = new SearchOptions();
options.setFilter("Rating gt 4");
options.setOrderBy("Rating desc");
options.setSelect("HotelId", "HotelName", "Rating");
WriteSearchResults(searchClient.search("hotels", options, Context.NONE));
세 번째 쿼리는 전체 텍스트 검색 작업의 범위를 특정 필드로 지정하는 데 사용되는 searchFields를 보여 줍니다.
// Query 3
System.out.println("Query #3: Limit search to specific fields (pool in Tags field)...\n");
options = new SearchOptions();
options.setSearchFields("Tags");
options.setSelect("HotelId", "HotelName", "Tags");
WriteSearchResults(searchClient.search("pool", options, Context.NONE));
네 번째 쿼리는 facets패싯 탐색 구조를 구성하는 데 사용할 수 있는 방법을 보여 줍니다.
// Query 4
System.out.println("Query #4: Facet on 'Category'...\n");
options = new SearchOptions();
options.setFilter("");
options.setFacets("Category");
options.setSelect("HotelId", "HotelName", "Category");
WriteSearchResults(searchClient.search("*", options, Context.NONE));
다섯 번째 쿼리에서 특정 문서를 반환합니다.
// Query 5
System.out.println("Query #5: Look up a specific document...\n");
Hotel lookupResponse = searchClient.getDocument("3", Hotel.class);
System.out.println(lookupResponse.hotelId);
System.out.println();
마지막 쿼리는 자동 완성 구문을 보여 줍니다. 인덱스에 정의한 제안기에서 두 개의 가능한 일치 sourceFields 항목으로 확인되는 부분 사용자 입력 을 시뮬레이션합니다.
// Query 6
System.out.println("Query #6: Call Autocomplete on HotelName that starts with 's'...\n");
WriteAutocompleteResults(searchClient.autocomplete("s", "sg"));
RunQueries를 Main()에 추가합니다.
// Call the RunQueries method to invoke a series of queries
System.out.println("Starting queries...\n");
RunQueries(searchClient);
// End the program
System.out.println("Complete.\n");
이전 쿼리는 전체 텍스트 검색, 필터 및 자동 완성과 같은 쿼리에서 용어를 일치시키는 여러 방법을 보여줍니다.
전체 텍스트 검색 및 필터는 SearchClient.search 메서드를 사용하여 수행됩니다. 검색 쿼리는 searchText 문자열로 전달할 수 있는 반면, 필터 식은 SearchOptions 클래스의 filter 속성으로 전달할 수 있습니다. 검색하지 않고 필터링하려면 search 메서드의 searchText 매개 변수에 대한 "*"를 전달합니다. 필터링하지 않고 검색하려면 filter 속성을 설정하지 않고 그대로 두거나 SearchOptions 인스턴스에 전달하지 않아야 합니다.
프로그램 실행
F5 키를 눌러서 애플리케이션을 다시 빌드하고 프로그램 전체를 실행합니다.
출력에는 쿼리 정보 및 결과가 추가된 메시지가 System.out.println포함됩니다.
@azure/search-documents 라이브러리를 사용하여 Node.js 콘솔 애플리케이션을 빌드하여 검색 인덱스를 만들고 로드하며 쿼리합니다.
또는 소스 코드를 다운로드하여 완성된 프로젝트로 시작하거나 다음 단계를 수행하여 새 프로젝트를 직접 만들 수 있습니다.
환경 설정
다음 도구를 사용하여 이 빠른 시작을 만들었습니다.
프로젝트 만들기
Visual Studio Code 시작
Ctrl+Shift+P를 사용하여 명령 팔레트를 열고 통합 터미널을 엽니다.
개발 디렉터리를 만들어 이름 빠른 시작을 제공합니다.
mkdir quickstart
cd quickstart
다음 명령을 실행하여 npm으로 빈 프로젝트를 초기화합니다. 프로젝트를 완전히 초기화하려면 ENTER 키를 여러 번 눌러 MIT로 설정해야 하는 라이선스를 제외하고 기본값을 적용합니다.
npm init
@azure/search-documents(JavaScript/Azure AI 검색용 TypeScript SDK)를 설치합니다.
npm install @azure/search-documents
검색 서비스 이름 및 API 키와 같은 환경 변수를 가져오는 데 사용되는 dotenv를 설치합니다.
npm install dotenv
빠른 시작 디렉터리로 이동한 다음, package.json 파일이 다음 json과 유사한지 확인하여 프로젝트 및 해당 종속성을 구성했는지 확인합니다.
{
"name": "quickstart",
"version": "1.0.0",
"description": "Azure AI Search Quickstart",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [
"Azure",
"Search"
],
"author": "Your Name",
"license": "MIT",
"dependencies": {
"@azure/search-documents": "^11.3.0",
"dotenv": "^16.0.2"
}
}
검색 서비스 매개 변수를 보관할 .env 파일을 만듭니다.
SEARCH_API_KEY=<YOUR-SEARCH-ADMIN-API-KEY>
SEARCH_API_ENDPOINT=<YOUR-SEARCH-SERVICE-URL>
YOUR-SEARCH-SERVICE-URL 값을 검색 서비스 엔드포인트 URL의 이름으로 바꿉습니다. 앞에서 기록한 관리 키로 바꿉 <YOUR-SEARCH-ADMIN-API-KEY> 다.
index.js 파일 만들기
다음으로 코드를 호스트하는 기본 파일인 index.js 파일을 만듭니다.
이 파일의 위쪽에서 @azure/search-documents 라이브러리를 가져옵니다.
const { SearchIndexClient, SearchClient, AzureKeyCredential, odata } = require("@azure/search-documents");
다음으로, 다음과 같이 dotenv 패키지에서 .env 파일의 매개 변수를 읽도록 요구해야 합니다.
// Load the .env file if it exists
require("dotenv").config();
// Getting endpoint and apiKey from .env file
const endpoint = process.env.SEARCH_API_ENDPOINT || "";
const apiKey = process.env.SEARCH_API_KEY || "";
가져오기 및 환경 변수가 있으면 main 함수를 정의할 준비가 되었습니다.
대부분의 SDK 기능이 비동기이므로 async main 함수를 만듭니다. 또한 발생한 모든 오류를 catch하고 기록하기 위해 main().catch()를 main 함수 아래에 포함합니다.
async function main() {
console.log(`Running Azure AI Search JavaScript quickstart...`);
if (!endpoint || !apiKey) {
console.log("Make sure to set valid values for endpoint and apiKey with proper authorization.");
return;
}
// remaining quickstart code will go here
}
main().catch((err) => {
console.error("The sample encountered an error:", err);
});
이제 인덱스를 만들 준비가 되었습니다.
인덱스 만들기
hotels_quickstart_index.json 파일을 만듭니다. 이 파일은 다음 단계에서 로드할 문서에서 Azure AI 검색이 작동하는 방식을 정의합니다. 각 필드는 name으로 식별되며 지정된 type이 있습니다. 또한 각 필드에는 Azure AI 검색에서 필드를 검색, 필터링 및 정렬하고 패싯을 수행할 수 있는지 여부를 지정하는 일련의 인덱스 특성도 있습니다. 대부분의 필드는 단순 데이터 형식이지만 AddressType과 같은 일부 형식은 인덱스에서 다양한 데이터 구조를 만들 수 있게 해주는 복합 형식입니다. 인덱스 만들기(REST)에 설명된 지원되는 데이터 형식 및 인덱스 특성에 대해 자세히 알아볼 수 있습니다.
hotels_quickstart_index.json에 다음 콘텐츠를 추가하거나 파일을 다운로드하세요.
{
"name": "hotels-quickstart",
"fields": [
{
"name": "HotelId",
"type": "Edm.String",
"key": true,
"filterable": true
},
{
"name": "HotelName",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": true,
"facetable": false
},
{
"name": "Description",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "en.lucene"
},
{
"name": "Description_fr",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "fr.lucene"
},
{
"name": "Category",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Tags",
"type": "Collection(Edm.String)",
"searchable": true,
"filterable": true,
"sortable": false,
"facetable": true
},
{
"name": "ParkingIncluded",
"type": "Edm.Boolean",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "LastRenovationDate",
"type": "Edm.DateTimeOffset",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Rating",
"type": "Edm.Double",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Address",
"type": "Edm.ComplexType",
"fields": [
{
"name": "StreetAddress",
"type": "Edm.String",
"filterable": false,
"sortable": false,
"facetable": false,
"searchable": true
},
{
"name": "City",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "StateProvince",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "PostalCode",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Country",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [
"HotelName"
]
}
]
}
인덱스 정의가 있으면 main 함수에서 인덱스 정의에 액세스할 수 있도록 index.js의 위쪽에 있는 hotels_quickstart_index.json을 가져와야 합니다.
const indexDefinition = require('./hotels_quickstart_index.json');
그런 다음, main 함수 내에서 Azure AI 검색의 인덱스를 만들고 관리하는 데 사용되는 SearchIndexClient를 만듭니다.
const indexClient = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey));
다음으로, 인덱스가 이미 있으면 이를 삭제해야 합니다. 이 작업은 테스트/데모 코드에 대한 일반적인 사례입니다.
이 작업은 인덱스 삭제를 시도하는 간단한 함수를 정의하여 수행합니다.
async function deleteIndexIfExists(indexClient, indexName) {
try {
await indexClient.deleteIndex(indexName);
console.log('Deleting index...');
} catch {
console.log('Index does not exist yet.');
}
}
이 함수를 실행하기 위해 인덱스 정의에서 인덱스 이름을 추출하고 indexName을 indexClient와 함께 deleteIndexIfExists() 함수에 전달합니다.
const indexName = indexDefinition["name"];
console.log('Checking if index exists...');
await deleteIndexIfExists(indexClient, indexName);
그러면 createIndex() 메서드를 사용하여 인덱스를 만들 준비가 되었습니다.
console.log('Creating index...');
let index = await indexClient.createIndex(indexDefinition);
console.log(`Index named ${index.name} has been created.`);
샘플 실행
이 시점에서 샘플을 실행할 준비가 되었습니다. 터미널 창을 사용하여 다음 명령을 실행합니다.
node index.js
소스 코드를 다운로드했지만 필요한 패키지를 아직 설치하지 않은 경우 먼저 npm install을 실행합니다.
프로그램에서 수행하는 작업을 설명하는 일련의 메시지가 표시됩니다.
Azure Portal에서 검색 서비스의 개요를 엽니다. 인덱스 탭을 선택합니다. 다음 예와 유사한 출력이 표시됩니다.
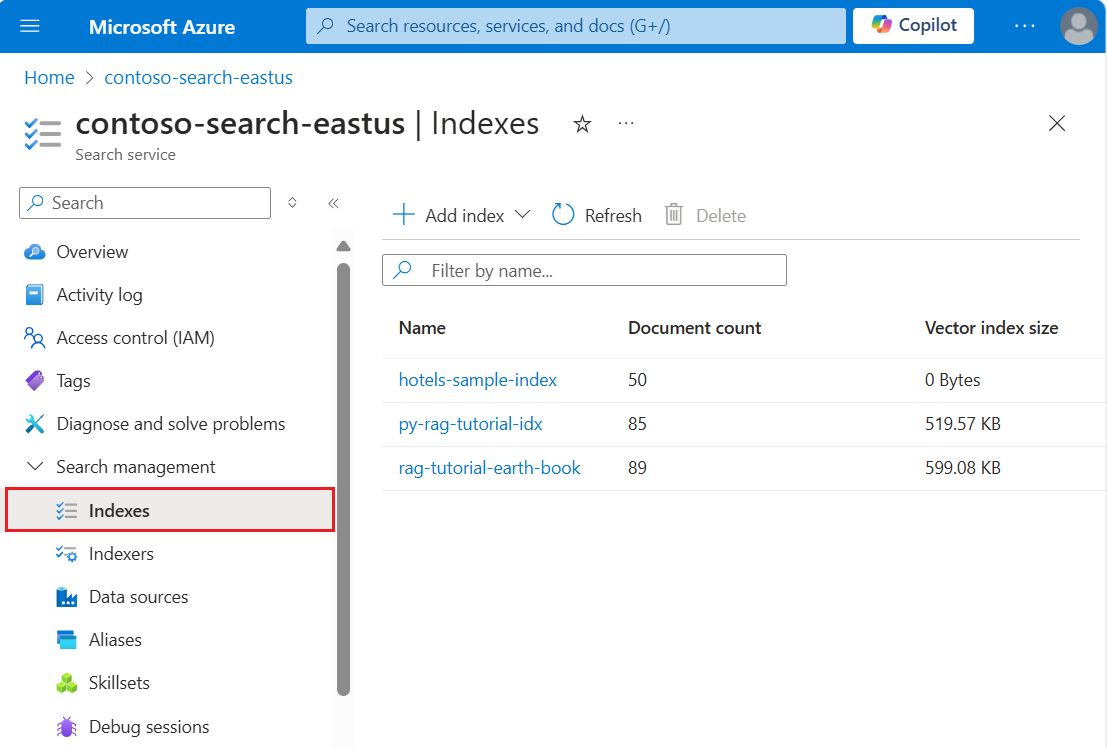
다음 단계에서는 데이터를 인덱스에 추가합니다.
문서 로드
Azure AI 검색에서 문서는 인덱싱에 대한 입력과 쿼리의 출력 모두에 해당하는 데이터 구조입니다. 이러한 데이터를 인덱스에 푸시하거나 인덱서를 사용할 수 있습니다. 이 경우 문서를 인덱스에 프로그래밍 방식으로 푸시합니다.
문서 입력은 데이터베이스의 행, Blob Storage의 Blob 또는 이 샘플처럼 디스크의 JSON 문서일 수 있습니다. 다음 콘텐츠를 사용하여 hotels.json을 다운로드하거나 자체 hotels.json 파일을 만들 수 있습니다.
{
"value": [
{
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": ["pool", "air conditioning", "concierge"],
"ParkingIncluded": false,
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022"
}
},
{
"HotelId": "2",
"HotelName": "Old Century Hotel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": ["pool", "free wifi", "concierge"],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243"
}
},
{
"HotelId": "3",
"HotelName": "Gastronomic Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": ["air conditioning", "bar", "continental breakfast"],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.8,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326"
}
},
{
"HotelId": "4",
"HotelName": "Sublime Palace Hotel",
"Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
"Description_fr": "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": ["concierge", "view", "24-hour front desk service"],
"ParkingIncluded": true,
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.6,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216"
}
}
]
}
indexDefinition또한 주 함수에서 데이터에 액세스할 수 있도록 index.js 맨 위에서 가져와야 hotels.json 합니다.
const hotelData = require('./hotels.json');
데이터를 검색 인덱스로 인덱싱하려면 이제 SearchClient를 만들어야 합니다. SearchIndexClient는 인덱스를 만들고 관리하는 데 사용되지만, SearchClient는 문서를 업로드하고 인덱스를 쿼리하는 데 사용됩니다.
SearchClient를 만드는 방법은 두 가지입니다. 첫 번째 옵션은 SearchClient를 처음부터 만드는 것입니다.
const searchClient = new SearchClient(endpoint, indexName, new AzureKeyCredential(apiKey));
또는 SearchIndexClient의 getSearchClient() 메서드를 사용하여 SearchClient를 만들 수 있습니다.
const searchClient = indexClient.getSearchClient(indexName);
이제 클라이언트가 정의되었으므로 문서를 검색 인덱스에 업로드합니다. 이 경우 동일한 키를 가진 문서가 이미 있는 경우 문서를 업로드하거나 기존 문서와 병합하는 메서드를 사용합니다 mergeOrUploadDocuments() .
console.log('Uploading documents...');
let indexDocumentsResult = await searchClient.mergeOrUploadDocuments(hotelData['value']);
console.log(`Index operations succeeded: ${JSON.stringify(indexDocumentsResult.results[0].succeeded)}`);
node index.js를 사용하여 프로그램을 다시 실행합니다. 1단계에서 본 것과 약간 다른 메시지 세트가 표시됩니다. 이번에는 인덱스가 있으며, 앱에서 새 인덱스를 만들어 데이터를 이 인덱스에 게시하기 전에 해당 인덱스를 삭제하라는 메시지가 표시됩니다.
다음 단계에서 쿼리를 실행하기 전에 프로그램에서 1초 동안 대기하도록 함수를 정의합니다. 이 작업은 인덱싱이 완료되고 쿼리에 대한 인덱스에서 문서를 사용할 수 있도록 하기 위해 테스트/데모 용도로만 수행됩니다.
function sleep(ms) {
var d = new Date();
var d2 = null;
do {
d2 = new Date();
} while (d2 - d < ms);
}
프로그램에서 1초 동안 대기하도록 하려면 아래와 같이 sleep 함수를 호출합니다.
sleep(1000);
인덱스 검색
인덱스가 만들어지고 문서가 업로드되면 쿼리를 인덱스에 보낼 준비가 되었습니다. 이 섹션에서는 5개의 다른 쿼리를 검색 인덱스에 보내 사용 가능한 다양한 쿼리 기능을 보여 줍니다.
쿼리는 다음과 같이 main 함수에서 호출하는 함수로 작성 sendQueries() 됩니다.
await sendQueries(searchClient);
쿼리는 searchClient의 search() 메서드를 사용하여 보냅니다. 첫 번째 매개 변수는 검색 텍스트이고, 두 번째 매개 변수는 검색 옵션을 지정합니다.
첫 번째 쿼리는 모든 항목을 검색하는 것과 동일한 *를 검색하고 인덱스에서 세 개의 필드를 선택합니다. 불필요한 데이터를 다시 끌어오면 쿼리의 대기 시간이 늘어날 수 있으므로 필요한 필드만 선택(select)하는 것이 좋습니다.
searchOptions 또한 이 쿼리의 includeTotalCount 경우 일치하는 결과 수를 반환하는 <a0/>로 설정되었습니다.
async function sendQueries(searchClient) {
console.log('Query #1 - search everything:');
let searchOptions = {
includeTotalCount: true,
select: ["HotelId", "HotelName", "Rating"]
};
let searchResults = await searchClient.search("*", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log(`Result count: ${searchResults.count}`);
// remaining queries go here
}
아래에 설명된 나머지 쿼리도 sendQueries() 함수에 추가해야 합니다. 이 경우 읽기 쉽도록 구분됩니다.
다음 쿼리에서는 "wifi"라는 검색 용어를 지정하고, 상태가 'FL'인 결과만 반환하는 필터도 포함합니다. 결과는 Hotel의 Rating을 기준으로 정렬됩니다.
console.log('Query #2 - Search with filter, orderBy, and select:');
let state = 'FL';
searchOptions = {
filter: odata`Address/StateProvince eq ${state}`,
orderBy: ["Rating desc"],
select: ["HotelId", "HotelName", "Rating"]
};
searchResults = await searchClient.search("wifi", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
다음으로, searchFields 매개 변수를 사용하여 검색을 검색 가능한 단일 필드로 제한합니다. 이 접근 방식은 특정 필드의 일치에만 관심이 있는 경우 쿼리를 더 효율적으로 만들 수 있는 좋은 옵션입니다.
console.log('Query #3 - Limit searchFields:');
searchOptions = {
select: ["HotelId", "HotelName", "Rating"],
searchFields: ["HotelName"]
};
searchResults = await searchClient.search("Sublime Palace", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log();
쿼리에 포함하는 또 다른 일반적인 옵션은 facets입니다. 패싯을 사용하면 사용자가 필터링할 수 있는 값을 쉽게 알 수 있도록 필터를 UI에 빌드할 수 있습니다.
console.log('Query #4 - Use facets:');
searchOptions = {
facets: ["Category"],
select: ["HotelId", "HotelName", "Rating"],
searchFields: ["HotelName"]
};
searchResults = await searchClient.search("*", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
최종 쿼리는 searchClient의 getDocument() 메서드를 사용합니다. 이렇게 하면 해당 키를 통해 문서를 효율적으로 검색할 수 있습니다.
console.log('Query #5 - Lookup document:');
let documentResult = await searchClient.getDocument(key='3')
console.log(`HotelId: ${documentResult.HotelId}; HotelName: ${documentResult.HotelName}`)
샘플 실행
를 사용하여 프로그램을 실행합니다 node index.js. 이제 이전 단계 외에도 쿼리가 전송되고 결과가 콘솔에 기록됩니다.
@azure/search-documents 라이브러리를 사용하여 Node.js 콘솔 애플리케이션을 빌드하여 검색 인덱스를 만들고 로드하며 쿼리합니다.
또는 소스 코드를 다운로드하여 완성된 프로젝트로 시작하거나 다음 단계를 수행하여 새 프로젝트를 직접 만들 수 있습니다.
환경 설정
다음 도구를 사용하여 이 빠른 시작을 만들었습니다.
프로젝트를 만듭니다.
Visual Studio Code 시작
Ctrl+Shift+P를 사용하여 명령 팔레트를 열고 통합 터미널을 엽니다.
개발 디렉터리를 만들어 이름 빠른 시작을 제공합니다.
mkdir quickstart
cd quickstart
다음 명령을 실행하여 npm으로 빈 프로젝트를 초기화합니다. 프로젝트를 완전히 초기화하려면 ENTER 키를 여러 번 눌러 MIT로 설정해야 하는 라이선스를 제외하고 기본값을 적용합니다.
npm init
@azure/search-documents(JavaScript/Azure AI 검색용 TypeScript SDK)를 설치합니다.
npm install @azure/search-documents
검색 서비스 이름 및 API 키와 같은 환경 변수를 가져오는 데 사용되는 dotenv를 설치합니다.
npm install dotenv
빠른 시작 디렉터리로 이동한 다음, package.json 파일이 다음 json과 유사한지 확인하여 프로젝트 및 해당 종속성을 구성했는지 확인합니다.
{
"name": "quickstart",
"version": "1.0.0",
"description": "Azure AI Search Quickstart",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [
"Azure",
"Search"
],
"author": "Your Name",
"license": "MIT",
"dependencies": {
"@azure/search-documents": "^12.1.0",
"dotenv": "^16.4.5"
}
}
검색 서비스 매개 변수를 보관할 .env 파일을 만듭니다.
SEARCH_API_KEY=<YOUR-SEARCH-ADMIN-API-KEY>
SEARCH_API_ENDPOINT=<YOUR-SEARCH-SERVICE-URL>
YOUR-SEARCH-SERVICE-URL 값을 검색 서비스 엔드포인트 URL의 이름으로 바꿉습니다. 앞에서 기록한 관리 키로 바꿉 <YOUR-SEARCH-ADMIN-API-KEY> 다.
index.js 파일 만들기
다음으로 코드를 호스트하는 기본 파일인 index.ts 파일을 만듭니다.
이 파일의 위쪽에서 @azure/search-documents 라이브러리를 가져옵니다.
import {
AzureKeyCredential,
ComplexField,
odata,
SearchClient,
SearchFieldArray,
SearchIndex,
SearchIndexClient,
SearchSuggester,
SimpleField
} from "@azure/search-documents";
다음으로, 다음과 같이 dotenv 패키지에서 .env 파일의 매개 변수를 읽도록 요구해야 합니다.
// Load the .env file if it exists
import dotenv from 'dotenv';
dotenv.config();
// Getting endpoint and apiKey from .env file
const endpoint = process.env.SEARCH_API_ENDPOINT || "";
const apiKey = process.env.SEARCH_API_KEY || "";
가져오기 및 환경 변수가 있으면 main 함수를 정의할 준비가 되었습니다.
대부분의 SDK 기능이 비동기이므로 async main 함수를 만듭니다. 또한 발생한 모든 오류를 catch하고 기록하기 위해 main().catch()를 main 함수 아래에 포함합니다.
async function main() {
console.log(`Running Azure AI Search JavaScript quickstart...`);
if (!endpoint || !apiKey) {
console.log("Make sure to set valid values for endpoint and apiKey with proper authorization.");
return;
}
// remaining quickstart code will go here
}
main().catch((err) => {
console.error("The sample encountered an error:", err);
});
이제 인덱스를 만들 준비가 되었습니다.
인덱스 만들기
hotels_quickstart_index.json 파일을 만듭니다. 이 파일은 다음 단계에서 로드할 문서에서 Azure AI 검색이 작동하는 방식을 정의합니다. 각 필드는 name으로 식별되며 지정된 type이 있습니다. 또한 각 필드에는 Azure AI 검색에서 필드를 검색, 필터링 및 정렬하고 패싯을 수행할 수 있는지 여부를 지정하는 일련의 인덱스 특성도 있습니다. 대부분의 필드는 단순 데이터 형식이지만 AddressType과 같은 일부 형식은 인덱스에서 다양한 데이터 구조를 만들 수 있게 해주는 복합 형식입니다. 인덱스 만들기(REST)에 설명된 지원되는 데이터 형식 및 인덱스 특성에 대해 자세히 알아볼 수 있습니다.
hotels_quickstart_index.json에 다음 콘텐츠를 추가하거나 파일을 다운로드하세요.
{
"name": "hotels-quickstart",
"fields": [
{
"name": "HotelId",
"type": "Edm.String",
"key": true,
"filterable": true
},
{
"name": "HotelName",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": true,
"facetable": false
},
{
"name": "Description",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "en.lucene"
},
{
"name": "Description_fr",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "fr.lucene"
},
{
"name": "Category",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Tags",
"type": "Collection(Edm.String)",
"searchable": true,
"filterable": true,
"sortable": false,
"facetable": true
},
{
"name": "ParkingIncluded",
"type": "Edm.Boolean",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "LastRenovationDate",
"type": "Edm.DateTimeOffset",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Rating",
"type": "Edm.Double",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Address",
"type": "Edm.ComplexType",
"fields": [
{
"name": "StreetAddress",
"type": "Edm.String",
"filterable": false,
"sortable": false,
"facetable": false,
"searchable": true
},
{
"name": "City",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "StateProvince",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "PostalCode",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Country",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [
"HotelName"
]
}
]
}
인덱스 정의가 있으면 main 함수에서 인덱스 정의에 액세스할 수 있도록 index.ts의 위쪽에 있는 hotels_quickstart_index.json을 가져와야 합니다.
// Importing the index definition and sample data
import indexDefinition from './hotels_quickstart_index.json';
interface HotelIndexDefinition {
name: string;
fields: SimpleField[] | ComplexField[];
suggesters: SearchSuggester[];
};
const hotelIndexDefinition: HotelIndexDefinition = indexDefinition as HotelIndexDefinition;
그런 다음, main 함수 내에서 Azure AI 검색의 인덱스를 만들고 관리하는 데 사용되는 SearchIndexClient를 만듭니다.
const indexClient = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey));
다음으로, 인덱스가 이미 있으면 이를 삭제해야 합니다. 이 작업은 테스트/데모 코드에 대한 일반적인 사례입니다.
이 작업은 인덱스 삭제를 시도하는 간단한 함수를 정의하여 수행합니다.
async function deleteIndexIfExists(indexClient: SearchIndexClient, indexName: string): Promise<void> {
try {
await indexClient.deleteIndex(indexName);
console.log('Deleting index...');
} catch {
console.log('Index does not exist yet.');
}
}
이 함수를 실행하기 위해 인덱스 정의에서 인덱스 이름을 추출하고 indexName을 indexClient와 함께 deleteIndexIfExists() 함수에 전달합니다.
// Getting the name of the index from the index definition
const indexName: string = hotelIndexDefinition.name;
console.log('Checking if index exists...');
await deleteIndexIfExists(indexClient, indexName);
그러면 createIndex() 메서드를 사용하여 인덱스를 만들 준비가 되었습니다.
console.log('Creating index...');
let index = await indexClient.createIndex(hotelIndexDefinition);
console.log(`Index named ${index.name} has been created.`);
샘플 실행
이 시점에서 샘플을 빌드하고 실행할 준비가 되었습니다. 터미널 창에서 다음 명령을 실행하여 tsc로 원본을 빌드한 다음, node로 사용하여 원본을 실행합니다.
tsc
node index.ts
소스 코드를 다운로드했지만 필요한 패키지를 아직 설치하지 않은 경우 먼저 npm install을 실행합니다.
프로그램에서 수행하는 작업을 설명하는 일련의 메시지가 표시됩니다.
Azure Portal에서 검색 서비스의 개요를 엽니다. 인덱스 탭을 선택합니다. 다음 예와 유사한 출력이 표시됩니다.
다음 단계에서는 데이터를 인덱스에 추가합니다.
문서 로드
Azure AI 검색에서 문서는 인덱싱에 대한 입력과 쿼리의 출력 모두에 해당하는 데이터 구조입니다. 이러한 데이터를 인덱스에 푸시하거나 인덱서를 사용할 수 있습니다. 이 경우 문서를 인덱스에 프로그래밍 방식으로 푸시합니다.
문서 입력은 데이터베이스의 행, Blob Storage의 Blob 또는 이 샘플처럼 디스크의 JSON 문서일 수 있습니다. 다음 콘텐츠를 사용하여 hotels.json을 다운로드하거나 자체 hotels.json 파일을 만들 수 있습니다.
{
"value": [
{
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": ["pool", "air conditioning", "concierge"],
"ParkingIncluded": false,
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022"
}
},
{
"HotelId": "2",
"HotelName": "Old Century Hotel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": ["pool", "free wifi", "concierge"],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243"
}
},
{
"HotelId": "3",
"HotelName": "Gastronomic Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": ["air conditioning", "bar", "continental breakfast"],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.8,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326"
}
},
{
"HotelId": "4",
"HotelName": "Sublime Palace Hotel",
"Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
"Description_fr": "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": ["concierge", "view", "24-hour front desk service"],
"ParkingIncluded": true,
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.6,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216"
}
}
]
}
indexDefinition을 사용하여 수행한 작업과 마찬가지로 main 함수에서 데이터에 액세스할 수 있도록 index.ts의 위쪽에 있는 hotels.json을 가져와야 합니다.
import hotelData from './hotels.json';
interface Hotel {
HotelId: string;
HotelName: string;
Description: string;
Description_fr: string;
Category: string;
Tags: string[];
ParkingIncluded: string | boolean;
LastRenovationDate: string;
Rating: number;
Address: {
StreetAddress: string;
City: string;
StateProvince: string;
PostalCode: string;
};
};
const hotels: Hotel[] = hotelData["value"];
데이터를 검색 인덱스로 인덱싱하려면 이제 SearchClient를 만들어야 합니다. SearchIndexClient는 인덱스를 만들고 관리하는 데 사용되지만, SearchClient는 문서를 업로드하고 인덱스를 쿼리하는 데 사용됩니다.
SearchClient를 만드는 방법은 두 가지입니다. 첫 번째 옵션은 SearchClient를 처음부터 만드는 것입니다.
const searchClient = new SearchClient<Hotel>(endpoint, indexName, new AzureKeyCredential(apiKey));
또는 SearchIndexClient의 getSearchClient() 메서드를 사용하여 SearchClient를 만들 수 있습니다.
const searchClient = indexClient.getSearchClient<Hotel>(indexName);
이제 클라이언트가 정의되었으므로 문서를 검색 인덱스에 업로드합니다. 이 경우 동일한 키를 가진 문서가 이미 있는 경우 문서를 업로드하거나 기존 문서와 병합하는 메서드를 사용합니다 mergeOrUploadDocuments() . 최소한 첫 번째 문서가 있으므로 작업이 성공했는지 확인합니다.
console.log("Uploading documents...");
const indexDocumentsResult = await searchClient.mergeOrUploadDocuments(hotels);
console.log(`Index operations succeeded: ${JSON.stringify(indexDocumentsResult.results[0].succeeded)}`);
tsc && node index.ts를 사용하여 프로그램을 다시 실행합니다. 1단계에서 본 것과 약간 다른 메시지 세트가 표시됩니다. 이번에는 인덱스가 있으며, 앱에서 새 인덱스를 만들어 데이터를 이 인덱스에 게시하기 전에 해당 인덱스를 삭제하라는 메시지가 표시됩니다.
다음 단계에서 쿼리를 실행하기 전에 프로그램에서 1초 동안 대기하도록 함수를 정의합니다. 이 작업은 인덱싱이 완료되고 쿼리에 대한 인덱스에서 문서를 사용할 수 있도록 하기 위해 테스트/데모 용도로만 수행됩니다.
function sleep(ms: number): Promise<void> {
return new Promise((resolve) => setTimeout(resolve, ms));
}
프로그램이 1초 동안 대기하도록 하려면 함수를 호출합니다 sleep .
sleep(1000);
인덱스 검색
인덱스가 만들어지고 문서가 업로드되면 쿼리를 인덱스에 보낼 준비가 되었습니다. 이 섹션에서는 5개의 다른 쿼리를 검색 인덱스에 보내 사용 가능한 다양한 쿼리 기능을 보여 줍니다.
쿼리는 다음과 같이 main 함수에서 호출하는 함수로 작성 sendQueries() 됩니다.
await sendQueries(searchClient);
쿼리는 searchClient의 search() 메서드를 사용하여 보냅니다. 첫 번째 매개 변수는 검색 텍스트이고, 두 번째 매개 변수는 검색 옵션을 지정합니다.
첫 번째 쿼리는 모든 항목을 검색하는 것과 동일한 *를 검색하고 인덱스에서 세 개의 필드를 선택합니다. 불필요한 데이터를 다시 끌어오면 쿼리의 대기 시간이 늘어날 수 있으므로 필요한 필드만 선택(select)하는 것이 좋습니다.
이 쿼리에 대한 searchOptions에도 true로 설정된 includeTotalCount가 있으며, 이 경우 일치하는 결과의 수를 반환합니다.
async function sendQueries(
searchClient: SearchClient<Hotel>
): Promise<void> {
// Query 1
console.log('Query #1 - search everything:');
const selectFields: SearchFieldArray<Hotel> = [
"HotelId",
"HotelName",
"Rating",
];
const searchOptions1 = {
includeTotalCount: true,
select: selectFields
};
let searchResults = await searchClient.search("*", searchOptions1);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log(`Result count: ${searchResults.count}`);
// remaining queries go here
}
아래에 설명된 나머지 쿼리도 sendQueries() 함수에 추가해야 합니다. 이 경우 읽기 쉽도록 구분됩니다.
다음 쿼리에서는 "wifi"라는 검색 용어를 지정하고, 상태가 'FL'인 결과만 반환하는 필터도 포함합니다. 결과는 Hotel의 Rating을 기준으로 정렬됩니다.
console.log('Query #2 - search with filter, orderBy, and select:');
let state = 'FL';
const searchOptions2 = {
filter: odata`Address/StateProvince eq ${state}`,
orderBy: ["Rating desc"],
select: selectFields
};
searchResults = await searchClient.search("wifi", searchOptions2);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
다음으로, searchFields 매개 변수를 사용하여 검색을 검색 가능한 단일 필드로 제한합니다. 이 접근 방식은 특정 필드의 일치에만 관심이 있는 경우 쿼리를 더 효율적으로 만들 수 있는 좋은 옵션입니다.
console.log('Query #3 - limit searchFields:');
const searchOptions3 = {
select: selectFields,
searchFields: ["HotelName"] as const
};
searchResults = await searchClient.search("Sublime Palace", searchOptions3);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
쿼리에 포함하는 또 다른 일반적인 옵션은 facets입니다. 패싯을 사용하면 UI의 결과에서 자기 주도형 드릴다운을 제공할 수 있습니다. 패싯 결과를 결과 창의 확인란으로 전환할 수 있습니다.
console.log('Query #4 - limit searchFields and use facets:');
const searchOptions4 = {
facets: ["Category"],
select: selectFields,
searchFields: ["HotelName"] as const
};
searchResults = await searchClient.search("*", searchOptions4);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
최종 쿼리는 searchClient의 getDocument() 메서드를 사용합니다. 이렇게 하면 해당 키를 통해 문서를 효율적으로 검색할 수 있습니다.
console.log('Query #5 - Lookup document:');
let documentResult = await searchClient.getDocument('3')
console.log(`HotelId: ${documentResult.HotelId}; HotelName: ${documentResult.HotelName}`)
샘플 다시 실행
tsc && node index.ts를 사용하여 프로그램을 빌드하고 실행합니다. 이제 이전 단계 외에도 쿼리가 전송되고 결과가 콘솔에 기록됩니다.
본인 소유의 구독으로 이 모듈을 진행하고 있는 경우에는 프로젝트가 끝날 때 여기에서 만든 리소스가 계속 필요한지 확인하는 것이 좋습니다. 계속 실행되는 리소스에는 요금이 부과될 수 있습니다. 리소스를 개별적으로 삭제하거나 리소스 그룹을 삭제하여 전체 리소스 세트를 삭제할 수 있습니다.
무료 서비스를 사용하는 경우 인덱스, 인덱서, 데이터 원본 3개로 제한됩니다. Azure Portal에서 개별 항목을 삭제하여 제한 이하로 유지할 수 있습니다.
이 빠른 시작에서는 인덱스를 만들고 문서와 함께 로드하며 쿼리를 실행하는 일련의 작업을 수행했습니다. 여러 단계에서, 가독성과 이해를 돕기 위해 손쉬운 방법을 사용하여 코드를 간소화했습니다. 이제 기본 개념에 익숙해졌으므로 웹앱에서 Azure AI 검색 API를 호출하는 자습서를 시도해 보세요.