Azure Synapse Analytics의 서버리스 SQL 풀 문제 해결
이 문서에는 Azure Synapse Analytics에서 서버리스 SQL 풀의 자주 발생하는 문제를 해결하는 방법에 대한 정보가 포함되어 있습니다.
Azure Synapse Analytics에 대한 자세한 내용은 개요에서 항목을 확인하세요.
Synapse Studio
Synapse Studio는 데이터베이스 액세스 도구를 설치할 필요 없이 브라우저를 사용하여 데이터에 액세스하는 데 사용할 수 있는 사용하기 쉬운 도구입니다. Synapse Studio는 대규모의 데이터 세트 또는 SQL 개체의 전체 관리를 읽도록 설계되지 않았습니다.
Synapse Studio에서 서버리스 SQL 풀이 회색으로 표시됨
Synapse Studio가 서버리스 SQL 풀에 대한 연결을 설정할 수 없는 경우 서버리스 SQL 풀이 회색으로 표시되거나 오프라인 상태로 표시됩니다.
일반적으로 이 문제는 다음 두 가지 이유 중 하나로 인해 발생합니다.
- 네트워크가 Azure Synapse Analytics 백 엔드에 대한 통신을 방지합니다. 가장 빈번한 경우는 TCP 포트 1443이 차단된 경우입니다. 서버리스 SQL 풀이 작동하도록 하려면 이 포트의 차단을 해제합니다. 다른 문제로 인해 서버리스 SQL 풀도 작동하지 않을 수 있습니다. 자세한 내용은 문제 해결 가이드를 참조하세요.
- 서버리스 SQL 풀에 로그인할 수 있는 권한이 없습니다. 액세스하려면 Azure Synapse 작업 영역 관리자가 작업 영역 관리자 역할 또는 SQL 관리자 역할에 사용자를 추가해야 합니다. 자세한 내용은 Azure Synapse 액세스 제어를 참조하세요.
WebSocket 연결이 예기치 않게 닫혔습니다.
Websocket connection was closed unexpectedly. 오류 메시지와 함께 쿼리가 실패할 수 있습니다. 이 메시지는 예를 들어, 네트워크 문제로 인해 Synapse Studio에 대한 브라우저 연결이 중단되었음을 의미합니다.
- 이 문제를 해결하려면 쿼리를 다시 실행합니다.
- 추가 조사를 위해 Synapse Studio 대신 동일한 쿼리에 대해 Azure Data Studio 또는 SQL Server Management Studio를 사용해 보세요.
- 이 메시지가 사용자 환경에서 자주 발생하는 경우 네트워크 관리자의 도움을 받으세요. 방화벽 설정을 확인하고 문제 해결 가이드를 확인할 수도 있습니다.
- 문제가 계속되면 Azure Portal을 통해 지원 티켓을 만듭니다.
서버리스 데이터베이스는 Synapse Studio에 표시되지 않습니다.
서버리스 SQL 풀에 만들어진 데이터베이스가 보이지 않으면 서버리스 SQL 풀이 시작되었는지 확인합니다. 서버리스 SQL 풀이 비활성화되면 데이터베이스가 표시되지 않습니다. 서버리스 SQL 풀에서 쿼리(예: SELECT 1)를 실행하여 쿼리를 활성화하고 데이터베이스를 표시합니다.
Synapse 서버리스 SQL 풀이 사용할 수 없는 것으로 표시됨
잘못된 네트워크 구성은 종종 이 동작의 원인입니다. 포트가 올바르게 구성되었는지 확인합니다. 방화벽이나 프라이빗 엔드포인트를 사용하는 경우 이 설정도 확인합니다.
마지막으로 적절한 역할이 부여되고 해지되지 않았는지 확인합니다.
요청이 이전/만료된 키를 사용하므로 새 데이터베이스를 만들 수 없습니다.
이 오류는 암호화에 사용되는 작업 영역 고객 관리형 키를 변경하여 발생합니다. 작업 영역의 모든 데이터를 최신 버전의 활성 키로 다시 암호화하도록 선택할 수 있습니다. 다시 암호화하기 위해서는 Azure Portal의 키를 임시 키로 변경한 다음 암호화에 사용할 키로 다시 전환합니다. 여기에서 작업 영역 키 관리 방법을 알아봅니다.
구독을 다른 Microsoft Entra 테넌트로 전송한 후 Synapse 서버리스 SQL 풀을 사용할 수 없음
구독을 다른 Microsoft Entra 테넌트로 이동한 경우 서버리스 SQL 풀에 몇 가지 문제가 발생할 수 있습니다. 지원 티켓을 만들면 Azure 지원 팀에서 연락하여 문제를 해결해 드립니다.
스토리지 액세스
Azure 스토리지에 있는 파일에 액세스하는 동안 발생하는 오류가 발생하면 데이터에 액세스할 수 있는 권한이 있는지 확인합니다. 공개적으로 사용 가능한 파일에 액세스할 수 있어야 합니다. 자격 증명 없이 데이터에 액세스하려는 경우 Microsoft Entra ID가 파일에 직접 액세스할 수 있는지 확인합니다.
파일에 액세스하는 데 사용해야 하는 공유 액세스 서명 키가 있는 경우 해당 자격 증명이 포함된 서버 수준 또는 데이터베이스 범위 자격 증명을 만들었는지 확인합니다. 작업 영역 관리 ID 및 사용자 지정 SPN(서비스 사용자 이름)을 사용하여 데이터에 액세스 해야 하는 경우 자격 증명이 필요합니다.
Azure Data Lake Storage에서 파일을 읽거나 나열하거나 액세스할 수 없음
명시적 자격 증명 없이 Microsoft Entra 로그인을 사용하는 경우 Microsoft Entra ID가 스토리지의 파일에 액세스할 수 있는지 확인합니다. 파일에 액세스하려면 Microsoft Entra ID에 Blob 데이터 읽기 권한자 사용 권한 또는 목록 및 ADLS의 읽기 액세스 제어 목록(ACL) 권한이 있어야 합니다. 자세한 내용은 파일을 열 수 없어 쿼리 실패를 참조하세요.
자격 증명을 사용하여 스토리지에 액세스하는 경우 관리 ID 또는 SPN에 데이터 읽기 권한자 또는 기여자 역할이나 특정 ACL 권한이 있는지 확인하세요. 공유 액세스 서명 토큰을 사용한 경우 rl 권한이 있고 만료되지 않았는지 확인합니다.
데이터 원본 없이 SQL 로그인 및 OPENROWSET 함수를 사용하는 경우 스토리지 URI와 일치하고 스토리지에 액세스할 수 있는 권한이 있는 서버 수준 자격 증명이 있는지 확인합니다.
파일을 열 수 없기 때문에 쿼리가 실패합니다.
File cannot be opened because it does not exist or it is used by another process 오류와 함께 쿼리가 실패하고 두 파일이 모두 존재하고 다른 프로세스에서 사용되지 않는 것이 확실한 경우 서버리스 SQL 풀은 파일에 액세스할 수 없습니다. 이 문제는 일반적으로 Microsoft Entra ID에 파일에 액세스할 수 있는 권한이 없거나 방화벽이 파일에 대한 액세스를 차단하고 있기 때문에 발생합니다.
기본적으로 서버리스 SQL 풀은 Microsoft Entra ID를 사용하여 파일에 액세스를 시도합니다. 이 문제를 해결하려면 파일에 액세스할 수 있는 적절한 권한이 있어야 합니다. 가장 쉬운 방법은 쿼리하려는 스토리지 계정에 대한 Storage Blob 데이터 기여자 역할을 자신에게 부여하는 것입니다.
자세한 내용은 다음을 참조하세요.
Storage Blob 데이터 기여자 역할의 대체 기능
자신에게 Storage Blob 데이터 기여자 역할을 부여하는 대신 파일 하위 집합에 대해 보다 세분화된 권한을 부여할 수도 있습니다.
이 컨테이너의 일부 데이터에 액세스해야 하는 모든 사용자는 루트(컨테이너)까지의 모든 부모 폴더에 대한 EXECUTE 권한도 있어야 합니다.
Azure Data Lake Storage Gen2에서 ACL을 설정하는 방법에 대해 자세히 알아봅니다.
참고 항목
컨테이너 수준에 대한 실행 권한은 Azure Data Lake Storage Gen2 내에서 설정되어야 합니다. 폴더에 대한 권한은 Azure Synapse 내에서 설정할 수 있습니다.
이 예에서 data2.csv를 쿼리하려면 다음 권한이 필요합니다.
- 컨테이너에 대한 실행 권한
- folder1에 대한 실행 권한
- data2.csv에 대한 읽기 권한
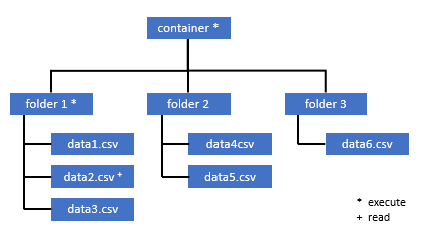
액세스하려는 데이터에 대한 모든 권한이 있는 관리 사용자로 Azure Synapse에 로그인합니다.
데이터 창에서 파일을 마우스 오른쪽 단추로 클릭하고 액세스 관리를 선택합니다.
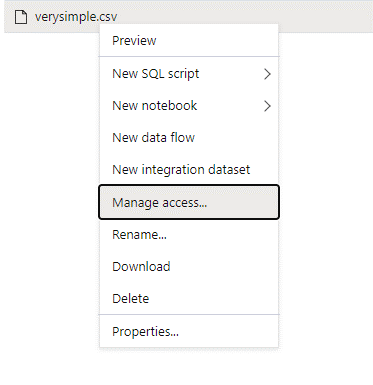
최소한 읽기 권한을 선택합니다. 사용자의 UPN 또는 개체 ID를 입력합니다(예:
user@contoso.com). 추가를 선택합니다.이 사용자에 대한 읽기 권한을 부여합니다.

참고 항목
게스트 사용자의 경우 이 단계는 Azure Synapse를 통해 직접 수행할 수 없으므로 Azure Data Lake에서 직접 수행해야 합니다.
경로의 디렉터리 내용을 나열할 수 없습니다.
이 오류는 Azure Data Lake를 쿼리하는 사용자가 스토리지의 파일을 나열할 수 없음을 나타냅니다. 이 오류가 발생할 수 있는 몇 가지 시나리오는 다음과 같습니다.
- Microsoft Entra 통과 인증을 사용하는 Microsoft Entra 사용자는 Data Lake Storage의 파일을 나열할 권한이 없습니다.
- 공유 액세스 서명 키 또는 작업 영역 관리 ID를 사용하여 데이터를 읽고 있고 해당 키 또는 ID에 스토리지의 파일을 나열할 권한이 없는 Microsoft Entra ID 또는 SQL 사용자입니다.
- Dataverse에서 데이터를 쿼리할 권한이 없는 Dataverse 데이터에 액세스하는 사용자입니다. 이 시나리오는 SQL 사용자를 사용하는 경우 발생할 수 있습니다.
- Delta Lake에 액세스하는 사용자는 Delta Lake 트랜잭션 로그를 읽을 수 있는 권한이 없을 수 있습니다.
이 문제를 해결하는 가장 쉬운 방법은 쿼리하려는 스토리지 계정에서 Storage Blob 데이터 기여자 역할을 자신에게 부여하는 것입니다.
자세한 내용은 다음을 참조하세요.
Dataverse 테이블의 내용을 나열할 수 없습니다.
Azure Synapse Link for Dataverse를 사용하여 연결된 DataVerse 테이블을 읽는 경우 Microsoft Entra 계정을 사용하여 서버리스 SQL 풀을 사용하여 연결된 데이터에 액세스해야 합니다. 자세한 내용은 Azure Data Lake가 있는 Dataverse용 Azure Synapse Link를 참조하세요.
SQL 로그인을 사용하여 DataVerse 테이블을 참조하는 외부 테이블을 읽으려고 하면 다음과 같은 오류가 발생합니다. External table '???' is not accessible because content of directory cannot be listed.
Dataverse 외부 테이블은 항상 Microsoft Entra 통과 인증을 사용합니다. 공유 액세스 서명 키 또는 작업 영역 관리 ID를 사용하도록 구성할 수 없습니다.
Delta Lake 트랜잭션 로그의 내용을 나열할 수 없습니다.
서버리스 SQL 풀이 Delta Lake 트랜잭션 로그 폴더를 읽을 수 없는 경우 다음 오류가 반환됩니다.
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
_delta_log 폴더가 있는지 확인합니다. Delta Lake 형식으로 변환되지 않은 일반 Parquet 파일을 쿼리 중일 수 있습니다. _delta_log 폴더가 있는 경우 기본 Delta Lake 폴더에 대한 읽기 및 나열 권한이 둘 다 있는지 확인합니다. FORMAT='csv'를 사용하여 json 파일을 직접 읽으세요. BULK 매개 변수에 URI를 입력합니다.
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
이 쿼리가 실패하면 호출자는 기본 스토리지 파일을 읽을 수 있는 권한이 없습니다.
쿼리 실행
다음과 같은 경우 쿼리를 실행하는 동안 발생하는 오류가 발생할 수 있습니다.
- 호출자가 일부 개체에 액세스할 수 없습니다.
- 쿼리가 외부 데이터에 액세스할 수 없습니다.
- 쿼리에 서버리스 SQL 풀에서 지원되지 않는 일부 기능이 포함되어 있습니다.
현재 리소스 제약 조건으로 인해 쿼리를 실행할 수 없어 쿼리가 실패
This query cannot be executed due to current resource constraints. 오류 메시지와 함께 쿼리가 실패할 수 있습니다. 이 메시지는 현재 서버리스 SQL 풀을 실행할 수 없음을 의미합니다. 다음은 몇 가지 문제 해결 옵션입니다.
- 적절한 크기의 데이터 형식이 사용되는지 확인합니다.
- 쿼리에서 Parquet 파일을 대상으로 하는 경우 문자열 열은 기본적으로 VARCHAR(8000) 형식이므로 이 열에 대한 명시적 형식을 정의하는 것이 좋습니다. 유추한 데이터 형식을 확인하세요.
- 쿼리 대상이 CSV 파일인 경우 통계 만들기를 고려해 보세요.
- 쿼리를 최적화하려면 서버리스 SQL 풀의 성능 모범 사례를 참조하세요.
쿼리 제한 시간이 만료되었습니다.
서버리스 SQL 풀에서 쿼리가 30분 이상 실행되면 Query timeout expired 오류가 반환됩니다. 서버리스 SQL 풀에 대한 이 제한은 변경할 수 없습니다.
- 모범 사례를 적용하여 쿼리를 최적화해 보세요.
- 또는 CETAS(create external table as selec)를 사용하여 쿼리의 일부를 구체화해 보세요.
- 다른 쿼리가 리소스를 사용할 수 있으므로 서버리스 SQL 풀에서 실행 중인 동시 워크로드가 있는지 확인합니다. 이 경우 워크로드를 여러 작업 영역에 분할할 수 있습니다.
잘못된 개체 이름
Invalid object name 'table name' 오류는 서버리스 SQL 풀 데이터베이스에 존재하지 않는 개체(예: 테이블 또는 뷰)를 사용하고 있음을 나타냅니다. 다음 옵션을 시도해 보세요.
테이블 또는 뷰를 나열하고 개체가 있는지 확인합니다. Synapse Studio는 서버리스 SQL 풀에서 사용할 수 없는 일부 테이블을 표시할 수 있으므로 SQL Server Management Studio 또는 Azure Data Studio를 사용합니다.
개체가 보이면 대/소문자 구분/이진 데이터베이스 데이터 정렬을 사용하고 있는지 확인합니다. 개체 이름이 쿼리에 사용한 이름과 일치하지 않을 수 있습니다. 이진 데이터베이스 데이터 정렬을 사용하는 경우
Employee와employee는 서로 다른 두 개체입니다.개체가 표시되지 않으면 Lake 또는 Spark 데이터베이스에서 테이블을 쿼리하려는 것일 수 있습니다. 다음과 같은 이유로 서버리스 SQL 풀에서 테이블을 사용하지 못할 수 있습니다.
- 테이블에는 서버리스 SQL 풀에서 표시할 수 없는 일부 열 형식이 있습니다.
- 테이블에 서버리스 SQL 풀에서 지원되지 않는 형식이 있습니다. 예를 들어 Avro 또는 ORC가 있습니다.
문자열이나 이진 데이터가 잘림
이 오류는 문자열 또는 이진 열 형식(예: VARCHAR, VARBINARY 또는 NVARCHAR)의 길이가 읽는 데이터의 실제 크기보다 짧은 경우에 발생합니다. 열 형식의 길이를 늘려서 이 오류를 해결할 수 있습니다.
- 문자열 열이
VARCHAR(32)형식으로 정의되고 텍스트가 60자이면 열 스키마에서VARCHAR(60)형식(또는 더 긴 형식)을 사용합니다. - 스키마 유추(
WITH스키마 제외)를 사용하는 경우 모든 문자열 열이 자동으로VARCHAR(8000)형식으로 정의됩니다. 이 오류가 발생하면 이 오류를 해결하기 위해 더 큰VARCHAR(MAX)열 형식의WITH절에서 스키마를 명시적으로 정의합니다. - 테이블이 Lake 데이터베이스에 있는 경우 Spark 풀에서 문자열 열 크기를 늘려 보세요.
- 기능에 영향을 주지 않는 경우 서버리스 SQL 풀이 VARCHAR 값을 자동으로 자르도록
SET ANSI_WARNINGS OFF합니다.
문자열 뒤의 따옴표가 짝이 맞지 않습니다.
드문 경우지만 문자열 열에 LIKE 연산자를 사용하거나 문자열 리터럴과 비교하면 다음 오류가 발생할 수 있습니다.
Unclosed quotation mark after the character string
이 오류는 열에서 Latin1_General_100_BIN2_UTF8 데이터 정렬을 사용하는 경우 발생할 수 있습니다. Latin1_General_100_BIN2_UTF8 데이터 정렬 대신 열에 Latin1_General_100_CI_AS_SC_UTF8 데이터 정렬을 설정하여 문제를 해결합니다. 오류가 계속 반환되면 Azure Portal을 통해 지원 요청을 제출합니다.
한 배포에서 다른 배포로 데이터를 전송하는 동안 tempdb 공간을 할당할 수 없습니다.
쿼리 실행 엔진이 데이터를 처리할 수 없고 쿼리를 실행 중인 노드 간에 데이터를 전송할 수 없으면 Could not allocate tempdb space while transferring data from one distribution to another 오류가 반환됩니다. 쿼리는 현재 리소스 제약 조건 오류로 인해 실행할 수 없기 때문에 실패하는 제네틱의 특별한 경우입니다. 이 오류는 tempdb 데이터베이스에 할당된 리소스가 쿼리를 실행하기에 충분하지 않을 때 반환됩니다.
지원 티켓을 제출하기 전에 모범 사례를 적용합니다.
외부 파일을 처리하는 동안 오류가 발생하여 쿼리가 실패함(최대 오류 수에 도달함)
오류 메시지 error handling external file: Max errors count reached으로 쿼리가 실패하는 경우 지정된 열 형식과 로드해야 하는 데이터가 일치하지 않음을 의미합니다.
오류 및 확인할 행과 열에 대한 자세한 내용을 보려면 파서 버전을 2.0에서 1.0으로 변경합니다.
예시
이 쿼리 1을 사용하여 names.csv 파일을 쿼리하려는 경우 Azure Synapse 서버리스 SQL 풀이 다음 오류와 함께 반환됩니다. Error handling external file: 'Max error count reached'. File/External table name: [filepath]. 예:
names.csv 파일에는 다음이 포함됩니다.
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
쿼리 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
원인
파서 버전이 버전 2.0에서 1.0으로 변경되는 즉시 오류 메시지가 문제를 식별하는 데 도움이 됩니다. 새 오류 메시지는 이제 Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].입니다.
잘림은 열 형식이 너무 작아 데이터에 맞지 않음을 나타냅니다. 이 names.csv 파일에서 가장 긴 이름은 7자입니다. 사용할 데이터 형식은 최소한 VARCHAR(7)이여야 합니다. 이 오류는 다음 코드 줄로 인해 발생합니다.
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
그에 따라 쿼리를 변경하면 오류가 해결됩니다. 디버깅 후 최대 성능을 달성하려면 파서 버전을 다시 2.0으로 변경합니다.
언제 어떤 파서 버전을 사용해야 하는지에 대한 자세한 내용은 Synapse Analytics에서 서버리스 SQL 풀을 사용하여 OPENROWSET 사용을 참조하세요.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
파일을 열 수 없기 때문에 대량 로드할 수 없습니다.
Cannot bulk load because the file could not be opened 오류는 쿼리 실행 중에 파일이 수정될 때 반환됩니다. 일반적으로 Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)와 같은 오류가 발생할 수 있습니다.
서버리스 SQL 풀은 쿼리가 실행되는 동안 수정 중인 파일을 읽을 수 없습니다. 쿼리는 파일을 잠글 수 없습니다. 수정 작업이 추가라는 것을 알고 있는 경우 {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]} 옵션을 설정해 볼 수 있습니다.
자세한 내용은 추가 전용 파일 쿼리 또는 추가 전용 파일에 테이블 만들기 방법을 참조하세요.
데이터 변환 오류로 인해 쿼리가 실패
Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath]. 오류 메시지와 함께 쿼리가 실패할 수 있습니다. 이 메시지는 데이터 형식이 행 번호 n 및 열 m의 실제 데이터와 일치하지 않음을 의미합니다.
예를 들어 데이터에 정수만 있어야 하지만 행 n에 문자열이 있는 경우 이 오류 메시지가 표시됩니다.
이 문제를 해결하려면 파일 및 선택한 데이터 형식을 검사합니다. 또한 행 구분 기호 및 필드 종결자 설정이 올바른지 확인합니다. 다음 예는 VARCHAR를 열 형식으로 사용하여 검사하는 방법을 보여 줍니다.
필드 종결자, 행 구분 기호 및 이스케이프 인용 문자에 대한 자세한 내용은 CSV 파일 쿼리를 참조하세요.
예시
names.csv 파일을 쿼리하려는 경우:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
다음 쿼리:
쿼리 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Azure Synapse 서버리스 SQL 풀이 Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath]. 오류를 반환합니다.
데이터를 찾아보고 합리적으로 결정하여 이 문제를 처리해야 합니다. 이 문제를 유발하는 데이터를 살펴보려면 먼저 데이터 형식을 변경해야 합니다. 데이터 형식이 SMALLINT인 ID 열을 쿼리하는 대신 VARCHAR(100)이 이제 이 문제를 분석하는 데 사용됩니다.
약간 변경된 이 쿼리 2를 사용하면 이제 데이터를 처리하여 이름 목록을 반환할 수 있습니다.
쿼리 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
데이터의 다섯 번째 행에서 ID에 대해 예기치 않은 값이 있음을 관찰할 수 있습니다. 이러한 상황에서는 데이터의 비즈니스 소유자와 협력하여 이 예와 같은 손상된 데이터를 방지할 수 있는 방법에 동의하는 것이 중요합니다. 애플리케이션 수준에서 방지가 불가능한 경우 적절한 크기의 VARCHAR가 유일한 옵션일 수 있습니다.
팁
VARCHAR()를 최대한 짧게 만들어 보세요. 성능을 저하시킬 수 있으므로 가능하면 VARCHAR(MAX)을 사용하지 마세요.
쿼리 결과가 예상대로 표시되지 않습니다.
쿼리가 실패하지 않을 수 있지만 결과 집합이 예상과 다를 수 있습니다. 결과 열이 비어 있거나 예기치 않은 데이터가 반환될 수 있습니다. 이 시나리오에서는 행 구분 기호 또는 필드 종결자가 잘못 선택되었을 수 있습니다.
이 문제를 해결하려면 데이터를 다시 살펴보고 해당 설정을 변경합니다. 다음 예제와 같이 이 쿼리를 디버깅하는 것은 쉽습니다.
예시
쿼리 1의 쿼리로 names.csv 파일을 쿼리하려는 경우 Azure Synapse 서버리스 SQL 풀은 이상하게 보이는 결과와 함께 반환됩니다.
names.csv의 경우
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
Firstname 열에 값이 없는 것 같습니다. 대신 모든 값이 결국 ID 열에 있었습니다. 이러한 값은 쉼표로 구분됩니다. 필드 종결자로 세미콜론 기호 대신 쉼표를 선택해야 하기 때문에 이 코드 줄에서 문제가 발생했습니다.
FIELDTERMINATOR =';',
이 단일 문자를 변경하면 문제가 해결됩니다.
FIELDTERMINATOR =',',
이제 쿼리 2에서 만들어진 결과 집합이 예상대로 보입니다.
쿼리 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
HRESULT = NO_ERROR를
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
형식의 열이 외부 데이터 형식과 호환되지 않습니다.
Column [column-name] of type [type-name] is not compatible with external data type […], 오류 메시지와 함께 쿼리가 실패하면 PARQUET 데이터 형식이 잘못된 SQL 데이터 형식에 매핑되었을 수 있습니다.
예를 들어 Parquet 파일에 부동 숫자(예: 12.89)가 포함된 열 가격이 있고 이를 INT에 매핑하려고 하면 이 오류 메시지가 표시됩니다.
이 문제를 해결하려면 선택한 파일과 데이터 형식을 검사합니다. 이 매핑 테이블은 올바른 SQL 데이터 형식을 선택하는 데 유용합니다. 가장 좋은 방법은 VARCHAR 데이터 형식으로 해석될 열에 대해서만 매핑을 지정하는 것입니다. 가능한 경우 VARCHAR를 방지하면 쿼리 성능이 향상됩니다.
예시
이 쿼리 1을 사용하여 taxi-data.parquet 파일을 쿼리하려는 경우 Azure Synapse 서버리스 SQL 풀이 다음 오류와 함께 반환됩니다.
taxi-data.parquet 파일에는 다음 항목이 포함되어 있습니다.
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
쿼리 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
이 오류 메시지는 데이터 형식이 호환되지 않으며 INT 대신 FLOAT를 사용하라는 제안과 함께 제공됩니다. 이 오류는 다음 코드 줄로 인해 발생합니다.
SumTripDistance INT,
약간 변경된 쿼리 2를 사용하면 이제 데이터를 처리할 수 있으며 세 개의 열이 모두 표시됩니다.
쿼리 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
쿼리가 분산 처리 모드에서 지원되지 않는 개체를 참조하세요.
The query references an object that is not supported in distributed processing mode 오류는 Azure Storage 또는 Azure Cosmos DB 분석 스토리지에서 데이터를 쿼리하는 동안 사용할 수 없는 개체 또는 함수를 사용했음을 나타냅니다.
시스템 뷰와 같은 일부 개체 및 함수는 Azure Data Lake 또는 Azure Cosmos DB 분석 스토리지에 저장된 데이터를 쿼리하는 동안 사용할 수 없습니다. 외부 데이터를 시스템 뷰와 조인하거나, 임시 테이블에 외부 데이터를 로드하거나, 일부 보안 또는 메타데이터 함수를 사용하여 외부 데이터를 필터링하는 쿼리를 사용하지 마세요.
WaitIOCompletion 호출 실패
WaitIOCompletion call failed 오류 메시지는 원격 스토리지(Azure Data Lake)에서 데이터를 읽는 I/O 작업이 완료되기를 기다리는 동안 쿼리가 실패했음을 나타냅니다.
오류 메시지의 패턴은 다음과 같습니다. Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
스토리지가 서버리스 SQL 풀과 동일한 지역에 있는지 확인합니다. 스토리지 메트릭을 검사하고 스토리지 계층(새 파일 업로드)에 I/O 요청을 포화시킬 수 있는 다른 워크로드가 없는지 확인하세요.
HRESULT 필드에는 결과 코드가 포함됩니다. 다음 오류 코드는 잠재적 솔루션과 함께 가장 일반적입니다.
이 오류 코드는 원본 파일이 스토리지에 없음을 의미합니다.
이 오류 코드가 발생할 수 있는 이유는 다음과 같습니다.
- 파일이 다른 애플리케이션에 의해 삭제되었습니다.
- 이 일반적인 시나리오에서 쿼리 실행이 시작되고, 파일이 열거되고, 파일이 발견됩니다. 나중에 쿼리 실행 중에 파일이 삭제됩니다. 예를 들어 Databricks, Spark 또는 Azure Data Factory에서 삭제할 수 있습니다. 파일을 찾을 수 없기 때문에 쿼리가 실패합니다.
- 이 문제는 델타 형식에서도 발생할 수 있습니다. 새 버전의 테이블이 있고 삭제된 파일이 다시 쿼리되지 않기 때문에 다시 시도 시 쿼리가 성공할 수 있습니다.
- 잘못된 실행 계획이 캐시됩니다.
- 임시 완화 조치로
DBCC FREEPROCCACHE명령을 실행합니다. 문제가 지속되면 지원 티켓을 만드세요.
- 임시 완화 조치로
NOT 근처의 잘못된 구문
Incorrect syntax near 'NOT' 오류는 열 정의에 NOT NULL 제약 조건이 포함된 열이 있는 일부 외부 테이블이 있음을 나타냅니다.
- 열 정의에서 NOT NULL을 제거하도록 테이블을 업데이트합니다.
- 이 오류는 CETAS 문에서 만든 테이블에서 일시적으로 발생할 수도 있습니다. 문제가 해결되지 않으면 외부 테이블을 삭제하고 다시 만들 수 있습니다.
분할 열이 NULL 값 반환
쿼리가 파티션 열 대신 NULL 값을 반환하거나 파티션 열을 찾을 수 없는 경우 몇 가지 가능한 문제 해결 단계가 있습니다.
- 테이블을 사용하여 분할된 데이터 세트를 쿼리하는 경우 테이블은 분할을 지원하지 않습니다. 테이블을 분할된 뷰로 바꾸세요.
- FILEPATH() 함수를 사용하여 분할된 파일을 쿼리하는 OPENROWSET과 함께 분할된 뷰를 사용하는 경우 위치에 와일드카드 패턴을 올바르게 지정했는지, 와일드카드를 참조하는 데 적절한 인덱스를 사용했는지 확인합니다.
- 분할된 폴더에서 직접 파일을 쿼리하는 경우 분할 열은 파일 열의 일부가 아닙니다. 분할 값은 파일이 아닌 폴더 경로에 배치됩니다. 이러한 이유로 파일에는 파티션 값이 포함되어 있지 않습니다.
열 형식 DATETIME2의 일괄 처리에 값을 삽입하지 못함
Inserting value to batch for column type DATETIME2 failed 오류는 서버리스 풀이 기본 파일에서 날짜 값을 읽을 수 없음을 나타냅니다. Parquet 또는 Delta Lake 파일에 저장된 날짜/시간 값은 DATETIME2 열로 나타낼 수 없습니다.
Spark를 사용하여 파일의 최솟값을 검사하고 일부 날짜가 0001-01-03보다 작은지 확인합니다. Spark 2.4(지원되지 않는 런타임 버전) 버전 또는 여전히 레거시 datetime 스토리지 형식을 사용하는 상위 Spark 버전을 사용하여 파일을 저장한 경우 이전 날짜/시간 값은 서버리스 SQL 풀에서 사용되는 역산 양력과 일치하지 않는 율리우스력을 사용하여 작성됩니다.
Parquet(일부 Spark 버전에서)에서 값을 작성하는 데 사용되는 율리우스력과 서버리스 SQL 풀에서 사용되는 역산 양력 사이에는 2일 간의 차이가 있을 수 있습니다. 이 차이로 인해 유효하지 않은 음수 날짜 값으로 변환될 수 있습니다.
이러한 값은 SQL에서 잘못된 날짜 값으로 처리되므로 Spark를 사용하여 업데이트해 보세요. 다음 샘플에서는 Delta Lake에서 SQL 날짜 범위를 벗어난 값을 NULL로 업데이트하는 방법을 보여줍니다.
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
이렇게 변경하면 나타낼 수 없는 값이 제거됩니다. 다른 날짜 값은 제대로 로드되지만 율리우스력과 역산 양력 사이에는 여전히 차이가 있기 때문에 잘못 표시될 수 있습니다. Spark 3.0 또는 이전 버전을 사용하는 경우 1900-01-01 이전의 날짜에 대해서도 예기치 않은 날짜 이동이 나타날 수 있습니다.
Spark 3.1 이상으로 마이그레이션하고 역산 양력으로 전환하는 것이 좋습니다. 최신 Spark 버전은 기본적으로 서버리스 SQL 풀의 달력과 일치하는 비례 양력 달력을 사용합니다. 더 높은 버전의 Spark를 사용하여 레거시 데이터를 다시 로드하고 다음 설정을 사용하여 날짜를 수정합니다.
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
토폴로지 변경 또는 컴퓨팅 컨테이너 오류로 인해 쿼리 실패
이 오류는 서버리스 SQL 풀에서 일부 내부 프로세스 문제가 발생했음을 나타낼 수 있습니다. Azure 지원 팀이 문제를 조사하는 데 도움이 될 수 있는 모든 필요한 세부 정보가 포함된 지원 티켓을 제출합니다.
정규 워크로드와 비교하여 비정상적일 수 있는 사항을 설명합니다. 예를 들어 이 오류가 발생하기 전에 많은 수의 동시 요청이 있거나 특수한 워크로드 또는 쿼리가 실행되기 시작했을 수 있습니다.
와일드카드 확장 시간 초과
쿼리 폴더 및 여러 파일 섹션에 설명된 대로 서버리스 SQL 풀은 와일드카드를 사용하여 여러 파일/폴더 읽기를 지원합니다. 쿼리당 최대 10개의 와일드카드 제한이 있습니다. 이 기능에는 비용이 든다는 점을 알고 있어야 합니다. 서버리스 풀이 와일드카드와 일치할 수 있는 모든 파일을 나열하는 데 시간이 걸립니다. 이로 인해 대기 시간이 발생하며 쿼리하려는 파일 수가 많을 경우 이 대기 시간이 증가할 수 있습니다. 이 경우 다음 오류가 발생할 수 있습니다.
"Wildcard expansion timed out after X seconds."
이를 방지하기 위해 수행할 수 있는 몇 가지 완화 단계가 있습니다.
- 서버리스 SQL 풀 모범 사례에 설명된 모범 사례를 적용합니다.
- 파일을 더 큰 파일로 압축하여 쿼리하려는 파일 수를 줄이십시오. 파일 크기를 100MB 이상으로 유지합니다.
- 가능하면 분할 열에 대한 필터가 사용되는지 확인합니다.
- 델타 파일 형식을 사용하는 경우 Spark에서 쓰기 최적화 기능을 사용합니다. 이렇게 하면 읽고 처리해야 하는 데이터의 양이 줄어들어 쿼리 성능이 개선될 수 있습니다. 쓰기 최적화를 사용하는 방법은 Apache Spark에서 쓰기 최적화 사용에 설명되어 있습니다.
- 분할 열에 대한 암시적 필터를 효과적으로 하드코딩하여 일부 최상위 와일드카드를 방지하려면 동적 SQL을 사용합니다.
자동 스키마 유추를 사용할 때 누락된 열
WITH 절을 생략하면 스키마를 모르거나 지정하지 않고도 쉽게 파일을 쿼리할 수 있습니다. 이 경우 파일에서 열 이름과 데이터 형식이 유추됩니다. 한 번에 파일 수를 읽는 경우 스토리지에서 가져오는 첫 번째 파일 서비스에서 스키마가 유추됩니다. 이는 스키마를 정의하기 위해 서비스에서 사용하는 파일에 이러한 열이 포함되지 않았기 때문에 예상되는 일부 열이 생략되었음을 의미할 수 있습니다. 스키마를 명시적으로 지정하려면 OPENROWSET WITH 절을 사용합니다. 스키마를 지정하면(외부 테이블 또는 OPENROWSET WITH 절 사용) 기본 lax 경로 모드가 사용됩니다. 즉, 일부 파일에 없는 열은 NULL로 반환됩니다(해당 파일의 행에 대해). 경로 모드를 사용하는 방법을 이해하려면 다음 설명서 및 샘플을 확인하세요.
구성
서버리스 SQL 풀을 사용하면 T-SQL을 사용하여 데이터베이스 개체를 구성할 수 있습니다. 몇 가지 제약 조건이 있습니다.
master및lakehouse또는 Spark 데이터베이스에서 개체를 만들 수 없습니다.- 자격 증명을 만들려면 마스터 키가 있어야 합니다.
- 개체에 사용되는 데이터를 참조할 수 있는 권한이 있어야 합니다.
데이터베이스를 만들 수 없음
CREATE DATABASE failed. User database limit has been already reached. 오류가 발생하면 하나의 작업 영역에서 지원되는 최대 데이터베이스 수를 만든 것입니다. 자세한 내용은 제약 조건을 참조하세요.
- 개체를 분리해야 하는 경우 데이터베이스 내에서 스키마를 사용합니다.
- Azure Data Lake Storage를 참조해야 하는 경우 서버리스 SQL 풀에서 동기화할 lakehouse 데이터베이스 또는 Spark 데이터베이스를 만듭니다.
최소 행 크기가 허용되는 최대 테이블 행 크기인 8060바이트를 초과하므로 테이블 만들기 또는 변경에 실패함
모든 테이블에는 행당 최대 8KB 크기(행이 아닌 VARCHAR(MAX)/VARBINARY(MAX) 데이터가 포함되지 않음)가 있을 수 있습니다. 행의 총 셀 크기가 8060바이트를 초과하는 테이블을 만들면 다음 오류가 발생합니다.
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
열 크기가 8060바이트를 초과하는 Spark 테이블을 만들고 서버리스 SQL 풀에서 Spark 테이블 데이터를 참조하는 테이블을 만들 수 없는 경우에도 이 오류가 발생할 수 있습니다.
완화하려면 CHAR(N)과 같은 고정 크기 형식을 사용하지 않고 변수 크기 VARCHAR(N) 형식으로 바꾸거나 CHAR(N)에서 크기를 줄입니다. SQL Server에서 8KB 행 그룹 제한을 참조하세요.
이 작업을 수행하기 전에 데이터베이스에서 마스터 키를 만들거나 세션의 마스터 키를 엽니다.
Please create a master key in the database or open the master key in the session before performing this operation. 오류 메시지를 나타내며 쿼리가 실패하는 경우 현재 사용자 데이터베이스가 마스터 키에 액세스할 수 없음을 의미합니다.
새 사용자 데이터베이스를 만들고 아직 마스터 키를 만들지 않았을 가능성이 큽니다.
이 문제를 해결하려면 다음 쿼리를 사용하여 마스터 키를 만듭니다.
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
참고 항목
여기에서 'strongpasswordhere'를 다른 비밀로 바꿉니다.
CREATE 문은 master 데이터베이스에서 지원되지 않습니다.
Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database. 오류 메시지와 함께 쿼리가 실패하면 서버리스 SQL 풀의 master 데이터베이스가 다음 만들기를 지원하지 않는다는 의미입니다.
- 외부 테이블.
- 외부 데이터 원본.
- 데이터베이스 범위 자격 증명.
- 외부 파일 형식.
솔루션:
사용자 데이터베이스를 만듭니다.
CREATE DATABASE <DATABASE_NAME>이전에
master데이터베이스에 대해 실패한 <DATABASE_NAME> 컨텍스트에서 CREATE 문을 실행합니다.다음은 외부 파일 형식 만들기의 예입니다.
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
Microsoft Entra 로그인 또는 사용자를 만들 수 없음
데이터베이스에서 새 Microsoft Entra 로그인 또는 사용자를 만들려고 시도하는 동안 오류가 발생하면 데이터베이스에 연결하는 데 사용한 로그인을 확인합니다. 새 Microsoft Entra 사용자를 만들려는 로그인에는 Microsoft Entra 도메인에 액세스하고 사용자가 있는지 확인할 수 있는 권한이 있어야 합니다. 유의 사항:
- SQL 로그인에는 이 권한이 없으므로 SQL 인증을 사용하면 항상 이 오류가 발생합니다.
- Microsoft Entra 로그인을 사용하여 새 로그인을 만드는 경우 Microsoft Entra 도메인에 액세스할 수 있는 권한이 있는지 확인합니다.
Azure Cosmos DB
서버리스 SQL 풀을 사용하면 OPENROWSET 함수를 사용하여 Azure Cosmos DB 분석 스토리지를 쿼리할 수 있습니다. Azure Cosmos DB 컨테이너에 분석 스토리지가 있는지 확인합니다. 계정, 데이터베이스 및 컨테이너 이름을 올바르게 지정했는지 확인합니다. 또한 Azure Cosmos DB 계정 키가 유효한지 확인합니다. 자세한 내용은 필수 구성 요소를 참조하세요.
OPENROWSET 함수를 사용하여 Azure Cosmos DB를 쿼리할 수 없음
Azure Cosmos DB 계정에 연결할 수 없는 경우 필수 조건을 확인합니다. 가능한 오류 및 문제 해결 작업은 다음 표에 나와 있습니다.
| 오류 | 근본 원인 |
|---|---|
| 구문 오류: - OPENROWSET 근처의 구문이 잘못되었습니다.- ...는 인식되는 BULK OPENROWSET 공급자 옵션이 아닙니다.- ... 근처의 구문이 잘못되었습니다. |
가능한 근본 원인: - Azure Cosmos DB를 첫 번째 매개 변수로 사용하지 않습니다. - 세 번째 매개 변수에서 식별자 대신 문자열 리터럴을 사용함. - 세 번째 매개 변수(컨테이너 이름)를 지정하지 않음. |
| Azure Cosmos DB 연결 문자열에 오류가 있습니다. | - 계정, 데이터베이스 또는 키가 지정되지 않음. - 연결 문자열의 옵션이 인식되지 않습니다. - 세미콜론( ;)은 연결 문자열의 끝에 배치됩니다. |
| "잘못된 계정 이름" 또는 "잘못된 데이터베이스 이름" 오류로 인해 Azure Cosmos DB 경로를 확인하지 못했습니다. | 지정된 계정 이름, 데이터베이스 이름 또는 컨테이너를 찾을 수 없거나 지정된 컬렉션에 대해 분석 스토리지를 사용하도록 설정하지 않았습니다. |
| "잘못된 비밀 값" 또는 "비밀이 Null이거나 비어 있습니다." 오류로 인해 Azure Cosmos DB 경로를 확인하지 못했습니다. | 계정 키가 잘못되었거나 없습니다. |
Azure Cosmos DB 문자열 형식을 읽는 동안 UTF-8 데이터 정렬 경고가 반환됨
서버리스 SQL 풀은 OPENROWSET 열 데이터 정렬에 UTF-8 인코딩이 없는 경우 컴파일 타임 경고를 반환합니다. T-SQL 문을 사용하여 현재 데이터베이스에서 실행되는 모든 OPENROWSET 함수에 대한 기본 데이터 정렬을 쉽게 변경할 수 있습니다.
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
Latin1_General_100_BIN2_UTF8 데이터 정렬은 문자열 조건자를 사용하여 데이터를 필터링할 때 최상의 성능을 제공합니다.
Azure Cosmos DB 분석 저장소의 누락된 행
Azure Cosmos DB의 일부 항목은 OPENROWSET 함수에서 반환되지 않을 수 있습니다. 유의 사항:
- 트랜잭션 저장소와 분석 저장소 간에 동기화 지연이 있습니다. Azure Cosmos DB 트랜잭션 저장소에 입력한 문서는 2~3분 후에 분석 저장소에 나타날 수 있습니다.
- 문서가 스키마 제약 조건을 위반할 수 있습니다.
쿼리가 일부 Azure Cosmos DB 항목에서 NULL 값을 반환합니다.
Azure Synapse SQL은 다음과 같은 경우 트랜잭션 저장소에 표시되는 값 대신 NULL을 반환합니다.
- 트랜잭션 저장소와 분석 저장소 간에 동기화 지연이 있습니다. Azure Cosmos DB 트랜잭션 저장소에 입력한 값은 2~3분 후에 분석 저장소에 나타날 수 있습니다.
- WITH 절에 잘못된 열 이름 또는 경로 식이 있을 수 있습니다. WITH 절의 열 이름(또는 열 형식 뒤의 경로 식)은 Azure Cosmos DB 컬렉션의 속성 이름과 일치해야 합니다. 비교 시 대/소문자가 구분됩니다. 예를 들어
productCode와ProductCode는 서로 다른 속성입니다. 열 이름이 Azure Cosmos DB 속성 이름과 정확히 일치하는지 확인합니다. - 이 속성은 1000개를 초과하는 속성 또는 127개를 초과하는 중첩 수준과 같은 스키마 제약 조건을 위반하기 때문에 분석 스토리지로 이동되지 않을 수 있습니다.
- 잘 정의된 스키마 표현을 사용하는 경우 트랜잭션 저장소의 값에 잘못된 형식이 있을 수 있습니다. 잘 정의된 스키마는 문서를 샘플링하여 각 속성에 대한 형식을 잠급니다. 트랜잭션 저장소에 추가된 값 중에서 형식과 일치하지 않는 값은 잘못된 값으로 처리되고 분석 저장소로 마이그레이션되지 않습니다.
- 완전한 스키마 표현을 사용하는 경우
$.price.int64와 같은 속성 이름 뒤에 형식 접미사를 추가해야 합니다. 참조된 경로에 대한 값이 표시되지 않으면 다른 형식 경로(예:$.price.float64)에 저장되어 있을 수 있습니다. 자세한 내용은 완전한 스키마에서 Azure Cosmos DB 컬렉션 쿼리를 참조하세요.
열이 외부 데이터 형식과 호환되지 않습니다.
WITH 절에 지정된 열 형식이 Azure Cosmos DB 컨테이너의 형식과 일치하지 않으면 Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. 오류가 반환됩니다. Azure Cosmos DB에서 SQL 형식 매핑 섹션에 설명된 바와 같이 열 형식을 변경하거나 VARCHAR 형식을 사용하세요.
해결: Azure Cosmos DB 경로가 오류로 인해 실패함
Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'. 오류가 발생하면 Azure Cosmos DB에서 프라이빗 엔드포인트를 사용했는지 확인합니다. 서버리스 SQL 풀이 프라이빗 엔드포인트가 있는 분석 저장소에 액세스할 수 있도록 하려면 Azure Cosmos DB 분석 저장소에 대한 프라이빗 엔드포인트를 구성해야 합니다.
Azure Cosmos DB 성능 문제
예기치 못한 성능 문제가 발생하면 다음과 같은 모범 사례를 적용했는지 확인합니다.
- 클라이언트 애플리케이션, 서버리스 풀 및 Azure Cosmos DB 분석 스토리지를 동일한 지역에 배치했는지 확인합니다.
- 최적 데이터 형식과 함께 WITH 절을 사용해야 합니다.
- 문자열 조건자를 사용하여 데이터를 필터링할 때 Latin1_General_100_BIN2_UTF8 데이터 정렬을 사용해야 합니다.
- 캐시될 수 있는 반복 쿼리가 있는 경우 Azure Data Lake Storage에 쿼리 결과를 저장하는 CETAS를 사용해 보세요.
Delta Lake
서버리스 SQL 풀의 Delta Lake 지원에서 볼 수 있는 몇 가지 제한 사항이 있습니다.
- OPENROWSET 함수 또는 외부 테이블 위치에서 루트 Delta Lake 폴더를 참조하고 있는지 확인합니다.
- 루트 폴더에는
_delta_log라는 하위 폴더가 있어야 합니다._delta_log폴더가 없으면 쿼리가 실패합니다. 해당 폴더가 표시되지 않으면 Apache Spark 풀을 사용하여 Delta Lake로 변환해야 하는 일반 Parquet 파일을 참조하고 있는 것입니다. - 파티션 스키마를 설명하는 와일드카드를 지정하지 마세요. Delta Lake 쿼리는 Delta Lake 파티션을 자동으로 식별합니다.
- 루트 폴더에는
- Apache Spark 풀에서 만든 Delta Lake 테이블은 서버리스 SQL 풀에서 자동으로 사용할 수 있지만 스키마는 업데이트되지 않습니다(공개 미리 보기 제한). Spark 풀을 사용하여 Delta 테이블에 열을 추가하는 경우 서버리스 SQL 풀 데이터베이스에 변경 내용이 표시되지 않습니다.
- 외부 테이블은 분할을 지원하지 않습니다. Delta Lake 폴더에서 분할된 뷰를 사용하여 파티션 제거를 사용합니다. 문서의 뒷부분에서 알려진 문제 및 해결 방법을 참조하세요.
- 서버리스 SQL 풀은 시간 이동 쿼리를 지원하지 않습니다. Synapse Analytics에서 Apache Spark 풀을 사용하여 이전 데이터를 읽습니다.
- 서버리스 SQL 풀은 Delta Lake 파일 업데이트를 지원하지 않습니다. 서버리스 SQL 풀을 사용하여 최신 버전의 Delta Lake를 쿼리할 수 있습니다. Synapse Analytics에서 Apache Spark 풀을 사용하여 Delta Lake를 업데이트합니다.
- CETAS 명령을 사용하여 쿼리 결과를 Delta Lake 형식으로 스토리지에 저장할 수 없습니다. CETAS 명령은 출력 형식으로 Parquet 및 CSV만 지원합니다.
- Synapse Analytics의 서버리스 SQL 풀은 Delta 읽기 권한자 버전 1과 호환됩니다.
- Synapse Analytics의 서버리스 SQL 풀은 BLOOM 필터가 있는 데이터 세트를 지원하지 않습니다. 서버리스 SQL 풀은 BLOOM 필터를 무시합니다.
- Delta Lake 지원은 전용 SQL 풀에서 사용할 수 없습니다. 서버리스 SQL 풀을 사용하여 Delta Lake 파일을 쿼리해야 합니다.
- 서버리스 SQL 풀의 알려진 문제에 대한 자세한 내용은 Azure Synapse Analytics의 알려진 문제를 참조하세요.
서버리스 지원 델타 1.0 버전
서버리스 SQL 풀은 Delta Lake 1.0 버전만 읽습니다. 서버리스 SQL 풀은 수준 1이 있는 델타 판독기이며 다음 기능을 지원하지 않습니다.
- 열 매핑은 무시됩니다. 서버리스 SQL 풀은 원래 열 이름을 반환합니다.
- 삭제 벡터는 무시되고 삭제/업데이트된 행의 이전 버전이 반환됩니다(잘못된 결과일 수 있음).
- 다음 Delta Lake 기능은 지원되지 않습니다. V2 검사점, 표준 시간대 없는 타임스탬프, VACUUM 프로토콜 검사
삭제 벡터는 무시됨
Delta Lake 테이블이 델타 Writer 버전 7을 사용하도록 구성된 경우 삭제된 행과 업데이트된 행의 이전 버전을 DV(삭제 벡터)에 저장합니다. 서버리스 SQL 풀에는 델타 판독기 1 수준이 있으므로 삭제 벡터를 무시하고 지원되지 않는 Delta Lake 버전을 읽을 때 잘못된 결과를 생성할 수 있습니다.
Delta 테이블의 열 이름 바꾸기는 지원되지 않음
서버리스 SQL 풀은 이름이 바뀐 열이 Delta Lake 테이블 쿼리를 지원하지 않습니다. 서버리스 SQL 풀은 이름이 바뀐 열에서 데이터를 읽을 수 없습니다.
Delta 테이블의 열 값이 NULL입니다.
델타 판독기 버전 2 이상이 필요한 델타 데이터 집합을 사용하고 버전 1에서 지원되지 않는 기능(예: 열 이름 바꾸기, 열 삭제 또는 열 매핑)을 사용하는 경우 참조된 열의 값이 표시되지 않을 수 있습니다.
JSON 텍스트의 형식이 올바르지 않습니다.
이 오류는 서버리스 SQL 풀이 Delta Lake 트랜잭션 로그를 읽을 수 없음을 나타냅니다. 다음 오류가 표시될 수 있습니다.
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Delta Lake 데이터 세트가 손상되지 않았는지 확인합니다. Azure Synapse에서 Apache Spark 풀을 사용하여 Delta Lake 폴더의 콘텐츠를 읽을 수 있는지 확인합니다. 이렇게 하면 _delta_log 파일이 손상되지 않았는지 확인할 수 있습니다.
해결 방법
Apache Spark 풀을 사용하여 Delta Lake 데이터 세트에 검사점을 만들고 쿼리를 다시 실행해 보세요. 검사점은 트랜잭션 JSON 로그 파일을 집계하고 문제를 해결할 수 있습니다.
데이터 세트가 유효한 경우 지원 티켓을 만들고 추가 정보를 제공합니다.
- 열 추가 또는 제거 또는 테이블 최적화와 같은 변경 작업을 수행하지 마세요. 이 작업은 Delta Lake 트랜잭션 로그 파일의 상태를 변경할 수 있기 때문입니다.
_delta_log폴더의 내용을 새 빈 폴더에 복사합니다..parquet data파일을 복사하지 마세요.- 새 폴더에 복사한 콘텐츠를 읽고 동일한 오류가 발생하는지 확인합니다.
- 복사한
_delta_log파일의 콘텐츠를 Azure 지원에 보냅니다.
이제 Spark 풀과 함께 Delta Lake 폴더를 계속 사용할 수 있습니다. 이 정보를 공유할 수 있는 경우 복사된 데이터를 Microsoft 지원에 제공합니다. Azure 팀은 delta_log 파일의 내용을 조사하고 가능한 오류 및 해결 방법에 대한 추가 정보를 제공합니다.
델타 로그 해결 실패
다음 오류는 서버리스 SQL 풀이 델타 로그를 확인할 수 없음을 나타냅니다. Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder. 가장 일반적인 원인은 _delta_log 폴더의 last_checkpoint_file Spark 3.3에 추가된 checkpointSchema 필드로 인해 200바이트보다 크다는 것입니다.
이 오류를 피하기 위해 사용할 수 있는 두 가지 옵션이 있습니다.
- Spark Notebook에서 적절한 구성을 수정하고 새 검사점을 만들어
last_checkpoint_file이 다시 만들어지도록 합니다. Azure Databricks를 사용하는 경우 구성 수정은 다음과 같습니다.spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Spark 3.2.1로 다운그레이드
Microsoft 엔지니어링 팀은 현재 Spark 3.3에 대한 완전한 지원을 위해 노력하고 있습니다.
Spark에서 만들어진 Delta 테이블이 서버리스 풀에 표시되지 않음
참고 항목
Spark에서 만들어진 Delta 테이블의 복제는 아직 공개 미리 보기 상태입니다.
Spark에서 델타 테이블을 만들었는데 서버리스 SQL 풀에 표시되지 않는 경우 다음을 확인합니다.
- Spark 테이블이 지연과 동기화되기 때문에 잠시(보통 30초) 기다립니다.
- 일정 시간이 지난 후에도 서버리스 SQL 풀에 테이블이 나타나지 않으면 Spark Delta 테이블의 스키마를 확인합니다. 복합 형식이 있는 Spark 테이블 또는 서버리스에서 지원되지 않는 형식은 사용할 수 없습니다. 레이크 데이터베이스에서 동일한 스키마로 Spark Parquet 테이블을 만들고 해당 테이블이 서버리스 SQL 풀에 나타나는지 확인합니다.
- 테이블에서 참조하는 작업 영역 관리 ID 액세스 Delta Lake 폴더를 확인합니다. 서버리스 SQL 풀은 작업 영역 관리 ID를 사용하여 스토리지에서 테이블 열 정보를 가져와 테이블을 만듭니다.
레이크 데이터베이스
Spark 또는 Synapse 디자이너를 사용하여 만든 Lake 데이터베이스 테이블은 쿼리를 위해 서버리스 SQL 풀에서 자동으로 사용할 수 있습니다. 서버리스 SQL 풀을 사용하여 Spark 풀을 사용하여 만든 Parquet, CSV 및 Delta Lake 테이블을 쿼리하고, db_datareader 역할의 다른 스키마, 뷰, 프로시저, 테이블 값 함수 및 Microsoft Entra 사용자를 Lake 데이터베이스에 추가할 수 있습니다. 가능한 문제는 이 섹션에 나열되어 있습니다.
Spark에서 만든 테이블은 서버리스 풀에서 사용할 수 없습니다.
만든 테이블은 서버리스 SQL 풀에서 즉시 사용할 수 없을 수 있습니다.
- 테이블은 서버리스 풀에서 사용할 수 있으며 약간의 지연이 있습니다. 서버리스 SQL 풀에서 표시하려면 Spark에서 테이블을 만든 후 5-10분 정도 기다려야 할 수 있습니다.
- Parquet, CSV 및 Delta 형식을 참조하는 테이블만 서버리스 SQL 풀에서 사용할 수 있습니다. 다른 테이블 형식은 사용할 수 없습니다.
- 일부 지원되지 않는 열 형식은 포함된 테이블은 서버리스 SQL 풀에서 사용할 수 없습니다.
- Lake 데이터베이스의 Delta Lake 테이블에 액세스는 공개 미리 보기로 제공됩니다. 이 섹션 또는 Delta Lake 섹션에 나열된 다른 문제를 확인합니다.
Spark에서 만든 외부 테이블이 서버리스 풀에서 예기치 않은 결과를 표시하고 있습니다.
서버리스 풀에서 원본 Spark 외부 테이블과 복제된 외부 테이블 간에 불일치가 발생할 수 있습니다. Spark 외부 테이블을 만드는 데 사용되는 파일에 확장명이 없는 경우에 발생할 수 있습니다. 적절한 결과를 얻으려면 모든 파일에 .parquet과 같은 확장이 있는지 확인합니다.
복제된 데이터베이스에는 작업이 허용되지 않습니다.
이 오류는 Lake 데이터베이스를 수정하고, 외부 테이블, 외부 데이터 원본, 데이터베이스 범위 자격 증명 또는 Lake 데이터베이스에서 다른 개체를 만들려는 경우에 반환됩니다. 이러한 개체는 SQL 데이터베이스에서만 만들 수 있습니다.
Lake 데이터베이스는 Apache Spark 풀에서 복제되고 Apache Spark에서 관리됩니다. 따라서 T-SQL 언어를 사용하여 SQL Database에서와 같은 개체를 만들 수 없습니다.
Lake 데이터베이스에서는 다음 작업만 허용됩니다.
dbo이외의 스키마에서 보기, 프로시저 및 iTVF(인라인 테이블 값 함수)를 만들거나, 삭제하거나 변경합니다.- Microsoft Entra ID에서 데이터베이스 사용자를 만들고 삭제합니다.
db_datareader스키마에서 데이터베이스 사용자를 추가하거나 제거합니다.
Lake 데이터베이스에서는 다른 작업이 허용되지 않습니다.
참고 항목
dbo 스키마에서 보기, 프로시저 또는 함수를 만드는 경우 또는 스키마를 생략하고 일반적으로 dbo인 기본 스키마를 사용하는 경우 오류 메시지가 표시됩니다.
Lake 데이터베이스의 Delta 테이블은 서버리스 SQL 풀에서 사용할 수 없습니다.
작업 영역 관리 ID가 Delta 폴더가 포함된 ADLS 스토리지에 대한 읽기 권한이 있는지 확인합니다. 서버리스 SQL 풀은 ADLS에 배치된 Delta 로그에서 Delta Lake 테이블 스키마를 읽고 작업 영역 관리 ID를 사용하여 Delta 트랜잭션 로그에 액세스합니다.
관리 ID 자격 증명을 사용하여 Azure Data Lake 스토리지를 참조하는 일부 SQL Database에서 데이터 원본을 설치하고 관리 ID가 있는 테이블이 스토리지에 액세스할 수 있도록 관리 ID를 사용하여 데이터 원본 위에 외부 테이블을 만들려고 합니다.
Lake 데이터베이스의 델타 테이블에는 Spark 및 서버리스 풀에서 동일한 스키마가 없습니다.
서버리스 SQL 풀을 사용하면 Spark 또는 Synapse 디자이너를 사용하여 Lake 데이터베이스에서 만든 Parquet, CSV 및 Delta 테이블에 액세스할 수 있습니다. 델타 테이블에 대한 액세스는 아직 공개 미리 보기 상태이며 현재 서버리스에서는 생성 시 Delta 테이블을 Spark와 동기화하지만 나중에 Spark의 ALTER TABLE 문을 사용하여 열이 추가되면 스키마를 업데이트하지 않습니다.
이는 공개 미리 보기 제한 사항입니다. 이 문제를 해결하기 위해 테이블을 변경하는 대신 Spark에서 델타 테이블을 삭제하고 다시 만듭니다(가능한 경우).
성능
서버리스 SQL 풀은 데이터 세트의 크기와 쿼리 복잡성을 기반으로 쿼리에 리소스를 할당합니다. 쿼리에 제공되는 리소스를 변경하거나 제한할 수 없습니다. 예기치 않게 쿼리 성능이 저하되어 근본 원인을 파악해야 할 때가 있습니다.
매우 긴 쿼리 기간
쿼리 기간이 30분보다 긴 쿼리가 있는 경우 클라이언트에 천천히 결과를 반환하는 쿼리가 느립니다. 서버리스 SQL 풀의 실행 제한 시간은 30분입니다. 결과 스트리밍에 더 많은 시간을 할애합니다. 다음 해결 방법을 시도해 보세요.
- Synapse Studio를 사용하는 경우 SQL Server Management Studio 또는 Azure Data Studio와 같은 다른 애플리케이션과 관련된 문제를 재현해 봅니다.
- SQL Server Management Studio, Azure Data Studio, Power BI 또는 기타 애플리케이션을 사용하여 실행할 때 쿼리가 느린 경우 네트워킹 문제와 모범 사례를 확인합니다.
- CETAS 명령에 쿼리를 넣고 쿼리 기간을 측정합니다. CETAS 명령은 결과를 Azure Data Lake Storage에 저장하며 클라이언트 연결에 의존하지 않습니다. CETAS 명령이 원래 쿼리보다 빠르게 완료되면 클라이언트와 서버리스 SQL 풀 간의 네트워크 대역폭을 확인합니다.
Synapse Studio를 사용하여 실행할 때 쿼리가 느림
Synapse Studio를 사용하는 경우 SQL Server Management Studio 또는 Azure Data Studio와 같은 데스크톱 클라이언트를 사용해 보세요. Synapse Studio는 일반적으로 SQL Server Management Studio 또는 Azure Data Studio에서 사용되는 네이티브 SQL 연결보다 느린 HTTP 프로토콜을 사용하여 서버리스 SQL 풀에 연결하는 웹 클라이언트입니다.
애플리케이션을 사용하여 실행할 때 쿼리가 느림
쿼리 실행이 느린 경우 다음 문제를 확인합니다.
- 클라이언트 애플리케이션이 서버리스 SQL 풀 엔드포인트와 함께 배치되었는지 확인합니다. 지역 전체에서 쿼리를 실행하면 추가 대기 시간이 발생하고 결과 집합의 스트리밍 속도가 느려질 수 있습니다.
- 결과 집합 스트리밍 속도가 느려질 수 있는 네트워킹 문제가 없는지 확인합니다.
- 클라이언트 애플리케이션에 충분한 리소스가 있는지 확인합니다(예: CPU 사용률이 100%가 아님).
- 스토리지 계정 또는 Azure Cosmos DB 분석 스토리지가 서버리스 SQL 엔드포인트와 동일한 지역에 배치되어 있는지 확인합니다.
리소스 배치에 대한 모범 사례를 참조하세요.
쿼리 기간의 큰 차이
동일한 쿼리를 실행하고 쿼리 기간의 변화를 관찰하는 경우 몇 가지 이유로 인해 이 동작이 발생할 수 있습니다.
- 이것이 쿼리의 첫 번째 실행인지 확인합니다. 쿼리를 처음 실행하면 계획을 작성하는 데 필요한 통계가 수집됩니다. 통계는 기본 파일을 스캔하여 수집되며, 이로 인해 쿼리 기간이 늘어날 수 있습니다. Synapse Studio에서는 쿼리 전에 실행되는 SQL 요청 목록에서 "전역 통계 만들기" 쿼리를 볼 수 있습니다.
- 통계는 일정 시간이 지나면 만료될 수 있습니다. 서버리스 풀은 통계를 검사하고 다시 빌드해야 하므로 주기적으로 성능에 미치는 영향을 관찰할 수 있습니다. 쿼리 전에 실행되는 SQL 요청 목록에서 또 다른 "전역 통계 만들기" 쿼리를 볼 수 있습니다.
- 실행 기간이 더 긴 쿼리를 실행했을 때 동일한 엔드포인트에서 실행되는 워크로드가 있는지 확인합니다. 서버리스 SQL 엔드포인트는 병렬로 실행되는 모든 쿼리에 리소스를 균등하게 할당하며, 쿼리가 지연될 수 있습니다.
연결
서버리스 SQL 풀에서는 TDS 프로토콜을 사용하여 연결하고 T SQL 언어를 사용하여 데이터를 쿼리할 수 있습니다. SQL 서버 또는 Azure SQL Database에 연결할 수 있는 대부분의 도구도 서버리스 SQL 풀에 연결할 수 있습니다.
SQL 풀이 준비 중
장시간 활동이 없으면 서버리스 SQL 풀이 비활성화됩니다. 첫 번째 연결 시도와 같은 첫 번째 다음 작업에서 활성화가 자동으로 수행됩니다. 활성화 프로세스는 단일 연결 시도 간격보다 약간 더 오래 걸릴 수 있으므로 오류 메시지가 표시됩니다. 연결 시도를 다시 하는 것만으로 충분합니다.
클라이언트에서 지원하는 경우 ConnectionRetryCount 및 ConnectRetryInterval 연결 문자열 키워드를 사용하여 다시 연결 동작을 제어하는 것이 좋습니다.
오류 메시지가 지속되면 Azure Portal을 통해 지원 티켓을 제출하세요.
Synapse Studio에서 연결할 수 없음
Synapse Studio 섹션을 참조하세요.
도구에서 Azure Synapse 풀에 연결할 수 없습니다.
일부 도구에는 Azure Synapse 서버리스 SQL 풀에 연결하는 데 사용할 수 있는 명시적 옵션이 없을 수 있습니다. SQL Server 또는 SQL Database에 연결하는 데 사용할 옵션을 사용합니다. 서버리스 SQL 풀은 SQL Server 또는 SQL Database와 동일한 프로토콜을 사용하므로 연결 대화 상자를 "Synapse"로 브랜딩할 필요가 없습니다.
도구를 사용하여 논리 서버 이름만 입력할 수 있고 database.windows.net 도메인을 미리 정의하더라도 Azure Synapse 작업 영역 이름 뒤에 -ondemand 접미사 및 database.windows.net 도메인을 입력합니다.
보안
사용자에게 데이터베이스 액세스 권한, 명령 실행 권한, Azure Data Lake 또는 Azure Cosmos DB 스토리지 액세스 권한이 있는지 확인합니다.
Azure Cosmos DB 계정에 액세스할 수 없습니다.
분석 스토리지에 액세스하려면 읽기 전용 Azure Cosmos DB 키를 사용해야 하므로 만료되지 않았거나 다시 생성되지 않았는지 확인합니다.
"Azure Cosmos DB 경로를 확인하는 데 오류가 발생했습니다" 오류가 표시되면 방화벽을 구성했는지 확인합니다.
lakehouse 또는 Spark 데이터베이스에 액세스할 수 없음
사용자가 lakehouse 또는 Spark 데이터베이스에 액세스할 수 없는 경우 사용자에게 데이터베이스에 액세스하고 읽을 수 있는 권한이 없을 수 있습니다. CONTROL SERVER 권한이 있는 사용자는 모든 데이터베이스에 대한 모든 권한이 있어야 합니다. 제한된 권한으로 CONNECT ANY DATABASE 및 SELECT ALL USER SECURABLES를 사용하려고 시도했을 수 있습니다.
SQL 사용자가 Dataverse 테이블에 액세스할 수 없음
Dataverse 테이블은 호출자의 Microsoft Entra ID를 사용하여 스토리지에 액세스합니다. 높은 권한이 있는 SQL 사용자가 테이블에서 데이터를 선택하려고 시도하지만 테이블이 Dataverse 데이터에 액세스할 수 없습니다. 이 시나리오는 지원되지 않습니다.
SPI가 역할 할당을 만들 때 Microsoft Entra 서비스 주체 로그인 실패
다른 SPI를 사용하여 SPI(서비스 주체 식별자) 또는 Microsoft Entra 앱에 대한 역할 할당을 만들려는 경우 또는 이미 만든 경우 로그인에 실패하면 다음 오류가 표시될 수 있습니다.Login error: Login failed for user '<token-identified principal>'.
서비스 주체의 경우 개체 ID가 아닌 SID(보안 ID)로 애플리케이션 ID를 사용하여 로그인을 만들어야 합니다. Azure Synapse가 다른 SPI 또는 앱에 대한 역할 할당을 만들 때 Microsoft Graph에서 애플리케이션 ID를 가져오지 못하게 하는 서비스 주체에 대한 알려진 제한이 있습니다.
해결 방법 1
Azure Portal>Synapse Studio>관리>액세스 제어로 이동하여 원하는 서비스 주체에 대해 Synapse 관리자 또는 Synapse SQL 관리자를 수동으로 추가합니다.
해결 방법 2
SQL 코드를 사용하여 적절한 로그인을 수동으로 만들어야 합니다.
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
솔루션 3
PowerShell을 사용하여 서비스 주체 Azure Synapse 관리자를 설정할 수도 있습니다. Az.Synapse 모듈이 설치되어 있어야 합니다.
솔루션은 -ObjectId "parameter"와 함께 cmdlet New-AzSynapseRoleAssignment를 사용하는 것입니다. 해당 매개 변수 필드에 작업 영역 관리자 Azure 서비스 주체 자격 증명을 사용하여 개체 ID 대신 애플리케이션 ID를 제공합니다.
PowerShell 스크립트:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
참고 항목
이 경우 synapse Data Studio UI는 위의 메서드에서 추가한 역할 할당을 표시하지 않으므로 UI에도 표시될 수 있도록 개체 ID와 애플리케이션 ID 모두에 역할 할당을 동시에 추가하는 것이 좋습니다.
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<object_id_to_add_as_admin>" [-Debug]
유효성 검사
서버리스 SQL 엔드포인트에 연결하고 SID(이전 샘플의 app_id_to_add_as_admin)를 사용하여 외부 로그인이 만들어졌는지 확인합니다.
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
또는 set admin 앱을 사용하여 서버리스 SQL 엔드포인트에서 로그인을 시도합니다.
제약 조건
일부 일반 시스템 제약 조건이 워크로드에 영향을 줄 수 있습니다.
| 속성 | 제한 사항 |
|---|---|
| 구독당 최대 Azure Synapse 작업 영역 수 | 제한 참조. |
| 서버리스 풀당 최대 데이터베이스 수 | 100(Apache Spark 풀에서 동기화된 데이터베이스 제외) |
| Apache Spark 풀에서 동기화된 최대 데이터베이스 수 | 제한되지 않습니다. |
| 데이터베이스당 최대 데이터베이스 개체 수 | 한 데이터베이스에서 모든 개체 수의 합계는 2,147,483,647을 초과할 수 없습니다. SQL Server 데이터베이스 엔진의 제한 사항을 참조하세요. |
| 최대 식별자 길이(문자 수) | 128. SQL Server 데이터베이스 엔진의 제한 사항을 참조하세요. |
| 최대 쿼리 기간 | 30분 |
| 결과 집합의 최대 크기 | 동시 쿼리 간 최대 400GB 공유 |
| 최대 동시성 | 제한되지 않으며 쿼리 복잡성 및 검색된 데이터의 양에 따라 달라집니다. 하나의 서버리스 SQL 풀은 간단한 쿼리를 실행하는 1000개의 활성 세션을 동시에 처리할 수 있습니다. 쿼리가 더 복잡하거나 더 많은 양의 데이터를 검색하면 숫자가 감소하므로 이 경우 동시성을 줄이고 가능한 경우 더 오랜 기간 동안 쿼리를 실행하는 것이 좋습니다. |
| 외부 테이블 이름의 최대 크기 | 100자 |
서버리스 SQL 풀에서 데이터베이스를 만들 수 없습니다.
서버리스 SQL 풀에는 제한 사항이 있으며 작업 영역당 100개 이상의 데이터베이스를 만들 수 없습니다. 개체를 분리하고 격리해야 하는 경우 스키마를 사용합니다.
CREATE DATABASE failed. User database limit has been already reached 오류가 발생하면 하나의 작업 영역에서 지원되는 최대 데이터베이스 수를 만든 것입니다.
다른 테넌트의 데이터를 격리하기 위해 별도의 데이터베이스를 사용할 필요가 없습니다. 모든 데이터는 데이터 레이크 및 Azure Cosmos DB에 외부적으로 저장됩니다. 테이블, 뷰 및 함수 정의와 같은 메타데이터는 스키마를 사용하여 성공적으로 격리할 수 있습니다. 스키마 기반 격리는 데이터베이스와 스키마가 동일한 개념을 갖는 Spark에서도 사용됩니다.