쿼리 폴딩 예제
이 문서에서는 쿼리 폴딩에 사용할 수 있는 세 가지 결과 각각에 대한 몇 가지 예제 시나리오를 제공합니다. 또한 쿼리 접기 메커니즘을 최대한 활용 하는 방법에 대 한 몇 가지 제안 및 쿼리에 있을 수 있는 효과 포함 합니다.
시나리오
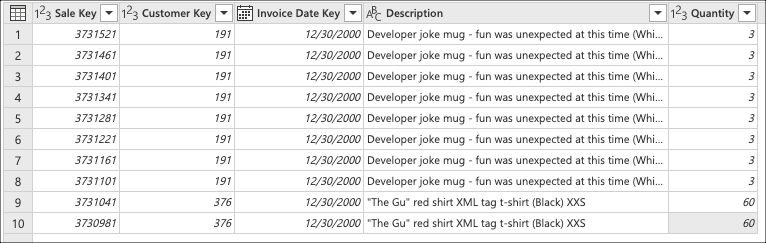
Azure Synapse Analytics SQL 데이터베이스용 Wide World Importers 데이터베이스를 사용하여 테이블에 연결하고 다음 필드만 사용하여 마지막 10개의 판매를 검색하는 fact_Sale 쿼리를 파워 쿼리에서 만드는 작업을 수행하는 시나리오를 상상해 보세요.
- 판매 키
- 고객 키
- 송장 날짜 키
- 설명
- 수량
참고 항목
데모를 위해 이 문서에서는 Wide World Importers 데이터베이스를 Azure Synapse Analytics에 로드하는 자습서에 설명된 데이터베이스를 사용합니다. 이 문서의 기본 차이점은 테이블은 fact_Sale 총 3,644,356개의 행이 있는 2000년의 데이터만 보유합니다.
결과는 Azure Synapse Analytics 설명서의 자습서에 따라 얻을 수 있는 결과와 정확히 일치하지 않을 수 있지만, 이 문서의 목표는 쿼리 폴딩이 쿼리에 미칠 수 있는 핵심 개념과 영향을 소개하는 것입니다.
이 문서에서는 서로 다른 수준의 쿼리 접기를 사용하여 동일한 출력을 달성하는 세 가지 방법을 보여 줍니다.
- 쿼리 접기 없음
- 부분 쿼리 폴딩
- 전체 쿼리 접기
쿼리 폴딩 예제 없음
Important
구조화되지 않은 데이터 원본에만 의존하거나 CSV 또는 Excel 파일과 같은 컴퓨팅 엔진이 없는 쿼리에는 쿼리 폴딩 기능이 없습니다. 즉, 파워 쿼리는 파워 쿼리 엔진을 사용하여 필요한 모든 데이터 변환을 평가합니다.
데이터베이스에 연결하고 테이블로 fact_Sale 이동한 후 홈 탭의 행 감소 그룹 내에 있는 아래쪽 행 유지 변환을 선택합니다.
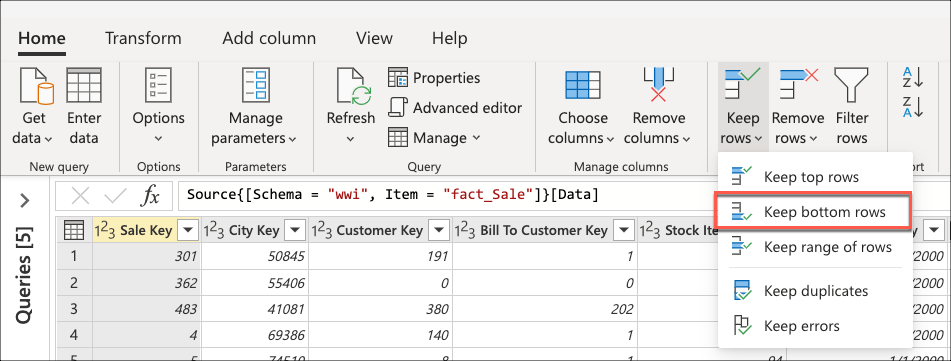
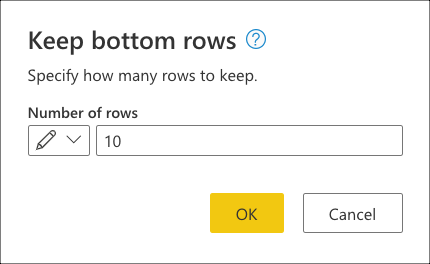
이 변환을 선택하면 새 대화 상자가 나타납니다. 이 새 대화 상자에서는 유지할 행 수를 입력할 수 있습니다. 이 경우 값 10을 입력한 다음 확인을 선택합니다.
팁
이 경우 이 작업을 수행하면 마지막 10개의 판매 결과가 생성됩니다. 대부분의 시나리오에서는 테이블에 정렬 작업을 적용하여 마지막으로 간주되는 행을 정의하는 보다 명시적인 논리를 제공하는 것이 좋습니다.
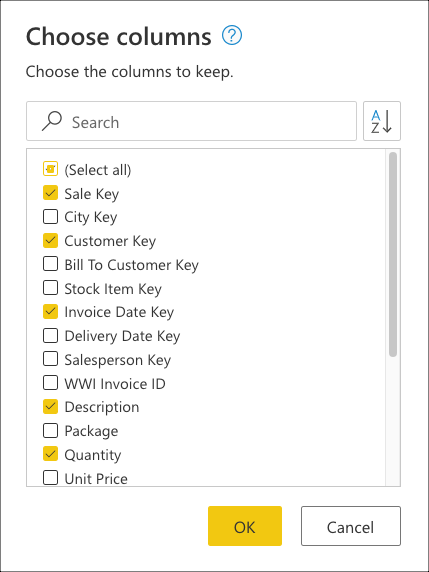
다음으로 홈 탭의 열 관리 그룹 내에 있는 열 선택 변환을 선택합니다. 그런 다음 테이블에서 유지할 열을 선택하고 나머지는 제거할 수 있습니다.
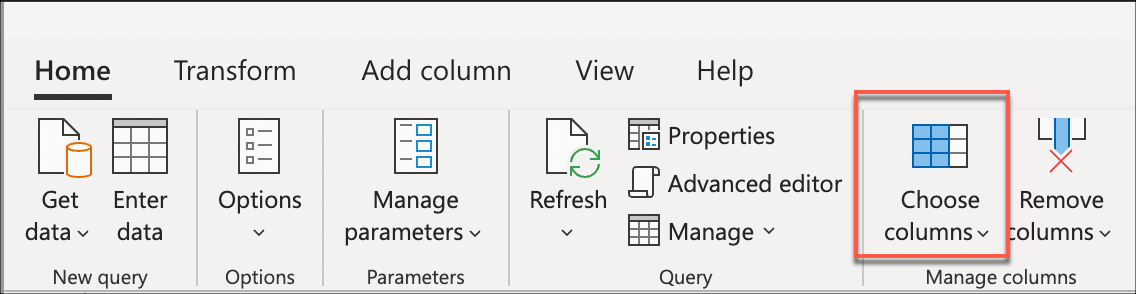
마지막으로 열 선택 대화 상자 내에서 , Customer Key, Invoice Date Key및 DescriptionQuantity 열을 선택한 Sale Key다음 확인을 선택합니다.
다음 코드 샘플은 만든 쿼리에 대한 전체 M 스크립트입니다.
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Kept bottom rows" = Table.LastN(Navigation, 10),
#"Choose columns" = Table.SelectColumns(#"Kept bottom rows", {"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"})
in
#"Choose columns""
쿼리 폴딩 없음: 쿼리 평가 이해
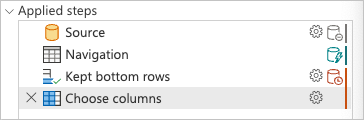
파워 쿼리 편집기에서 적용된 단계에서는 유지된 아래쪽 행 및 선택 열에 대한 쿼리 접기 표시기가 데이터 원본 외부 또는 파워 쿼리 엔진에서 평가되는 단계로 표시됩니다.
쿼리의 마지막 단계인 열 선택(Select columns)을 마우스 오른쪽 단추로 클릭하고 쿼리 계획 보기를 읽는 옵션을 선택할 수 있습니다. 쿼리 계획의 목표는 쿼리 실행 방법에 대한 자세한 보기를 제공하는 것입니다. 이 기능에 대해 자세히 알아보려면 쿼리 계획으로 이동합니다.
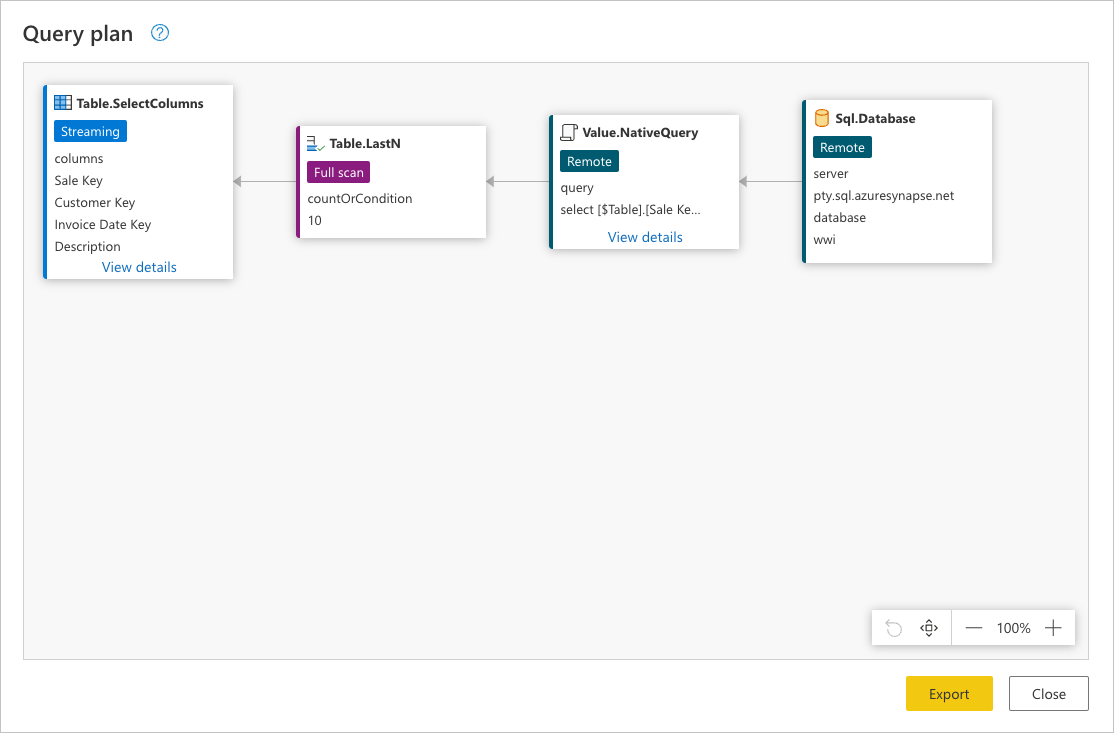
이전 이미지의 각 상자를 노드라고 합니다. 노드는 이 쿼리를 수행하기 위한 작업 분석을 나타냅니다. 위의 예제의 SQL Server 및 노드와 같은 데이터 원본을 Value.NativeQuery 나타내는 노드는 쿼리의 어느 부분이 데이터 원본에 오프로드되어 있는지를 나타냅니다. 이 경우 Table.LastN Table.SelectColumns 이전 이미지의 사각형에서 강조 표시된 나머지 노드는 파워 쿼리 엔진에 의해 평가됩니다. 이 두 노드는 추가한 두 개의 변환, 유지된 아래쪽 행 및 열 선택을 나타냅니다. 나머지 노드는 데이터 원본 수준에서 발생하는 작업을 나타냅니다.
데이터 원본으로 전송되는 정확한 요청을 보려면 노드에서 Value.NativeQuery 세부 정보 보기를 선택합니다.
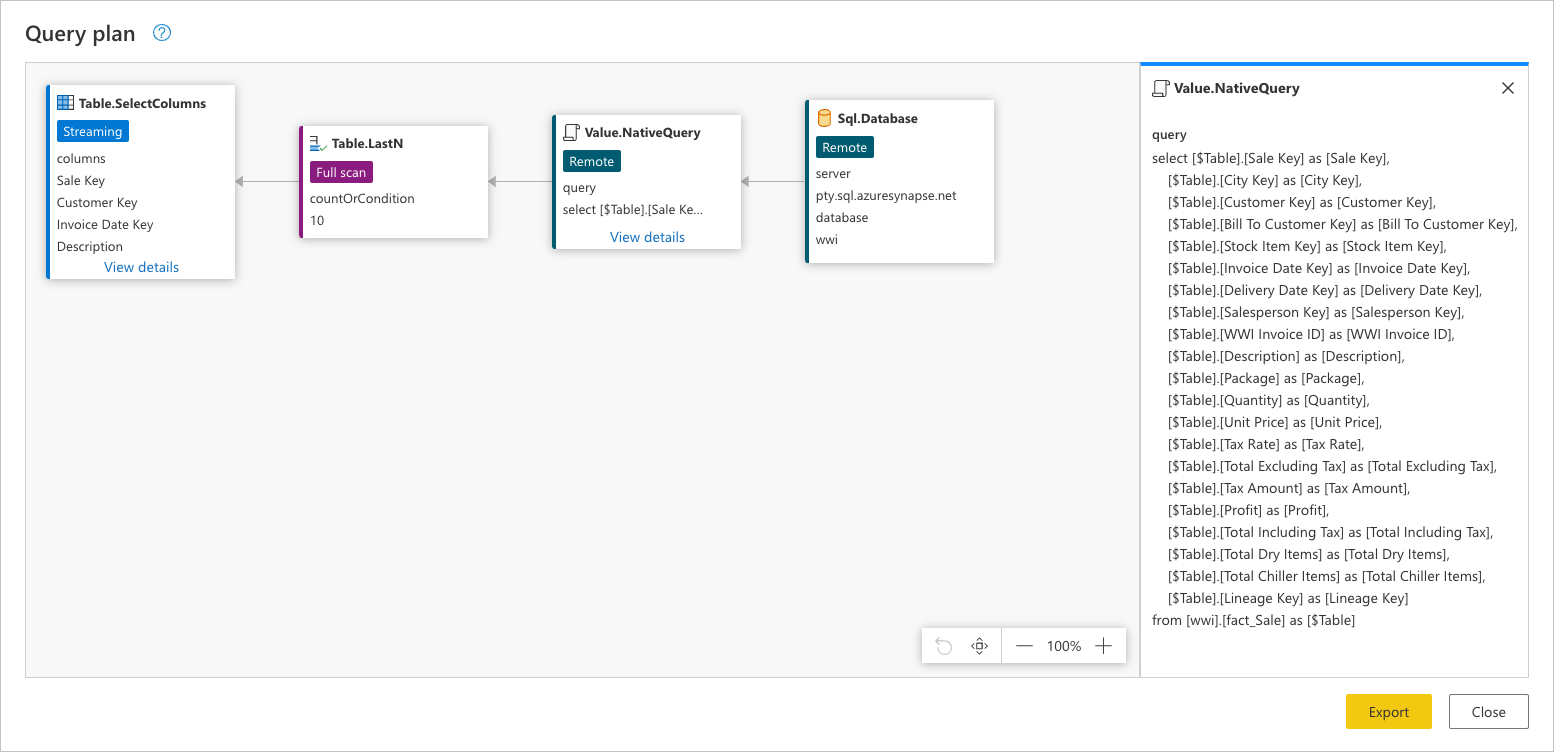
이 데이터 원본 요청은 데이터 원본의 기본 언어입니다. 이 경우 해당 언어는 SQL이고 이 문은 테이블의 모든 행과 필드에 fact_Sale 대한 요청을 나타냅니다.
이 데이터 원본 요청을 참조하면 쿼리 계획이 전달하려는 스토리를 더 잘 이해할 수 있습니다.
Sql.Database: 이 노드는 데이터 원본 액세스를 나타냅니다. 데이터베이스에 커넥트 해당 기능을 이해하기 위해 메타데이터 요청을 보냅니다.Value.NativeQuery: 쿼리를 수행하기 위해 파워 쿼리에서 생성한 요청을 나타냅니다. 파워 쿼리는 네이티브 SQL 문의 데이터 요청을 데이터 원본에 제출합니다. 이 경우 테이블의 모든 레코드와 필드(열)를fact_Sale나타냅니다. 이 시나리오에서는 테이블에 수백만 개의 행이 포함되어 있고 관심은 마지막 10개에 불과하므로 이 경우는 바람직하지 않습니다.Table.LastN: 파워 쿼리가 테이블에서 모든 레코드를fact_Sale받으면 파워 쿼리 엔진을 사용하여 테이블을 필터링하고 마지막 10개 행만 유지합니다.Table.SelectColumns: 파워 쿼리는 노드의 출력을Table.LastN사용하고 테이블에서 유지하려는 특정 열을 선택하는 새Table.SelectColumns변환을 적용합니다.
평가를 위해 이 쿼리는 테이블에서 모든 행과 필드를 다운로드해야 했습니다 fact_Sale . 이 쿼리는 Power BI 데이터 흐름의 표준 인스턴스에서 처리되는 데 평균 6분 1초가 걸렸습니다(데이터 흐름에 대한 데이터 평가 및 로드를 고려).
부분 쿼리 폴딩 예제
데이터베이스에 연결하고 테이블로 fact_Sale 이동한 후에는 테이블에서 유지할 열을 선택하여 시작합니다. 홈 탭에서 열 관리 그룹 내에 있는 열 선택 변환을 선택합니다. 이 변환을 사용하면 테이블에서 유지할 열을 명시적으로 선택하고 나머지 열을 제거할 수 있습니다.
열 선택 대화 상자에서 , Customer Key, Invoice Date Key및 Quantity Description열을 선택한 Sale Key다음 확인을 선택합니다.
이제 테이블을 정렬하여 테이블 맨 아래에 마지막 판매액을 가지는 논리를 만듭니다. 테이블의 Sale Key 기본 키 및 증분 시퀀스 또는 인덱스인 열을 선택합니다. 열의 상황에 맞는 메뉴에서 이 필드만 오름차순으로 사용하여 테이블을 정렬합니다.
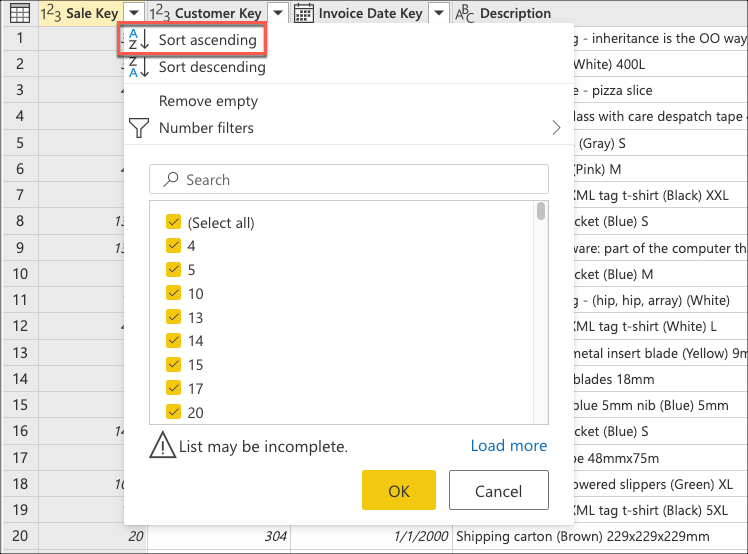
다음으로 테이블 상황에 맞는 메뉴를 선택하고 아래쪽 행 유지 변환을 선택합니다.
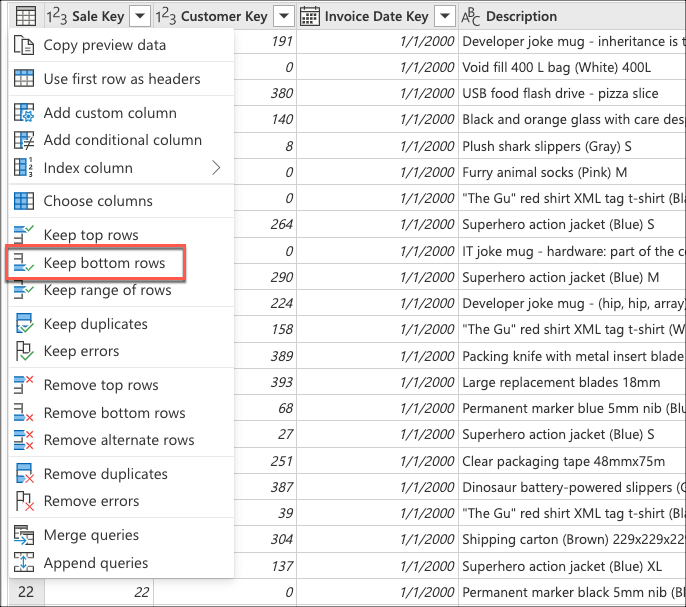
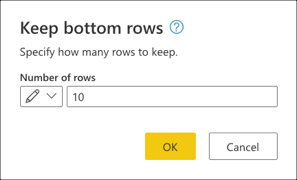
아래쪽 행 유지에서 값 10을 입력한 다음 확인을 선택합니다.
다음 코드 샘플은 만든 쿼리에 대한 전체 M 스크립트입니다.
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(Navigation, {"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Ascending}}),
#"Kept bottom rows" = Table.LastN(#"Sorted rows", 10)
in
#"Kept bottom rows"
부분 쿼리 폴딩 예제: 쿼리 평가 이해
적용된 단계 창을 확인하면 쿼리 접기 표시기에 추가 Kept bottom rows한 마지막 변환이 데이터 원본 외부 또는 파워 쿼리 엔진에서 평가되는 단계로 표시됩니다.
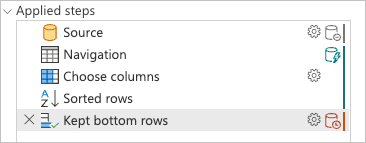
쿼리의 마지막 단계인 쿼리Kept bottom rows를 마우스 오른쪽 단추로 클릭하고 쿼리 계획 옵션을 선택하여 쿼리를 평가하는 방법을 더 잘 이해할 수 있습니다.
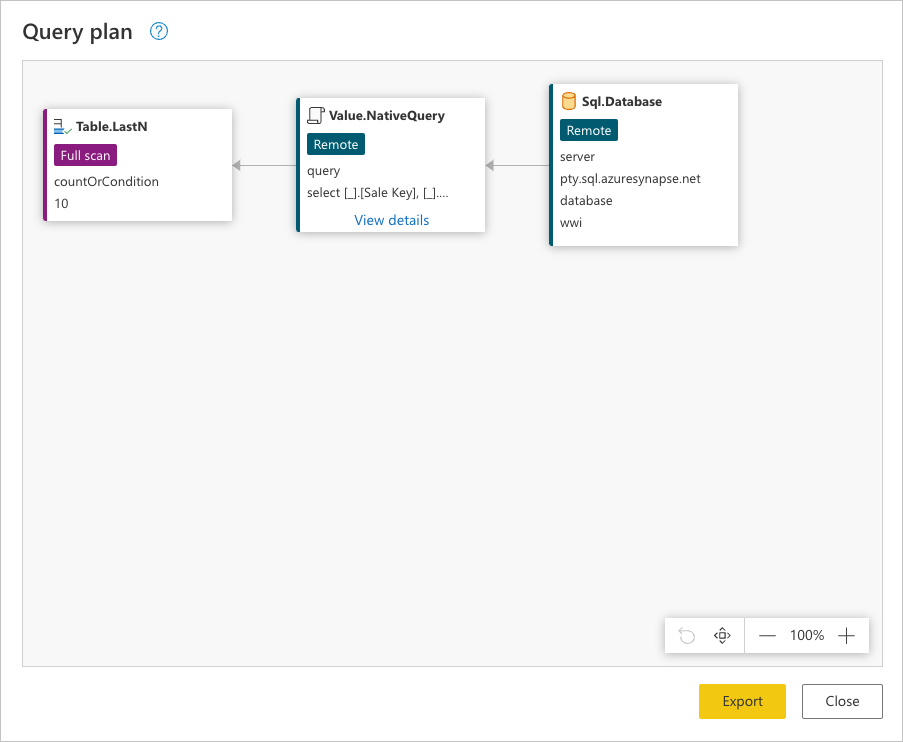
이전 이미지의 각 상자를 노드라고 합니다. 노드는 쿼리를 평가하기 위해 수행해야 하는 모든 프로세스(왼쪽에서 오른쪽)를 나타냅니다. 이러한 노드 중 일부는 데이터 원본에서 평가할 수 있으며, 유지된 하위 행 단계로 표시되는 노드와 같은 다른 노드Table.LastN는 파워 쿼리 엔진을 사용하여 평가됩니다.
데이터 원본으로 전송되는 정확한 요청을 보려면 노드에서 Value.NativeQuery 세부 정보 보기를 선택합니다.
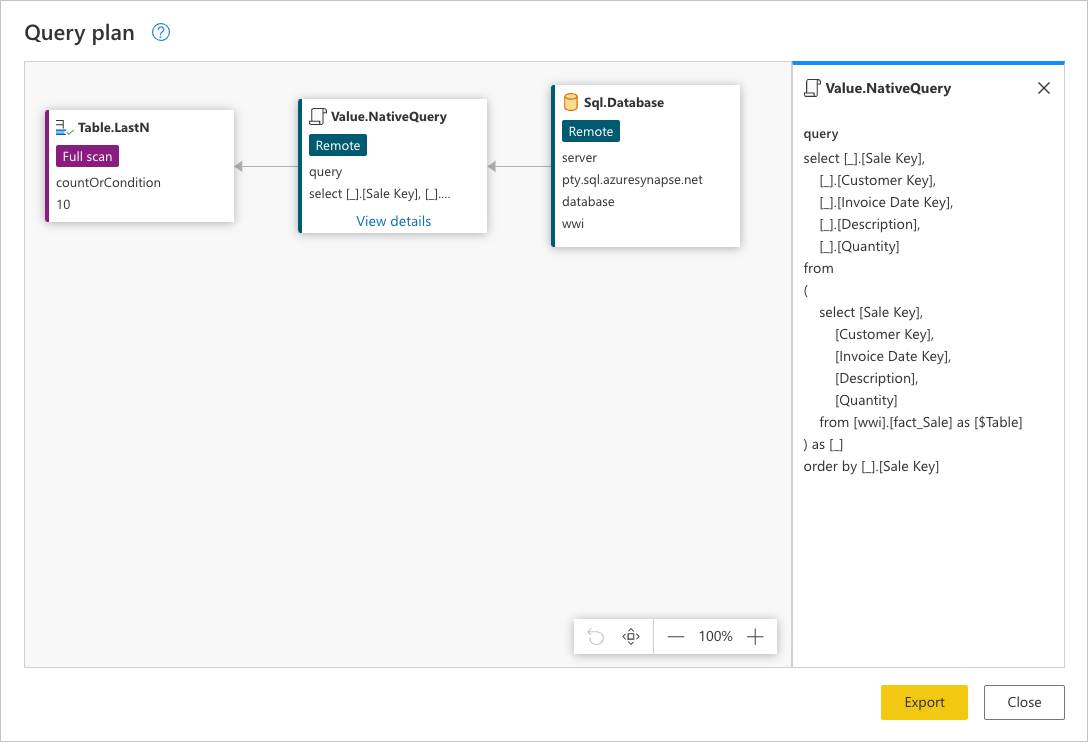
이 요청은 데이터 원본의 기본 언어로 표시됩니다. 이 경우 해당 언어는 SQL이고 이 문은 필드로 정렬된 테이블의 요청된 Sale Key 필드 fact_Sale 만 사용하여 모든 행에 대한 요청을 나타냅니다.
이 데이터 원본 요청을 참조하면 전체 쿼리 계획이 전달하려고 하는 스토리를 더 잘 이해할 수 있습니다. 노드의 순서는 데이터 원본에서 데이터를 요청하여 시작하는 순차적 프로세스입니다.
Sql.Database: 데이터베이스에 커넥트 해당 기능을 이해하기 위해 메타데이터 요청을 보냅니다.Value.NativeQuery: 쿼리를 수행하기 위해 파워 쿼리에서 생성한 요청을 나타냅니다. 파워 쿼리는 네이티브 SQL 문의 데이터 요청을 데이터 원본에 제출합니다. 이 경우 모든 레코드를 나타내며 데이터베이스의 테이블에서 요청한 필드fact_Sale만 필드별로 오름차순으로Sales Key정렬됩니다.Table.LastN: 파워 쿼리가 테이블에서 모든 레코드를fact_Sale받으면 파워 쿼리 엔진을 사용하여 테이블을 필터링하고 마지막 10개 행만 유지합니다.
평가를 위해 이 쿼리는 모든 행과 테이블에서 필요한 필드만 다운로드해야 했습니다 fact_Sale . Power BI 데이터 흐름의 표준 인스턴스에서 처리되는 데 평균 3분 4초가 걸렸습니다(데이터 흐름에 대한 데이터 평가 및 로드를 고려).
전체 쿼리 접기 예제
데이터베이스에 연결하고 테이블로 fact_Sale 이동한 후 테이블에서 유지할 열을 선택하여 시작합니다. 홈 탭에서 열 관리 그룹 내에 있는 열 선택 변환을 선택합니다. 이 변환을 사용하면 테이블에서 유지할 열을 명시적으로 선택하고 나머지 열을 제거할 수 있습니다.
열 선택에서 , , Customer KeyInvoice Date Key및 DescriptionQuantity 열을 선택한 Sale Key다음 확인을 선택합니다.
이제 테이블의 맨 위에 마지막 판매가 있도록 테이블을 정렬하는 논리를 만듭니다. 테이블의 Sale Key 기본 키 및 증분 시퀀스 또는 인덱스인 열을 선택합니다. 열의 상황에 맞는 메뉴에서 내림차순으로 이 필드를 사용하여 테이블을 정렬합니다.
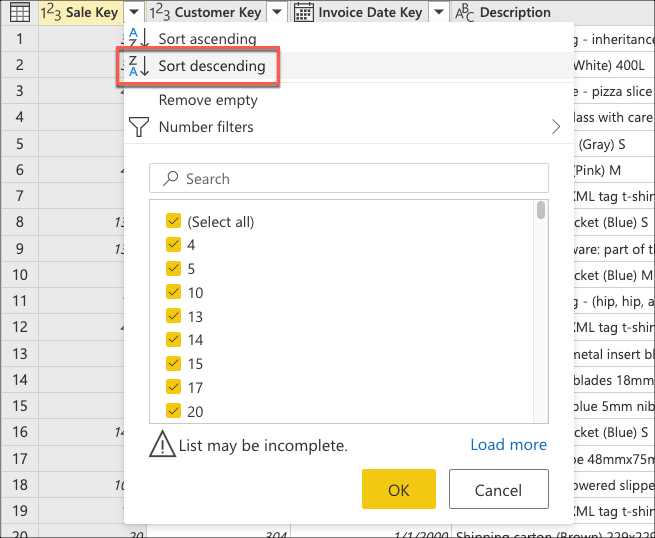
다음으로 테이블 상황에 맞는 메뉴를 선택하고 맨 위 행 유지 변환을 선택합니다.
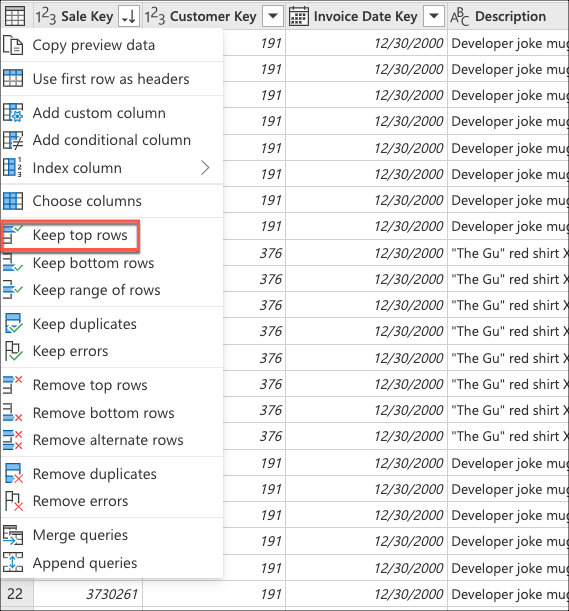
위쪽 행 유지에서 값 10을 입력한 다음 확인을 선택합니다.
다음 코드 샘플은 만든 쿼리에 대한 전체 M 스크립트입니다.
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(Navigation, {"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Descending}}),
#"Kept top rows" = Table.FirstN(#"Sorted rows", 10)
in
#"Kept top rows"
전체 쿼리 접기 예제: 쿼리 평가 이해
적용된 단계 창을 검사 때 쿼리 접기 표시기에 추가한 변환, 열 선택, 정렬된 행 및 유지된 상위 행이 데이터 원본에서 평가되는 단계로 표시됩니다.

쿼리의 마지막 단계인 최상위 행 유지를 마우스 오른쪽 단추로 클릭하고 쿼리 계획을 읽는 옵션을 선택할 수 있습니다.
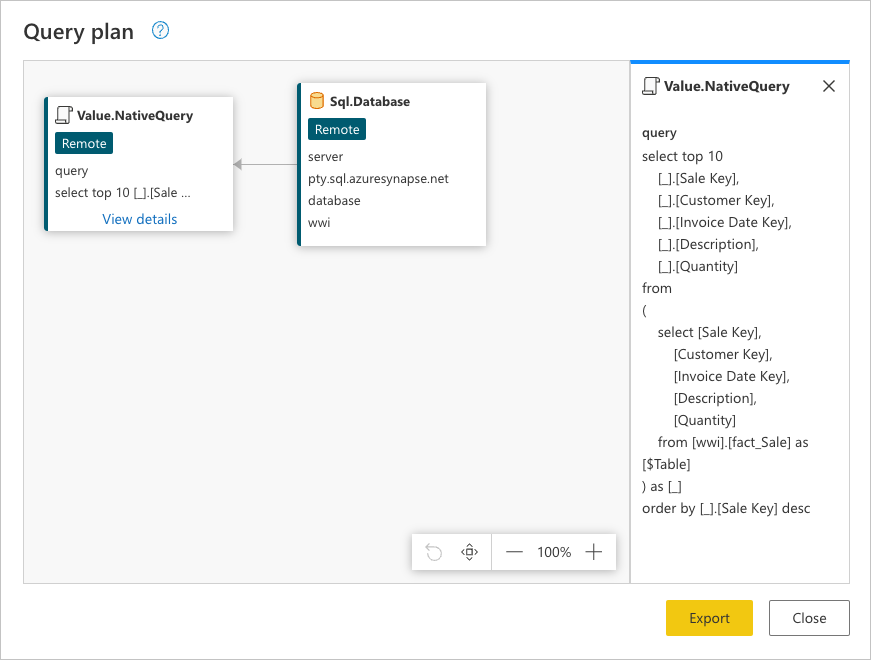
이 요청은 데이터 원본의 기본 언어로 표시됩니다. 이 경우 해당 언어는 SQL이고 이 문은 테이블의 모든 행과 필드에 fact_Sale 대한 요청을 나타냅니다.
이 데이터 원본 쿼리를 참조하면 전체 쿼리 계획이 전달하려고 하는 스토리를 더 잘 이해할 수 있습니다.
Sql.Database: 데이터베이스에 커넥트 해당 기능을 이해하기 위해 메타데이터 요청을 보냅니다.Value.NativeQuery: 쿼리를 수행하기 위해 파워 쿼리에서 생성한 요청을 나타냅니다. 파워 쿼리는 네이티브 SQL 문의 데이터 요청을 데이터 원본에 제출합니다. 이 경우 테이블의fact_Sale상위 10개 레코드에 대한 요청만 나타내며 필드를 사용하여 내림차순으로 정렬된 후에는 필수 필드만 포함Sale Key됩니다.
참고 항목
T-SQL 언어로 테이블의 아래쪽 행을 선택하는 데 사용할 수 있는 절은 없지만 테이블의 맨 위 행을 검색하는 TOP 절이 있습니다.
평가를 위해 이 쿼리는 테이블에서 요청한 fact_Sale 필드만 사용하여 10개의 행만 다운로드합니다. 이 쿼리는 Power BI 데이터 흐름의 표준 인스턴스(데이터 흐름에 대한 데이터 평가 및 로드를 고려)에서 처리되는 데 평균 31초가 걸렸습니다.
성능 비교
이러한 쿼리에서 쿼리 폴딩이 미치는 영향을 더 잘 이해하려면 쿼리를 새로 고치고, 각 쿼리를 완전히 새로 고치는 데 걸리는 시간을 기록하고, 비교할 수 있습니다. 간단히 하기 위해 이 문서에서는 서비스 수준으로 DW2000c를 사용하여 전용 Azure Synapse Analytics 환경에 연결하는 동안 Power BI 데이터 흐름 새로 고침 메커니즘을 사용하여 캡처한 평균 새로 고침 타이밍을 제공합니다.
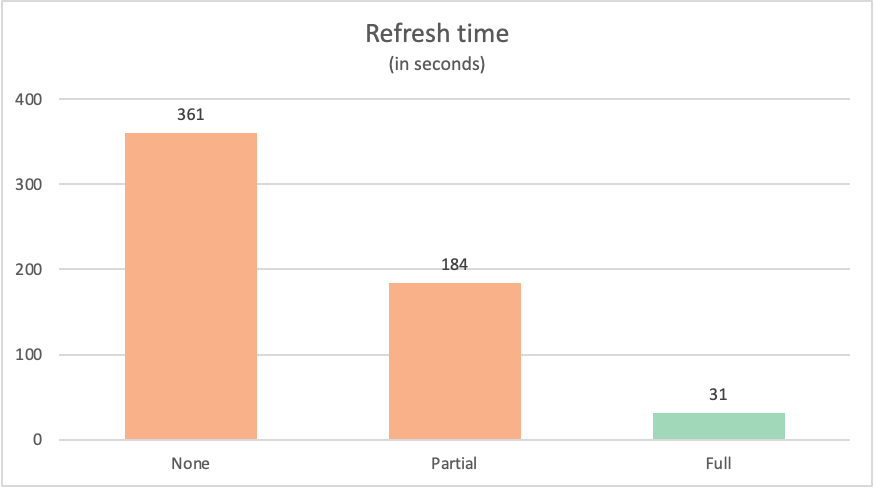
각 쿼리의 새로 고침 시간은 다음과 같습니다.
| 예시 | Label | 시간(초) |
|---|---|---|
| 쿼리 접기 없음 | None | 361 |
| 부분 쿼리 폴딩 | 부분 | 184 |
| 전체 쿼리 접기 | 전체 | 31 |
데이터 원본으로 완전히 접는 쿼리가 데이터 원본으로 완전히 접지 않는 유사한 쿼리보다 뛰어난 경우가 많습니다. 이런 경우는 여러 가지 이유가 있을 수 있습니다. 이러한 이유는 쿼리가 수행하는 변환의 복잡성부터 데이터 원본에서 구현된 쿼리 최적화(예: 인덱스, 전용 컴퓨팅 및 네트워크 리소스)에 이르기까지 다양합니다. 그러나 쿼리 폴딩이 사용하려고 시도하는 두 가지 특정 키 프로세스는 이러한 두 프로세스가 파워 쿼리에 미치는 영향을 최소화합니다.
- 전송 중 데이터
- 파워 쿼리 엔진에서 실행되는 변환
다음 섹션에서는 이러한 두 프로세스가 이전에 멘션 쿼리에 미치는 영향을 설명합니다.
전송 중 데이터
쿼리가 실행되면 첫 번째 단계 중 하나로 데이터 원본에서 데이터를 가져오려고 시도합니다. 데이터 원본에서 가져오는 데이터는 쿼리 폴딩 메커니즘에 의해 정의됩니다. 이 메커니즘은 데이터 원본으로 오프로드할 수 있는 쿼리의 단계를 식별합니다.
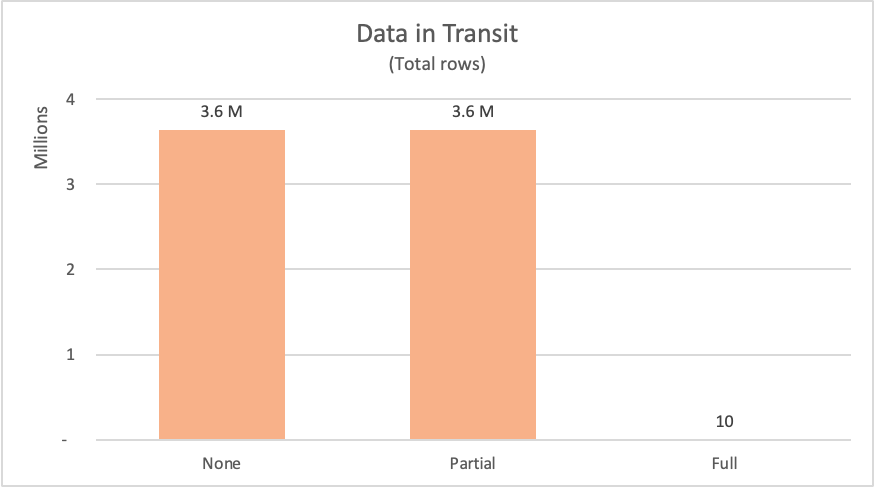
다음 표에서는 데이터베이스 테이블에서 요청 fact_Sale 된 행 수를 나열합니다. 이 테이블에는 데이터 원본에서 이러한 데이터를 요청하기 위해 전송된 SQL 문에 대한 간략한 설명도 포함되어 있습니다.
| 예시 | Label | 요청된 행 | 설명 |
|---|---|---|---|
| 쿼리 접기 없음 | None | 3644356 | 테이블의 모든 필드 및 모든 레코드에 fact_Sale 대한 요청 |
| 부분 쿼리 폴딩 | 부분 | 3644356 | 모든 레코드에 대한 요청이지만 필드별로 정렬된 후 테이블의 fact_Sale 필수 필드만 요청 Sale Key 합니다. |
| 전체 쿼리 접기 | 전체 | 10 | 필드별로 내림차순 Sale Key 으로 정렬된 후 필수 필드 및 테이블의 fact_Sale TOP 10 레코드에 대한 요청 |
데이터 원본에서 데이터를 요청할 때 데이터 원본은 요청에 대한 결과를 계산한 다음, 요청자에게 데이터를 보내야 합니다. 컴퓨팅 리소스가 이미 멘션 동안 데이터 원본에서 파워 쿼리로 데이터를 이동한 다음 파워 쿼리가 데이터를 효과적으로 수신하고 로컬에서 발생하는 변환을 준비할 수 있도록 하는 네트워크 리소스는 데이터 크기에 따라 다소 시간이 걸릴 수 있습니다.
소개된 예제의 경우 파워 쿼리는 쿼리 폴딩 없음 및 부분 쿼리 폴딩 예제를 위해 데이터 원본에서 360만 개 이상의 행을 요청해야 했습니다. 전체 쿼리 폴딩 예제의 경우 10개의 행만 요청했습니다. 요청된 필드의 경우 쿼리 폴딩 없음 예제는 테이블에서 사용 가능한 모든 필드를 요청했습니다. 부분 쿼리 폴딩과 전체 쿼리 폴딩 예제는 모두 필요한 필드에 대한 요청만 제출했습니다.
주의
많은 양의 데이터가 있는 쿼리 또는 테이블에 대한 쿼리 폴딩을 활용하는 증분 새로 고침 솔루션을 구현하는 것이 좋습니다. 파워 쿼리의 다양한 제품 통합은 장기 실행 쿼리를 종료하는 시간 제한을 구현합니다. 또한 일부 데이터 원본은 장기 실행 세션에서 시간 제한을 구현하여 서버에 대해 비용이 많이 드는 쿼리를 실행하려고 합니다. 추가 정보: 의미 체계 모델에 데이터 흐름 및 증분 새로 고침과 함께 증분 새로 고침 사용
파워 쿼리 엔진에서 실행되는 변환
이 문서에서는 쿼리 계획을 사용하여 쿼리를 평가하는 방법을 더 잘 이해할 수 있는 방법을 보여 줍니다. 쿼리 계획 내에서 파워 쿼리 엔진에서 수행할 변환 작업의 정확한 노드를 볼 수 있습니다.
다음 표에서는 파워 쿼리 엔진에서 평가한 이전 쿼리의 쿼리 계획의 노드를 보여 줍니다.
| 예시 | Label | 파워 쿼리 엔진 변환 노드 |
|---|---|---|
| 쿼리 접기 없음 | None | Table.LastN, Table.SelectColumns |
| 부분 쿼리 폴딩 | 부분 | Table.LastN |
| 전체 쿼리 접기 | 전체 | — |
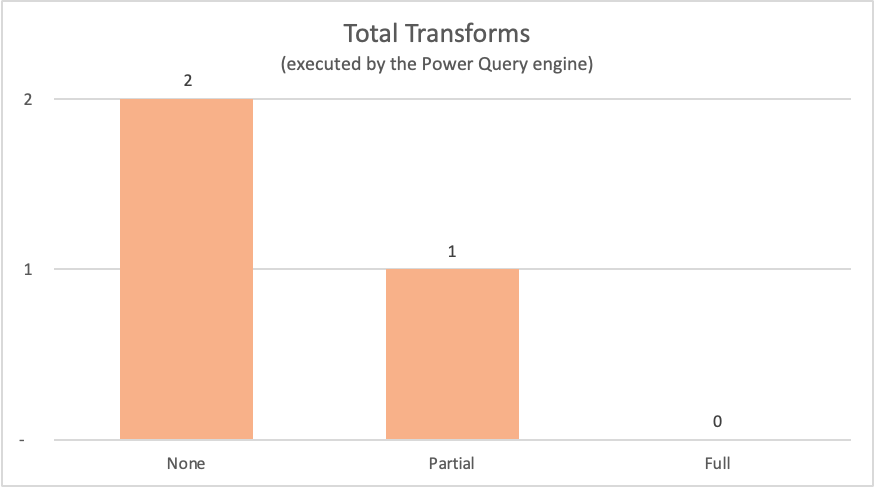
이 문서에 소개된 예제의 경우 전체 쿼리 접기 예제에서는 필요한 출력 테이블이 데이터 원본에서 직접 제공되기 때문에 파워 쿼리 엔진 내에서 변환이 수행될 필요가 없습니다. 반면, 다른 두 쿼리는 파워 쿼리 엔진에서 일부 계산이 필요했습니다. 이러한 두 쿼리에서 처리해야 하는 데이터의 양 때문에 이러한 예제에 대한 프로세스는 전체 쿼리 접기 예제보다 더 많은 시간이 걸립니다.
변환은 다음 범주로 그룹화할 수 있습니다.
| 연산자 유형 | 설명 |
|---|---|
| 원격 | 데이터 원본 노드인 연산자입니다. 이러한 연산자의 평가는 파워 쿼리 외부에서 발생합니다. |
| 스트리밍 | 연산자는 통과 연산자입니다. 예를 들어 Table.SelectRows 간단한 필터를 사용하면 일반적으로 연산자를 통과할 때 결과를 필터링할 수 있으며 데이터를 이동하기 전에 모든 행을 수집할 필요가 없습니다. Table.SelectColumns 이러한 Table.ReorderColumns 연산자의 다른 예입니다. |
| 전체 검사 | 데이터가 체인의 다음 연산자로 이동하기 전에 모든 행을 수집해야 하는 연산자입니다. 예를 들어 데이터를 정렬하려면 파워 쿼리가 모든 데이터를 수집해야 합니다. 전체 검사 연산자의 다른 예는 Table.Group, Table.NestedJoin및 Table.Pivot. |
팁
모든 변환이 성능 관점에서 동일하지는 않지만 대부분의 경우 변환 수가 적으면 일반적으로 더 좋습니다.
고려 사항 및 제안
- 파워 쿼리의 모범 사례에 설명된 대로 새 쿼리를 만들 때 모범 사례를 따릅니다.
- 쿼리 접기 표시기를 사용하여 쿼리가 폴딩되지 않도록 하는 단계를 검사. 접기를 늘리기 위해 필요한 경우 순서를 다시 지정합니다.
- 쿼리 계획을 사용하여 특정 단계에 대한 파워 쿼리 엔진에서 발생하는 변환을 결정합니다. 단계를 다시 정렬하여 기존 쿼리를 수정하는 것이 좋습니다. 그런 다음 쿼리의 마지막 단계의 쿼리 계획을 다시 검사 쿼리 계획이 이전 계획보다 더 나은지 확인합니다. 예를 들어 새 쿼리 계획에는 이전보다 적은 노드가 있으며 대부분의 노드는 "전체 검사"가 아닌 "스트리밍" 노드입니다. 접기를 지원하는 데이터 원본의 경우 쿼리 계획 이외의
Value.NativeQuery노드와 데이터 원본 액세스 노드는 접지 않은 변환을 나타냅니다. - 사용 가능한 경우 네이 티브 쿼리 보기(또는 데이터 원본 쿼리 보기) 옵션을 사용하여 쿼리를 데이터 원본으로 다시 접을 수 있는지 확인할 수 있습니다. 이 옵션을 단계에 대해 사용하지 않도록 설정하고 일반적으로 사용하도록 설정하는 원본을 사용하는 경우 쿼리 폴딩을 중지하는 단계를 만들었습니다. 이 옵션을 지원하지 않는 원본을 사용하는 경우 쿼리 접기 표시기 및 쿼리 계획을 사용할 수 있습니다.
- 쿼리 진단 도구를 사용하여 커넥터에 쿼리 폴딩 기능을 사용할 수 있을 때 데이터 원본으로 전송되는 요청을 더 잘 이해할 수 있습니다.
- 여러 커넥터를 사용하여 원본 데이터를 결합하는 경우 파워 쿼리는 각 데이터 원본에 대해 정의된 개인 정보 수준을 준수하면서 가능한 한 많은 작업을 두 데이터 원본에 푸시하려고 합니다.
- 데이터 개인 정보 방화벽 오류로부터 쿼리가 실행되는 것을 방지하려면 개인 정보 수준에 대한 문서를 읽어보세요.
- 다른 도구를 사용하여 데이터 원본에서 수신되는 요청의 관점에서 쿼리 폴딩을 검사. 이 문서의 예제에 따라 Microsoft SQL Server Profiler를 사용하여 파워 쿼리에서 보내고 Microsoft SQL Server에서 수신하는 요청을 검사 수 있습니다.
- 완전히 접힌 쿼리에 새 단계를 추가하고 새 단계도 접는 경우 파워 쿼리는 이전 결과의 캐시된 버전을 사용하는 대신 데이터 원본에 새 요청을 보낼 수 있습니다. 실제로 이 프로세스는 미리 보기에서 예상보다 새로 고치는 데 시간이 오래 걸리는 적은 양의 데이터에 대해 간단한 작업을 수행할 수 있습니다. 이 긴 새로 고침은 데이터의 로컬 복사본을 작업하는 대신 파워 쿼리가 데이터 원본을 다시 쿼리하기 때문입니다.