Koble deg til Common Data Model-tabeller i Azure Data Lake Storage
Merk
Azure Active Directory er nå Microsoft Entra ID. Finn ut mer
Inntak av data til Dynamics 365 Customer Insights - Data ved å bruke Azure Data Lake Storage-kontoen med Common Data Model-tabeller. Datainntak kan være full eller trinnvis.
Forutsetning
Azure Data Lake Storage-kontoen må ha hierarkisk navneområde aktivert. Dataene må lagres i et hierarkisk mappeformat som definerer rotmappen og har undermapper for hver tabell. Undermappene kan ha fullstendige data eller trinnvise datamapper.
Når du skal godkjenne med en Microsoft Entra-tjenestekontohaver, må den være konfigurert i leieren. Hvis du vil ha mer informasjon, kan du se Koble til en Azure Data Lake Storage-konto med en Microsoft Entra-tjenestekontohaver.
Hvis du vil koble til en lagringsplass som er beskyttet av brannmurer, kan du konfigurere private Azure-koblinger.
Hvis datasjøen for øyeblikket har tilkoblinger av typen privat kobling, må Customer Insights - Data også kobles til ved hjelp av en privat kobling, uavhengig av innstillingen for nettverkstilgang.
Azure Data Lake Storage du vil koble til og ta inn data fra, må være i samme Azure-område som Dynamics 365 Customer Insights-miljøet og abonnementene må være i samme leier. Tilkoblinger til en Common Data Model-mappe fra en Data Lake-forekomst i et annet Azure-område støttes ikke. For å finne ut Azure-området for miljøet går du til Innstillinger>System>Om i Customer Insights - Data.
Data som er lagret i onlinetjenester, kan lagres på en annen plassering enn der data behandles eller lagres. Ved å importere eller koble til data som er lagret i en onlinetjeneste, godtar du at dataene kan overføres. Finn ut mer om Microsofts Klareringssenter.
Customer Insights - Data-tjenestekontohaveren må være i en av følgende roller for å få tilgang til lagringskontoen. Hvis du vil ha mer informasjon, kan du se Gi tillatelser til tjenestekontohaveren for å få tilgang til lagringskontoen.
- Storage Blob-dataleser
- Storage Blob-dataeier
- Storage Blob-databidragsyter
Når du kobler til Azure Storage ved å bruke alternativet Azure-abonnement, må brukeren som konfigurerer datakildetilkoblingen, minst ha tillatelser av typen Storage Blob-databidragsyter på lagringskontoen.
Når du kobler til Azure Storage ved å bruke alternativet Azure-ressurs, må brukeren som konfigurerer datakildetilkoblingen, minst ha tillatelsen for handlingen Microsoft.Storage/storageAccounts/read på lagringskontoen. En innebygd Azure-rolle som omfatter denne handlingen, er Leser-rollen. Du kan begrense tilgang til bare den nødvendige handlingen, ved å opprette en egendefinert Azure-rolle som bare omfatter denne handlingen.
For å få best mulig ytelse bør størrelsen på en partisjon være 1 GB eller mindre, og antallet partisjonsfiler i en mappe må ikke overskride 1000.
Data i Data Lake Storage skal følge Common Data Model-standarden for lagring av dataene og ha Common Data Model-manifestet for å representere skjemaet for datafilene (*.csv eller *.parquet). Manifestet må gi detaljene for tabellene, for eksempel tabellkolonner og datatyper, og datafilplasseringen og filtypen. Hvis du vil ha mer informasjon, kan du se Common Data Model-manifestet. Hvis manifestet ikke finnes, kan administratorbrukere med tilgang for Storage Blob-dataeier eller Storage Blob-databidragsyter angi skjemaet ved inntak av dataene.
Merk
Hvis noen av feltene i .parquet-filene har datatypen Int96, kan det hende at dataene ikke vises på Tabeller-siden. Vi anbefaler at du bruker standarddatatyper, for eksempel tidsstempelformatet Unix (som representerer tiden som antall sekunder siden 1. januar 1970 ved midnatt UTC).
Begrensninger
- Customer Insights - Data støtter ikke kolonner av desimaltypen med en større presisjon enn 16.
Koble til Azure Data Lake Storage
Datatilkoblingsnavn, databaner, for eksempel mapper i en beholder, og tabellnavn må bruke navn som begynner med en bokstav. Navn kan bare inneholde bokstaver, tall og understrekingstegn (_). Spesialtegn støttes ikke.
Gå til Data>Datakilder.
Velg Legg til en datakilde.
Velg Azure Data Lake Common Data Model-tabeller.

Angi et datakildenavn og en valgfri beskrivelse. Navnet henvises til i nedstrømsprosesser, og det er ikke mulig å endre det etter at datakilden er opprettet.
Velg et av følgende alternativer for Koble til lagringen ved hjelp av. Hvis du vil ha mer informasjon, kan du se Koble til en Azure Data Lake Storage-konto med en Microsoft Entra-tjenestekontohaver.
- Azure-ressurs: Angi Ressurs-ID.
- Azure-abonnement: Velg abonnementet og deretter ressursgruppen og lagringskontoen.
Merk
Du må ha en av følgende roller i beholderen for å kunne opprette datakilden:
- Storage Blob Data-leser er tilstrekkelig for å lese fra en lagringskonto og registrere dataene i Customer Insights - Data.
- Storage Blob Data-bidragsyter eller Eier er nødvendig hvis du vil redigere manifestfilene direkte i Customer Insights - Data.
Når du har rollen på lagringskontoen, får du den samme rollen i alle beholderne for den.
Velg navnet på beholderen som inneholder dataene og skjemaet (model.json- eller manifest.json-fil) du vil importere data fra.
Merk
En model.json- eller manifest.json-fil som er tilknyttet en annen datakilde i miljøet, vises ikke i listen. Den samme model.json- eller manifest.json-filen kan imidlertid brukes for datakilder i flere miljøer.
Hvis du eventuelt vil legge inn data fra en lagringskonto via en Azure Private Link, velger du Aktiver privat kobling. Hvis du vil ha mer informasjon, kan du gå til Private koblinger.
Hvis du vil opprette et nytt skjema, går du til Opprett en ny skjemafil.
Hvis du vil bruke et eksisterende skjema, navigerer du til mappen som inneholder filen model.json eller manifest.cdm.json. Du kan søke i en katalog for å finne filen.
Velg JSON-filen og deretter Neste. Det vises en liste over tilgjengelige tabeller.
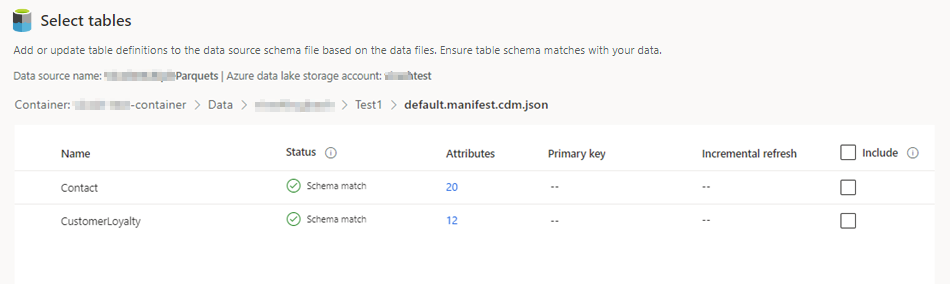
Velg tabellene du vil inkludere.
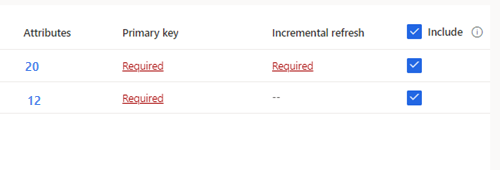
Tips
Hvis du vil redigere en tabell i et JSON-redigeringsgrensesnitt, velger du tabellen og deretter Rediger skjemafil. Foreta endringene og velg Lagre.
For valgte tabeller der en primærnøkkel ikke er definert, vises Obligatorisk under Primærnøkkel. For hver av disse tabellene:
- Velg Obligatorisk. Panelet Rediger tabell vises.
- Velg primærnøkkelen. Primærnøkkelen er et attributt som er unikt for tabellen. For at et attributt skal være en gyldig primærnøkkel, bør den ikke inneholde duplikate verdier, manglende verdier eller nullverdier. Datatypeattributtene streng, heltall og GUID støttes som primærnøkler.
- Du kan eventuelt endre partisjonsmønsteret.
- Velg Lukk for å lagre lukke panelet.
Velg antall kolonner for hver inkluderte tabell. Siden Administrer attributter vises.
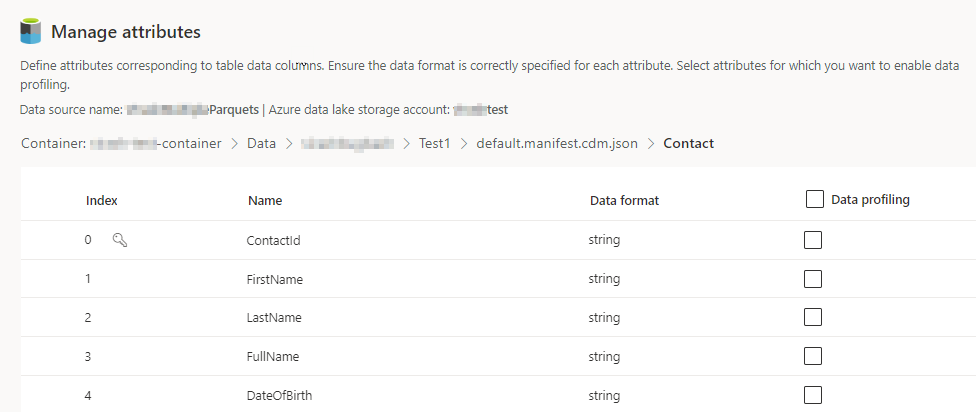
- Opprett nye kolonner, rediger eller slett eksisterende kolonner. Du kan endre navnet, dataformatet eller legge til en semantisk type.
- Hvis du vil aktivere analyse og andre funksjoner, velger du Dataprofilering for hele tabellen eller for bestemte kolonner. Som standard er ingen tabeller aktivert for dataprofilering.
- Velg Ferdig.
Velg Lagre. Siden Datakilder åpnes med den nye datakilde i statusen Oppdaterer.
Tips
Det finnes statuser for oppgaver og prosesser. De fleste prosesser avhenger av andre oppstrømsprosesser, for eksempel datakilder og oppdatering av dataprofilering.
Velg statusen for å åpne Fremdriftsdetaljer-ruten og vise fremgangen for oppgaver. Hvis du vil avbryte jobben, velger du Avbryt jobb nederst i ruten.
Under hver oppgave kan du velge Se detaljer for mer fremdriftsinformasjon, for eksempel behandlingstid, siste behandlingsdato og eventuelle relevante feil og advarsler som er tilknyttet oppgaven eller prosessen. Velg Vis systemstatus nederst i panelet for å vise andre prosesser i systemet.

Det kan ta tid å laste inn data. Etter en vellykket oppdatering kan de innhentede dataene gjennomgås fra Tabeller-siden.
Opprett en ny skjemafil
Velg Opprett skjemafil.
Skriv inn et navn for filen, og velg deretter Lagre.
Velg Ny tabell. Panelet Ny tabell vises.
Skriv inn tabellnavnet, og velg Plassering av datafiler.
- Flere .csv- eller .parquet-filer: Bla til rotmappen, velg mønstertypen og angi uttrykket.
- Enkle .csv- eller .parquet-filer: Bla til .csv- eller .parquet-filen, og velg den.
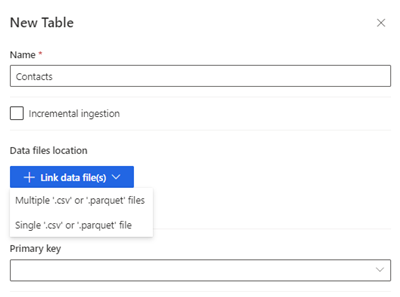
Velg Lagre.
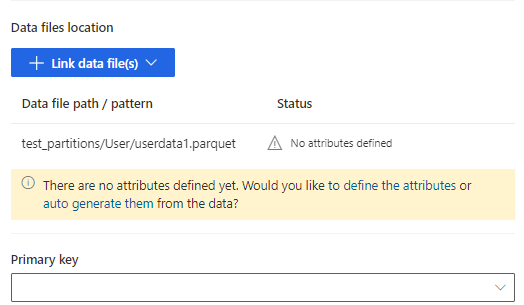
Velg Definer attributtene for manuelt å legge til attributtene, eller velg Generer dem automatisk. Hvis du vil definere attributtene, angir du et navn, velger dataformatet og den valgfrie semantiske typen. For automatisk genererte attributter:
Når attributtene er generert automatisk, velger du Se gjennom attributter. Siden Administrer attributter vises.
Kontroller at dataformatet er riktig for hvert attributt.
Hvis du vil aktivere analyse og andre funksjoner, velger du Dataprofilering for hele tabellen eller for bestemte kolonner. Som standard er ingen tabeller aktivert for dataprofilering.
Velg Ferdig. Siden Velg tabeller vises.
Fortsett for å legge til tabell og kolonner hvis aktuelt.
Når alle tabellene er lagt til, velger du Inkluder for å inkludere tabellene i datakildeinntaket.
For valgte tabeller der en primærnøkkel ikke er definert, vises Obligatorisk under Primærnøkkel. For hver av disse tabellene:
- Velg Obligatorisk. Panelet Rediger tabell vises.
- Velg primærnøkkelen. Primærnøkkelen er et attributt som er unikt for tabellen. For at et attributt skal være en gyldig primærnøkkel, bør den ikke inneholde duplikate verdier, manglende verdier eller nullverdier. Datatypeattributtene streng, heltall og GUID støttes som primærnøkler.
- Du kan eventuelt endre partisjonsmønsteret.
- Velg Lukk for å lagre lukke panelet.
Velg Lagre. Siden Datakilder åpnes med den nye datakilde i statusen Oppdaterer.
Tips
Det finnes statuser for oppgaver og prosesser. De fleste prosesser avhenger av andre oppstrømsprosesser, for eksempel datakilder og oppdatering av dataprofilering.
Velg statusen for å åpne Fremdriftsdetaljer-ruten og vise fremgangen for oppgaver. Hvis du vil avbryte jobben, velger du Avbryt jobb nederst i ruten.
Under hver oppgave kan du velge Se detaljer for mer fremdriftsinformasjon, for eksempel behandlingstid, siste behandlingsdato og eventuelle relevante feil og advarsler som er tilknyttet oppgaven eller prosessen. Velg Vis systemstatus nederst i panelet for å vise andre prosesser i systemet.
Det kan ta tid å laste inn data. Etter en vellykket oppdatering kan de innhentede dataene gjennomgås fra siden Data>Tabeller.
Rediger en Azure Data Lake Storage-datakilde
Du kan oppdatere alternativet Koble til lagringskonto ved hjelp av. Hvis du vil ha mer informasjon, kan du se Koble til en Azure Data Lake Storage-konto med en Microsoft Entra-tjenestekontohaver. Hvis du vil koble til en annen beholder fra lagringskontoen, eller endre navnet på forretningsforbindelsen, må du opprette en ny datakilde-tilkobling.
Gå til Data>Datakilder. Ved siden av datakilde du vil oppdatere, velger du Rediger.
Endre eventuelt følgende informasjon:
Bekrivelse
Koble til lagringen ved hjelp av og tilkoblingsinformasjon. Du kan ikke endre informasjon om en beholder når du oppdaterer tilkoblingen.
Merk
En av følgende roller må være tildelt til lagringskontoen eller beholderen:
- Storage Blob-dataleser
- Storage Blob-dataeier
- Storage Blob-databidragsyter
Aktiver privat kobling hvis du eventuelt vil legge inn data fra en lagringskonto via en Azure Private Link. Hvis du vil ha mer informasjon, kan du gå til Private koblinger.
Velg Neste.
Endre eventuelt følgende:
Naviger til en annen model.json- eller manifest.json-fil med et annet sett med tabeller fra beholderen.
Hvis du vil legge til flere tabeller i inntaket, velger du Ny tabell.
Hvis du vil fjerne alle allerede valgte tabeller og det ikke finnes avhengigheter, velger du tabellen og Slett.
Viktig
Hvis det finnes avhengigheter i den eksisterende model.json- eller manifest.json-filen og tabellene, vises en feilmelding og du kan ikke velge en annen model.json- eller manifest.json-fil. Fjern avhengighetene før du endrer model.json- eller manifest.json-filen, eller opprett en ny datakilde med model.json- eller manifest.json-filen som du vil bruke for å unngå å fjerne avhengighetene.
Hvis du vil endre datafilplasseringen eller primærnøkkelen, velger du Rediger.
Endre bare tabellnavnet slik at det er likt tabellnavnet i JSON-filen.
Merk
Behold alltid tabellnavnet i det samme som tabellnavnet i filen model.json eller manifest.json etter inntak. Customer Insights - Data validerer alle tabellnavn med model.json eller manifest.json under hver systemoppdatering. Hvis et tabellnavn endres, oppstår det en feil fordi Customer Insights - Data ikke finner det nye tabellnavnet i JSON-filen. Hvis et integrert tabellnavn ble endret ved et uhell, redigerer du tabellnavnet slik at det samsvarer med navnet i JSON-filen.
Velg Kolonner for å legge til eller endre dem, eller for å aktivere dataprofilering. Deretter velger du Ferdig.
VelgLagre for å ta i bruk endringene, og gå tilbake til siden Datakilder.
Tips
Det finnes statuser for oppgaver og prosesser. De fleste prosesser avhenger av andre oppstrømsprosesser, for eksempel datakilder og oppdatering av dataprofilering.
Velg statusen for å åpne Fremdriftsdetaljer-ruten og vise fremgangen for oppgaver. Hvis du vil avbryte jobben, velger du Avbryt jobb nederst i ruten.
Under hver oppgave kan du velge Se detaljer for mer fremdriftsinformasjon, for eksempel behandlingstid, siste behandlingsdato og eventuelle relevante feil og advarsler som er tilknyttet oppgaven eller prosessen. Velg Vis systemstatus nederst i panelet for å vise andre prosesser i systemet.