Lakehouse ende-til-ende scenario: oversikt og arkitektur
Microsoft Fabric er en alt-i-ett-analyseløsning for bedrifter som dekker alt fra databevegelse til datavitenskap, sanntidsanalyse og forretningsintelligens. Det tilbyr en omfattende pakke med tjenester, inkludert datainnsjø, datateknikk og dataintegrering, alt på ett sted. Hvis du vil ha mer informasjon, kan du se Hva er Microsoft Fabric?
Denne opplæringen veileder deg gjennom et ende-til-ende-scenario fra datainnsamling til dataforbruk. Det hjelper deg med å bygge en grunnleggende forståelse av Fabric, inkludert de ulike opplevelsene og hvordan de integreres, samt de profesjonelle og borgerutvikleropplevelsene som følger med å jobbe på denne plattformen. Denne opplæringen er ikke ment å være en referansearkitektur, en omfattende liste over funksjoner og funksjonalitet, eller en anbefaling av spesifikke anbefalte fremgangsmåter.
Lakehouse ende-til-ende scenario
Tradisjonelt har organisasjoner bygget moderne datalagre for sine transaksjonsmessige og strukturerte dataanalysebehov. Og data lakehouses for big data (semi/unstructured) data analytics behov. Disse to systemene kjørte parallelt, noe som skapte siloer, dataduplisering og økte totale eierkostnader.
Stoff med sin samling av datalager og standardisering på Delta Lake-format lar deg eliminere siloer, fjerne dataduplisering og drastisk redusere totale eierkostnader.
Med fleksibiliteten som tilbys av Fabric, kan du implementere enten lakehouse- eller datalagerarkitekturer eller kombinere dem sammen for å få det beste fra begge deler med enkel implementering. I denne opplæringen skal du ta et eksempel på en detaljhandelsorganisasjon og bygge lakehouse fra start til slutt. Den bruker medaljongarkitekturen der bronselaget har rådataene, sølvlaget har de validerte og deduplicerte dataene, og gulllaget har svært raffinerte data. Du kan ta samme tilnærming til å implementere et lakehouse for enhver organisasjon fra enhver bransje.
Denne opplæringen forklarer hvordan en utvikler hos det fiktive firmaet Wide World Importers fra detaljhandeldomenet fullfører følgende trinn:
Logg på Power BI-kontoen din, og registrer deg for den gratis prøveversjonen av Microsoft Fabric. Hvis du ikke har en Power BI-lisens, kan du registrere deg for en gratis Lisens for Power BI, og deretter kan du starte stoffprøveperioden.
Bygg og implementer et ende-til-ende lakehouse for organisasjonen:
- Opprett et stoffarbeidsområde.
- Lag et innsjøhus.
- Innta data, transformere data og laste dem inn i lakehouse. Du kan også utforske OneLake, én kopi av dataene på tvers av lakehouse-modus og SQL Analytics-endepunktmodus.
- Koble til lakehouse ved hjelp av SQL Analytics-endepunktet og Opprett en Power BI-rapport ved hjelp av DirectLake for å analysere salgsdata på tvers av ulike dimensjoner.
- Du kan eventuelt organisere og planlegge datainntak og transformasjonsflyt med et datasamlebånd.
Rydd opp i ressurser ved å slette arbeidsområdet og andre elementer.
Arkitektur
Bildet nedenfor viser lakehouse ende-til-ende arkitektur. Komponentene som er involvert, er beskrevet i listen nedenfor.
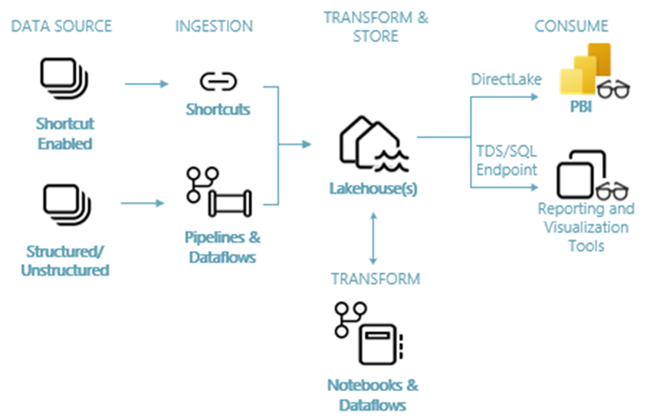
Datakilder: Fabric gjør det raskt og enkelt å koble til Azure Data Services, i tillegg til andre skybaserte plattformer og lokale datakilder, for strømlinjeformet datainntak.
Inntak: Du kan raskt bygge innsikt for organisasjonen ved hjelp av mer enn 200 opprinnelige koblinger. Disse koblingene er integrert i Fabric-datasamlebåndet og bruker den brukervennlige dra-og-slipp-datatransformasjonen med dataflyt. I tillegg, med snarveisfunksjonen i Fabric, kan du koble til eksisterende data, uten å måtte kopiere eller flytte den.
Transformer og lagre: Stoff standardiseres på Delta Lake-format. Som betyr at alle Fabric-motorene kan få tilgang til og manipulere det samme datasettet som er lagret i OneLake uten å duplisere data. Dette lagringssystemet gir fleksibilitet til å bygge innsjøer ved hjelp av en medaljongarkitektur eller et datanett, avhengig av organisasjonens krav. Du kan velge mellom en lavkode- eller no-code-opplevelse for datatransformasjon, ved hjelp av datasamlebånd/dataflyter eller notatblokk/Spark for en kode-første opplevelse.
Forbruk: Power BI kan bruke data fra Lakehouse for rapportering og visualisering. Hver Lakehouse har et innebygd TDS-endepunkt kalt SQL Analytics-endepunktet for enkel tilkobling og spørring av data i Lakehouse-tabellene fra andre rapporteringsverktøy. Sql Analytics-endepunktet gir brukere sql-tilkoblingsfunksjonaliteten.
Eksempeldatasett
Denne opplæringen bruker eksempeldatabasen Wide World Importers (WWI), som du importerer til lakehouse i neste opplæring. For lakehouse ende-til-ende-scenarioet har vi generert tilstrekkelige data til å utforske skalaen og ytelsesegenskapene til Fabric-plattformen.
Wide World Importers (WWI) er en engros nyhet varer importør og distributør opererer fra San Francisco Bay området. Som grossist inkluderer WWI kunder for det meste selskaper som videreselger til enkeltpersoner. WWI selger til detaljhandel kunder over hele USA inkludert spesialitet butikker, supermarkeder, databehandling butikker, turistattraksjon butikker, og noen individer. WWI selger også til andre grossister via et nettverk av agenter som markedsfører produktene på WWI vegne. Hvis du vil ha mer informasjon om firmaets profil og drift, kan du se eksempeldatabaser for Wide World Importers for Microsoft SQL.
Generelt hentes data fra transaksjonssystemer eller bransjeprogrammer inn i et innsjøhus. For enkelhets skyld i denne opplæringen bruker vi imidlertid den dimensjonale modellen som leveres av WWI som vår opprinnelige datakilde. Vi bruker den som kilde til å innta dataene til et innsjøhus og forvandle dem gjennom ulike stadier (bronse, sølv og gull) av en medaljongarkitektur.
Datamodell
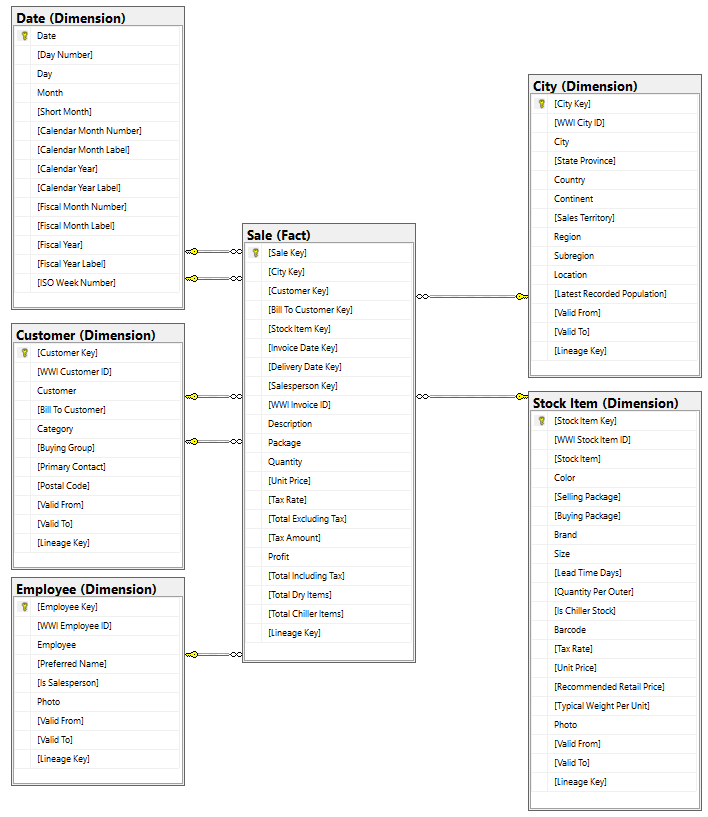
Selv om den wWI-dimensjonale modellen inneholder mange faktatabeller, bruker vi faktatabellen Salg og dens korrelerte dimensjoner for denne opplæringen. Følgende eksempel illustrerer datamodellen for første verdenskrig:
Data- og transformasjonsflyt
Som beskrevet tidligere bruker vi eksempeldataene fra WWI-eksempeldata (Wide World Importers) til å bygge dette ende-til-ende lakehouse. I denne implementeringen lagres eksempeldataene i en Azure Data Storage-konto i Parquet-filformat for alle tabellene. Men i virkelige scenarier kommer data vanligvis fra ulike kilder og i ulike formater.
Følgende bilde viser kilden, målet og datatransformasjonen:
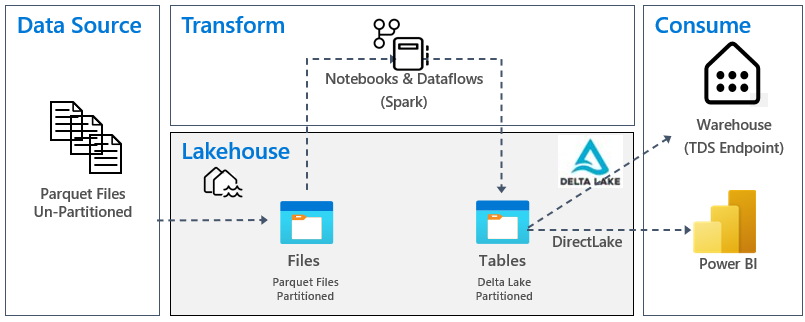
Datakilde: Kildedataene er i Parquet-filformat og i en upartisjonert struktur. Den lagres i en mappe for hver tabell. I denne opplæringen satte vi opp et datasamlebånd for å innta fullstendige historiske data eller engangsdata til lakehouse.
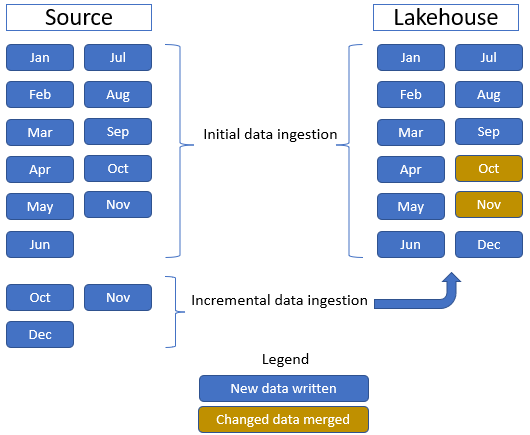
I denne opplæringen bruker vi faktatabellen Salg , som har én overordnet mappe med historiske data i 11 måneder (med én undermappe for hver måned) og en annen mappe som inneholder trinnvise data i tre måneder (én undermappe for hver måned). Under den første datainntaken blir 11 måneder med data inntatt i lakehouse-tabellen. Når de trinnvise dataene kommer, inkluderer de imidlertid oppdaterte data for oktober og november, og nye data for desember. Okt- og november-data slås sammen med eksisterende data, og de nye desemberdataene skrives inn i lakehouse-tabellen som vist på følgende bilde:
Lakehouse: I denne opplæringen oppretter du et lakehouse, inntar data i fildelen av lakehouse, og deretter oppretter du delta lake tabeller i Tabeller-delen av lakehouse.
Transformer: Hvis du vil ha dataforberedelse og transformasjon, ser du to ulike tilnærminger. Vi demonstrerer bruken av notatblokker/Spark for brukere som foretrekker en kode-først-opplevelse og bruker datasamlebånd/dataflyt for brukere som foretrekker en lavkode- eller no-code-opplevelse.
Bruk: Hvis du vil demonstrere dataforbruk, kan du se hvordan du kan bruke DirectLake-funksjonen i Power BI til å opprette rapporter, instrumentbord og direkte spørre etter data fra lakehouse. I tillegg demonstrerer vi hvordan du kan gjøre dataene tilgjengelige for tredjeparts rapporteringsverktøy ved hjelp av TDS/SQL Analytics-endepunktet. Dette endepunktet lar deg koble til lageret og kjøre SQL-spørringer for analyse.