Scripts pré-pós aprimorados para instantâneo consistente do banco de dados
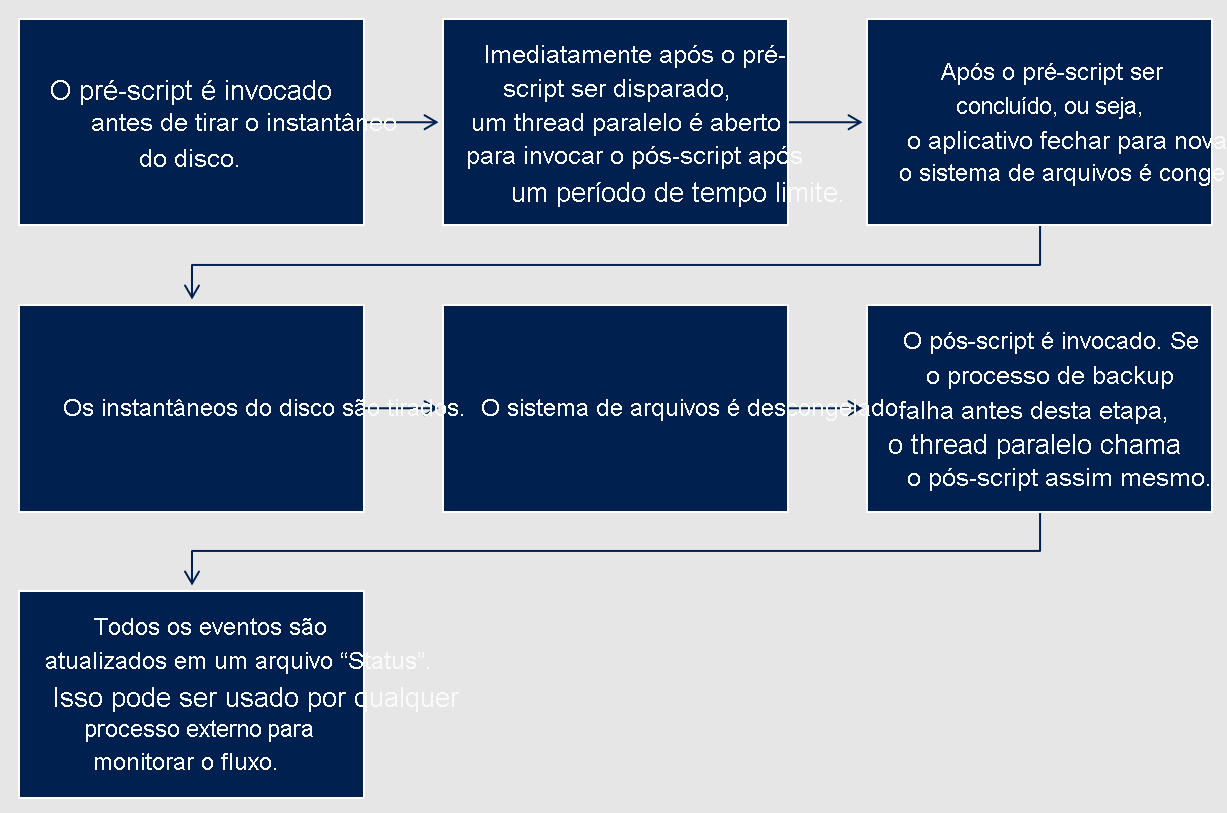
O serviço de Backup do Azure já fornece uma estrutura de script pré-pós para obter consistência de aplicativo em VMs do Linux usando o Backup do Azure. Este processo envolve invocar um pré-script (para cancelar os aplicativos) antes de obter um instantâneo de discos e chamar o pós-script (comandos para descongelar os aplicativos) depois que o instantâneo for concluído para retornar os aplicativos ao modo normal.
A criação, a depuração e a manutenção de pré/pós-scripts podem ser desafiadoras. Para remover essa complexidade, o Backup do Azure oferece uma experiência simplificada de pré/pós-script para bancos de dados de letreiro para obter um instantâneo consistente do aplicativo com menos sobrecarga.
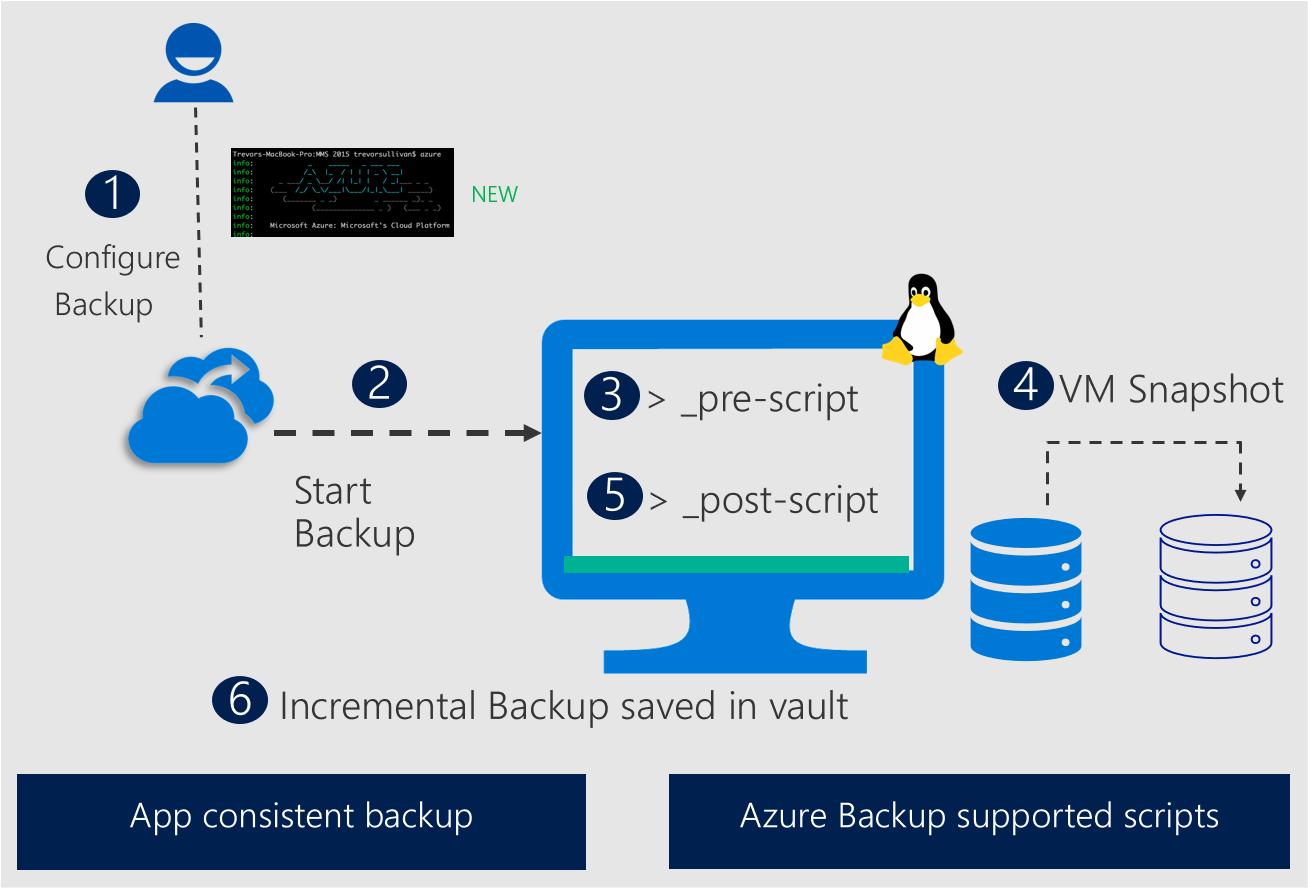
A nova estrutura de pré/pós-script aprimorada tem os seguintes benefícios principais:
- Esses scripts de pré-postagem são instalados diretamente em VMs do Azure junto com a extensão de backup, o que ajuda a eliminar a criação e baixá-los de um local externo.
- Você pode exibir a definição e o conteúdo de pré/pós-scripts no GitHub e até mesmo enviar sugestões e alterações. Você pode até mesmo enviar sugestões e alterações por meio do GitHub, que serão submetidas a triagem e adicionadas para beneficiar a comunidade mais ampla.
- Você pode até mesmo adicionar novos pré/pós-scripts para outros bancos de dados por meio do GitHub, que serão submetidos a triagem e tratados para beneficiar a comunidade mais ampla.
- A estrutura robusta é eficiente para lidar com cenários, como panes ou falhas de execução de pré-script. Em qualquer caso, o pós-script é executado automaticamente para reverter todas as alterações feitas no pré-script.
- A estrutura também fornece um canal de mensagens para que ferramentas externas busquem atualizações e prepararem seu próprio plano de ação em qualquer mensagem/evento.
Fluxo de solução
Matriz de suporte
A seguir, a lista de bancos de dados é abordada na estrutura aprimorada:
- Oracle (em disponibilidade geral) - Link da matriz de suporte
- MySQL (versão prévia)
Pré-requisitos
Basta modificar um arquivo de configuração, workload.conf em /etc/azure, para fornecer detalhes de conexão. Isso permite que o Backup do Azure se conecte ao aplicativo relevante e execute pré/pós-scripts. O arquivo de configuração apresenta os seguintes parâmetros.
[workload]
# valid values are mysql, oracle
workload_name =
command_path =
linux_user =
credString =
ipc_folder =
timeout =
A tabela a seguir lista os parâmetros:
| Parâmetro | Obrigatório | Explicação |
|---|---|---|
| workload_name | Sim | Esse parâmetro conterá o nome do banco de dados para o qual você precisa de backup consistente de aplicativos. Os valores com suporte atuais são oracle ou mysql. |
| command_path/configuration_path | Esse parâmetro conterá o caminho para o binário da carga de trabalho. Este não será um campo obrigatório se o binário da carga de trabalho for definido como variável de caminho. | |
| linux_user | Sim | Esse parâmetro conterá o nome de usuário do Linux com acesso ao logon do usuário do banco de dados. Se esse valor não estiver definido, root será considerado como o usuário padrão. |
| credString | Representa a cadeia de caracteres de credencial para se conectar ao banco de dados. Conterá toda a cadeia de caracteres de logon. | |
| ipc_folder | A carga de trabalho só pode gravar em determinados caminhos do sistema de arquivos. É preciso fornecer aqui esse caminho de pasta para que o pré-script possa gravar os estados nesse caminho de pasta. | |
| tempo limite | Sim | Esse é o limite máximo de tempo para o qual o banco de dados estará no estado de fechamento para novas sessões. O valor padrão é 90 segundos. Não é recomendável definir um valor inferior a 60 segundos. |
Observação
A definição JSON é um modelo que o serviço do Backup do Azure pode modificar para se adequar a um banco de dados específico. Para entender o arquivo de configuração de cada banco de dados, consulte o manual de cada banco de dados.
A experiência geral para usar a estrutura de pré/pós-script aprimorada é a seguinte:
- Preparar o ambiente do banco de dados
- Editar o arquivo de configuração
- Disparar o backup de VM
- Restaure VMs ou discos/arquivos do ponto de recuperação consistente do aplicativo, conforme necessário.
Criar uma estratégia de backup de banco de dados
Uso de instantâneos em vez de streaming
Normalmente, os backups de streaming (como completo, diferencial ou incremental) e os logs são usados por administradores de banco de dados em sua estratégia de backup. A seguir, estão alguns dos principais pivôs no design.
- Desempenho e custo: logs diários + completos seriam mais rápidos durante a restauração, mas envolvem um custo significativo. Incluir o tipo de backup de streaming diferencial/incremental reduz o custo, mas pode afetar o desempenho da restauração. No entanto, os instantâneos fornecem a melhor combinação de desempenho e custo. Como os instantâneos são inerentemente incrementais, eles têm menos impacto sobre o desempenho durante o backup, são restaurados rapidamente e também economizam custos.
- Impacto no banco de dados/infraestrutura: o desempenho de um backup de streaming depende do IOPS de armazenamento subjacente e da largura de banda de rede disponível quando o fluxo é direcionado a um local remoto. Os instantâneos não têm essa dependência e a demanda por IOPS e largura de banda de rede é significativamente reduzida.
- Reusabilidade: os comandos para disparar diferentes tipos de backup de streaming são diferentes para cada banco de dados. Portanto, os scripts não podem ser reutilizados com facilidade. Além disso, se você estiver usando tipos de backup diferentes, avalie a cadeia de dependências para manter o ciclo de vida. Para instantâneos, é fácil gravar scripts, pois não há nenhuma cadeia de dependências.
- Retenção de longo prazo: backups completos são sempre benéficos para retenção de longo prazo, pois podem ser movidos e recuperados independentemente. Mas, para backups operacionais com retenção de curto prazo, os instantâneos são favoráveis.
Portanto, um instantâneo + logs diários com backup completo ocasional para retenção de longo prazo é a melhor política de backup para bancos de dados.
Estratégia de backup de log
A estrutura de pré/pós-script aprimorada é criada no backup de VM do Azure que agenda o backup uma vez por dia. Portanto, a janela de perda de dados com objetivo de ponto de recuperação (RPO) de 24 horas não é adequada para bancos de dados de produção. Essa solução é complementada com uma estratégia de backup de log em que os backups de log são transmitidos explicitamente.
O NFS no blob e o NFS no AFS (versão prévia) ajuda na montagem fácil de volumes diretamente em VMs de banco de dados e usa clientes de banco de dados para transferir backups de log. A janela de perda de dados que é RPO se enquadra na frequência dos backups de log. Além disso, os destinos NFS não precisam ser de alto desempenho, pois talvez você não precise disparar streaming regular (completo e incremental) para backups operacionais depois de ter instantâneos consistentes com o banco de dados.
Observação
O pré-script aprimorado geralmente tem o cuidado de liberar todas as transações de log em trânsito para o destino de backup de log, antes de fechar o banco de dados para novas sessões para tirar um instantâneo. Portanto, os instantâneos são confiáveis e consistentes com o banco de dados durante a recuperação.
Estratégia de recuperação
Depois que os instantâneos consistentes com o banco de dados são tirados e os backups de log são transmitidos para um volume NFS, a estratégia de recuperação do banco de dados pode usar a funcionalidade de recuperação de backups de VM do Azure. A capacidade de backups de log também é aplicada a ele usando o cliente de banco de dados. A seguir, estão algumas opções de estratégia de recuperação:
- Crie novas VMs do ponto de recuperação consistente do banco de dados. A VM já deve ter o ponto de montagem de log conectado. Use clientes de banco de dados para executar comandos de recuperação para recuperação pontual.
- Crie discos do ponto de recuperação consistente do banco de dados e anexe-os a outra VM de destino. Em seguida, monte o destino do log e use clientes de banco de dados para executar comandos de recuperação para recuperação pontual
- Use a opção de recuperação de arquivo e gere um script. Execute o script na VM de destino e anexe o ponto de recuperação como discos iSCSI. Em seguida, use clientes de banco de dados para executar as funções de validação específicas do banco de dados nos discos anexados e validar os dados de backup. Além disso, use clientes de banco de dados para exportar/recuperar algumas tabelas/arquivos em vez de recuperar todo o banco de dados.
- Use a funcionalidade Restauração entre regiões para executar as ações acima da região emparelhada secundária durante o desastre regional.
Resumo
Usando instantâneos consistentes de banco de dados + logs com backup usando uma solução personalizada, é possível criar uma solução de backup de banco de dados econômica e de alto desempenho aproveitando os benefícios do backup de VM do Azure e também reutilizando os recursos de clientes de banco de dados.