Otimizar o Apache Hive com o Apache Ambari no Azure HDInsight
O Apache Ambari é uma interface da Web voltada para gerenciar e monitorar clusters do HDInsight. Para ver uma introdução à IU da Web do Ambari, veja Gerenciar clusters do HDInsight usando a IU da Web do Apache Ambari.
As seções a seguir descrevem opções de configuração para otimizar o desempenho geral do Apache Hive.
- Para modificar parâmetros de configuração do Hive, selecione Hive na barra lateral Serviços.
- Navegue até a guia Configurações.
Definir o mecanismo de execução do Hive
O Hive fornece dois mecanismos de execução: Apache Hadoop MapReduce e Apache TEZ. O Tez é mais rápido que o MapReduce. Clusters Linux do HDInsight têm o Tez como mecanismo de execução padrão. Para alterar o mecanismo de execução:
Na guia Configurações do Hive, digite mecanismo de execução na caixa de filtro.
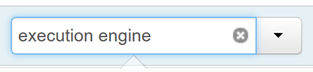
O valor padrão da propriedade Otimização é Tez.
Ajustar mapeadores
O Hadoop tenta dividir (mapear) arquivos únicos em vários arquivos e processar os arquivos resultantes em paralelo. O número de mapeadores depende do número de divisões. Os dois parâmetros de configuração a seguir definem o número de divisões para o mecanismo de execução Tez:
tez.grouping.min-size: limite inferior do tamanho de uma divisão agrupada, com um valor padrão de 16 MB (16.777.216 bytes).tez.grouping.max-size: limite superior do tamanho de uma divisão agrupada, com um valor padrão de 1 GB (1.073.741.824 bytes).
Como diretriz de desempenho, diminua esses dois parâmetros para melhorar a latência e aumente para aumentar a taxa de transferência.
Por exemplo, para definir quatro tarefas de mapeador com o tamanho de dados de 128 MB, você definiria os dois parâmetros como 32 MB cada (33.554.432 bytes).
Para modificar os parâmetros de limite, navegue até a guia Configurações do serviço Tez. Expanda o painel Geral e localize os parâmetros
tez.grouping.max-sizeetez.grouping.min-size.Defina os dois parâmetros como 33,554,432 bytes (32 MB).

Essas alterações afetam todos os trabalhos do Tez no servidor. Para obter o resultado ideal, escolha valores de parâmetro apropriados.
Ajustar redutores
Apache ORC e Snappy ambos oferecem alto desempenho. Entretanto, o Hive pode ter poucos redutores por padrão, o que causa gargalos.
Por exemplo, digamos que você tenha um tamanho de dados de entrada igual a 50 GB. Esses dados em formato ORC com compactação do Snappy terão 1 GB. O Hive estima o número de redutores necessários como: (número de entrada de bytes para mapeadores / hive.exec.reducers.bytes.per.reducer).
Com as configurações padrão, esse exemplo terá quatro redutores.
O parâmetro hive.exec.reducers.bytes.per.reducer especifica o número de bytes processados por redutor. O valor padrão é 64 MB. Diminuir esse valor aumenta o paralelismo e pode melhorar o desempenho. Diminui-lo demais também pode produzir muitos redutores, o que pode prejudicar o desempenho. Este parâmetro é baseado em seus requisitos de dados específicos, nas configurações de compactação e em outros fatores ambientais.
Para modificá-lo, navegue até a guia Configurações do Hive e localize o parâmetro Dados por Redutor na página Configurações.
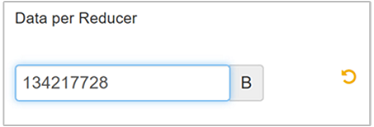
Selecione Editar para modificar o valor para 128 MB (134.217.728 bytes) e, em seguida, pressione Enter para salvar.
Dado um tamanho de entrada de 1.024 MB, com 128 MB de dados por redutor, há oito redutores (1024/128).
Atribuir um valor incorreto para o parâmetro Dados por Redutor pode resultar em um grande número de redutores, afetando negativamente o desempenho da consulta. Para limitar o número máximo de redutores, defina um valor apropriado para
hive.exec.reducers.max. O valor padrão é 1009.
Habilitar execução paralela
Uma consulta do Hive é executada em uma ou mais etapas. Se as etapas independentes puderem ser executadas em paralelo, o desempenho da consulta aumentará.
Para habilitar a execução de consultas em paralelo, navegue até a guia Configurações do Hive e pesquise pela propriedade
hive.exec.parallel. O valor padrão é false. Altere o valor para true e pressione Enter para salvá-lo.Para limitar o número de trabalhos executados em paralelo, modifique a propriedade
hive.exec.parallel.thread.number. O valor padrão é 8.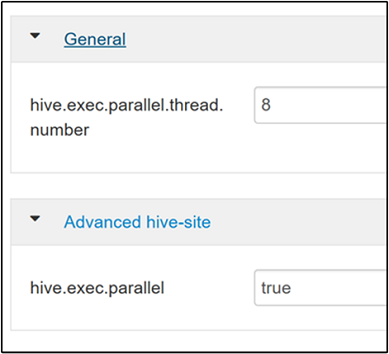
Habilitar vetorização
O Hive processa dados linha por linha. A vetorização instrui o Hive a processar dados em blocos de 1.024 linhas em vez de uma linha por vez. A vetorização é aplicável somente ao formato de arquivo ORC.
Para habilitar uma execução de consulta vetorizada, navegue até a guia Configurações do Hive e pesquise pelo parâmetro
hive.vectorized.execution.enabled. O valor padrão é true para o Hive 0.13.0 ou posterior.Para habilitar a execução vetorizada para o lado de redução da consulta, defina o parâmetro
hive.vectorized.execution.reduce.enabledcomo true. O valor padrão é false.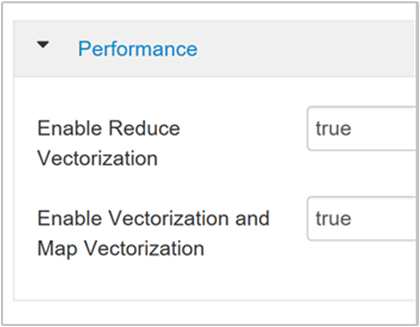
Habilitar CBO (otimização baseada em custo)
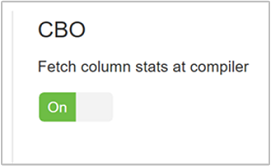
Por padrão, o Hive segue um conjunto de regras para encontrar um plano de execução de consulta ideal. A CBO (otimização baseada em custo) avalia vários planos para executar uma consulta. E atribui um custo a cada plano e determina o plano mais barato para executar uma consulta.
Para habilitar a CBO, vá paraHive>Configurações>Definições e encontre Habilitar Otimizador Baseado em Custo, em seguida, alterne o botão para Ativado.

Os seguintes parâmetros de configuração adicionais aumentam o desempenho de consulta do Hive quando a CBO está habilitada:
hive.compute.query.using.statsQuando definido como true, o Hive usa estatísticas armazenadas em seu metastore para responder consultas simples como
count(*).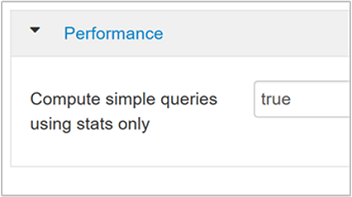
hive.stats.fetch.column.statsEstatísticas de coluna são criadas quando a CBO está habilitada. O Hive usa estatísticas de coluna, que são armazenadas em um metastore, para otimizar consultas. Obter estatísticas de coluna para cada coluna leva mais tempo quando o número de colunas é alto. Quando definida como false, essa configuração desabilita a busca de estatísticas de coluna do metastore.
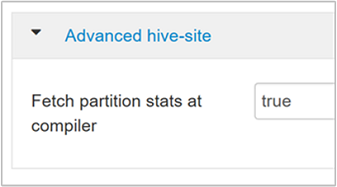
hive.stats.fetch.partition.statsEstatísticas de partição básicas, como número de linhas, tamanho de dados e tamanho do arquivo, são armazenadas no metastore. Se definidas como true, as estatísticas de partição serão buscadas no metastore. Se definidas como falso, o tamanho do arquivo será obtido do sistema de arquivos. E o número de linhas é buscado no esquema de linha.
Confira a postagem de blog Otimização baseada em custo do Hive no Blog Analytics no Azure para leitura adicional
Habilitar compactação intermediária
Tarefas de mapeamento criam arquivos intermediários que são usados pelas tarefas do redutor. A compactação intermediária reduz o tamanho do arquivo intermediário.
Trabalhos do Hadoop normalmente têm um gargalo de E/S. Compactar os dados pode acelerar a E/S e a transferência de rede em geral.
Os tipos de compactação disponíveis são:
| Formatar | Ferramenta | Algoritmo | Extensão do arquivo | Divisível? |
|---|---|---|---|---|
| Gzip | Gzip | DEFLATE | .gz |
No |
| Bzip2 | Bzip2 | Bzip2 | .bz2 |
Yes |
| LZO | Lzop |
LZO | .lzo |
Sim, se indexado |
| Snappy | N/D | Snappy | Snappy | No |
Como regra geral, é importante que o método de compactação seja divisível. Caso contrário, serão criados poucos mapeadores. Se os dados de entrada forem texto, bzip2 será a melhor opção. Para o formato ORC, o Snappy é a opção de compactação mais rápida.
Para habilitar a compactação intermediária, navegue até a guia Configurações do Hive e, em seguida, defina o parâmetro
hive.exec.compress.intermediatecomo verdadeiro. O valor padrão é false.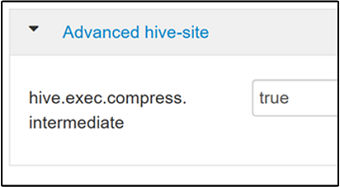
Observação
Para compactar arquivos intermediários, escolha um codec de compactação com menor custo de CPU, mesmo se o codec não tiver uma alta saída de compactação.
Para definir o codec de compactação intermediário, adicione a propriedade personalizada
mapred.map.output.compression.codecao arquivohive-site.xmloumapred-site.xml.Para adicionar uma configuração personalizada:
a. Navegue até Hive>Configurações>Avançado>Hive-site personalizado.
b. Selecione Adicionar Propriedade... na parte inferior do painel Hive-site personalizado.
c. Na janela Adicionar Propriedade, digite
mapred.map.output.compression.codeccomo a chave eorg.apache.hadoop.io.compress.SnappyCodeccomo o valor.d. Selecione Adicionar.
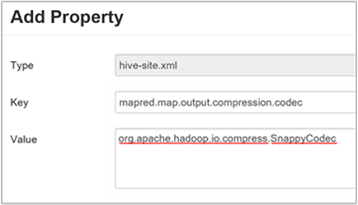
Essa configuração compactará o arquivo intermediário usando a compactação do Snappy. Após ser adicionada, a propriedade aparecerá no painel hive-site personalizado.
Observação
Este procedimento modifica o arquivo
$HADOOP_HOME/conf/hive-site.xml.
Compactar a saída final
A saída final do Hive também pode ser compactada.
Para compactar a saída final do Hive, navegue até a guia Configurações do Hive e, em seguida, defina o parâmetro
hive.exec.compress.outputcomo verdadeiro. O valor padrão é false.Para escolher o codec de compactação de saída, adicione a propriedade personalizada
mapred.output.compression.codecao painel hive-site personalizado, conforme descrito na etapa 3 da seção anterior.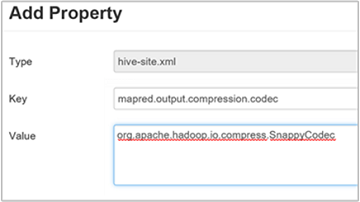
Habilitar a execução especulativa
A execução especulativa inicia um determinado número de tarefas duplicadas para detectar e recusar a listagem do rastreador de tarefas de execução lenta. Tudo isso enquanto melhora a execução geral do trabalho, otimizando os resultados de tarefas individuais.
A execução especulativa não deve ser ativada para tarefas MapReduce de execução longa com grandes quantidades de entrada.
Para habilitar a execução especulativa, navegue até a guia Configurações do Hive e, em seguida, defina o parâmetro
hive.mapred.reduce.tasks.speculative.executioncomo verdadeiro. O valor padrão é false.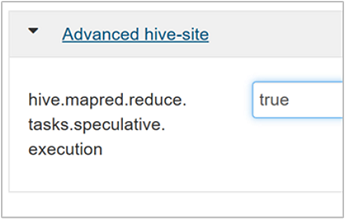
Ajustar partições dinâmicas
O Hive permite criar partições dinâmicas ao inserir registros em uma tabela sem predefinir cada partição. Essa capacidade é um recurso avançado. Embora talvez isso resulte na criação de um grande número de partições. E um grande número de arquivos para cada partição.
Para o Hive fazer partições dinâmicas, o valor do parâmetro
hive.exec.dynamic.partitiondeve ser true (o padrão).Altere o modo de partição dinâmica para estrito. No modo estrito, pelo menos uma partição deve ser estática. Isso impede consultas sem o filtro de partição na cláusula WHERE, ou seja, estrito impede consultas que verificam todas as partições. Navegue até a guia Configurações do Hive e, em seguida, defina
hive.exec.dynamic.partition.modecomo estrito. O valor padrão é não estrito.Para limitar o número de partições dinâmicas a serem criadas, modifique o parâmetro
hive.exec.max.dynamic.partitions. O valor padrão é 5.000.Para limitar o número total de partições dinâmicas por nó, modifique
hive.exec.max.dynamic.partitions.pernode. O valor padrão é 2.000.
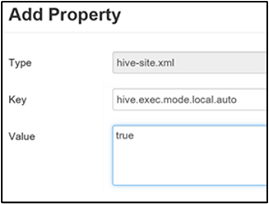
Habilitar modo local
O modo local permite que o Hive execute todas as tarefas de um trabalho em um único computador. Ou, às vezes, em um único processo. Essa configuração melhora o desempenho da consulta quando os dados de entrada são pequenos. E a sobrecarga de iniciar tarefas para consultas consome um percentual significativo da execução geral da consulta.
Para habilitar o modo local, adicione o parâmetro hive.exec.mode.local.auto ao painel hive-site personalizado, conforme explicado na etapa 3 da seção Habilitar compactação intermediária.
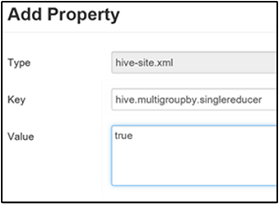
Definir MultiGROUP BY para MapReduce único
Quando esta propriedade é definida como true, uma consulta MultiGROUP BY com chaves de agrupamento comuns gera um único trabalho de MapReduce.
Para habilitar esse comportamento, adicione o parâmetro hive.multigroupby.singlereducer ao painel hive-site personalizado, conforme explicado na etapa 3 da seção Habilitar compactação intermediária.
Otimizações adicionais do Hive
As seções a seguir descrevem otimizações adicionais relacionadas ao Hive que você pode definir.
Otimizações de junção
O tipo de junção padrão no Hive é a junção em ordem aleatória. No Hive, mapeadores especiais leem a entrada e emitem um par de chave/valor de junção para um arquivo intermediário. O Hadoop classifica e mescla esses pares em um estágio de ordem aleatória. Esse estágio de ordem aleatória é caro. Selecionar a junção correta com base em seus dados pode melhorar significativamente o desempenho.
| Tipo de junção | Quando | Como | Configurações do Hive | Comentários |
|---|---|---|---|---|
| Junção em ordem aleatória |
|
|
Nenhuma configuração significativa do Hive é necessária | Sempre funciona |
| Junção de mapa |
|
|
hive.auto.convert.join=true |
Rápido, mas limitado |
| Classificar bucket de mesclagem | Se as duas tabelas forem:
|
Cada processo:
|
hive.auto.convert.sortmerge.join=true |
Eficiente |
Otimizações do mecanismo de execução
Recomendações adicionais para otimizar o mecanismo de execução do Hive:
| Configuração | Recomendadas | Padrão do HDInsight |
|---|---|---|
hive.mapjoin.hybridgrace.hashtable |
True = mais seguro, mais lento; false = mais rápido | false |
tez.am.resource.memory.mb |
Limite superior de 4 GB para a maioria | Ajustado automaticamente |
tez.session.am.dag.submit.timeout.secs |
300+ | 300 |
tez.am.container.idle.release-timeout-min.millis |
20000+ | 10000 |
tez.am.container.idle.release-timeout-max.millis |
40000+ | 20000 |