Implantar um modelo como um ponto de extremidade online
APLICA-SE A:  SDK do Python azure-ai-ml v2 (atual)
SDK do Python azure-ai-ml v2 (atual)
Saiba como implantar um modelo em um ponto de extremidade online usando o SDK do Python do Azure Machine Learning v2.
Neste tutorial, implemente e use um modelo que prevê a probabilidade de inadimplência de um cliente em um pagamento com cartão de crédito.
As etapas são:
- Registre seu modelo
- Criar um ponto de extremidade e uma primeira implantação
- Implantar uma execução de avaliação
- Enviar dados de teste manualmente para implantação
- Obter detalhes da implantação
- Criar uma segunda implantação
- Dimensionar manualmente a segunda implantação
- Atualizar a alocação de tráfego de produção entre ambas as implantações
- Obter detalhes da segunda implantação
- Distribuir a nova implantação e excluir a primeira
Esse vídeo mostra como começar a usar o Estúdio do Azure Machine Learning para que você possa seguir as etapas no tutorial. O vídeo mostra como criar um notebook, criar uma instância de computação e clonar o notebook. Essas etapas estão descritas nas seções a seguir.
Pré-requisitos
-
Para usar o Azure Machine Learning, você precisa de um workspace. Se você não tiver um, conclua Criar recursos necessários para começar para criar um workspace e saber mais sobre como usá-lo.
Importante
Se o seu espaço de trabalho do Azure Machine Learning estiver configurado com uma rede virtual gerenciada, talvez seja necessário adicionar regras de saída para permitir o acesso aos repositórios públicos de pacotes do Python. Para obter mais informações, veja Cenário: Acessar pacotes públicos de aprendizado de máquina.
-
Entre no estúdio e selecione seu workspace, caso ele ainda não esteja aberto.
-
Abra ou crie um notebook em seu workspace:
- Se você quiser copiar e colar código em células, crie um novo notebook.
- Ou abra tutorials/get-started-notebooks/deploy-model.ipynb na seção Amostras do Studio. Em seguida, selecione Clonar para adicionar o notebook aos seus Arquivos. Para localizar notebooks de exemplo, confira o artigo Aprender com os notebooks de exemplo.
Exiba sua cota de VM e verifique se você tem cota suficiente disponível para criar implantações online. Neste tutorial, você precisa de pelo menos 8 núcleos de
STANDARD_DS3_v2e 12 núcleos deSTANDARD_F4s_v2. Para exibir o uso da cota de VM e solicitar aumentos de cota, confira Gerenciar cotas de recursos.
Definir o kernel e abrir no VS Code (Visual Studio Code)
Na barra superior acima do notebook aberto, crie uma instância de computação se você ainda não tiver uma.

Se a instância de computação for interrompida, selecione Iniciar computação e aguarde até que ela esteja em execução.

Aguarde até que a instância de computação esteja em execução. Em seguida, verifique se o kernel, encontrado no canto superior direito, é
Python 3.10 - SDK v2. Caso contrário, use a lista suspensa para selecionar esse kernel.
Se você não vir esse kernel, verifique se a instância de computação está em execução. Se estiver, selecione o botão Atualizar na parte superior direita do notebook.
Se você vir uma barra de notificação dizendo que você precisa de autenticação, selecione Autenticar.
Você pode executar o notebook aqui ou abri-lo no VS Code para um IDE (ambiente de desenvolvimento integrado) completo com o poder dos recursos do Azure Machine Learning. Selecione Abrir no VS Code e, em seguida, selecione a opção Web ou desktop. Quando iniciado dessa forma, o VS Code é anexado à instância de computação, ao kernel e ao sistema de arquivos do workspace.





Importante
O restante deste tutorial contém células do notebook do tutorial. Copie e cole-os em seu novo notebook ou alterne para o notebook agora se você o clonou.
Observação
- A Computação do Spark sem servidor não tem
Python 3.10 - SDK v2instalado por padrão. Recomendamos que os usuários criem uma instância de computação e a selecionem antes de prosseguir com o tutorial.
Criar identificador para o workspace
Antes de se aprofundar no código, você precisa de uma maneira de fazer referência ao seu espaço de trabalho. Crie ml_client para um identificador do espaço de trabalho e use ml_client para gerenciar recursos e trabalhos.
Na próxima célula, insira a ID da Assinatura, o nome do Grupo de Recursos e o nome do espaço de trabalho. Para encontrar esses valores:
- Na barra de ferramentas do Estúdio do Azure Machine Learning superior direito, selecione o nome do espaço de trabalho.
- Copie o valor do espaço de trabalho, do grupo de recursos e da ID da assinatura no código.
- Você precisa copiar um valor, fechar a área e colar, depois voltar para o próximo.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Observação
Criar MLClient não se conectará ao espaço de trabalho. A inicialização do cliente é lenta e aguarda a primeira vez que precisa fazer uma chamada (isso acontece na próxima célula de código).
Registre o modelo
Se já tiver concluído o tutorial de treinamento anterior, Treinar um modelo, você registrou um modelo MLflow como parte do script de treinamento e pode pular para a próxima seção.
Se não tiver concluído o tutorial de treinamento, precisará registrar o modelo. Registrar seu modelo antes da implantação é uma prática recomendada.
O código a seguir especifica o path (de onde carregar os arquivos) em linha. Se você clonou a pasta de tutoriais, execute o código a seguir como está. Caso contrário, baixe os arquivos e metadados para o modelo da pasta credit_defaults_model. Salve os arquivos que você baixar em uma versão local da pasta credit_defaults_model no seu computador e atualize o caminho no código a seguir para o local dos arquivos baixados.
O SDK carrega automaticamente os arquivos e registra o modelo.
Para obter mais informações sobre como registrar seu modelo como um ativo, consulte Registrar seu modelo como um ativo no Machine Learning usando o SDK.
# Import the necessary libraries
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
# Provide the model details, including the
# path to the model files, if you've stored them locally.
mlflow_model = Model(
path="./deploy/credit_defaults_model/",
type=AssetTypes.MLFLOW_MODEL,
name="credit_defaults_model",
description="MLflow Model created from local files.",
)
# Register the model
ml_client.models.create_or_update(mlflow_model)
Confirme se o modelo está registrado
Você pode verificar a página Modelos no Estúdio do Azure Machine Learning para identificar a versão mais recente do modelo registrado.
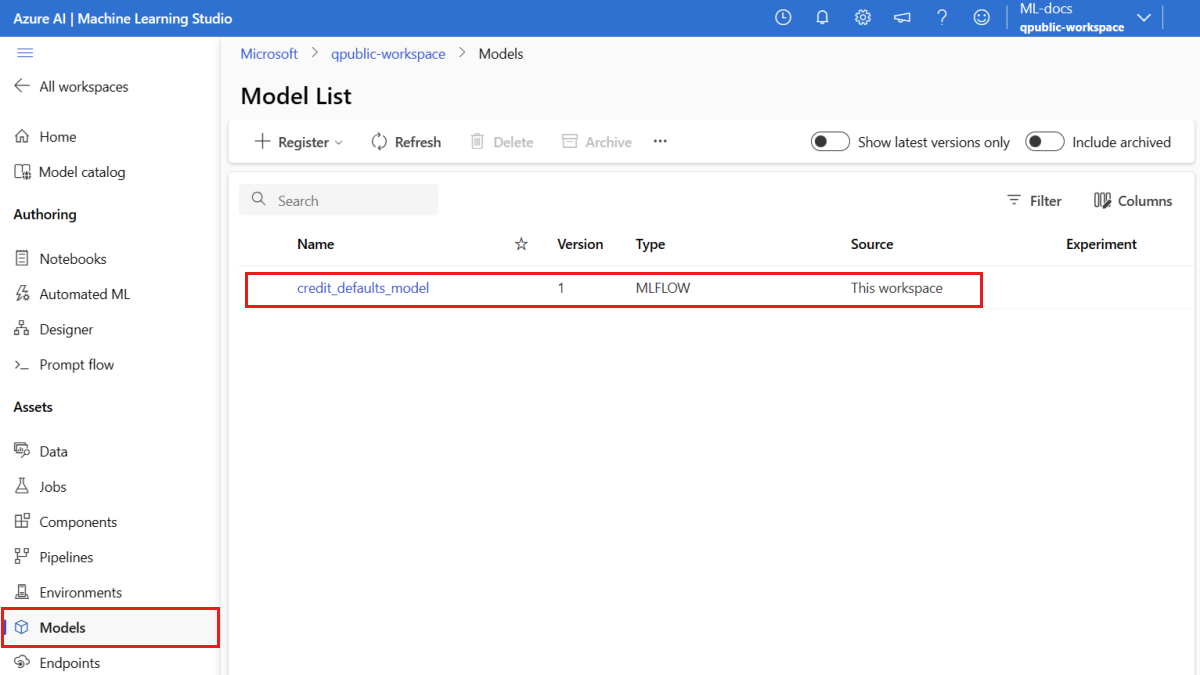
Como alternativa, o código a seguir recupera o número da versão mais recente para você usar.
registered_model_name = "credit_defaults_model"
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(latest_model_version)
Agora que você tem um modelo registrado, crie um ponto de extremidade e uma implantação. A próxima seção aborda brevemente alguns detalhes importantes sobre esses tópicos.
Pontos de extremidade e implantações
Depois de treinar um modelo de machine learning, você precisará implantá-lo para que outras pessoas possam usá-lo para inferência. Para essa finalidade, o Azure Machine Learning permite que você crie pontos de extremidade e adicione implantações a eles.
Um ponto de extremidade, neste contexto, é um caminho HTTPS que fornece uma interface para que os clientes enviem solicitações (dados de entrada) a um modelo treinado e recebam os resultados de inferência (pontuação) do modelo. Um ponto de extremidade fornece:
- Autenticação usando autenticação baseada em "chave ou token"
- Terminação TLS(SSL)
- Um URI de pontuação estável (endpoint-name.region.inference.ml.azure.com)
Uma implantação é um conjunto de recursos necessários para hospedar o modelo que executa a inferência real.
Um ponto de extremidade pode conter várias implantações. Os pontos de extremidade e as implantações são recursos do Azure Resource Manager independentes que aparecem no portal do Azure.
O Azure Machine Learning permite implementar pontos de extremidade online para inferência em tempo real nos dados do cliente e pontos de extremidade em lote para inferência em grandes volumes de dados durante um período de tempo.
Neste tutorial, você percorrerá as etapas de implementação de um ponto de extremidade online gerenciado. Os pontos de extremidade online gerenciados funcionam com computadores avançados de CPU e GPU no Azure de forma escalonável e totalmente gerenciada que libera você da sobrecarga de configurar e gerenciar a infraestrutura de implantação subjacente.
Criar um ponto de extremidade online
Agora que você tem um modelo registrado, é hora de criar seu ponto de extremidade online. O nome do ponto de extremidade deve ser exclusivo em toda a região do Azure. Para este tutorial, crie um nome exclusivo usando um identificador universalmente exclusivo UUID. Para obter mais informações sobre as regras de nomenclatura do ponto de extremidade, confira os limites de ponto de extremidade.
import uuid
# Create a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Primeiro, defina o ponto de extremidade usando a classe ManagedOnlineEndpoint.
Dica
auth_mode: usekeypara autenticação baseada em chave. Useaml_tokenpara autenticação baseada em chave do Azure Machine Learning.keynão expira, masaml_tokenexpira. Para obter mais informações sobre autenticação, consulte Autenticar clientes para pontos de extremidade online.Opcionalmente, você pode adicionar uma descrição e marcas para o ponto de extremidade.
from azure.ai.ml.entities import ManagedOnlineEndpoint
# define an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
},
)
Usando o MLClient criado anteriormente, crie o ponto de extremidade no espaço de trabalho. Esse comando inicia a criação do ponto de extremidade e retorna uma resposta de confirmação enquanto a criação do ponto de extremidade continuar.
Observação
A criação do ponto de extremidade deve levar aproximadamente 2 minutos.
# create the online endpoint
# expect the endpoint to take approximately 2 minutes.
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Depois de criar o ponto de extremidade, você pode recuperá-lo da seguinte forma:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Noções básicas sobre implantações online
Os principais aspectos de uma implantação incluem:
name- Nome da implantação.endpoint_name- Nome do ponto de extremidade que conterá a implantação.model– O modelo a ser usado para a implantação. Esse valor pode ser uma referência a um modelo com versão existente no workspace ou uma especificação de modelo embutida.environment- O ambiente a ser usado para a implantação (ou para executar o modelo). Esse valor pode ser uma referência para um ambiente com versão existente no espaço de trabalho ou uma especificação de ambiente embutido. O ambiente pode ser um imagem do Docker com dependências do Conda ou um Dockerfile.code_configuration- A configuração do código-fonte e o script de pontuação.path- O caminho para o diretório do código-fonte de pontuação do modelo.scoring_script- Caminho relativo para o arquivo de pontuação no diretório do código-fonte. O script executa o modelo em uma determinada solicitação de entrada. Para obter um exemplo de um script de pontuação, confira Entender o script de pontuação no artigo "Implantar um modelo de ML com um ponto de extremidade online".
instance_type– O tamanho da VM a ser usado para a implantação. Para obter a lista de tamanhos com suporte, confira Lista de SKU de pontos de extremidade online gerenciados.instance_count- O número de instâncias a serem usadas para a implantação.
Implantação usando um modelo MLflow
O Azure Machine Learning dá suporte à implantação sem código de um modelo criado e registrado com o MLflow. Isso significa que você não precisa fornecer um script de pontuação ou um ambiente durante a implantação do modelo, pois o script de pontuação e o ambiente são gerados automaticamente ao treinar um modelo MLflow. No entanto, se você estivesse usando um modelo personalizado, teria que especificar o ambiente e o script de pontuação durante a implantação.
Importante
Se você costuma implantar modelos usando scripts de pontuação e ambientes personalizados e deseja obter a mesma funcionalidade usando modelos do MLflow, recomendamos a leitura de Diretrizes para implantação de modelos do MLflow.
Implantar o modelo ao ponto de extremidade
Comece criando uma única implantação que lide com 100% do tráfego de entrada. Escolha um nome de cor arbitrário (azul) para a implantação. Para criar a implantação para o ponto de extremidade, use a classe ManagedOnlineDeployment.
Observação
Não é necessário especificar um ambiente ou script de pontuação, pois o modelo a ser implantado é um modelo MLflow.
from azure.ai.ml.entities import ManagedOnlineDeployment
# Choose the latest version of the registered model for deployment
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
Usando o MLClient criado anteriormente, crie agora a implantação no espaço de trabalho. Esse comando iniciará a criação da implantação e retornará uma resposta de confirmação enquanto a criação da implantação continuar.
# create the online deployment
blue_deployment = ml_client.online_deployments.begin_create_or_update(
blue_deployment
).result()
# blue deployment takes 100% traffic
# expect the deployment to take approximately 8 to 10 minutes.
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Verifique o status do endpoint
Verifique o status do ponto de extremidade para ver se o modelo foi implantado sem erro:
# return an object that contains metadata for the endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# print a selection of the endpoint's metadata
print(
f"Name: {endpoint.name}\nStatus: {endpoint.provisioning_state}\nDescription: {endpoint.description}"
)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
Testar o ponto de extremidade usando dados de exemplo
Agora que o modelo está implantado no ponto de extremidade, você pode executar a inferência com ele. Comece criando um arquivo de solicitação de amostra que siga o design esperado no método de execução encontrado no script de pontuação.
import os
# Create a directory to store the sample request file.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
Agora, crie o arquivo no diretório de implantação. A célula de código a seguir usa a mágica do IPython para gravar o arquivo no diretório que você acabou de criar.
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
Usando o MLClient criado anteriormente, obtenha um identificador para o ponto de extremidade. Você pode chamar o ponto de extremidade usando o comando invoke com os seguintes parâmetros:
endpoint_name– Nome do ponto de extremidaderequest_file– Arquivo com os dados de solicitaçãodeployment_name– Nome da implantação específica a ser testada em um ponto de extremidade
Teste a implantação azul com os dados de amostra.
# test the blue deployment with the sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="./deploy/sample-request.json",
)
Obter logs da implantação
Verifique os registros para ver se o ponto de extremidade/implantação foi invocado com êxito. Se houver erros, consulte Solução de problemas de implantação de pontos de extremidade online.
logs = ml_client.online_deployments.get_logs(
name="blue", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Criar uma segunda implantação
Implante o modelo como uma segunda implantação chamada green. Na prática, você pode criar várias implantações e comparar seu desempenho. Essas implantações podem usar uma versão diferente do mesmo modelo, um modelo diferente ou uma instância de computação mais avançada.
Neste exemplo, implemente a mesma versão do modelo, usando uma instância de computação mais avançada que possa melhorar o desempenho.
# pick the model to deploy. Here you use the latest version of the registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment using a more powerful instance type
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_F4s_v2",
instance_count=1,
)
# create the online deployment
# expect the deployment to take approximately 8 to 10 minutes
green_deployment = ml_client.online_deployments.begin_create_or_update(
green_deployment
).result()
Escalar a implantação para lidar com mais tráfego
Usando o MLClient criado anteriormente, você pode obter um controle sobre a implantação do green. Em seguida, você pode dimensioná-lo aumentando ou diminuindo o instance_count.
No código a seguir, você aumenta a instância da VM manualmente. No entanto, também é possível dimensionar automaticamente os pontos de extremidade online. O dimensionamento automático executa automaticamente a quantidade certa de recursos para lidar com a carga em seu aplicativo. Os pontos de extremidade gerenciados dão suporte ao dimensionamento automático por meio da integração com o recurso de dimensionamento automático do Azure Monitor. Para configurar o dimensionamento automático, consulte Pontos de extremidade online de dimensionamento automático.
# update definition of the deployment
green_deployment.instance_count = 2
# update the deployment
# expect the deployment to take approximately 8 to 10 minutes
ml_client.online_deployments.begin_create_or_update(green_deployment).result()
Atualizar a alocação de tráfego para implantações
Você pode dividir o tráfego de produção entre implantações. Talvez você queira primeiro testar a implantação de green com dados de exemplo, assim como fez para a implantação blue. Depois de testar a implantação verde, aloque um pequeno percentual de tráfego a ela.
endpoint.traffic = {"blue": 80, "green": 20}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Teste a alocação de tráfego invocando o ponto de extremidade várias vezes:
# You can invoke the endpoint several times
for i in range(30):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
)
Mostre os logs da implantação green para verificar se houve solicitações de entrada e se o modelo foi pontuado com sucesso.
logs = ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Exibir métricas usando o Azure Monitor
Você pode exibir várias métricas (números de solicitação, latência de solicitação, bytes de rede, utilização de CPU/GPU/Disco/Memória e muito mais) de um ponto de extremidade online e suas implantações seguindo os links da página Detalhes do ponto de extremidade no estúdio. Seguir qualquer um desses links leva você à página exata de métricas no portal do Microsoft Azure para o ponto de extremidade ou implantação.

Se você abrir as métricas do ponto de extremidade online, poderá configurar a página para ver as métricas como a latência média da solicitação, conforme mostrado na figura a seguir.

Para obter mais informações sobre como exibir as métricas de ponto de extremidade online, confira Monitorar pontos de extremidade online.
Enviar todo o tráfego para a nova implantação
Quando estiver totalmente satisfeito com a implantação green, alterne todo o tráfego para ela.
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
Excluir a implantação antiga
Remover a implantação antiga (azul):
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).result()
Limpar os recursos
Se você não for usar o ponto de extremidade e a implantação após concluir esse tutorial, deverá excluí-los.
Observação
Espera-se que a exclusão completa leve aproximadamente 20 minutos.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name).result()
Excluir tudo
Use estas etapas para excluir seu workspace do Azure Machine Learning e todos os recursos de computação.
Importante
Os recursos que você criou podem ser usados como pré-requisitos em outros tutoriais e artigos de instruções do Azure Machine Learning.
Se você não pretende usar nenhum dos recursos criados, exclua-os para não gerar custos:
No portal do Azure, na caixa de pesquisa, insira Grupos de recursos e selecione-o nos resultados.
Selecione o grupo de recursos que você criou por meio da lista.
Na página Visão geral, selecione Excluir grupo de recursos.
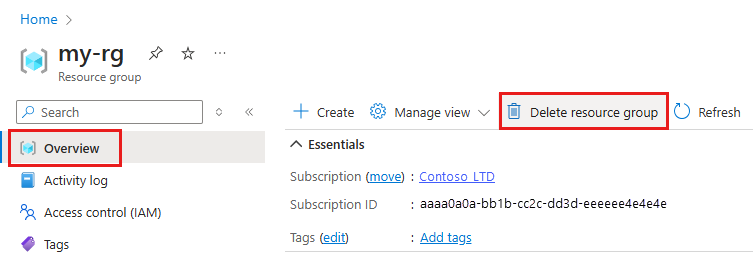
Insira o nome do grupo de recursos. Em seguida, selecione Excluir.