Tutorial: treinar um modelo no Azure Machine Learning
APLICA-SE A:  SDK do Python azure-ai-ml v2 (atual)
SDK do Python azure-ai-ml v2 (atual)
Saiba como um cientista de dados usa o Azure Machine Learning para treinar um modelo. Neste exemplo, você usa um conjunto de dados de cartão de crédito para entender como usar o Azure Machine Learning para um problema de classificação. A meta é prever se um cliente tem uma alta probabilidade de inadimplência em um pagamento de cartão de crédito. O script de treinamento manipula a preparação de dados. Em seguida, o script treina e registra um modelo.
Este tutorial leva você pelas etapas para enviar um trabalho de treinamento baseado em nuvem (trabalho de comando).
- Obter um identificador para o workspace do Azure Machine Learning
- Criar o recurso de computação e o ambiente de trabalho
- Criar seu script de treinamento
- Criar e executar seu trabalho de comando para executar o script de treinamento no recurso de computação
- Exibir a saída do script de treinamento
- Implantar o modelo recém-treinado como um ponto de extremidade
- Chamar o ponto de extremidade do Azure Machine Learning para inferência
Se você quiser saber mais sobre como carregar seus dados no Azure, consulte Tutorial: Carregar, acessar e explorar seus dados no Azure Machine Learning.
Esse vídeo mostra como começar a usar o Estúdio do Azure Machine Learning para que você possa seguir as etapas no tutorial. O vídeo mostra como criar um notebook, criar uma instância de computação e clonar o notebook. Essas etapas estão descritas nas seções a seguir.
Pré-requisitos
-
Para usar o Azure Machine Learning, você precisa de um workspace. Se você não tiver um, conclua Criar recursos necessários para começar para criar um workspace e saber mais sobre como usá-lo.
Importante
Se o seu espaço de trabalho do Azure Machine Learning estiver configurado com uma rede virtual gerenciada, talvez você precise adicionar regras de saída para permitir o acesso aos repositórios públicos de pacotes do Python. Para obter mais informações, confira Cenário: Acessar pacotes públicos de aprendizado de máquina.
-
Entre no estúdio e selecione seu workspace, caso ele ainda não esteja aberto.
-
Abra ou crie um notebook em seu workspace:
- Se você quiser copiar e colar código em células, crie um novo notebook.
- Ou abra tutoriais/get-started-notebooks/train-model.ipynb na seção Exemplos do studio. Em seguida, selecione Clonar para adicionar o bloco de anotações aos seus Arquivos. Para localizar os notebooks de exemplo, confira Aprender com os notebooks de exemplo.
Definir o kernel e abrir no VS Code (Visual Studio Code)
Na barra superior acima do notebook aberto, crie uma instância de computação se você ainda não tiver uma.

Se a instância de computação for interrompida, selecione Iniciar computação e aguarde até que ela esteja em execução.

Aguarde até que a instância de computação esteja em execução. Em seguida, verifique se o kernel, encontrado no canto superior direito, é
Python 3.10 - SDK v2. Caso contrário, use a lista suspensa para selecionar esse kernel.
Se você não vir esse kernel, verifique se a instância de computação está em execução. Se estiver, selecione o botão Atualizar na parte superior direita do notebook.
Se você vir uma barra de notificação dizendo que você precisa de autenticação, selecione Autenticar.
Você pode executar o notebook aqui ou abri-lo no VS Code para um IDE (ambiente de desenvolvimento integrado) completo com o poder dos recursos do Azure Machine Learning. Selecione Abrir no VS Code e, em seguida, selecione a opção Web ou desktop. Quando iniciado dessa forma, o VS Code é anexado à instância de computação, ao kernel e ao sistema de arquivos do workspace.





Importante
O restante deste tutorial contém células do notebook do tutorial. Copie e cole-os em seu novo bloco de anotações ou alterne para o bloco de anotações agora se você cloná-lo.
Use um trabalho de comando para treinar um modelo no Azure Machine Learning
Para treinar um modelo, você precisa enviar um trabalho. O Azure Machine Learning oferece vários tipos diferentes de trabalhos para treinar modelos. Os usuários podem selecionar seu método de treinamento com base na complexidade do modelo, do tamanho dos dados e dos requisitos de velocidade de treinamento. Neste tutorial, você aprenderá a enviar um trabalho de comando para executar um script de treinamento.
Um trabalho de comando é uma função que permite que você envie um script de treinamento personalizado para treinar seu modelo. Esse trabalho também pode ser definido como um trabalho de treinamento personalizado. Um trabalho de comando no Azure Machine Learning é um tipo de trabalho que executa um script ou comando em um ambiente especificado. Você pode usar trabalhos de comando para treinar modelos, processar dados ou qualquer outro código personalizado que deseja executar na nuvem.
Este tutorial se concentra no uso de um trabalho de comando para criar um trabalho de treinamento personalizado que você usa para treinar um modelo. Qualquer trabalho de treinamento personalizado requer os seguintes itens:
- ambiente
- data
- trabalho de comando
- script de treinamento
Este tutorial fornece estes itens para o exemplo: criar um classificador para prever clientes que têm uma alta probabilidade de inadimplência em pagamentos com cartão de crédito.
Criar identificador para o workspace
Antes de se aprofundar no código, você precisa de uma maneira de fazer referência ao seu espaço de trabalho. Crie ml_client para um identificador para o workspace. Em seguida, use ml_client para gerenciar recursos e trabalhos.
Na próxima célula, insira a ID da assinatura, o nome do grupo de recursos e o nome do workspace. Para encontrar esses valores:
- Na barra de ferramentas do Estúdio do Azure Machine Learning superior direito, selecione o nome do espaço de trabalho.
- Copie o valor do espaço de trabalho, do grupo de recursos e da ID da assinatura no código. Você precisa copiar um valor, fechar a área e colar, depois voltar para o próximo.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Observação
A criação do MLClient não se conecta ao workspace. A inicialização do cliente é lenta. Ele aguarda pela primeira vez que precisa fazer uma chamada, o que acontece na próxima célula de código.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
Criar um ambiente de trabalho
Para executar o trabalho do Azure Machine Learning no recurso de computação, é necessário ter um ambiente. Um ambiente lista o runtime de software e as bibliotecas que você deseja instalar na computação em que o treinamento é feito. É semelhante ao ambiente python em seu computador local. Para obter mais informações, confira O que são ambientes do Azure Machine Learning?
O Azure Machine Learning fornece muitos ambientes coletados ou prontos que são úteis para cenários comuns de treinamento e inferência.
Neste exemplo, você cria um ambiente conda personalizado para seus trabalhos usando um arquivo Conda YAML.
Primeiro, crie um diretório para armazenar o arquivo.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
A próxima célula usa a magia IPython para gravar o arquivo conda no diretório que você criou.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=1.0.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- mlflow==2.8.0
- mlflow-skinny==2.8.0
- azureml-mlflow==1.51.0
- psutil>=5.8,<5.9
- tqdm>=4.59,<4.60
- ipykernel~=6.0
- matplotlib
A especificação contém alguns pacotes usuais que você usa em seu trabalho, como numpy e pip.
Use o arquivo yaml para criar e registrar o ambiente personalizado no workspace:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
custom_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults job",
tags={"scikit-learn": "1.0.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
custom_job_env = ml_client.environments.create_or_update(custom_job_env)
print(
f"Environment with name {custom_job_env.name} is registered to workspace, the environment version is {custom_job_env.version}"
)
Configure um trabalho de treinamento usando a função de comando
Crie um trabalho de comando do Azure Machine Learning para treinar um modelo para a previsão de padrão de crédito. O trabalho de comando executa um script de treinamento em um ambiente especificado de um recurso de computação específico. Você já criou o ambiente e o cluster de computação. Em seguida, crie o script de treinamento. Nesse caso, você está treinando o conjunto de dados para produzir um classificador usando o modelo GradientBoostingClassifier.
O script de treinamento manipula a preparação, o treinamento e o registro de dados do modelo treinado. O método train_test_split divide o conjunto de dados em dados de teste e treinamento. Neste tutorial, você criará um script de treinamento do Python.
Os trabalhos de comando podem ser executados na CLI, no SDK do Python ou na interface do estúdio. Neste tutorial, use o SDK do Python do Azure Machine Learning v2 para criar e executar o trabalho de comando.
Criar o script de treinamento
Comece criando o script de treinamento: o arquivo python main.py. Primeiro crie uma pasta de origem para o script:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Esse script pré-processa os dados, dividindo-os em dados de teste e de treinamento. Em seguida, ele consome os dados para treinar um modelo baseado em árvore e retornar o modelo de saída.
O MLFlow é usado para registrar os parâmetros e as métricas durante esse trabalho. O pacote MLFlow permite que você acompanhe as métricas e os resultados de cada modelo de trens do Azure. Use o MLFlow para obter o melhor modelo para seus dados. Em seguida, exiba as métricas do modelo no estúdio do Azure. Para obter mais informações, consulte MLflow e Azure Machine Learning.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
#Split train and test datasets
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Nesse script, depois que o modelo é treinado, o arquivo de modelo é salvo e registrado no workspace. Registrar seu modelo permite que você armazene e controle a versão de seus modelos na nuvem do Azure em seu workspace. Depois de registrar um modelo, você pode encontrar todos os outros modelos registrados em um só lugar no Azure Studio chamado registro de modelo. O registro de modelos ajuda você a organizar e manter o controle sobre seus modelos treinados.
Configurar o comando
Com esse script que pode executar a tarefa de classificação. Use o comando de uso geral para executar ações de linha de comando. Essa ação de linha de comando pode chamar diretamente comandos do sistema ou executar um script.
Crie variáveis de entrada para especificar os dados de entrada, a taxa de divisão, a taxa de aprendizagem e o nome do modelo registrado. O script de comando:
- Usa o ambiente criado anteriormente. Use a notação
@latestpara indicar a versão mais recente do ambiente quando o comando for executado. - Configura a ação de linha de comando em si,
python main.pynesse caso. Você pode acessar as entradas e saídas no comando usando a notação${{ ... }}. - Como um recurso de computação não foi especificado, o script é executado em um cluster de computação sem servidor que é criado automaticamente.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="aml-scikit-learn@latest",
display_name="credit_default_prediction",
)
Enviar o trabalho
Envie o trabalho a ser executado no Estúdio do Azure Machine Learning. Desta vez, use create_or_update em ml_client. ml_client é uma classe cliente que permite que você se conecte à sua assinatura do Azure usando Python e interaja com os serviços do Azure Machine Learning. Oml_client permite que você envie seus trabalhos usando o Python.
ml_client.create_or_update(job)
Exiba a saída do trabalho e aguarde a conclusão dele
Para exibir o trabalho no Estúdio do Azure Machine Learning, selecione o link na saída da célula anterior. A saída desse trabalho é parecida com esta no Estúdio do Azure Machine Learning. Explore as guias para obter vários detalhes, como métricas, saídas etc. Após a conclusão do trabalho, ele registra um modelo em seu workspace como resultado do treinamento.
Importante
Aguarde até que o status do trabalho seja concluído antes de retornar a este bloco de anotações para continuar. O trabalho leva de 2 a 3 minutos para ser executado. Pode levar mais tempo, até 10 minutos, se o cluster de computação tiver sido reduzido para zero nós e o ambiente personalizado ainda estiver sendo criado.
Quando você executa a célula, a saída do notebook mostra um link para a página de detalhes do trabalho no Machine Learning Studio. Como alternativa, você também pode selecionar Trabalhos no menu de navegação à esquerda.
Um trabalho é um agrupamento de diversas execuções de um script ou um código especificados. As informações da execução são armazenadas nesse trabalho. A página de detalhes fornece uma visão geral do trabalho, o tempo necessário para ser executado, quando ele foi criado e outras informações. A página também tem guias para outras informações sobre o trabalho, como métricas, Saídas + logs e código. Aqui estão as guias disponíveis na página de detalhes do trabalho:
- Visão geral: informações básicas sobre o trabalho, incluindo seu status, horários de início e término e o tipo de trabalho que foi executado
- Entradas: os dados e o código que foram usados como entradas para o trabalho. Esta seção pode incluir conjuntos de dados, scripts, configurações de ambiente e outros recursos que foram usados durante o treinamento.
- Saídas + logs: logs gerados enquanto o trabalho estava em execução. Essa guia ajuda a solucionar problemas se algo der errado com seu script de treinamento ou criação de modelo.
- Métricas: Principais métricas de desempenho do seu modelo, como pontuação de treinamento, pontuação f1 e pontuação de precisão.
Limpar os recursos
Se você planeja continuar agora para outros tutoriais, pule para Conteúdo relacionado.
Parar a instância de computação
Se não for usá-la agora, pare a instância de computação:
- No estúdio, na área de navegação à esquerda, selecione Computação.
- Nas guias superiores, selecione Instâncias de computação.
- Selecione a instância de computação na lista.
- Na barra de ferramentas superior, selecione Parar.
Excluir todos os recursos
Importante
Os recursos que você criou podem ser usados como pré-requisitos em outros tutoriais e artigos de instruções do Azure Machine Learning.
Se você não pretende usar nenhum dos recursos criados, exclua-os para não gerar custos:
No portal do Azure, na caixa de pesquisa, insira Grupos de recursos e selecione-o nos resultados.
Selecione o grupo de recursos que você criou por meio da lista.
Na página Visão geral, selecione Excluir grupo de recursos.
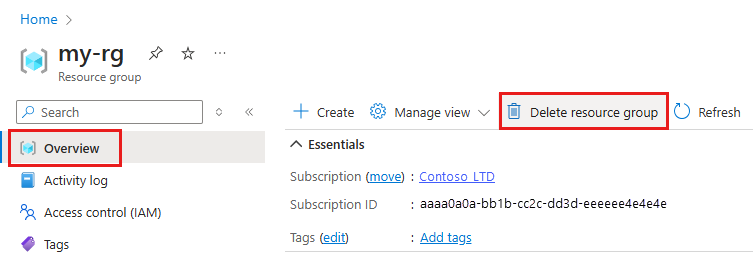
Insira o nome do grupo de recursos. Em seguida, selecione Excluir.
Conteúdo relacionado
Saiba mais sobre como implantar um modelo:
Este tutorial usou um arquivo de dados online. Para saber mais sobre outras maneiras de acessar dados, consulte Tutorial: Carregar, acessar e explorar seus dados no Azure Machine Learning.
O ML automatizado é uma ferramenta complementar para reduzir a quantidade de tempo que um cientista de dados gasta ao encontrar um modelo que funcione melhor com seus dados. Para obter mais informações, consulte O que é aprendizado de máquina automatizado.
Se você quiser mais exemplos semelhantes a este tutorial, consulte Aprender com blocos de anotações de exemplo. Esses exemplos estão disponíveis na página de exemplos do GitHub. Os exemplos incluem Notebooks Python completos que você pode executar código e aprender a treinar um modelo. Você pode modificar e executar scripts existentes a partir dos exemplos, contendo cenários incluindo classificação, processamento de linguagem natural e detecção de anomalias.