Conceitos dos conjunto de habilidades na IA do Azure Search
Este artigo destina-se a desenvolvedores que precisam de uma compreensão mais profunda dos conceitos e composição do conjunto de habilidades e pressupõe familiaridade com os conceitos de alto nível de IA aplicada na Pesquisa de IA do Azure.
Um conjunto de habilidades é um recurso reutilizável na IA do Azure Search que é anexado a um indexador. Ele contém uma ou mais habilidades que chamam a IA interna ou o processamento personalizado externo em documentos recuperados de uma fonte de dados externa.
O diagrama a seguir ilustra o fluxo de dados básico da execução do conjunto de habilidades.
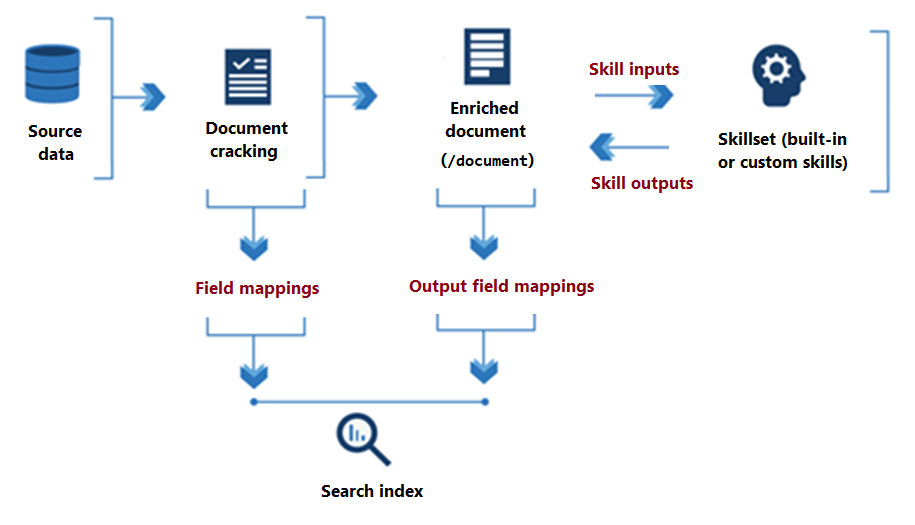
Desde o início do processamento do conjunto de habilidades até a sua conclusão, as habilidades leem e gravam em um documento enriquecido que existe na memória. Inicialmente, um documento enriquecido é apenas o conteúdo bruto extraído de uma fonte de dados (articulado como o nó raiz "/document"). Com cada execução de uma habilidade, o documento enriquecido ganha estrutura e substância à medida que a habilidade grava sua saída como nós no grafo.
Após a execução do conjunto de habilidades, a saída de um documento enriquecido chega a um índice por meio de mapeamentos de campo de saída. Qualquer conteúdo bruto que você desejar que seja transferido intacto, da origem para um índice, é definido por meio de mapeamentos de campo.
Para definir a IA aplicada, especifique as configurações em um conjunto de habilidades e indexador.
Definição de conjunto de qualificações
Um conjunto de habilidades é uma matriz de uma ou mais habilidades que executam um enriquecimento, como traduzir texto ou OCR em um arquivo de imagem. As habilidades podem ser habilidades internas da Microsoft ou habilidades personalizadas para processar lógica que você hospeda externamente. Um conjunto de habilidades produz documentos enriquecidos que são consumidos durante a indexação ou projetados para um repositório de conhecimento.
Todas as habilidades têm contexto, entradas e saídas.
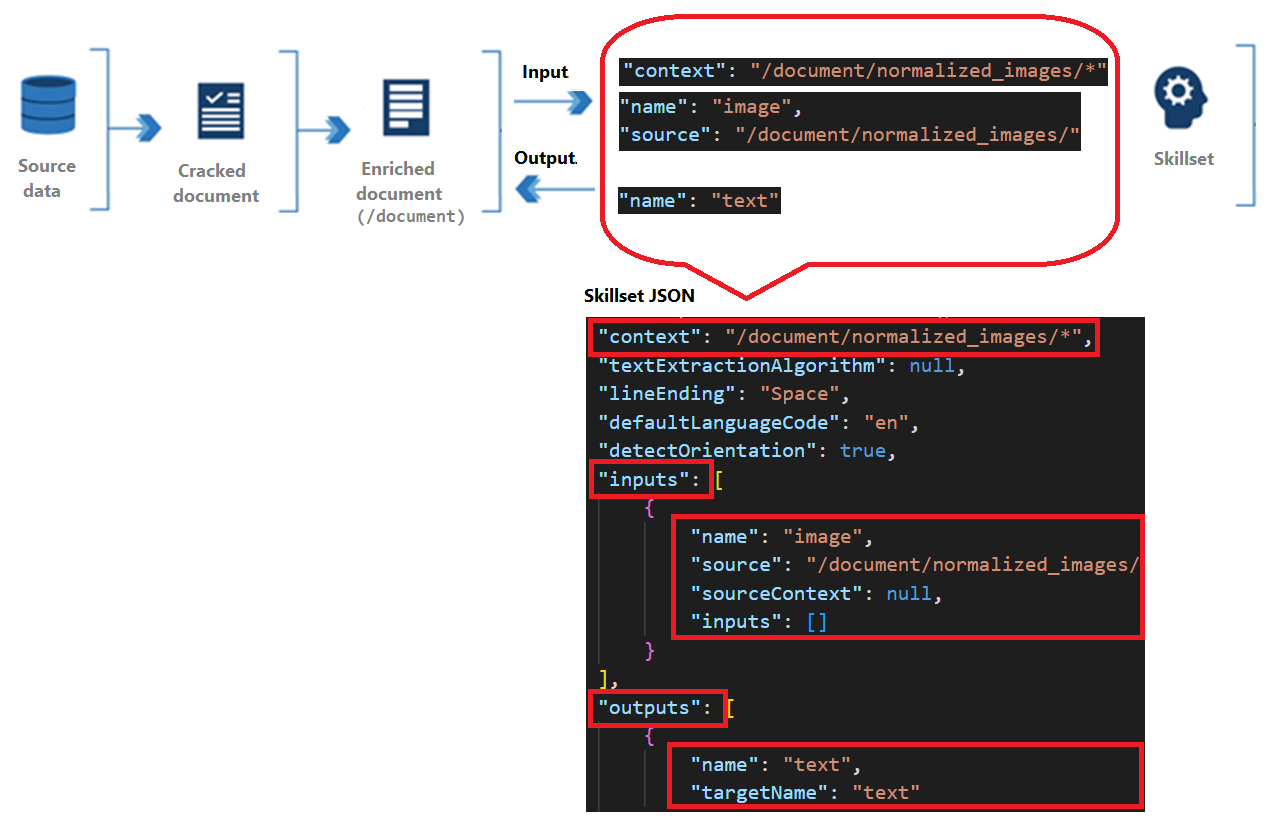
Contexto refere-se ao escopo da operação, que pode ser uma vez por documento ou uma vez para cada item em uma coleção.
As entradas se originam de nós em um documento enriquecido, em que uma "origem" e um "nome" identificam um determinado nó.
A saída é enviada de volta ao documento enriquecido como um novo nó. Os valores são o "nome" e o conteúdo do nó. Se o nome de um nó for duplicado, você poderá definir um nome de destino para eliminar a ambiguidade.
Contexto da habilidade
Cada habilidade tem um contexto, que pode ser o documento inteiro (/document) ou um nó inferior na árvore (/document/countries/*).
Um contexto determina:
O número de vezes que a habilidade é executada, sobre um valor (uma vez por campo, por documento) ou para valores de contexto da coleção de tipos, em que a adição de um
/*resulta na invocação de habilidades, uma vez para cada instância na coleção.Declaração de saída ou o local em que são adicionadas as saídas de habilidades na árvore de enriquecimento. As saídas são sempre adicionadas à árvore como filhos do nó de contexto.
A forma das entradas. Para coleções de vários níveis, a configuração do contexto para a coleção pai afetará a forma da entrada da habilidade. Por exemplo, se você tiver uma árvore de enriquecimento com uma lista de países/regiões, cada uma enriquecida com uma lista de estados que contém uma lista de códigos postais, a maneira como você definir o contexto determinará como a entrada será interpretada.
Contexto Entrada Forma da entrada Invocação de habilidades /document/countries/*/document/countries/*/states/*/zipcodes/*Uma lista de todos os códigos postais no país/região Uma vez por país/região /document/countries/*/states/*/document/countries/*/states/*/zipcodes/*Uma lista de códigos postais no estado Uma vez por combinação de país/região e estado
Dependências de habilidade
As habilidades podem ser executadas de maneira independente e paralela ou sequencialmente, quando você usa a saída de uma habilidade como entrada de outra. O seguinte exemplo demonstra duas habilidades internas executadas em sequência:
A primeira habilidade é uma habilidade de Divisão de Texto que aceita o conteúdo do campo de origem “reviews_text” como entrada e divide esse conteúdo em “páginas” de 5 mil caracteres como saída. Dividir texto grande em partes menores pode produzir resultados melhores para habilidades como a detecção de sentimento.
A segunda habilidade é uma Habilidade de detecção de sentimentos que aceita “páginas” como entrada e produz um novo campo chamado “Sentimento” como saída que contém os resultados da análise de sentimentos.
Observe como a saída da primeira habilidade ("pages") é usada na análise de sentimento, em que "/document/reviews_text/pages/*" é o contexto e a entrada. Para obter mais informações sobre formulação de caminho, veja Como fazer referência a enriquecimentos.
{
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SentimentSkill",
"name": "#2",
"description": null,
"context": "/document/reviews_text/pages/*",
"defaultLanguageCode": "en",
"inputs": [
{
"name": "text",
"source": "/document/reviews_text/pages/*",
}
],
"outputs": [
{
"name": "sentiment",
"targetName": "sentiment"
},
{
"name": "confidenceScores",
"targetName": "confidenceScores"
},
{
"name": "sentences",
"targetName": "sentences"
}
]
}
. . .
]
}
Árvore de enriquecimento
Um documento enriquecido é uma estrutura de dados temporária, com formato de árvore, criada durante a execução do conjunto de habilidades e que coleta todas as alterações introduzidas pelas habilidades. Coletivamente, os enriquecimentos são representados como uma hierarquia de nós endereçáveis. Os nós também incluem os campos não enriquecidos que são passados verbatim da fonte de dados externa.
Um documento enriquecido existe pela duração da execução do conjunto de habilidades, mas pode ser armazenado em cache ou enviado para um repositório de conhecimento.
Inicialmente, um documento enriquecido é simplesmente o conteúdo extraído de uma fonte de dados durante quebra de documento, em que texto e imagens são extraídos da origem e disponibilizados para análise de idioma ou imagem.
O conteúdo inicial são metadados e o nó raiz (document/content). O nó raiz geralmente é um documento inteiro ou uma imagem normalizada extraída de uma fonte de dados durante a quebra de documento. A maneira como isso é articulado em uma árvore de enriquecimento varia para cada tipo de fonte de dados. A seguinte tabela mostra o estado de um documento entrando no pipeline de enriquecimento de diversas fontes de dados compatíveis:
| Fonte de dados\Modo de análise | Padrão | JSON, linhas JSON & CSV |
|---|---|---|
| Armazenamento de Blobs | /document/content /document/normalized_images/* … |
/document/{key1} /document/{key2} … |
| SQL do Azure | /document/{column1} /document/{column2} … |
N/D |
| Azure Cosmos DB | /document/{key1} /document/{key2} … |
N/D |
Conforme as habilidades são executadas, a saída é adicionada à árvore de enriquecimento como novos nós. Se a execução da habilidade for feita em todo o documento, nós serão adicionados no primeiro nível sob a raiz.
Os nós podem ser usados como entradas para habilidades downstream. Por exemplo, habilidades que criam conteúdo, como cadeias de caracteres traduzidas, podem se tornar a entrada de habilidades que reconhecem entidades ou extraem frases-chave.
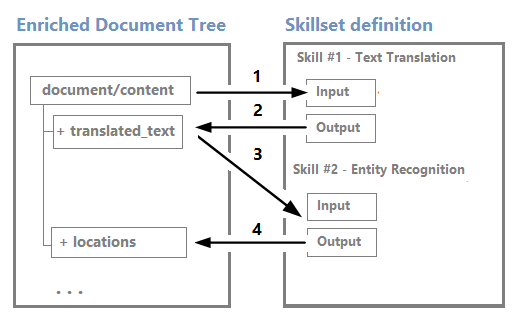
Embora você possa visualizar uma árvore de enriquecimento e trabalhar com ela usando o editor visual das Sessões de Depuração, ela é principalmente uma estrutura interna.
Os enriquecimentos são imutáveis: uma vez criados, os nós não podem ser editados. À medida que seus conjuntos de habilidades se tornam mais complexos, a árvore de enriquecimento também aumenta, mas nem todos os nós da árvore de enriquecimento precisam chegar ao índice ou ao repositório de conhecimento.
Você pode persistir seletivamente apenas um subconjunto das saídas de enriquecimento para que mantenha apenas o que pretende usar. Os mapeamentos de campo de saída na definição do indexador determinarão qual conteúdo realmente é ingerido no índice de pesquisa. Da mesma forma, se você estiver criando um repositório de conhecimento, poderá mapear saídas para formas que são atribuídas a projeções.
Observação
O formato da árvore de enriquecimento permite ao pipeline de enriquecimento anexar metadados até mesmo aos tipos de dados primitivos. Os metadados não serão um objeto JSON válido, mas podem ser projetados em um formato JSON válido em definições de projeção em um repositório de conhecimento. Para obter mais informações, confira Habilidade Modelador.
Definição de indexador
Um indexador tem propriedades e parâmetros usados para configurar a execução do indexador. Entre essas propriedades estão os mapeamentos que definem o caminho de dados para os campos em um índice de pesquisa.

Há dois conjuntos de mapeamentos:
"fieldMappings" mapeiam um campo de origem para um campo de pesquisa.
"outputFieldMappings" mapeiam um nó em um documento enriquecido para um campo de pesquisa.
A propriedade "sourceFieldName" especifica um campo em sua fonte de dados ou um nó em uma árvore de enriquecimento. A propriedade "targetFieldName" especifica o campo de pesquisa em um índice que recebe o conteúdo.
Exemplo de enriquecimento
Usando o conjunto de habilidades de avaliações de hotel como um ponto de referência, este exemplo explica como uma árvore de enriquecimento evolui por meio da execução de habilidades usando diagramas conceituais.
O exemplo também mostra:
- Como o contexto e as entradas de uma habilidade funcionam para determinar quantas vezes uma habilidade é executada
- Qual é a forma da entrada, com base no contexto
Neste exemplo, os campos de origem de um arquivo CSV incluem avaliações do cliente sobre hotéis ("reviews_text") e classificações ("reviews_rating"). O indexador adiciona campos de metadados do Armazenamento de Blobs e as habilidades adicionam texto traduzido, pontuações de sentimento e detecção de frases-chave.
No exemplo de avaliações de hotel, um “documento” dentro do processo de enriquecimento representa uma avaliação de hotel.
Dica
Você pode criar um índice de pesquisa e armazenamento de conhecimento para esses dados no portal do Azure ou APIs REST. Você também pode usar Sessões de Depuração para insights na composição, nas dependências e nos efeitos do conjunto de habilidades em uma árvore de enriquecimento. As imagens neste artigo são retiradas de Sessões de Depuração.
De modo conceitual, a árvore de enriquecimento inicial tem a seguinte aparência:

O nó raiz de todos os enriquecimentos é "/document". Quando você trabalha com indexadores de blob, o nó "/document" terá os nós filhos "/document/content" e "/document/normalized_images". Quando os dados são CSV, como neste exemplo, os nomes das colunas serão mapeados para os nós abaixo de "/document".
Habilidade nº 1: habilidade de divisão
Quando o conteúdo de origem consiste em grandes segmentos de texto, é útil dividi-lo em componentes menores para maior precisão de linguagem, de sentimentos e de detecção de frases-chave. Há duas granulações disponíveis: páginas e frases. Uma página consiste em aproximadamente 5 mil caracteres.
Uma habilidade de divisão de texto normalmente é a primeira em um conjunto de habilidades.
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
Com o contexto de habilidade de "/document/reviews_text", a habilidade de divisão é executada uma vez para reviews_text. A saída de habilidade é uma lista em que reviews_text é dividido em segmentos de 5 mil caracteres. A saída da habilidade de divisão é chamada pages e é adicionada à árvore de enriquecimento. O recurso targetName permite renomear uma saída de habilidade antes que ela seja adicionada à árvore de enriquecimento.
A árvore de enriquecimento agora tem um novo nó colocado no contexto da habilidade. Este nó está disponível para qualquer habilidade, projeção ou mapeamento de campo de saída.

Para acessar qualquer um dos enriquecimentos adicionados a um nó por uma habilidade, é necessário o caminho completo para o enriquecimento. Por exemplo, se você quiser usar o texto do nó pages como entrada para outra habilidade, precisará especificá-lo como "/document/reviews_text/pages/*". Para obter mais informações sobre caminhos, veja Enriquecimentos de referência.
Habilidade nº 2: detecção de idioma
Os documentos de resenhas de hotéis incluem comentários de clientes expressos em vários idiomas. A habilidade de detecção do idioma determina qual idioma é usado. Em seguida, o resultado será passado para a extração de frases-chave e detecção de sentimentos (não mostrado), levando o idioma em consideração ao detectar sentimentos e frases.
Embora a habilidade de detecção de idioma seja a terceira (habilidade nº 3) definida no conjunto de habilidades, ela é a próxima habilidade a ser executada. Ela não requer nenhuma entrada, portanto, é executada em paralelo com a habilidade anterior. Como a habilidade de divisão que a precedeu, a habilidade de detecção de idioma também é invocada uma vez para cada documento. A árvore de enriquecimento agora tem um novo nó para o idioma.

Habilidades nº 3 e nº 4 (análise de sentimento e detecção de frases-chave)
Os comentários dos clientes refletem uma variedade de experiências positivas e negativas. A habilidade de análise de sentimento analisa os comentários e atribui uma pontuação ao longo de uma faixa de números negativos a positivos ou neutro, se o sentimento for indeterminado. Paralelo à análise de sentimento, a detecção de frases-chave identifica e extrai palavras e frases curtas que parecem consequenciais.
Dado o contexto de /document/reviews_text/pages/*, as habilidades de frases-chave e análise de sentimento serão invocadas uma vez para cada um dos itens na coleção pages. A saída da habilidade será um nó no elemento de página associado.
Agora você deve poder examinar o restante das habilidades no conjunto de habilidades e visualizar como a árvore de enriquecimentos continuará a crescer com a execução de cada habilidade. Algumas habilidades, como a de mesclagem e a de formatação, também criam novos nós, mas apenas usam dados de nós existentes e não criam novos enriquecimentos.

As cores dos conectores na árvore acima indicam que os enriquecimentos foram criados por diferentes habilidades e os nós precisarão ser endereçados individualmente e não farão parte do objeto retornado ao selecionar o nó pai.
Habilidade nº 5 Habilidade Modelador
Se a saída incluir um repositório de conhecimento, adicione uma Habilidade Modelador como uma última etapa. A habilidade de Modelador cria formas de dados fora dos nós em uma árvore de enriquecimento. Por exemplo, talvez você queira consolidar vários nós em uma forma. Em seguida, você pode projetar essa forma como uma tabela (nós se tornam as colunas em uma tabela), passando a forma pelo nome para uma projeção de tabela.
A habilidade de Modelador é fácil de trabalhar, pois ela enfoca a formatação sob uma habilidade. Como alternativa, você pode optar pela formatação em linha dentro de projeções individuais. A habilidade de Shaper não adiciona nem reduz de uma árvore de enriquecimento, e portanto não é visualizada. Em vez disso, você pode considerar uma habilidade de Shaper como o meio pelo qual rearticula a árvore de enriquecimento que já tem. Conceitualmente, isso é semelhante à criação de modos de exibição de tabelas em um banco de dados.
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"description": null,
"context": "/document",
"inputs": [
{
"name": "name",
"source": "/document/name"
},
{
"name": "reviews_date",
"source": "/document/reviews_date"
},
{
"name": "reviews_rating",
"source": "/document/reviews_rating"
},
{
"name": "reviews_text",
"source": "/document/reviews_text"
},
{
"name": "reviews_title",
"source": "/document/reviews_title"
},
{
"name": "AzureSearch_DocumentKey",
"source": "/document/AzureSearch_DocumentKey"
},
{
"name": "pages",
"sourceContext": "/document/reviews_text/pages/*",
"inputs": [
{
"name": "Sentiment",
"source": "/document/reviews_text/pages/*/Sentiment"
},
{
"name": "LanguageCode",
"source": "/document/Language"
},
{
"name": "Page",
"source": "/document/reviews_text/pages/*"
},
{
"name": "keyphrase",
"sourceContext": "/document/reviews_text/pages/*/Keyphrases/*",
"inputs": [
{
"name": "Keyphrases",
"source": "/document/reviews_text/pages/*/Keyphrases/*"
}
]
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "tableprojection"
}
]
}
Próximas etapas
Com o apoio de uma introdução e um exemplo, tente criar seu primeiro conjunto de habilidades usando habilidades internas.