Relevância na pesquisa de palavras-chave (pontuação BM25)
Este artigo explica o algoritmo de pontuação de relevância do BM25 usados para calcular as pontuações de pesquisa para pesquisa de texto completo. A relevância do BM25 é exclusiva da pesquisa de texto completo. Consultas de filtro, preenchimento automático e consultas sugeridas, pesquisa com curinga e consultas de pesquisa difusa não são pontuadas ou classificadas por relevância.
Algoritmos de pontuação usados na pesquisa de texto completo
A IA do Azure Search fornece os seguintes algoritmos de pontuação para pesquisa de texto completo:
| Algoritmo | Uso | Intervalo |
|---|---|---|
BM25Similarity |
Algoritmo corrigido em todos os serviços de pesquisa criados após julho de 2020. É possível configurar esse algoritmo, mas não pode alternar para um mais antigo (clássico). | Não associado. |
ClassicSimilarity |
Padrão em serviços de pesquisa mais antigos que antecedem julho de 2020. Em serviços mais antigos, você pode aceitar o uso do BM25 e escolher o algoritmo BM25 por índice. | 0 < 1,00 |
O BM25 e o Clássico são funções de recuperação do tipo TF-IDF que usam a TF (frequência de termos) e a IDF (frequência de documento inversa) como variáveis para calcular as pontuações de relevância para cada par de consulta de documento, que é usado para classificação dos resultados. Embora conceitualmente semelhante ao clássico, o BM25 tem raiz na recuperação de informações do probabilística que produz correspondências mais intuitivas, conforme medido pela pesquisa do usuário.
O BM25 oferece opções avançadas de personalização, como permitir que o usuário decida como a classificação de relevância é dimensionada com a frequência do termo dos termos correspondentes.
Como funciona a classificação do BM25
A pontuação de relevância se refere à computação de uma pontuação de pesquisa (@search.score), que serve como um indicador da relevância de um item no contexto da consulta atual. O intervalo não está associado. Entretanto, quanto maior a pontuação, mais relevante será o item.
A pontuação de pesquisa é calculada com base nas propriedades estatísticas da entrada da cadeia de caracteres e da consulta em si. A IA do Azure Search localiza documentos que correspondem aos termos de pesquisa (alguns ou todos, dependendo do searchMode), favorecendo documentos que contêm muitas instâncias do termo de pesquisa. A pontuação de pesquisa aumentará ainda mais se o termo for raro no índice de dados, mas comum no documento. A base para essa abordagem de cálculo de relevância é conhecida como TF-IDF ou, frequência do termo-inverso da frequência nos documentos.
As pontuações de pesquisa podem ser repetidas em todo um conjunto de resultados. Quando várias ocorrências têm a mesma pontuação de pesquisa, a ordenação dos mesmos itens pontuados é indefinida e instável. Execute a consulta novamente e você poderá observar os itens mudarem de posição, principalmente se você estiver usando o serviço gratuito ou um serviço faturável com várias réplicas. Se houver dois itens com uma pontuação idêntica, não há garantia de qual deles aparecerá primeiro.
Para interromper o empate entre pontuações repetidas, você pode adicionar uma cláusula $orderby para ordenar primeiro por pontuação e depois por outro campo classificável (por exemplo, $orderby=search.score() desc,Rating desc).
Somente campos marcados como searchable no índice ou searchFields na consulta são usados para a pontuação. Somente campos marcados como retrievable ou campos especificados em select na consulta são retornados nos resultados da pesquisa, juntamente com sua pontuação de pesquisa.
Observação
Um @search.score = 1 indica um conjunto de resultados sem pontuação ou sem classificação. A pontuação é uniforme entre todos os resultados. Os resultados sem pontuação ocorrem quando o formulário de consulta é pesquisa difusa, consultas curinga ou Regex ou uma pesquisa vazia (search=* às vezes, emparelhada com filtros, em que o filtro é o meio principal para retornar uma correspondência).
O segmento de vídeo a seguir avança rapidamente para uma explicação dos algoritmos de classificação de geralmente disponíveis, usados na IA do Azure Search. Para obter mais informações, assista ao vídeo completo.
Pontuações em resultados de texto
Sempre que os resultados são classificados, a propriedade @search.score contém o valor usado para ordenar os resultados.
A tabela a seguir identifica a propriedade de pontuação, o algoritmo e o intervalo.
| Método Search | Parâmetro | Algoritmo de pontuação | Intervalo |
|---|---|---|---|
| pesquisa de texto completo | @search.score |
Algoritmo do BM25, usando os parâmetros de especificados no índice. | Não associado. |
Variação de pontuação
As pontuações de pesquisa indicam a relevância geral, refletindo o grau da correspondência em relação a outros documentos no mesmo conjunto de resultados. Mas as pontuações nem sempre são consistentes de uma consulta para a outra, assim, à medida que você trabalha com consultas, pode notar pequenas discrepâncias na ordenação dos documentos de pesquisa. Há várias explicações para isso.
| Causa | Descrição |
|---|---|
| Pontuações idênticas | Quando vários documentos têm a mesma pontuação, qualquer um deles pode aparecer primeiro. |
| Volatilidade de dados | O conteúdo do índice varia quando você adiciona, modifica ou exclui documentos. As frequências de termo mudam conforme as atualizações de índice são processadas ao longo do tempo, afetando as pontuações de pesquisa de documentos correspondentes. |
| Várias réplicas | Para serviços que usam várias réplicas, as consultas são emitidas em cada réplica em paralelo. As estatísticas de índice usadas para calcular uma pontuação de pesquisa são calculadas por réplica, com os resultados mesclados e ordenados na resposta da consulta. As réplicas são, na maioria, espelhos umas das outras, mas as estatísticas podem ser diferentes devido a pequenas diferenças no estado. Por exemplo, é possível que documentos excluídos entrem nas estatísticas de uma réplica, mas sejam eliminados pela mesclagem em outras réplicas. Normalmente, as diferenças nas estatísticas por réplica são mais perceptíveis em índices menores. A seção a seguir fornece mais informações sobre essa condição. |
Efeitos da fragmentação nos resultados da consulta
Um fragmento é um pedaço de um índice. A Pesquisa de IA do Azure subdivide um índice em fragmentos para tornar o processo de adição de partições mais rápido (movendo fragmentos para novas unidades de pesquisa). Em um serviço de pesquisa, o gerenciamento de fragmentos é um detalhe de implementação e não é configurável, mas saber que um índice é fragmentado ajuda a entender as anomalias ocasionais nos comportamentos de classificação e preenchimento automático:
Classificação de anomalias: as pontuações de pesquisa são computadas primeiro no nível do fragmento e depois agregadas em um conjunto de resultados. Dependendo das características do conteúdo do fragmento, as correspondências de um fragmento podem ter uma classificação maior do que as correspondências em outro. Se você observar classificações contra-intuitivas nos resultados da pesquisa, isso provavelmente ocorre devido aos efeitos da fragmentação, especialmente se os índices forem baixos. Você pode evitar essas anomalias de classificação escolhendo computar pontuações globalmente em todo o índice, mas isso incorrerá em uma penalidade de desempenho.
Anomalias de preenchimento automático: as consultas de preenchimento automático, nas quais as correspondências são feitas nos primeiros caracteres de um termo parcialmente inserido, aceitam um parâmetro difuso que ignora pequenos erros de ortografia. Para preenchimento automático, a correspondência difusa é restrita a termos dentro do fragmento atual. Por exemplo, se um fragmento contiver “Microsoft” e um termo parcial de “micro” for inserido, o mecanismo de pesquisa corresponderá a “Microsoft” nesse fragmento, mas não em outros fragmentos que contêm as partes restantes do índice.
O diagrama a seguir mostra o relacionamento entre as réplicas, partições, fragmentos e unidades de pesquisa. Ele mostra um exemplo de como um índice é estendido em quatro unidades de pesquisa em um serviço com duas réplicas e duas partições. Cada uma das quatro unidades de pesquisa armazena apenas metade dos fragmentos do índice. As unidades de pesquisa na coluna à esquerda armazenam a primeira metade dos fragmentos, composta pela primeira partição, enquanto aquelas na coluna à direita armazenam a segunda metade dos fragmentos, composta pela segunda partição. Como há duas réplicas, há duas cópias de cada fragmento de índice. As unidades de pesquisa na linha superior armazenam uma cópia, composta pela primeira réplica, enquanto as unidades na linha inferior armazenam outra cópia, composta pela segunda réplica.
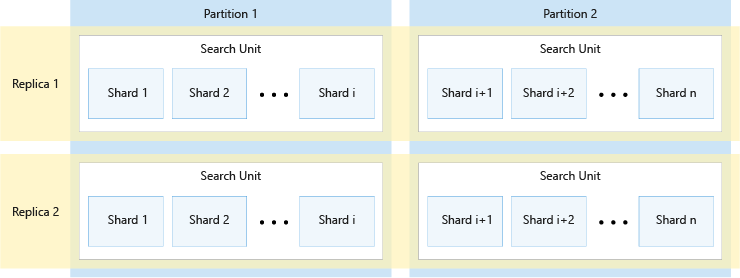
O diagrama acima é apenas um exemplo. Muitas combinações de partições e réplicas são possíveis, até um máximo de 36 unidades de pesquisa no total.
Observação
O número de réplicas e partições divide de maneira uniforme em 12 (especificamente, 1, 2, 3, 4, 6 e 12). A IA do Azure Search divide previamente cada índice em 12 fragmentos, para que ele possa ser distribuído em partes iguais entre todas as partições. Por exemplo, se o serviço tiver três partições e você criar um índice, cada partição conterá quatro fragmentos do índice. A maneira como a IA do Azure Search fragmenta um índice é um detalhe de implementação, sujeito a alterações em versões futuras. Embora o número seja 12 hoje, você não deve esperar que ele seja sempre 12 no futuro.
Estatísticas de pontuação e sessões temporárias
Para escalabilidade, a IA do Azure Search distribui cada índice horizontalmente por meio de um processo de fragmentação, o que significa que partes de um índice são fisicamente separadas.
Por padrão, a pontuação de um documento é calculada com base nas propriedades estatísticas dos dados dentro de um fragmento. Essa abordagem geralmente não é um problema para uma grande corpus de dados e fornece um melhor desempenho do que ter que calcular a pontuação com base nas informações de todos os fragmentos. Dito isso, o uso dessa otimização de desempenho pode fazer com que dois documentos muito semelhantes (ou até mesmo idênticos) acabem com pontuações de relevância diferentes se eles terminarem em fragmentos diferentes.
Se preferir calcular a pontuação com base nas propriedades estatísticas de todos os fragmentos, você pode fazer isso adicionando scoringStatistics=global como um parâmetro de consulta (ou adicionar "scoringStatistics": "global" como um parâmetro de corpo da solicitação de consulta).
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
O uso de scoringStatistics garantirá que todos os fragmentos na mesma réplica forneçam os mesmos resultados. Dito isso, diferentes réplicas podem ser ligeiramente diferentes umas das outras, pois estão sempre sendo atualizadas com as alterações mais recentes no seu índice. Em alguns cenários, talvez você queira que seus usuários obtenham resultados mais consistentes durante uma "sessão de consulta". Nesses cenários, você pode fornecer um sessionId como parte de suas consultas. O sessionId é uma cadeia de caracteres única que você cria para se referir a uma sessão de usuário exclusiva.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"sessionId": "<string>"
}
Enquanto o mesmo sessionId for usado, é feita uma tentativa de melhor esforço para atingir a mesma réplica, aumentando a consistência dos resultados que os usuários verão.
Observação
Reutilizar os mesmos valores sessionId repetidamente pode interferir no balanceamento de carga das solicitações entre réplicas e afetar adversamente o desempenho do serviço de pesquisa. O valor usado como sessionId não pode começar com um caractere “_”.
Ajuste de relevância
Na Pesquisa de IA do Azure, para pesquisa por palavra-chave e a parte de texto de uma consulta híbrida, você pode configurar os parâmetros do algoritmo BM25 além de ajustar a relevância da pesquisa e aumentar as pontuações de pesquisa por meio dos seguintes mecanismos.
| Abordagem | Implementação | Descrição |
|---|---|---|
| Configuração do algoritmo BM25 | Índice de pesquisa | Configure como o comprimento do documento e a frequência do termo afetam a classificação de relevância. |
| Perfis de pontuação | Índice de pesquisa | Forneça critérios para aumentar a pontuação de pesquisa de uma correspondência com base nas características do conteúdo. Por exemplo, você pode aumentar as correspondências com base no potencial de receita, promover itens mais novos ou talvez aumentar itens que estão em estoque há muito tempo. Um perfil de pontuação faz parte da definição de índice, composta por funções, parâmetros e campos ponderados. É possível atualizar um índice existente com alterações de perfil de pontuação, sem incorrer em uma recompilação de índice. |
| Classificação semântica | Solicitação de consulta | Aplica a compreensão de leitura do computador aos resultados da pesquisa, promovendo resultados mais semanticamente relevantes para a parte superior. |
| Parâmetro featuresMode | Solicitação de consulta | Esse parâmetro é usado principalmente para desempacotar uma pontuação classificada BM25, mas pode ser usado no código que fornece uma solução de pontuação personalizada. |
Parâmetro featuresMode (versão prévia)
As solicitações Pesquisar Documentos dão suporte a um parâmetro featuresMode que fornece mais detalhes sobre a pontuação de relevância BM25 no nível do campo. Enquanto o @searchScore é calculado para todo o documento (relevância desse documento no contexto dessa consulta), o featuresMode revela informações sobre campos individuais, conforme expresso em uma estrutura @search.features. A estrutura contém todos os campos usados na consulta (tanto campos específicos por meio do searchFields em uma consulta, quanto todos os campos atribuídos como pesquisáveis em um índice).
Para cada campo, você fornece aos @search.features os seguintes valores:
- Número de tokens exclusivos encontrados no campo
- Pontuação de similaridade ou uma medida de semelhança do conteúdo do campo relativas ao termo da consulta
- Frequência de termos ou o número de vezes que o termo de consulta foi encontrado no campo
Para uma consulta que tem como alvo os campos "Descrição" e "título", uma resposta que o inclui @search.features pode ter esta aparência:
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
Você pode consumir esses pontos de dados em soluções de pontuação personalizada ou usar as informações para depurar problemas de relevância de pesquisa.
O parâmetro featuresMode não está documentado nas APIs REST, mas você pode usá-lo em uma chamada de API REST de visualização para pesquisar documentos para pesquisa de texto (palavra-chave) classificada como BM25.
Número de resultados classificados em uma resposta de consulta de texto completo
Por padrão, caso não esteja usando paginação, o mecanismo de pesquisa retornará as 50 principais correspondências de classificação mais altas para pesquisa de texto completo. Você pode usar o parâmetro top para retornar um número menor ou maior de itens (até 1.000 em uma única resposta). Você pode usar skip e next para paginar os resultados. A paginação determina o número de resultados em cada página lógica e oferece suporte à navegação de conteúdo. Para obter mais informações, consulte Formatar os resultados da pesquisa.
A pesquisa de texto completo está sujeita a um limite máximo de 1.000 correspondências (confira limites de resposta da API). Depois de encontrar 1.000 correspondências, o mecanismo de pesquisa parará de procurar.