Migrar metadados do metastore do Hive do Azure Synapse Analytics para o Fabric
A etapa inicial na migração do metastore do Hive (HMS) envolve determinar os bancos de dados, tabelas e partições que você deseja transferir. Não é necessário migrar tudo; você pode selecionar bancos de dados específicos. Depois de identificar os bancos de dados para migração, verifique se há tabelas do Spark gerenciadas ou externas.
Para considerações sobre HMS, confira diferenças entre o Spark do Azure Synapse e o Fabric.
Observação
Como alternativa, se o ADLS Gen2 contiver tabelas Delta, você poderá criar um atalho do OneLake para uma tabela Delta no ADLS Gen2.
Pré-requisitos
- Se você ainda não tiver um, crie um workspace do Fabric em seu locatário.
- Se você ainda não tiver um, crie um lakehouse do Fabric no seu workspace.
Opção 1: exportar e importar o HMS para o metastore do lakehouse
Siga estas etapas importantes para migração:
- Etapa 1: exportar metadados do HMS de origem
- Etapa 2: importar metadados para o lakehouse do Fabric
- Etapas pós-migração: validar o conteúdo
Observação
Os scripts copiam apenas objetos do catálogo do Spark para o lakehouse do Fabric. A suposição é que os dados já foram copiados (por exemplo, do local do warehouse para o ADLS Gen2) ou estão disponíveis para tabelas gerenciadas e externas (por exemplo, por meio de atalhos – preferenciais) no lakehouse do Fabric.
Etapa 1: exportar metadados do HMS de origem
O foco da Etapa 1 é exportar os metadados do HMS de origem para a seção Arquivos do lakehouse do Fabric. Esse processo é o seguinte:
1.1) Importe o notebook de exportação de metadados HMS para o workspace do Azure Synapse. Esse notebook consulta e exporta metadados HMS de bancos de dados, tabelas e partições para um diretório intermediário no OneLake (funções ainda não incluídas). A API do catálogo interno do Spark é usada nesse script para ler objetos do catálogo.
1.2) Configure os parâmetros no primeiro comando para exportar informações de metadados para um armazenamento intermediário (OneLake). O snippet a seguir é usado para configurar os parâmetros de origem e destino. Substitua-os por seus próprios valores.
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) Execute todos os comandos do notebook para exportar objetos do catálogo para o OneLake. Depois que as células forem preenchidas, essa estrutura de pastas no diretório de saída intermediário será criada.
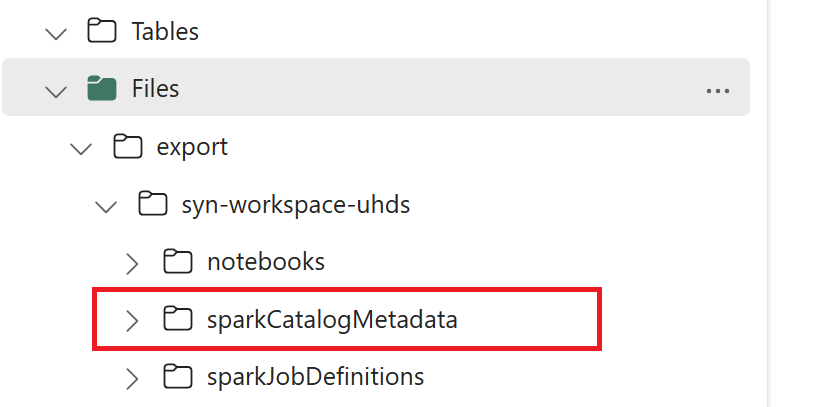
Etapa 2: importar metadados para o lakehouse do Fabric
A etapa 2 é quando os metadados reais são importados do armazenamento intermediário para o lakehouse do Fabric. A saída dessa etapa é a migração de todos os metadados HMS (bancos de dados, tabelas e partições). Esse processo é o seguinte:
2.1) Crie um atalho na seção “Arquivos” do lakehouse. Esse atalho precisa apontar para o diretório de origem do warehouse do Spark e será usado posteriormente substituir as tabelas gerenciadas do Spark. Veja exemplos de atalho apontando para o diretório do warehouse do Spark:
- Caminho de atalho para o diretório do warehouse do Spark do Azure Synapse:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - Caminho de atalho para o diretório do warehouse do Azure Databricks:
dbfs:/mnt/<warehouse_dir> - Caminho de atalho para o diretório do warehouse do Spark do HDInsight:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- Caminho de atalho para o diretório do warehouse do Spark do Azure Synapse:
2.2) Importe o notebook de importação de metadados HMS para o workspace do Fabric. Importe este notebook para importar objetos de banco de dados, tabela e partição do armazenamento intermediário. A API do catálogo interno do Spark é usada nesse script para criar’ objetos do catálogo no Fabric.
2.3) Configure os parâmetros no primeiro comando. No Apache Spark, quando você cria uma tabela gerenciada, os dados dela são armazenados em um local gerenciado pelo próprio Spark, normalmente no diretório do warehouse do Spark. O local exato é determinado pelo Spark. Já nas tabelas externas, você especifica o local e gerencia os dados subjacentes. Quando você migra os metadados de uma tabela gerenciada (sem mover os dados reais), os metadados mantêm as informações de localização originais que apontam para o antigo diretório do warehouse do Spark. Portanto, para tabelas gerenciadas,
WarehouseMappingsé usado para fazer a substituição usando o atalho criado na Etapa 2.1. Todas as tabelas gerenciadas de origem são convertidas como tabelas externas usando esse script.LakehouseIdrefere-se ao lakehouse criado na Etapa 2.1 que contém atalhos.// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) Execute todos os comandos do notebook para importar objetos do catálogo do caminho intermediário.
Observação
Ao importar vários bancos de dados, você pode (i) criar um lakehouse por banco de dados (a abordagem usada aqui) ou (ii) mover todas as tabelas de bancos de dados diferentes para um único lakehouse. Para a segunda opção, todas as tabelas migradas podem ser <lakehouse>.<db_name>_<table_name>, e você precisará ajustar o notebook de importação adequadamente.
Etapa 3: validar conteúdo
A etapa 3 é onde você valida a migração dos metadados. Veja diversos exemplos.
Você pode ver os bancos de dados importados em execução:
%%sql
SHOW DATABASES
Você pode verificar todas as tabelas em um lakehouse (banco de dados) executando:
%%sql
SHOW TABLES IN <lakehouse_name>
Você pode ver os detalhes de uma tabela específica executando:
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
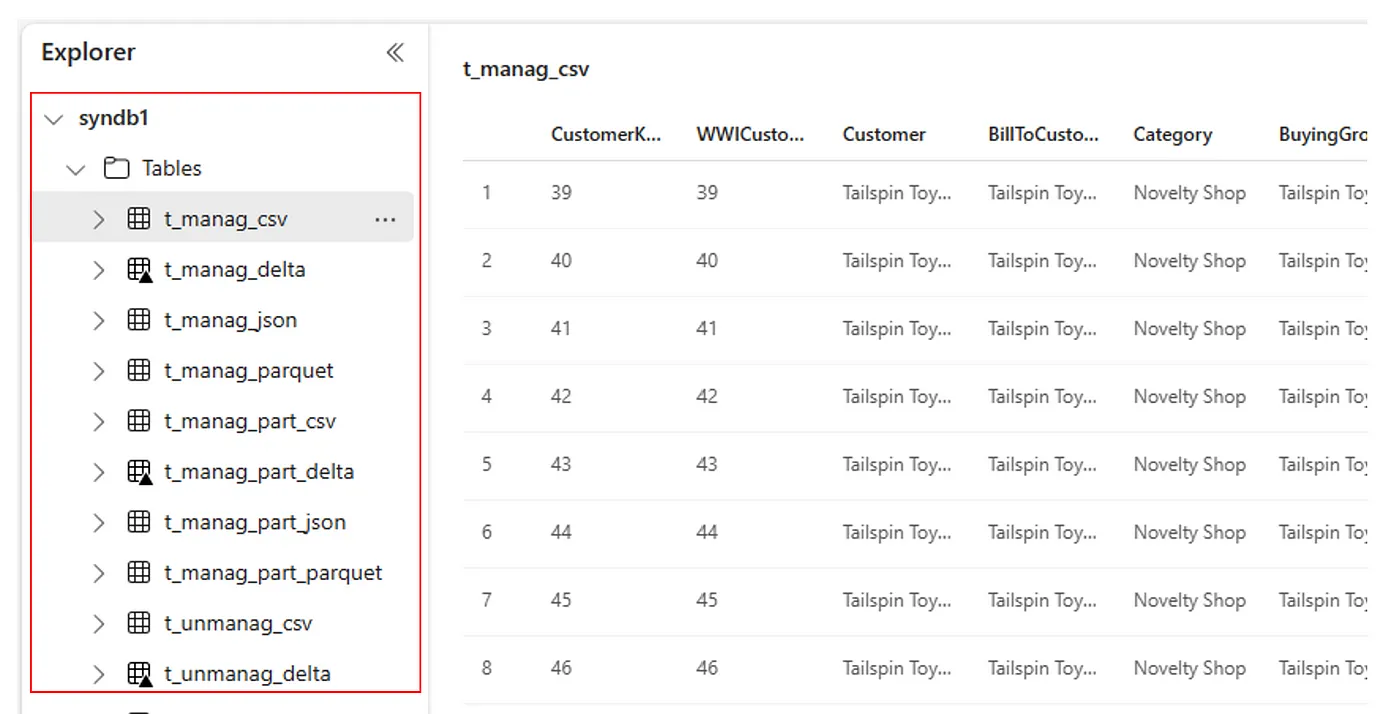
Como alternativa, todas as tabelas importadas de cada lakehouse podem ser vistas na seção Tabelas da interface do usuário do Lakehouse Explorer.
Outras considerações
- Escalabilidade: a solução aqui está usando a API interna do catálogo do Spark para fazer importação/exportação, mas não está se conectando diretamente ao HMS para obter objetos do catálogo. Portanto, a solução não terá uma boa escalabilidade se o catálogo for grande. Você precisaria alterar a lógica de exportação usando o BD do HMS.
- Precisão dos dados: não há garantia de isolamento. Ou seja, se o mecanismo de computação do Spark estiver fazendo modificações simultâneas no metastore durante a migração no notebook, dados inconsistentes poderão ser introduzidos no lakehouse do Fabric.
Conteúdo relacionado
- Fabric x Spark do Azure Synapse
- Saiba mais sobre as opções de migração para os pools do Spark, configurações, bibliotecas, notebooks e definição de trabalho do Spark