operador make-series
Aplica-se a: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Crie uma série de valores agregados especificados ao longo de um eixo especificado.
Sintaxe
T | make-series [MakeSeriesParameters] [Coluna =] Agregação [default = DefaultValue] [, ...] on AxisColumn [from início] [to fim] step etapa [by [Coluna =] GroupExpression [, ...]]
Saiba mais sobre as convenções de sintaxe.
Parâmetros
| Nome | Digitar | Obrigatória | Descrição |
|---|---|---|---|
| Coluna | string |
O nome da coluna de resultado. Assume o padrão de um nome derivado da expressão. | |
| DefaultValue | escalar | Um valor padrão a ser usado em vez de valores ausentes. Se não houver uma linha com valores específicos de AxisColumn e GroupExpression, o elemento correspondente da matriz assumirá um DefaultValue. O padrão é 0. | |
| Agregação | string |
✔️ | Uma chamada para uma função de agregação, como count() ou avg(), com nomes de coluna como argumentos. Confira a lista de funções de agregação. Somente funções de agregação que retornam resultados numéricos podem ser usadas com o operador make-series. |
| AxisColumn | string |
✔️ | A coluna na qual a série será ordenada. Normalmente, os valores de coluna serão do tipo datetime ou timespan, mas todos os tipos numéricos são aceitos. |
| start | scalar | ✔️ | O valor do limite inferior de AxisColumn para cada uma das séries a serem criadas. Se start não for especificado, será o primeiro compartimento, ou etapa, que tem dados em cada série. |
| end | scalar | ✔️ | O valor não inclusivo do limite deAxisColumn. O último índice da série temporal é menor que esse valor e será o start mais o inteiro múltiplo de step que for menor que end. Se end não for especificado, ele será o limite superior do último compartimento, ou etapa, que tem dados para cada série. |
| step | scalar | ✔️ | A diferença, ou o tamanho do compartimento, entre dois elementos consecutivos da matriz AxisColumn. Para obter uma lista de intervalos de tempo possíveis, confira timespan. |
| GroupExpression | uma expressão sobre as colunas que fornece um conjunto de valores distintos. Geralmente é um nome de coluna que já fornece um conjunto restrito de valores. | ||
| MakeSeriesParameters | Zero ou mais parâmetros separados por espaço na forma de Valor de Nome = que controlam o comportamento. Confira parâmetros de série make com suporte. |
Observação
Os parâmetros start, end e step são usados para criar uma matriz de valores de AxisColumn . A matriz consiste em valores entre start e end, com o valor de step representando a diferença entre um elemento de matriz para o próximo. Todos os valores de Agregação são ordenados respectivamente a essa matriz.
Parâmetros de série make com suporte
| Nome | Descrição |
|---|---|
kind |
Produz o resultado padrão quando a entrada do operador make-series está vazia. Valor: nonempty |
hint.shufflekey=<key> |
A consulta shufflekey compartilha a carga de consulta em nós de cluster usando uma chave para particionar dados. Confira a consulta aleatória |
Observação
As matrizes geradas pelo make-series são limitadas a valores 1048576 (2^20). Tentar gerar uma matriz maior usando make-series resultará em um erro ou em uma matriz truncada.
Sintaxe alternativa
T | make-series [Coluna =] Agregação [default = DefaultValue] [, ...] on AxisColumn in range(início, fim, etapa) [by [Coluna =] GroupExpression [, ...]]
A série gerada com a sintaxe alternativa difere da sintaxe principal em dois aspectos:
- O valor de fim é inclusivo.
- A compartimentalização do eixo do índice é gerada com bin(), e não com bin_at(), o que significa que início pode não ser incluído na série gerada.
É recomendável usar a sintaxe principal de make-series, e não a alternativa.
Retornos
As linhas de entrada são organizadas em grupos com os mesmos valores que as expressões by e a expressão bin_at(AxisColumn,etapa,início). Em seguida, as funções de agregação especificadas são calculadas sobre cada grupo, produzindo uma linha para cada grupo. O resultado contém as colunas by e AxisColumn e pelo menos uma coluna para cada agregação calculada. (Não há suporte para a agregação de várias colunas ou resultados não numéricos.)
Esse resultado intermediário tem tantas linhas quanto há combinações distintas de by e valores de bin_at(AxisColumn,etapa,início).
Por fim, as linhas do resultado intermediário organizadas em grupos que têm os mesmos valores que as expressões by e todos os valores agregados são organizados em matrizes (valores do tipo dynamic). Para cada agregação, há uma coluna contendo sua matriz com o mesmo nome. A última coluna é uma matriz que contém os valores de AxisColumn compartimentalizados de acordo com a etapaespecificada.
Observação
Embora você possa fornecer expressões aleatórias para as expressões de agregação e de agrupamento, é mais eficiente usar nomes de coluna simples.
Lista de funções de agregação
| Função | Descrição |
|---|---|
| avg() | Retorna um valor médio em todo o grupo |
| avgif() | Retorna uma média com o predicado do grupo |
| count() | Retorna uma contagem do grupo |
| countif() | Retorna uma contagem com o predicado do grupo |
| dcount() | Retorna uma contagem distinta aproximada dos elementos do grupo |
| dcountif() | Retorna uma contagem distinta aproximada com o predicado do grupo |
| max() | Retorna o valor máximo no grupo |
| maxif() | Retorna o valor máximo com o predicado do grupo |
| min() | Retorna o valor mínimo no grupo |
| minif() | Retorna o valor mínimo com o predicado do grupo |
| percentile() | Retorna o valor do percentil entre o grupo |
| take_any() | Retorna um valor não vazio aleatório para o grupo |
| stdev() | Retorna o desvio padrão no grupo |
| sum() | Retorna a soma dos elementos dentro do grupo |
| sumif() | Retorna a soma dos elementos com o predicado do grupo |
| variance() | Retorna a variância no grupo |
Lista de funções de análise de série
| Função | Descrição |
|---|---|
| series_fir() | Aplica o filtro de Resposta a impulso finito |
| series_iir() | Aplica o filtro de Resposta a impulso infinito |
| series_fit_line() | Encontra uma linha reta que é a melhor aproximação da entrada |
| series_fit_line_dynamic() | Localiza uma linha que é a melhor aproximação da entrada, retornando o objeto dinâmico |
| series_fit_2lines() | Localiza duas linhas que são a melhor aproximação da entrada |
| series_fit_2lines_dynamic() | Localiza duas linhas que são a melhor aproximação da entrada, retornando o objeto dinâmico |
| series_outliers() | Classifica pontos de anomalia em uma série |
| series_periods_detect() | Encontra os períodos mais significativos existentes em uma série temporal |
| series_periods_validate() | Verifica se uma série temporal contém padrões periódicos com os tamanhos fornecidos |
| series_stats_dynamic() | Retorna várias colunas com as estatísticas comuns (mín./máx./variância/desvio padrão/média) |
| series_stats() | Gera um valor dinâmico com as estatísticas comuns (mín./máx./variância/desvio padrão/média) |
Para obter uma lista completa de funções de análise de série, confira: Funções de processamento de série
Lista de funções de interpolação de séries
| Função | Descrição |
|---|---|
| series_fill_backward() | Executa a interpolação de preenchimento regressiva dos valores ausentes em uma série |
| series_fill_const() | Substitui os valores ausentes em uma série por um valor constante especificado |
| series_fill_forward() | Executa a interpolação de preenchimento progressiva dos valores ausentes em uma série |
| series_fill_linear() | Executa a interpolação linear dos valores ausentes em uma série |
- Observação: Por padrão, as funções de interpolação pressupõem
nullcomo um valor ausente. Portanto, especifiquedefault=double(null) emmake-seriesse você pretende usar funções de interpolação para a série.
Exemplos
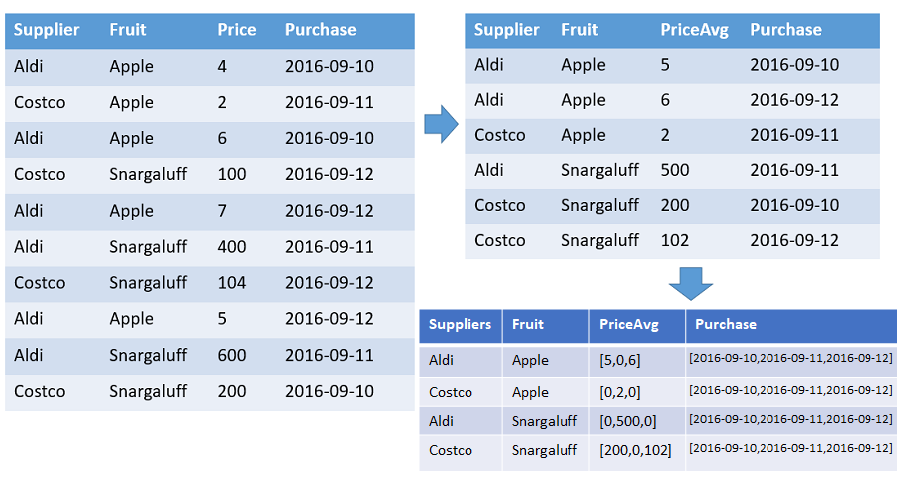
Uma tabela que mostra as matrizes dos números e os preços médios de cada fruta de cada fornecedor, ordenados pelo carimbo de data/hora com o intervalo especificado. Há uma linha na saída para cada combinação distinta de frutas e fornecedor. As colunas de saída mostram a fruta, o fornecedor e as matrizes de: contagem, média e a linha do tempo inteira (de 01/01/2016 até 10/01/2016). Todas as matrizes são classificadas pelo respectivo carimbo de data/hora e todas as lacunas são preenchidas com valores padrão (0 neste exemplo). Todas as outras colunas de entrada são ignoradas.
T | make-series PriceAvg=avg(Price) default=0
on Purchase from datetime(2016-09-10) to datetime(2016-09-13) step 1d by Supplier, Fruit
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| make-series avg(metric) on timestamp from stime to etime step interval
| avg_metric | timestamp |
|---|---|
| [ 4.0, 3.0, 5.0, 0.0, 10.5, 4.0, 3.0, 8.0, 6.5 ] | [ "2017-01-01T00:00:00.0000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:00:00.0000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |
Quando a entrada de make-series estiver vazia, o comportamento padrão de make-series produzirá um resultado vazio.
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series avg(metric) default=1.0 on timestamp from stime to etime step interval
| count
Saída
| Contagem |
|---|
| 0 |
Usar kind=nonempty em make-series produzirá um resultado não vazio dos valores padrão:
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series kind=nonempty avg(metric) default=1.0 on timestamp from stime to etime step interval
Saída
| avg_metric | timestamp |
|---|---|
| [ 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0 ] |
[ "2017-01-01T00:00:00.0000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:00:00.0000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |