Como configurar filtros de conteúdo com o Azure OpenAI Service
O sistema de filtragem de conteúdo integrado ao Serviço OpenAI do Azure é executado junto com os modelos principais, incluindo modelos de geração de imagem DALL-E. Ele usa um conjunto de modelos de classificação multiclasse para detetar quatro categorias de conteúdo nocivo (violência, ódio, violência sexual e automutilação) em quatro níveis de gravidade, respectivamente (seguro, baixo, médio e alto), e classificadores binários opcionais para detetar risco de jailbreak, texto existente e código em repositórios públicos. A configuração da filtragem de conteúdo predefinida está definida para filtrar no limiar de gravidade médio para as quatro categorias de danos de conteúdo para pedidos e conclusões. Isso significa que o conteúdo detetado no nível de gravidade médio ou alto é filtrado, enquanto o conteúdo detetado no nível de gravidade baixo ou seguro não é filtrado pelos filtros de conteúdo. Saiba mais sobre categorias de conteúdo, níveis de gravidade e o comportamento do sistema de filtragem de conteúdo aqui. A deteção de risco de jailbreak e os modelos de texto e código protegidos são opcionais e desativados por padrão. Para modelos de texto e código de jailbreak e material protegido, o recurso de configurabilidade permite que todos os clientes liguem e desliguem os modelos. Os modelos estão desativados por padrão e podem ser ativados de acordo com o seu cenário. Alguns modelos devem estar ativos em determinados cenários para manter a cobertura sob o Compromisso de Direitos Autorais do Cliente.
Nota
Todos os clientes têm a capacidade de modificar os filtros de conteúdo e configurar os limiares de gravidade (baixo, médio, alto). É necessária aprovação para desativar parcial ou totalmente os filtros de conteúdo. Apenas os clientes geridos podem solicitar o controlo total da filtragem de conteúdo através deste formulário: Revisão de Acesso Limitado do Azure OpenAI: Filtros de Conteúdo Modificados. Neste momento, não é possível tornar-se um cliente gerido.
Os filtros de conteúdo podem ser configurados no nível do recurso. Depois que uma nova configuração é criada, ela pode ser associada a uma ou mais implantações. Para obter mais informações sobre a implementação de modelos, veja o guia de implementação de recursos.
Pré-requisitos
- Você deve ter um recurso do Azure OpenAI e uma implantação de modelo de linguagem grande (LLM) para configurar filtros de conteúdo. Siga um guia de início rápido para começar.
Compreender a configurabilidade do filtro de conteúdo
O Serviço Azure OpenAI inclui configurações de segurança padrão aplicadas a todos os modelos, excluindo o Azure OpenAI Whisper. Essas configurações fornecem uma experiência responsável por padrão, incluindo modelos de filtragem de conteúdo, listas de bloqueio, transformação de prompt, credenciais de conteúdo e outros. Leia mais sobre isso aqui.
Todos os clientes também podem configurar filtros de conteúdo e criar políticas de segurança personalizadas adaptadas aos seus requisitos de casos de uso. O recurso de configurabilidade permite que os clientes ajustem as configurações, separadamente para prompts e conclusão, para filtrar o conteúdo de cada categoria de conteúdo em diferentes níveis de gravidade, conforme descrito na tabela abaixo. O conteúdo detetado no nível de gravidade "seguro" é rotulado em anotações, mas não está sujeito a filtragem e não é configurável.
| Severidade filtrada | Configurável para prompts | Configurável para finalizações | Descrições |
|---|---|---|---|
| Baixa, média, alta | Sim | Sim | Configuração de filtragem mais rigorosa. O conteúdo detetado nos níveis de gravidade baixo, médio e alto é filtrado. |
| Médio, alto | Sim | Sim | O conteúdo detetado no nível de gravidade baixo não é filtrado, o conteúdo em médio e alto é filtrado. |
| Alto | Sim | Sim | O conteúdo detetado nos níveis de gravidade baixo e médio não é filtrado. Apenas o conteúdo com nível de severidade alto é filtrado. |
| Sem filtros | Se aprovado1 | Se aprovado1 | Nenhum conteúdo é filtrado, independentemente do nível de gravidade detetado. Requer aprovação1. |
| Anotar apenas | Se aprovado1 | Se aprovado1 | Desativa a funcionalidade de filtro, para que o conteúdo não seja bloqueado, mas as anotações são retornadas por meio da resposta da API. Requer aprovação1. |
1 Para modelos do Azure OpenAI, apenas os clientes que foram aprovados para filtragem de conteúdo modificada têm controlo total de filtragem de conteúdo e podem desativar os filtros de conteúdo. Solicite filtros de conteúdo modificados por meio deste formulário: Azure OpenAI Limited Access Review: Modified Content Filters. Para clientes do Azure Government, solicite filtros de conteúdo modificados por meio deste formulário: Azure Government - Request Modified Content Filtering for Azure OpenAI Service.
Filtros de conteúdo configuráveis para entradas (prompts) e saídas (conclusão) estão disponíveis para os seguintes modelos do Azure OpenAI:
- Série de modelos GPT
- GPT-4 Visão Turbo GA* (
turbo-2024-04-09) - GPT-4O
- GPT-4o mini |
- DALL-E 2 e 3
Os filtros de conteúdo configuráveis não estão disponíveis para
- O1-Pré-visualização
- o1-mini
*Disponível apenas para GPT-4 Turbo Vision GA, não se aplica à pré-visualização GPT-4 Turbo Vision
As configurações de filtragem de conteúdo são criadas dentro de um Recurso no Azure AI Studio e podem ser associadas a Implantações. Saiba mais sobre a configurabilidade aqui.
Os clientes são responsáveis por garantir que os aplicativos que integram o Azure OpenAI estejam em conformidade com o Código de Conduta.
Entenda outros filtros
Você pode configurar as seguintes categorias de filtro, além dos filtros de categoria de dano padrão.
| Categoria do filtro | Status | Definição predefinida | Aplicado para prompt ou conclusão? | Description |
|---|---|---|---|---|
| Proteções imediatas para ataques diretos (jailbreak) | GA | Ativado | Prompt do usuário | Filtra / anota solicitações do usuário que podem apresentar um risco de jailbreak. Para obter mais informações sobre anotações, visite Filtragem de conteúdo do Serviço OpenAI do Azure. |
| Proteções imediatas para ataques indiretos | GA | Ativado | Prompt do usuário | Filtrar/anotar Ataques Indiretos, também conhecidos como Ataques Imediatos Indiretos ou Ataques de Injeção Imediata entre Domínios, uma vulnerabilidade potencial em que terceiros colocam instruções maliciosas dentro de documentos que o sistema de IA generativa pode acessar e processar. Obrigatório: Formatação do documento . |
| Material protegido - código | GA | Ativado | Conclusão | Filtra o código protegido ou obtém o exemplo de citação e informações de licença em anotações para trechos de código que correspondem a qualquer fonte de código pública, alimentado pelo GitHub Copilot. Para obter mais informações sobre como consumir anotações, consulte o guia de conceitos de filtragem de conteúdo |
| Material protegido - texto | GA | Ativado | Conclusão | Identifica e bloqueia a exibição de conteúdo de texto conhecido na saída do modelo (por exemplo, letras de músicas, receitas e conteúdo da Web selecionado). |
| Fundamentação* | Pré-visualizar | Inativo | Conclusão | Deteta se as respostas de texto de grandes modelos de linguagem (LLMs) estão fundamentadas nos materiais de origem fornecidos pelos usuários. Ungroundedness refere-se a casos em que os LLMs produzem informações que não são factuais ou imprecisas a partir do que estava presente nos materiais de origem. |
*Requer a incorporação de documentos em seu prompt. Ler mais.
Configurar filtros de conteúdo com o Azure AI Studio
As etapas a seguir mostram como configurar uma configuração de filtragem de conteúdo personalizada para seu recurso do Azure OpenAI no AI Studio. Para obter orientação com filtros de conteúdo em seu projeto do Azure AI Studio, você pode ler mais em Filtragem de conteúdo do Azure AI Studio.
Vá para Azure AI Studio e navegue até a página Segurança + proteção no menu à esquerda.
Vá para a guia Filtros de conteúdo e crie uma nova configuração de filtragem de conteúdo personalizada.
Isso leva à exibição de configuração a seguir, onde você pode escolher um nome para a configuração de filtragem de conteúdo personalizada. Depois de inserir um nome, você pode configurar os filtros de entrada (para solicitações do usuário) e filtros de saída (para conclusão do modelo).
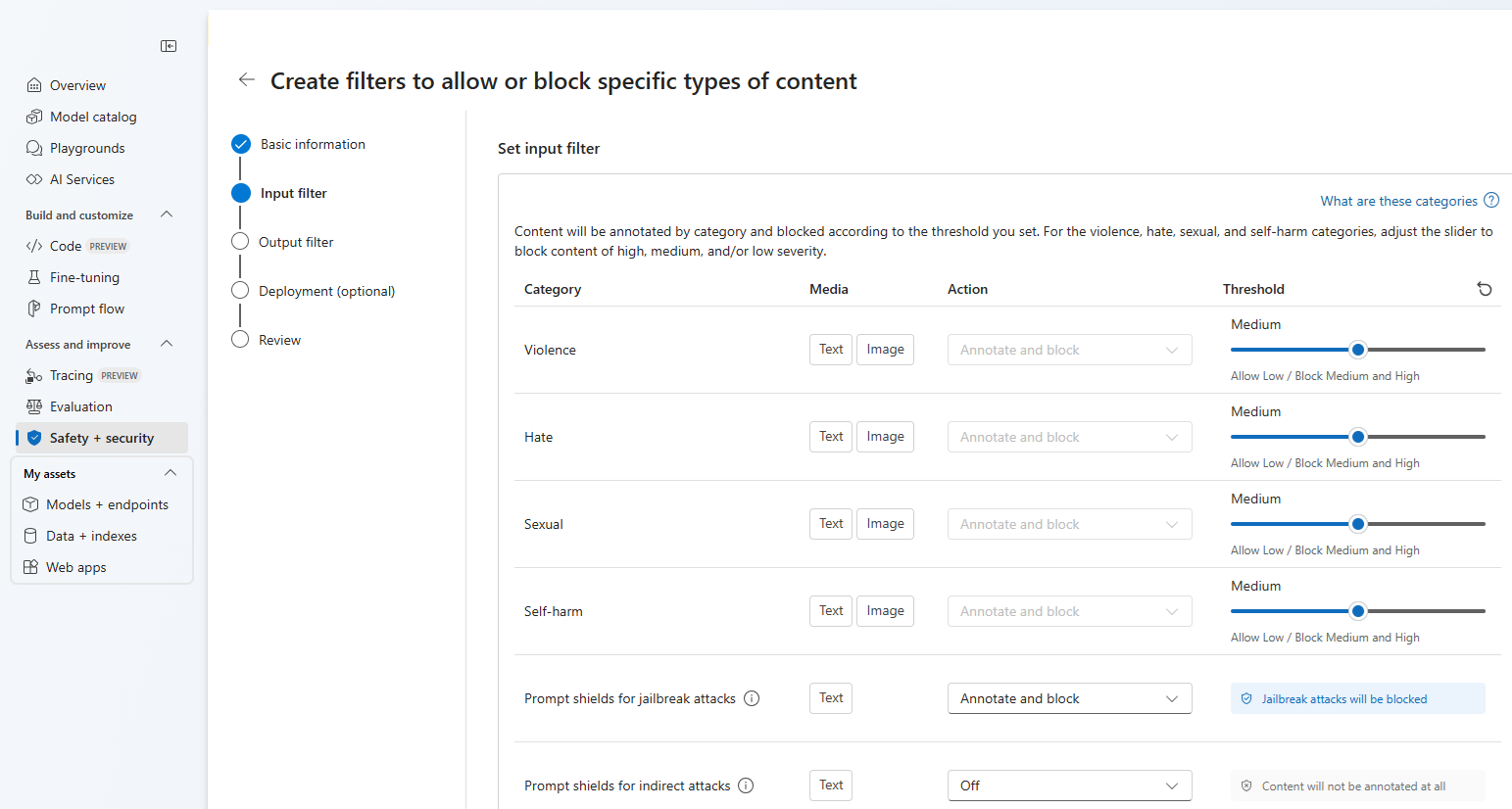
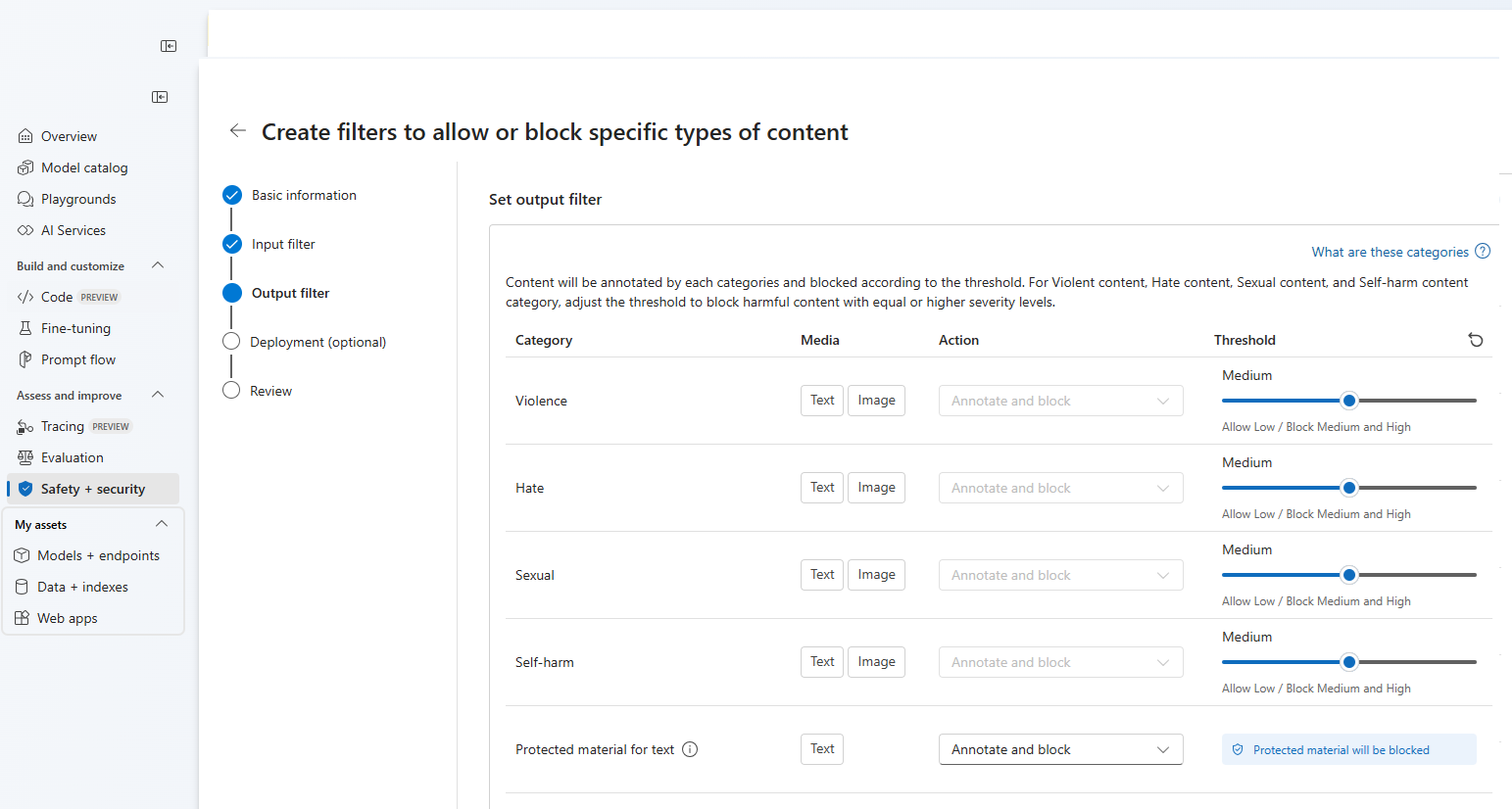
Para as quatro primeiras categorias de conteúdo, há três níveis de gravidade configuráveis: baixo, médio e alto. Você pode usar os controles deslizantes para definir o limite de gravidade se determinar que seu aplicativo ou cenário de uso requer filtragem diferente dos valores padrão.
Alguns filtros, como Escudos de Aviso e Deteção de material protegido, permitem determinar se o modelo deve anotar e/ou bloquear conteúdo. Selecionar Anotar executa apenas o respetivo modelo e retorna anotações via resposta da API, mas não filtrará o conteúdo. Além de anotar, você também pode optar por bloquear conteúdo.
Se o seu caso de uso foi aprovado para filtros de conteúdo modificados, você recebe controle total sobre as configurações de filtragem de conteúdo e pode optar por desativar a filtragem parcial ou totalmente, ou ativar a anotação apenas para as categorias de danos ao conteúdo (violência, ódio, violência sexual e automutilação).
Você pode criar várias configurações de filtragem de conteúdo de acordo com suas necessidades.

Em seguida, para usar uma configuração de filtragem de conteúdo personalizada, atribua-a a uma ou mais implantações em seu recurso. Para fazer isso, vá para a guia Implantações e selecione sua implantação. Em seguida, selecione Editar.
Na janela Atualizar implantação exibida, selecione seu filtro personalizado no menu suspenso Filtro de conteúdo. Em seguida, selecione Salvar e fechar para aplicar a configuração selecionada à implantação.

Você também pode editar e excluir uma configuração de filtro de conteúdo, se necessário.
Antes de excluir uma configuração de filtragem de conteúdo, você precisará cancelá-la e substituí-la de qualquer implantação na guia Implantações .


Feedback de filtragem de conteúdo de relatório
Se você estiver encontrando um problema de filtragem de conteúdo, selecione o botão Enviar comentários na parte superior do playground. Isso é ativado no playground Imagens, Bate-papo e Conclusão .
Quando a caixa de diálogo aparecer, selecione o problema de filtragem de conteúdo apropriado. Inclua o máximo de detalhes possível relacionados ao seu problema de filtragem de conteúdo, como o prompt específico e o erro de filtragem de conteúdo encontrado. Não inclua informações privadas ou confidenciais.
Para obter suporte, envie um tíquete de suporte.
Siga as melhores práticas
Recomendamos informar suas decisões de configuração de filtragem de conteúdo por meio de uma identificação iterativa (por exemplo, teste de equipe vermelha, teste de esforço e análise) e processo de medição para abordar os danos potenciais que são relevantes para um modelo, aplicativo e cenário de implantação específicos. Depois de implementar atenuações, como filtragem de conteúdo, repita a medição para testar a eficácia. As recomendações e as práticas recomendadas para IA Responsável para o Azure OpenAI, baseadas no Padrão de IA Responsável da Microsoft, podem ser encontradas na Visão Geral da IA Responsável para o Azure OpenAI.
Conteúdos relacionados
- Saiba mais sobre as práticas de IA responsável para o Azure OpenAI: Visão geral das práticas de IA responsável para modelos OpenAI do Azure.
- Leia mais sobre categorias de filtragem de conteúdo e níveis de gravidade com o Serviço Azure OpenAI.
- Saiba mais sobre o red teaming no nosso artigo: Introdução aos modelos de linguagem grandes (LLMs) do red teaming.