Criação de partições e dimensionamento horizontal no Azure Cosmos DB
APLICA-SE A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabela
Tabela
O Azure Cosmos DB usa o particionamento para dimensionar contêineres individuais em um banco de dados para atender às necessidades de desempenho do seu aplicativo. Os itens em um contêiner são divididos em subconjuntos distintos chamados partições lógicas. As partições lógicas são formadas com base no valor de uma chave de partição associada a cada item em um contêiner. Todos os itens em uma partição lógica têm o mesmo valor de chave de partição.
Por exemplo, um contêiner contém itens. Cada item tem um valor exclusivo para a UserID propriedade. Se UserID servir como a chave de partição para os itens no contêiner e houver 1.000 valores exclusivos UserID , 1.000 partições lógicas serão criadas para o contêiner.
Além de uma chave de partição que determina a partição lógica do item, cada item em um contêiner tem um ID de item (exclusivo dentro de uma partição lógica). A combinação da chave de partição e do ID do item cria o índice do item, que identifica exclusivamente o item. Escolher uma chave de partição é uma decisão importante que afeta o desempenho do seu aplicativo.
Este artigo explica a relação entre partições lógicas e físicas. Ele também discute as práticas recomendadas para particionamento e fornece uma visão detalhada de como o dimensionamento horizontal funciona no Azure Cosmos DB. Não é necessário entender esses detalhes internos para selecionar sua chave de partição, mas estamos abordando-os para que você possa ter clareza sobre como o Azure Cosmos DB funciona.
Partições lógicas
Uma partição lógica consiste em um conjunto de itens que têm a mesma chave de partição. Por exemplo, em um recipiente que contém dados sobre nutrição alimentar, todos os itens contêm uma foodGroup propriedade. Você pode usar foodGroup como a chave de partição para o contêiner. Grupos de itens que têm valores específicos para foodGroup, como Beef Products, Baked Productse Sausages and Luncheon Meats, formam partições lógicas distintas.
Uma partição lógica também define o escopo das transações de banco de dados. Você pode atualizar itens dentro de uma partição lógica usando uma transação com isolamento de instantâneo. Quando novos itens são adicionados a um contêiner, o sistema cria novas partições lógicas de forma transparente. Você não precisa se preocupar em excluir uma partição lógica quando os dados subjacentes são excluídos.
Não há limite para o número de partições lógicas em seu contêiner. Cada partição lógica pode armazenar até 20 GB de dados. Boas opções de chave de partição têm uma ampla gama de valores possíveis. Por exemplo, em um contêiner onde todos os itens contêm uma foodGroup propriedade, os dados dentro da Beef Products partição lógica podem crescer até 20 GB. Selecionar uma chave de partição com uma ampla gama de valores possíveis garante que o contêiner seja capaz de escalar.
Você pode usar os Alertas do Azure Monitor para monitorar se o tamanho de uma partição lógica está se aproximando de 20 GB.
Divisórias físicas
Um contêiner é dimensionado distribuindo dados e taxa de transferência entre partições físicas. Internamente, uma ou mais partições lógicas são mapeadas para uma única partição física. Normalmente, contêineres menores têm muitas partições lógicas, mas exigem apenas uma única partição física. Ao contrário das partições lógicas, as partições físicas são uma implementação interna do sistema e o Azure Cosmos DB gerencia inteiramente as partições físicas.
O número de partições físicas em seu contêiner depende das seguintes características:
A quantidade de taxa de transferência provisionada (cada partição física individual pode fornecer uma taxa de transferência de até 10.000 unidades de solicitação por segundo). O limite de 10.000 RU/s para partições físicas implica que as partições lógicas também têm um limite de 10.000 RU/s, pois cada partição lógica é mapeada apenas para uma partição física.
O armazenamento total de dados (cada partição física individual pode armazenar até 50 GB de dados).
Nota
As partições físicas são uma implementação interna do sistema e são totalmente gerenciadas pelo Azure Cosmos DB. Ao desenvolver suas soluções, não se concentre em partições físicas porque você não pode controlá-las. Em vez disso, concentre-se em suas chaves de partição. Se você escolher uma chave de partição que distribua uniformemente o consumo de taxa de transferência entre partições lógicas, garantirá que o consumo de taxa de transferência entre partições físicas seja equilibrado.
Não há limite para o número total de partições físicas em seu contêiner. À medida que a taxa de transferência provisionada ou o tamanho dos dados aumenta, o Azure Cosmos DB cria automaticamente novas partições físicas dividindo as existentes. As divisões de partição física não afetam a disponibilidade do seu aplicativo. Após a divisão da partição física, todos os dados dentro de uma única partição lógica ainda serão armazenados na mesma partição física. Uma divisão de partição física simplesmente cria um novo mapeamento de partições lógicas para partições físicas.
A taxa de transferência provisionada para um contêiner é dividida igualmente entre partições físicas. Um design de chave de partição que não distribui solicitações uniformemente pode resultar em muitas solicitações direcionadas a um pequeno subconjunto de partições que se tornam "quentes". As partições quentes levam ao uso ineficiente da taxa de transferência provisionada, o que pode resultar em limitação de taxa e custos mais altos.
Por exemplo, considere um contêiner com o caminho /foodGroup especificado como a chave de partição. O contêiner pode ter qualquer número de partições físicas, mas neste exemplo assumimos que ele tem três. Uma única partição física pode conter várias chaves de partição. Por exemplo, a maior partição física pode conter as três principais partições lógicas de tamanho mais significativo: Beef Products, Vegetable and Vegetable Productse Soups, Sauces, and Gravies.
Se você atribuir uma taxa de transferência de 18.000 unidades de solicitação por segundo (RU/s), cada uma das três partições físicas poderá utilizar 1/3 da taxa de transferência total provisionada. Dentro da partição física selecionada, as chaves Beef Productsde partição lógica , Vegetable and Vegetable Productse Soups, Sauces, and Gravies podem, coletivamente, utilizar os 6.000 RU/s provisionados da partição física. Como a taxa de transferência provisionada é dividida uniformemente entre as partições físicas do contêiner, é importante escolher uma chave de partição que distribua uniformemente o consumo de taxa de transferência. Para obter mais informações, consulte escolhendo a chave de partição lógica correta.
Gerenciando partições lógicas
O Azure Cosmos DB gerencia de forma transparente e automática o posicionamento de partições lógicas em partições físicas para satisfazer com eficiência as necessidades de escalabilidade e desempenho do contêiner. À medida que os requisitos de taxa de transferência e armazenamento de um aplicativo aumentam, o Azure Cosmos DB move partições lógicas para distribuir automaticamente a carga por um número maior de partições físicas. Você pode saber mais sobre partições físicas.
O Azure Cosmos DB utiliza a criação de partições baseada em hash para distribuir as partições lógicas por partições físicas. O Azure Cosmos DB cria o hash do valor da chave de partição de um item. O resultado em hash determina a partição lógica. Em seguida, o Azure Cosmos DB aloca os hashes do espaço da chave de partição uniformemente nas partições físicas.
As transações (em procedimentos armazenados ou gatilhos) são permitidas apenas em itens em uma única partição lógica.
Conjuntos de réplicas
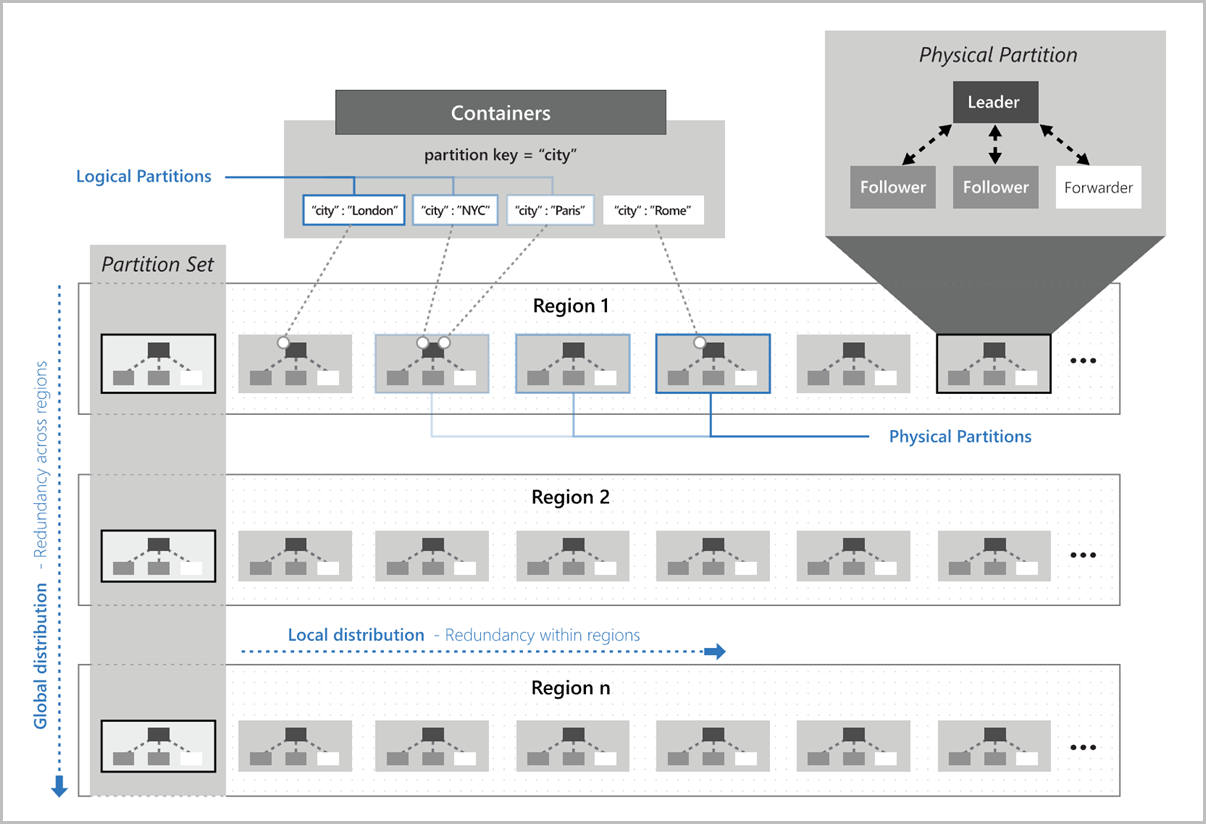
Cada partição física consiste em um conjunto de réplicas, também conhecido como conjunto de réplicas. Cada réplica hospeda uma instância do mecanismo de banco de dados. Um conjunto de réplicas torna o armazenamento de dados dentro da partição física durável, altamente disponível e consistente. Cada réplica que compõe a partição física herda a cota de armazenamento da partição. Todas as réplicas de uma partição física suportam coletivamente a taxa de transferência alocada para a partição física. O Azure Cosmos DB gerencia automaticamente conjuntos de réplicas.
Normalmente, contêineres menores exigem apenas uma única partição física, mas ainda têm pelo menos quatro réplicas.
A imagem a seguir mostra como as partições lógicas são mapeadas para partições físicas que são distribuídas globalmente. Partição definida na imagem refere-se a um grupo de partições físicas que gerenciam as mesmas chaves de partição lógica em várias regiões:
Escolher uma chave de partição
Uma chave de partição tem dois componentes: caminho da chave de partição e o valor da chave de partição. Por exemplo, considere um item { "userId" : "Andrew", "worksFor": "Microsoft" } se você escolher "userId" como a chave de partição, a seguir estão os dois componentes de chave de partição:
O caminho da chave de partição (Por exemplo: "/userId"). O caminho da chave de partição aceita caracteres alfanuméricos e sublinhados (_). Você também pode usar objetos aninhados usando a notação de caminho padrão(/).
O valor da chave de partição (Por exemplo: "Andrew"). O valor da chave de partição pode ser do tipo string ou numérico.
Para saber mais sobre os limites de taxa de transferência, armazenamento e comprimento da chave de partição, consulte o artigo Cotas de serviço do Azure Cosmos DB.
Selecionar sua chave de partição é uma escolha de design simples, mas importante, no Azure Cosmos DB. Depois de selecionar a chave de partição, não é possível alterá-la no local. Se você precisar alterar sua chave de partição, você deve mover seus dados para um novo contêiner com sua nova chave de partição desejada. (Os trabalhos de cópia de contêiner ajudam nesse processo.)
Para todos os contêineres, sua chave de partição deve:
Seja um imóvel que tenha um valor, que não muda. Se uma propriedade for sua chave de partição, você não poderá atualizar o valor dessa propriedade.
Deve conter
Stringapenas valores - ou os números devem, idealmente, ser convertidos em umString, se houver alguma chance de que eles estejam fora dos limites de números de precisão dupla de acordo com o binário IEEE 75464. A especificação Json chama a atenção para as razões pelas quais o uso de números fora desse limite em geral é uma má prática devido a prováveis problemas de interoperabilidade. Essas preocupações são especialmente relevantes para a coluna de chave de partição, porque é imutável e requer migração de dados para alterá-la posteriormente.Ter uma cardinalidade elevada. Em outras palavras, o imóvel deve ter uma ampla gama de valores possíveis.
Espalhe o consumo da unidade de solicitação (RU) e o armazenamento de dados uniformemente em todas as partições lógicas. Esse spread garante o consumo de RU e a distribuição de armazenamento uniformes em suas partições físicas.
Ter valores que não sejam maiores do que 2048 bytes normalmente, ou 101 bytes se chaves de partição grandes não estiverem habilitadas. Para obter mais informações, consulte chaves de partição grandes
Se você precisar de transações ACID de vários itens no Azure Cosmos DB, precisará usar procedimentos armazenados ou gatilhos. Todos os procedimentos armazenados e gatilhos baseados em JavaScript têm como escopo uma única partição lógica.
Nota
Se você tiver apenas uma partição física, o valor da chave de partição pode não ser relevante, pois todas as consultas terão como alvo a mesma partição física.
Tipos de chaves de partição
| Estratégia de particionamento | Quando Utilizar | Vantagens | Desvantagens |
|---|---|---|---|
| Chave de partição regular (por exemplo, CustomerId, OrderId) | - Use quando a chave de partição tem alta cardinalidade e se alinha com padrões de consulta (por exemplo, filtragem por CustomerId). - Adequado para cargas de trabalho em que as consultas visam principalmente os dados de um único cliente (por exemplo, recuperar todos os pedidos de um cliente). |
- Simples de gerir. - Consultas eficientes quando o padrão de acesso corresponde à chave de partição (por exemplo, consultando todos os pedidos por CustomerId). - Evita consultas entre partições se os padrões de acesso forem consistentes. |
- Risco de partições quentes se alguns valores (por exemplo, alguns clientes de alto tráfego) gerarem significativamente mais dados do que outros. - Pode atingir o limite de 20 GB por partição lógica se o volume de dados para uma chave específica crescer rapidamente. |
| Chave de partição sintética (por exemplo, CustomerId + OrderDate) | - Use quando nenhum campo tiver alta cardinalidade e corresponder aos padrões de consulta. - Bom para cargas de trabalho de gravação pesadas, onde os dados precisam ser distribuídos uniformemente entre partições físicas (por exemplo, muitos pedidos feitos na mesma data). |
- Ajuda a distribuir dados uniformemente entre partições, reduzindo partições quentes (por exemplo, distribuindo pedidos por CustomerId e OrderDate). - Espalha gravações em várias partições, melhorando a taxa de transferência. |
- Consultas que filtram apenas por um campo (por exemplo, somente CustomerId) podem resultar em consultas entre partições. - Consultas entre partições podem levar a um maior consumo de RU (carga adicional de 2-3 RU/s para cada partição física existente) e latência adicionada. |
| Chave de partição hierárquica (HPK) (por exemplo, CustomerId/OrderId, StoreId/ProductId) | - Use quando precisar de particionamento de vários níveis para suportar conjuntos de dados de grande escala. - Ideal quando as consultas filtram no primeiro e segundo níveis da hierarquia. |
- Ajuda a evitar o limite de 20 GB criando vários níveis de particionamento. - Consulta eficiente em ambos os níveis hierárquicos (por exemplo, filtrando primeiro por CustomerID, depois por OrderID). - Minimiza consultas entre partições para consultas direcionadas ao nível superior (por exemplo, recuperando todos os dados de um ID de cliente específico). |
- Requer um planejamento cuidadoso para garantir que a chave de primeiro nível tenha alta cardinalidade e esteja incluída na maioria das consultas. - Mais complexo de gerenciar do que uma chave de partição regular. - Se as consultas não estiverem alinhadas com a hierarquia (por exemplo, filtrando apenas por OrderID quando CustomerID for o primeiro nível), o desempenho da consulta poderá ser prejudicado. |
Chaves de partição para contêineres com leitura pesada
Para a maioria dos contêineres, os critérios acima são tudo o que você precisa considerar ao escolher uma chave de partição. No entanto, para contêineres grandes com leitura pesada, convém escolher uma chave de partição que apareça com frequência como um filtro em suas consultas. As consultas podem ser encaminhadas de forma eficiente apenas para as partições físicas relevantes, incluindo a chave de partição no predicado do filtro.
Essa propriedade pode ser uma boa opção de chave de partição se a maioria das solicitações da sua carga de trabalho forem consultas e a maioria das suas consultas tiver um filtro de igualdade na mesma propriedade. Por exemplo, se você executar com freqüência uma consulta que filtra no UserID, selecionar UserID como a chave de partição reduziria o número de consultas entre partições.
No entanto, se o contêiner for pequeno, você provavelmente não terá partições físicas suficientes para precisar se preocupar com o desempenho de consultas entre partições. A maioria dos contêineres pequenos no Azure Cosmos DB requer apenas uma ou duas partições físicas.
Se o contêiner puder crescer para mais do que algumas partições físicas, certifique-se de escolher uma chave de partição que minimize as consultas entre partições. Seu contêiner requer mais do que algumas partições físicas quando uma das seguintes opções for verdadeira:
Seu contêiner tem mais de 30.000 RUs provisionados
Seu contêiner armazena mais de 100 GB de dados
Usar ID de item como a chave de partição
Nota
Esta seção se aplica principalmente à API para NoSQL. Outras APIs, como a API para Gremlin, não suportam o identificador exclusivo como a chave de partição.
Se o contêiner tiver uma propriedade que tenha uma ampla gama de valores possíveis, é provável que seja uma ótima opção de chave de partição. Um exemplo possível de tal propriedade é o ID do item. Para pequenos contêineres de leitura pesada ou contêineres pesados de gravação de qualquer tamanho, o ID do item (/id) é naturalmente uma ótima opção para a chave de partição.
O ID do item de propriedade do sistema existe em cada item no contêiner. Você pode ter outras propriedades que representam uma ID lógica do seu item. Em muitos casos, esses IDs também são ótimas opções de chave de partição pelos mesmos motivos que o ID do item.
O ID do item é uma ótima opção de chave de partição pelos seguintes motivos:
- Há uma ampla gama de valores possíveis (um ID de item exclusivo por item).
- Como há um ID de item exclusivo por item, o ID do item faz um ótimo trabalho ao equilibrar uniformemente o consumo de RU e o armazenamento de dados.
- Você pode facilmente fazer leituras pontuais eficientes, uma vez que você sempre sabe a chave de partição de um item se souber seu ID de item.
Algumas coisas a considerar ao selecionar o ID do item como a chave de partição incluem:
- Se o ID do item for a chave de partição, ele se tornará um identificador exclusivo em todo o contêiner. Não é possível criar itens com IDs de item duplicadas.
- Se você tiver um contêiner de leitura pesada com muitas partições físicas, as consultas serão mais eficientes se tiverem um filtro de igualdade com a ID do item.
- Não é possível executar procedimentos armazenados ou gatilhos destinados a várias partições lógicas.