Guia de desempenho e ajuste de fluxos de dados de mapeamento
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Os fluxos de dados de mapeamento no Azure Data Factory e nos pipelines do Synapse fornecem uma interface sem código para conceber e executar transformações de dados em escala. Se não estiver familiarizado com os fluxos de dados de mapeamento, veja a Mapping Data Flow Overview (Descrição Geral do Fluxo de Dados de Mapeamento). Este artigo destaca várias maneiras de ajustar e otimizar seus fluxos de dados para que eles atendam aos seus benchmarks de desempenho.
Assista ao vídeo a seguir para ver alguns exemplos de temporizações transformando dados com fluxos de dados.
Monitorando o desempenho do fluxo de dados
Depois de verificar sua lógica de transformação usando o modo de depuração, execute o fluxo de dados de ponta a ponta como uma atividade em um pipeline. Os fluxos de dados são operacionalizados em um pipeline usando a atividade de fluxo de dados de execução. A atividade de fluxo de dados tem uma experiência de monitoramento única em comparação com outras atividades que exibe um plano de execução detalhado e um perfil de desempenho da lógica de transformação. Para visualizar informações detalhadas de monitoramento de um fluxo de dados, selecione o ícone de óculos na saída de execução de atividade de um pipeline. Para obter mais informações, consulte Monitoramento de fluxos de dados de mapeamento.

Quando você está monitorando o desempenho do fluxo de dados, há quatro gargalos possíveis a serem observados:
- Tempo de arranque do cluster
- Leitura a partir de uma fonte
- Tempo de transformação
- Escrevendo para uma pia
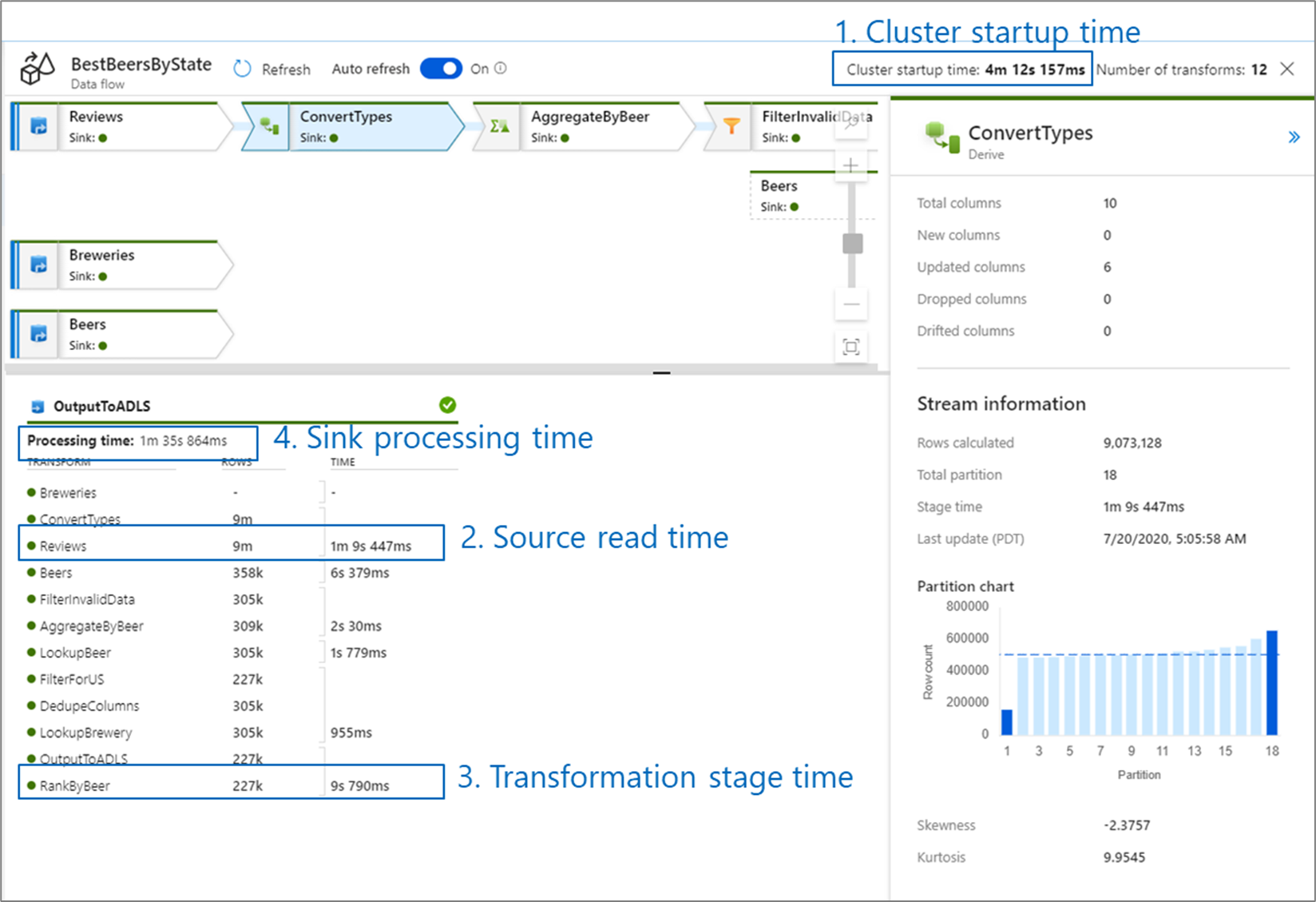
O tempo de inicialização do cluster é o tempo necessário para girar um cluster do Apache Spark. Esse valor está localizado no canto superior direito da tela de monitoramento. Os fluxos de dados são executados em um modelo just-in-time em que cada tarefa usa um cluster isolado. Este tempo de inicialização geralmente leva de 3 a 5 minutos. Para trabalhos sequenciais, o tempo de inicialização pode ser reduzido, permitindo um tempo de vida de valor. Para obter mais informações, consulte a seção Time to live em Integration Runtime performance.
Os fluxos de dados utilizam um otimizador Spark que reordena e executa sua lógica de negócios em "estágios" para executar o mais rápido possível. Para cada coletor no qual o fluxo de dados grava, a saída de monitoramento lista a duração de cada estágio de transformação, juntamente com o tempo necessário para gravar dados no coletor. O tempo que é maior é provavelmente o gargalo do seu fluxo de dados. Se o estágio de transformação que ocorre o maior contiver uma fonte, então você pode querer olhar para otimizar ainda mais seu tempo de leitura. Se uma transformação estiver demorando muito tempo, talvez seja necessário reparticionar ou aumentar o tamanho do tempo de execução da integração. Se o tempo de processamento do coletor for grande, talvez seja necessário aumentar a escala do banco de dados ou verificar se não está enviando para um único arquivo.
Depois de identificar o gargalo do seu fluxo de dados, use as estratégias de otimizações abaixo para melhorar o desempenho.
Testando a lógica de fluxo de dados
Quando você está projetando e testando fluxos de dados da interface do usuário, o modo de depuração permite que você teste interativamente em relação a um cluster Spark ao vivo, o que permite visualizar dados e executar seus fluxos de dados sem esperar que um cluster aqueça. Para obter mais informações, consulte Modo de depuração.
Otimizar o separador
A guia Otimizar contém configurações para configurar o esquema de particionamento do cluster Spark. Essa guia existe em cada transformação do fluxo de dados e especifica se você deseja reparticionar os dados após a conclusão da transformação. O ajuste do particionamento fornece controle sobre a distribuição de seus dados entre nós de computação e otimizações de localidade de dados que podem ter efeitos positivos e negativos no desempenho geral do fluxo de dados.
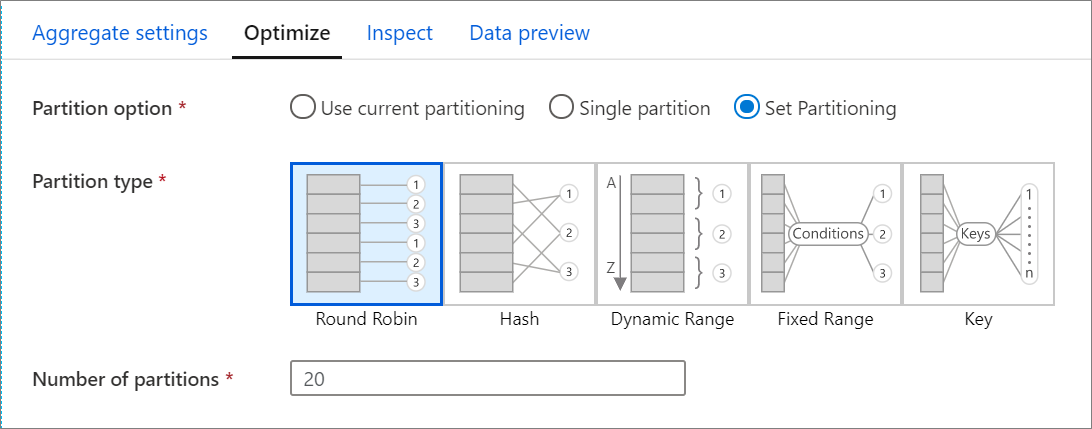
Por padrão, Usar particionamento atual é selecionado, o que instrui o serviço a manter o particionamento de saída atual da transformação. Como o reparticionamento de dados leva tempo, o uso do particionamento atual é recomendado na maioria dos cenários. Os cenários em que você pode querer reparticionar seus dados incluem após agregações e junções que distorcem significativamente seus dados ou ao usar o particionamento de origem em um banco de dados SQL.
Para alterar o particionamento em qualquer transformação, selecione a guia Otimizar e selecione o botão de opção Definir particionamento . É apresentada uma série de opções para particionamento. O melhor método de particionamento difere com base em seus volumes de dados, chaves candidatas, valores nulos e cardinalidade.
Importante
Uma única partição combina todos os dados distribuídos em uma única partição. Esta é uma operação muito lenta que também afeta significativamente todas as transformações e gravações a jusante. Esta opção é fortemente desencorajada, a menos que haja uma razão comercial explícita para a utilizar.
As seguintes opções de particionamento estão disponíveis em cada transformação:
Round robin
Round robin distribui dados igualmente entre partições. Use round-robin quando não tiver bons candidatos-chave para implementar uma estratégia de particionamento sólida e inteligente. Você pode definir o número de partições físicas.
Hash
O serviço produz um hash de colunas para produzir partições uniformes de modo que linhas com valores semelhantes caiam na mesma partição. Quando utilizar a opção Hash, teste a possível distorção da partição. Você pode definir o número de partições físicas.
Faixa dinâmica
O intervalo dinâmico usa intervalos dinâmicos do Spark com base nas colunas ou expressões fornecidas. Você pode definir o número de partições físicas.
Intervalo fixo
Crie uma expressão que forneça um intervalo fixo para valores dentro de suas colunas de dados particionadas. Para evitar a distorção de partição, você deve ter uma boa compreensão de seus dados antes de usar essa opção. Os valores inseridos para a expressão são usados como parte de uma função de partição. Você pode definir o número de partições físicas.
Chave
Se você tiver uma boa compreensão da cardinalidade de seus dados, o particionamento de chaves pode ser uma boa estratégia. O particionamento de chave cria partições para cada valor exclusivo em sua coluna. Não é possível definir o número de partições porque o número é baseado em valores exclusivos nos dados.
Gorjeta
A configuração manual do esquema de particionamento reorganiza os dados e pode compensar os benefícios do otimizador Spark. Uma prática recomendada é não definir manualmente o particionamento, a menos que seja necessário.
Nível de registo
Se você não precisar que todas as execuções de pipeline de suas atividades de fluxo de dados registrem totalmente todos os logs de telemetria detalhados, você pode, opcionalmente, definir seu nível de log como "Básico" ou "Nenhum". Ao executar seus fluxos de dados no modo "Detalhado" (padrão), você está solicitando que o serviço registre totalmente a atividade em cada nível de partição individual durante a transformação de dados. Essa pode ser uma operação cara, portanto, apenas habilitar detalhadamente a solução de problemas pode melhorar o fluxo geral de dados e o desempenho do pipeline. O modo "Básico" registra apenas as durações de transformação, enquanto "Nenhum" fornecerá apenas um resumo das durações.

Conteúdos relacionados
Veja outros artigos do Data Flow relacionados ao desempenho: