Otimizar as transformações
Use as estratégias a seguir para otimizar o desempenho de transformações no mapeamento de fluxos de dados no Azure Data Factory e nos pipelines do Azure Synapse Analytics.
Otimizando junções, existências e pesquisas
Radiodifusão
Em junções, pesquisas e transformações existentes, se um ou ambos os fluxos de dados forem pequenos o suficiente para caber na memória do nó de trabalho, você poderá otimizar o desempenho habilitando a Difusão. A transmissão é quando você envia pequenos quadros de dados para todos os nós no cluster. Isso permite que o mecanismo Spark execute uma junção sem reorganizar os dados no fluxo grande. Por padrão, o mecanismo Spark decide automaticamente se transmite ou não um lado de uma associação. Se você estiver familiarizado com seus dados de entrada e souber que um fluxo é menor do que o outro, você pode selecionar Transmissão fixa . A transmissão fixa força o Spark a transmitir o fluxo selecionado.
Se o tamanho dos dados transmitidos for muito grande para o nó Spark, você poderá obter um erro de falta de memória. Para evitar erros de falta de memória, use clusters otimizados para memória. Se você enfrentar tempos limite de transmissão durante execuções de fluxo de dados, poderá desativar a otimização de transmissão. No entanto, isso resulta em fluxos de dados de desempenho mais lento.
Ao trabalhar com fontes de dados que podem levar mais tempo para consultar, como consultas de banco de dados grandes, é recomendável desativar a transmissão para junções. A origem com longos tempos de consulta pode causar tempos limite do Spark quando o cluster tenta transmitir para nós de computação. Outra boa opção para desativar a transmissão é quando você tem um fluxo em seu fluxo de dados que está agregando valores para uso em uma transformação de pesquisa mais tarde. Esse padrão pode confundir o otimizador Spark e causar tempos limites.
Junções cruzadas
Se você usar valores literais em suas condições de associação ou tiver várias correspondências em ambos os lados de uma associação, o Spark executará a junção como uma associação cruzada. Uma junção cruzada é um produto cartesiano completo que, em seguida, filtra os valores unidos. Isso é mais lento do que outros tipos de junção. Certifique-se de ter referências de coluna em ambos os lados das condições de junção para evitar o impacto no desempenho.
Ordenar antes de aderir
Ao contrário da junção de mesclagem em ferramentas como o SSIS, a transformação de junção não é uma operação de junção de mesclagem obrigatória. As chaves de junção não exigem classificação antes da transformação. O uso de transformações de classificação no mapeamento de fluxos de dados não é recomendado.
Desempenho de transformação de janelas
A transformação Janela no mapeamento do fluxo de dados particiona seus dados por valor em colunas que você seleciona over() como parte da cláusula nas configurações de transformação. Há muitas funções analíticas e agregadas populares que são expostas na transformação do Windows. No entanto, se o seu caso de uso for gerar uma janela sobre todo o conjunto de dados para classificação rank() ou número rowNumber()de linha, é recomendável que você use a transformação Rank e a transformação Surrogate Key. Essas transformações executam melhor novamente operações completas de conjunto de dados usando essas funções.
Reparticionamento de dados distorcidos
Certas transformações, como junções e agregações, reorganizam suas partições de dados e, ocasionalmente, podem levar a dados distorcidos. Dados distorcidos significam que os dados não são distribuídos uniformemente entre as partições. Dados fortemente distorcidos podem levar a transformações downstream mais lentas e gravações de coletor. Você pode verificar a assimetria de seus dados a qualquer momento em uma execução de fluxo de dados clicando na transformação na exibição de monitoramento.
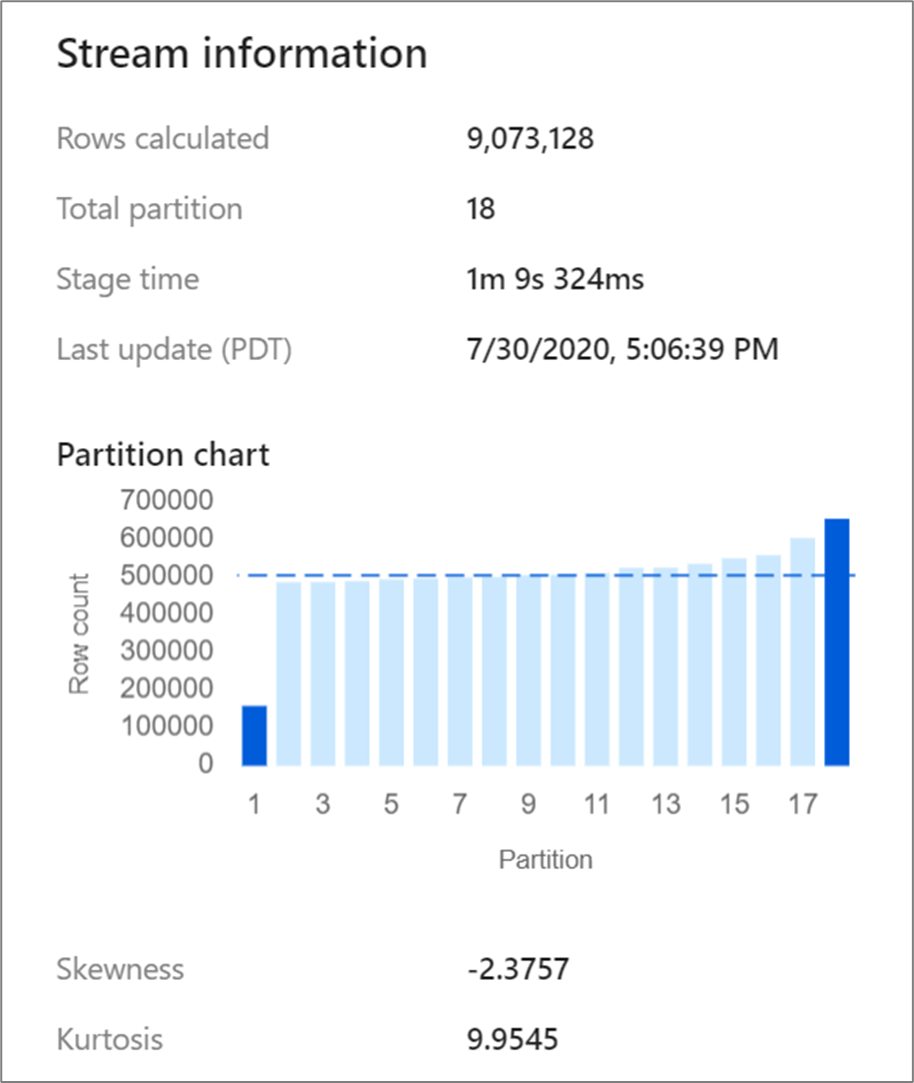
A exibição de monitoramento mostra como os dados são distribuídos em cada partição, juntamente com duas métricas, assimetria e curtose. A assimetria é uma medida de quão assimétricos os dados são e podem ter um valor positivo, zero, negativo ou indefinido. A inclinação negativa significa que a cauda esquerda é mais longa do que a direita. Kurtosis é a medida de se os dados são de cauda pesada ou de cauda clara. Altos valores de curtose não são desejáveis. As gamas ideais de assimetria situam-se entre -3 e 3 e as gamas de curtose são inferiores a 10. Uma maneira fácil de interpretar esses números é olhar para o gráfico de partição e ver se 1 barra é maior do que o resto.
Se seus dados não forem particionados uniformemente após uma transformação, você poderá usar a guia otimizar para reparticionar. A reorganização de dados leva tempo e pode não melhorar o desempenho do fluxo de dados.
Gorjeta
Se criar novamente partições de dados, mas tiver transformações a jusante que reordenam os dados, utilize a criação de partições hash numa coluna utilizada como chave de associação.
Nota
As transformações dentro do fluxo de dados (com exceção da transformação Coletor) não modificam o particionamento de arquivos e pastas dos dados em repouso. O particionamento em cada transformação reparticiona os dados dentro dos quadros de dados do cluster temporário do Spark sem servidor que o ADF gerencia para cada uma das execuções de fluxo de dados.
Conteúdos relacionados
- Visão geral do desempenho do fluxo de dados
- Otimizar origens
- Otimizar os sinks
- Usando fluxos de dados em pipelines
Veja outros artigos do Data Flow relacionados ao desempenho: