Recursos de computação do notebook
Este artigo aborda as opções para recursos de computação do bloco de anotações. Você pode executar um bloco de anotações em um cluster Databricks, computação sem servidor ou, para comandos SQL, pode usar um SQL warehouse, um tipo de computação otimizada para análise SQL.
Computação sem servidor para notebooks
A computação sem servidor permite que você conecte rapidamente seu notebook a recursos de computação sob demanda.
Para anexar à computação sem servidor, clique no menu suspenso Conectar no bloco de anotações e selecione Sem servidor.
Consulte Computação sem servidor para blocos de anotações para obter mais informações.
Anexar um bloco de notas a um cluster
Para anexar um bloco de anotações a um cluster, você precisa da permissão no nível de cluster CAN ATTACH TO.
Importante
Desde que um bloco de anotações esteja conectado a um cluster, qualquer usuário com a permissão CAN RUN no bloco de anotações tem permissão implícita para acessar o cluster.
Para anexar um bloco de anotações a um cluster, clique no seletor de computação na barra de ferramentas do bloco de anotações e selecione um cluster no menu suspenso.
O menu mostra uma seleção de clusters que você usou recentemente ou está em execução no momento.
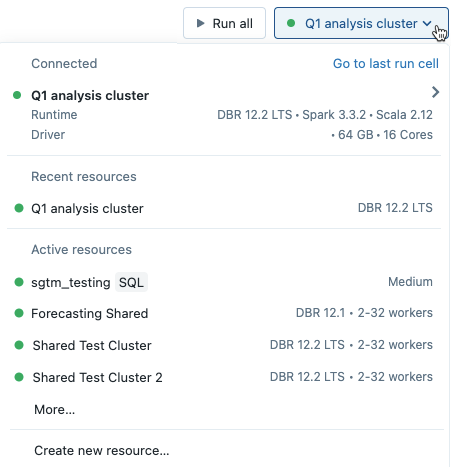
Para selecionar entre todos os clusters disponíveis, clique em Mais.... Clique no nome do cluster para exibir um menu suspenso e selecione um cluster existente.
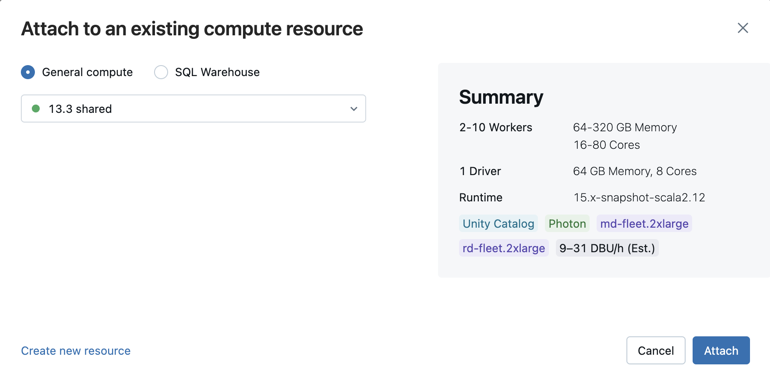
Você também pode criar um novo cluster selecionando Criar novo recurso... no menu suspenso.
Importante
Um bloco de anotações anexado tem as seguintes variáveis do Apache Spark definidas.
| Classe | Nome da variável |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Faísca 2.x) |
spark |
Não crie um SparkSession, SparkContextou SQLContext. Fazer isso levará a um comportamento inconsistente.
Usar um bloco de anotações com um SQL warehouse
Quando um bloco de anotações é anexado a um armazém SQL, você pode executar células SQL e Markdown. Executar uma célula em qualquer outra linguagem (como Python ou R) gera um erro. As células SQL executadas em um SQL warehouse aparecem no histórico de consultas do SQL warehouse. O usuário que executou uma consulta pode visualizar o perfil de consulta do bloco de anotações clicando no tempo decorrido na parte inferior da saída.
A execução de um bloco de anotações requer um SQL warehouse profissional ou sem servidor. Você deve ter acesso ao espaço de trabalho e ao SQL warehouse.
Para anexar um bloco de anotações a um armazém SQL, faça o seguinte:
Clique no seletor de computação na barra de ferramentas do bloco de anotações. O menu suspenso mostra os recursos de computação que estão em execução no momento ou que você usou recentemente. Os armazéns SQL são marcados com
 .
.No menu, selecione um SQL warehouse.
Para ver todos os armazéns SQL disponíveis, selecione Mais... no menu suspenso. É exibida uma caixa de diálogo mostrando os recursos de computação disponíveis para o bloco de anotações. Selecione SQL Warehouse, escolha o depósito que deseja usar e clique em Anexar.
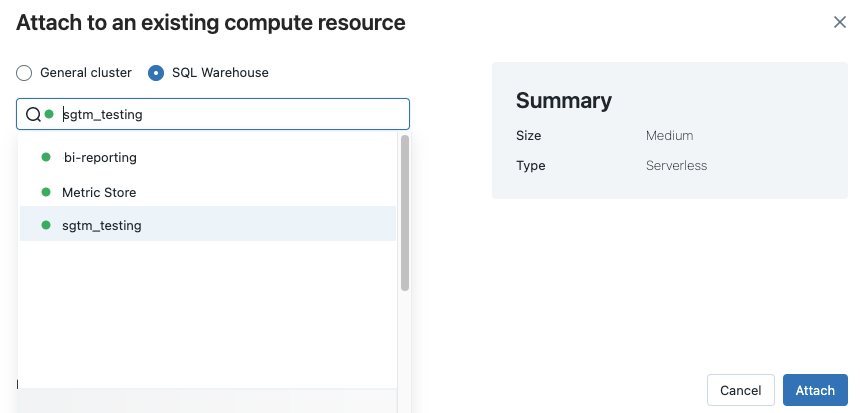
Você também pode selecionar um SQL warehouse como o recurso de computação para um bloco de anotações SQL ao criar um fluxo de trabalho ou um trabalho agendado.
Limitações do SQL warehouse
Consulte Limitações conhecidas Blocos de anotações Databricks para obter mais informações.
Desanexar um bloco de notas
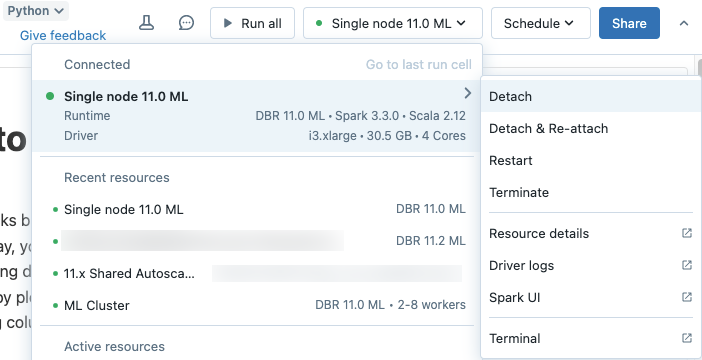
Para desanexar um bloco de anotações de um recurso de computação, clique no seletor de computação na barra de ferramentas do bloco de anotações e passe o mouse sobre o cluster anexado ou o SQL warehouse na lista para exibir um menu lateral. No menu lateral, selecione Desanexar.
Você também pode desanexar blocos de anotações de um cluster usando a guia Blocos de Anotações na página de detalhes do cluster.
Gorjeta
O Azure Databricks recomenda que você desanexe blocos de anotações não utilizados de clusters. Isso libera espaço de memória no driver.