Aprendizagem profunda com previsão de AutoML
Este artigo se concentra nos métodos de aprendizagem profunda para previsão de séries temporais no AutoML. Instruções e exemplos para treinar modelos de previsão no AutoML podem ser encontrados em nosso artigo de configuração do AutoML para previsão de séries temporais .
A aprendizagem profunda tem inúmeros casos de uso em campos que vão desde a modelagem de linguagem até o dobramento de proteínas, entre muitos outros. A previsão de séries temporais também se beneficia dos recentes avanços na tecnologia de aprendizagem profunda. Por exemplo, os modelos de redes neurais profundas (DNN) aparecem com destaque nos modelos de melhor desempenho da quarta e quinta iterações da competição de previsão Makridakis de alto perfil.
Neste artigo, descrevemos a estrutura e a operação do modelo TCNForecaster no AutoML para ajudá-lo a aplicar melhor o modelo ao seu cenário.
Introdução ao TCNForecaster
TCNForecaster é uma rede convolucional temporal, ou TCN, que tem uma arquitetura DNN projetada para dados de séries temporais. O modelo usa dados históricos para uma quantidade alvo, juntamente com recursos relacionados, para fazer previsões probabilísticas da meta até um horizonte de previsão especificado. A imagem a seguir mostra os principais componentes da arquitetura TCNForecaster:

A TCNForecaster tem os seguintes componentes principais:
- Uma camada de pré-mistura que mistura as séries temporais de entrada e os dados de recursos em uma matriz de canais de sinal que a pilha convolucional processa.
- Uma pilha de camadas de convolução dilatadas que processa a matriz de canais sequencialmente, cada camada na pilha processa a saída da camada anterior para produzir uma nova matriz de canais. Cada canal nesta saída contém uma mistura de sinais filtrados por convolução dos canais de entrada.
- Uma coleção de unidades principais de previsão que coalescem os sinais de saída das camadas de convolução e geram previsões da quantidade-alvo a partir dessa representação latente. Cada unidade principal produz previsões até ao horizonte para um quantil da distribuição da previsão.
Convolução causal dilatada
A operação central de um TCN é uma convolução causal dilatada ao longo da dimensão temporal de um sinal de entrada. Intuitivamente, a convolução mistura valores de pontos de tempo próximos na entrada. As proporções na mistura são o miolo, ou os pesos, da convolução, enquanto a separação entre os pontos da mistura é a dilatação. O sinal de saída é gerado a partir da entrada, deslizando o kernel no tempo ao longo da entrada e acumulando a mistura em cada posição. Uma convolução causal é aquela em que o kernel apenas mistura valores de entrada no passado em relação a cada ponto de saída, impedindo que a saída "olhe" para o futuro.
O empilhamento de convoluções dilatadas dá ao TCN a capacidade de modelar correlações ao longo de longas durações em sinais de entrada com relativamente poucos pesos de kernel. Por exemplo, a imagem a seguir mostra três camadas empilhadas com um kernel de dois pesos em cada camada e fatores de dilatação exponencialmente crescentes:
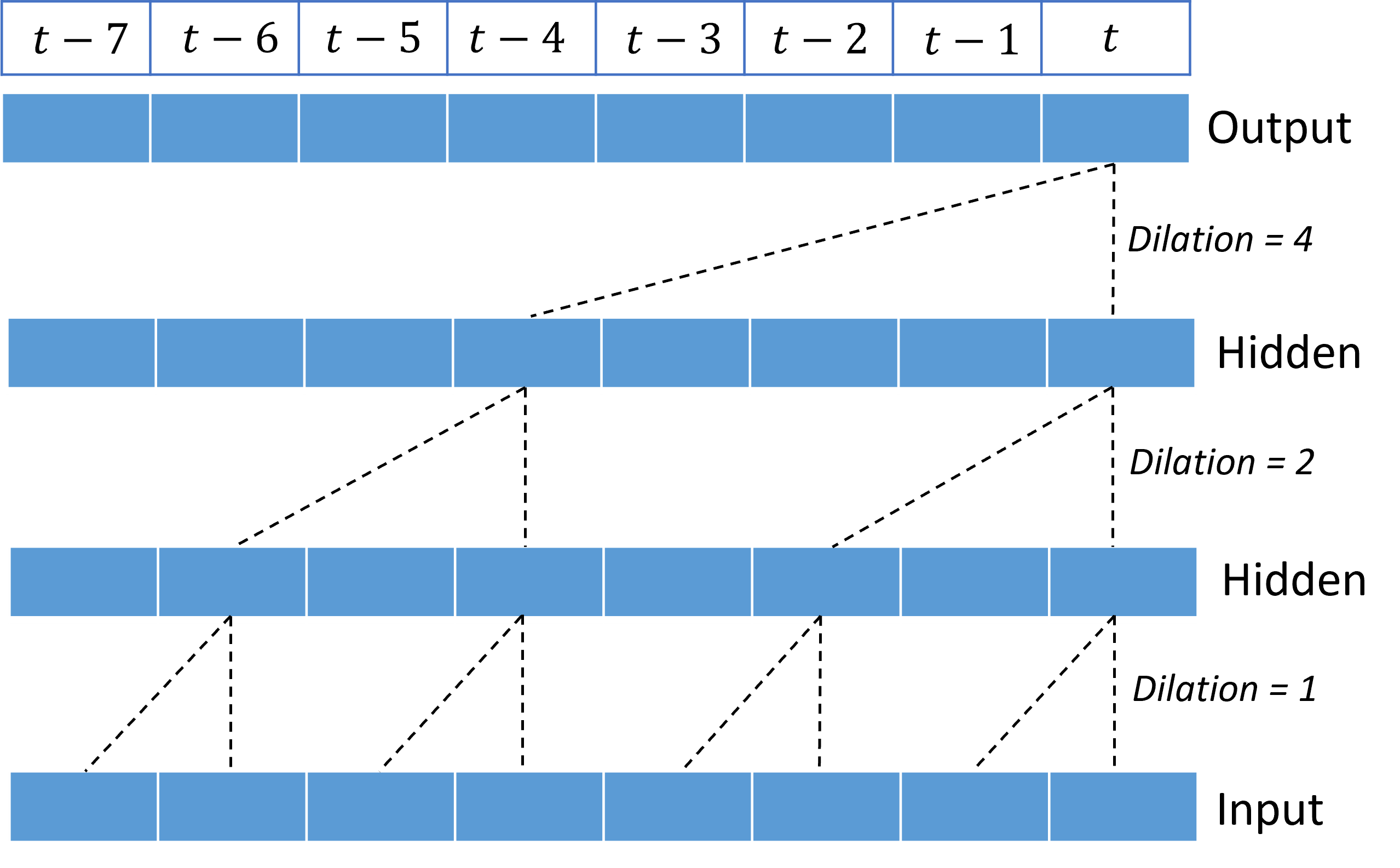
As linhas tracejadas mostram caminhos através da rede que terminam na saída de cada vez $t$. Estes caminhos abrangem os últimos oito pontos na entrada, ilustrando que cada ponto de saída é uma função dos oito pontos mais relativamente recentes na entrada. A extensão da história, ou "olhar para trás", que uma rede convolucional usa para fazer previsões é chamada de campo recetivo e é determinada completamente pela arquitetura TCN.
Arquitetura TCNForecaster
O núcleo da arquitetura TCNForecaster é a pilha de camadas convolucionais entre as cabeças de pré-mistura e previsão. A pilha é logicamente dividida em unidades repetitivas chamadas blocos que são, por sua vez, compostos por células residuais. Uma célula residual aplica convoluções causais em uma dilatação definida juntamente com normalização e ativação não linear. É importante ressaltar que cada célula residual adiciona sua saída à sua entrada usando uma chamada conexão residual. Está demonstrado que estas ligações beneficiam a formação em DNN, talvez porque facilitem um fluxo de informação mais eficiente através da rede. A imagem a seguir mostra a arquitetura das camadas convolucionais para uma rede de exemplo com dois blocos e três células residuais em cada bloco:
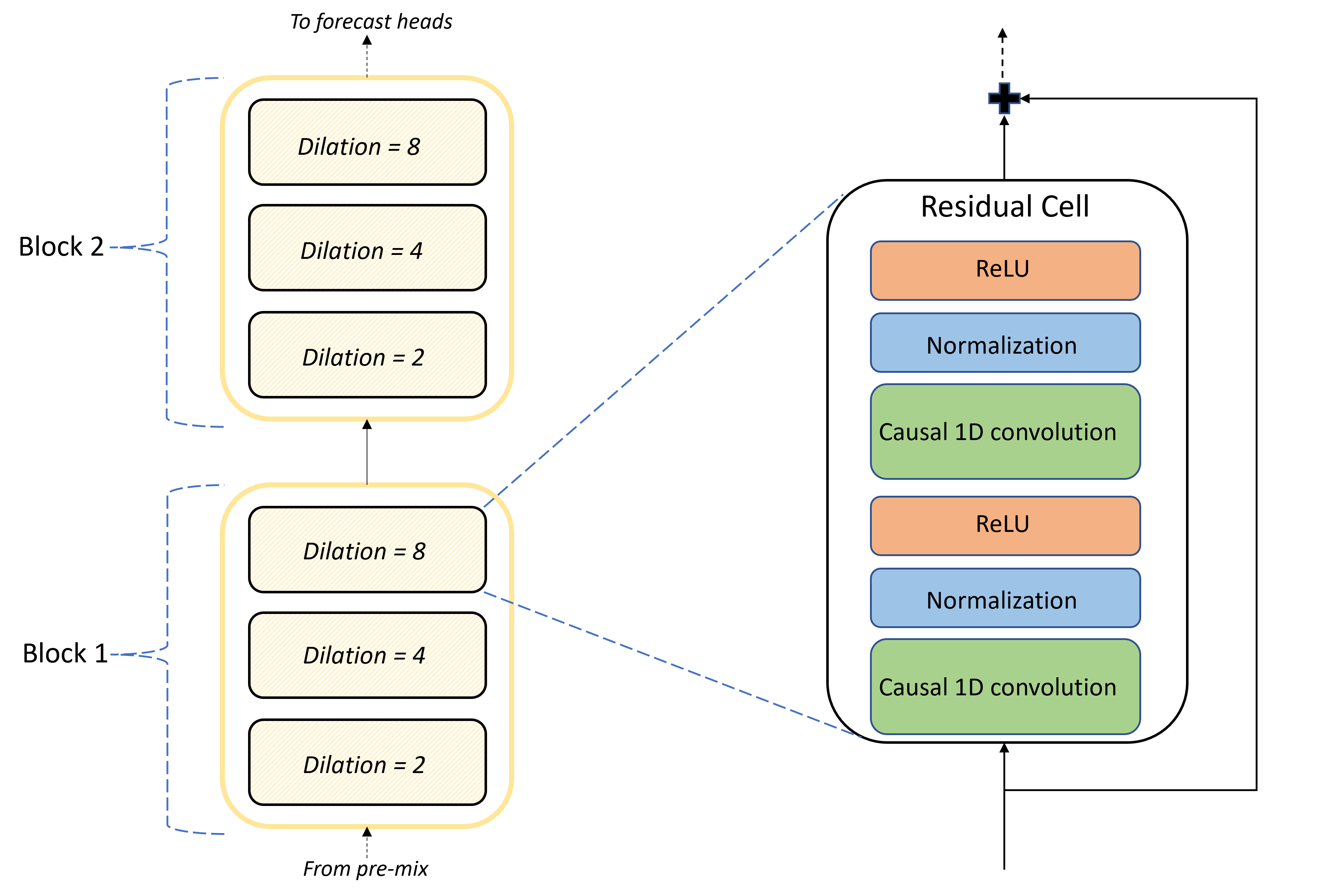
O número de blocos e células, juntamente com o número de canais de sinal em cada camada, controlar o tamanho da rede. Os parâmetros arquitetônicos do TCNForecaster são resumidos na tabela a seguir:
| Parâmetro | Description |
|---|---|
| $n_{b}$ | Número de blocos na rede; também chamada de profundidade |
| $n_{c}$ | Número de células em cada bloco |
| $n_{\text{ch}}$ | Número de canais nas camadas ocultas |
O campo recetivo depende dos parâmetros de profundidade e é dado pela fórmula,
$t_{\text{rf}} = 4n_{b}\left(2^{n_{c}} - 1\right) + 1.$
Podemos dar uma definição mais precisa da arquitetura TCNForecaster em termos de fórmulas. Deixe $X$ ser uma matriz de entrada onde cada linha contém valores de feição dos dados de entrada. Podemos dividir $X$ em matrizes de recursos numéricos e categóricos, $X_{\text{num}}$ e $X_{\text{cat}}$. Em seguida, o TCNForecaster é dado pelas fórmulas,
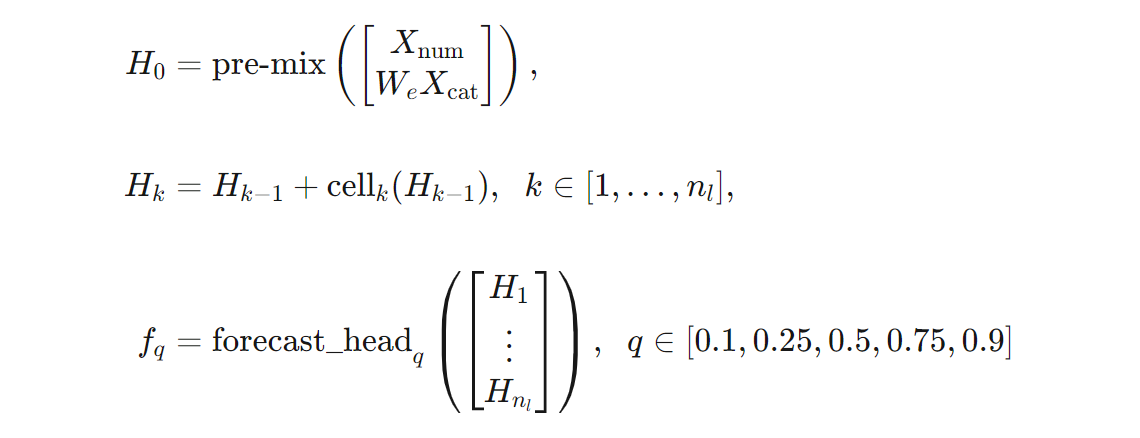
Onde $W_{e}$ é uma matriz de incorporação para as características categóricas, $n_{l} = n_{b}n_{c}$ é o número total de células residuais, os $H_{k}$ denotam saídas de camada oculta e os $f_{q}$ são saídas de previsão para determinados quantis da distribuição de previsão. Para facilitar a compreensão, as dimensões dessas variáveis estão na tabela a seguir:
| Variável | Description | Dimensões |
|---|---|---|
| $X$ | Matriz de entrada | $n_{\text{input}} \times t_{\text{rf}}$ |
| $H_{i}$ | Saída de camada oculta para $i=0,1,\ldots,n_{l}$ | $n_{\text{ch}} \times t_{\text{rf}}$ |
| $f_{q}$ | Previsão de saída para quantil $q$ | $h$ |
Na tabela, $n_{\text{input}} = n_{\text{features}} + 1$, o número de variáveis preditoras/feições mais a quantidade de destino. As cabeças de previsão geram todas as previsões até o horizonte máximo, $h$, em uma única passagem, então a TCNForecaster é um meteorologista direto.
TCNForecaster em AutoML
TCNForecaster é um modelo opcional no AutoML. Para saber como usá-lo, consulte habilitar o deep learning.
Nesta seção, descrevemos como o AutoML cria modelos TCNForecaster com seus dados, incluindo explicações sobre pré-processamento de dados, treinamento e pesquisa de modelos.
Etapas de pré-processamento de dados
O AutoML executa várias etapas de pré-processamento em seus dados para se preparar para o treinamento do modelo. A tabela a seguir descreve essas etapas na ordem em que são executadas:
| Passo | Description |
|---|---|
| Preencher dados em falta | Imputar valores em falta e lacunas de observação e, opcionalmente, preencher ou largar séries temporais curtas |
| Criar recursos de calendário | Aumente os dados de entrada com recursos derivados do calendário , como dia da semana e, opcionalmente, feriados para um país/região específico. |
| Codificar dados categóricos | Rotule cadeias de caracteres de codificação e outros tipos categóricos, isso inclui todas as colunas de ID de série temporal. |
| Transformação de destino | Opcionalmente, aplicar a função de logaritmo natural ao alvo, dependendo dos resultados de certos testes estatísticos. |
| Normalização | O Z-score normaliza todos os dados numéricos, a normalização é realizada por recurso e por grupo de séries temporais, conforme definido pelas colunas ID da série temporal. |
Essas etapas estão incluídas nos pipelines de transformação do AutoML, portanto, são aplicadas automaticamente quando necessário no momento da inferência. Em alguns casos, a operação inversa a uma etapa é incluída no pipeline de inferência. Por exemplo, se o AutoML aplicou uma transformação $\log$ ao destino durante o treinamento, as previsões brutas serão exponenciadas no pipeline de inferência.
Formação
O TCNForecaster segue as melhores práticas de treinamento da DNN comuns a outras aplicações em imagens e linguagem. O AutoML divide os dados de treinamento pré-processados em exemplos que são embaralhados e combinados em lotes. A rede processa os lotes sequencialmente, usando retropropagação e descida de gradiente estocástico para otimizar os pesos da rede em relação a uma função de perda. O treinamento pode exigir muitas passagens pelos dados completos do treinamento; Cada passagem é chamada de época.
A tabela a seguir lista e descreve as configurações e parâmetros de entrada para o treinamento TCNForecaster:
| Contributos para a formação | Description | valor |
|---|---|---|
| Dados de validação | Uma parte dos dados que é mantida a partir do treinamento para orientar a otimização da rede e mitigar o excesso de ajuste. | Fornecido pelo usuário ou criado automaticamente a partir de dados de treinamento, se não fornecidos. |
| Métrica primária | Métrica calculada a partir de previsões de valor mediano sobre os dados de validação no final de cada época de treinamento; utilizado para paragem antecipada e seleção de modelos. | Escolhido pelo usuário: erro quadrado médio de raiz normalizado ou erro absoluto médio normalizado. |
| Épocas de formação | Número máximo de épocas a serem executadas para otimização do peso da rede. | 100; A lógica de parada precoce automatizada pode encerrar o treinamento em um número menor de épocas. |
| Parar cedo a paciência | Número de épocas para aguardar a melhoria da métrica primária antes que o treinamento seja interrompido. | 20 |
| Função de perda | A função objetiva para otimização do peso da rede. | A perda quantílica foi em média acima das previsões dos percentis 10, 25, 50, 75 e 90. |
| Tamanho do lote | Número de exemplos num lote. Cada exemplo tem dimensões $n_{\text{input}} \times t_{\text{rf}}$ para entrada e $h$ para saída. | Determinado automaticamente a partir do número total de exemplos nos dados de treinamento; valor máximo de 1024. |
| Incorporação de dimensões | Dimensões dos espaços de incorporação para características categóricas. | Definido automaticamente para a quarta raiz do número de valores distintos em cada recurso, arredondado para o inteiro mais próximo. Os limiares são aplicados a um valor mínimo de 3 e máximo de 100. |
| Arquitetura de rede* | Parâmetros que controlam o tamanho e a forma da rede: profundidade, número de células e número de canais. | Determinado pela pesquisa de modelo. |
| Pesos da rede | Parâmetros que controlam misturas de sinais, incorporações categóricas, pesos de kernel de convolução e mapeamentos para valores de previsão. | Inicializado aleatoriamente e, em seguida, otimizado em relação à função de perda. |
| Taxa de aprendizagem* | Controla o quanto os pesos de rede podem ser ajustados em cada iteração de descida de gradiente; dinamicamente reduzida perto da convergência. | Determinado pela pesquisa de modelo. |
| Taxa de abandono* | Controla o grau de regularização do abandono aplicado aos pesos da rede. | Determinado pela pesquisa de modelo. |
As entradas marcadas com um asterisco (*) são determinadas por uma pesquisa de hiperparâmetro descrita na próxima seção.
Pesquisa de modelos
O AutoML usa métodos de pesquisa de modelo para localizar valores para os seguintes hiperparâmetros:
- Profundidade da rede, ou o número de blocos convolucionais,
- Número de células por bloco,
- Número de canais em cada camada oculta,
- Taxa de abandono para regularização da rede,
- Taxa de aprendizagem.
Os valores ideais para esses parâmetros podem variar significativamente dependendo do cenário do problema e dos dados de treinamento, de modo que o AutoML treina vários modelos diferentes no espaço de valores de hiperparâmetros e escolhe o melhor de acordo com a pontuação métrica primária nos dados de validação.
A pesquisa de modelos tem duas fases:
- O AutoML realiza uma pesquisa em 12 modelos "marcantes". Os modelos de referência são estáticos e escolhidos para abranger razoavelmente o espaço de hiperparâmetros.
- O AutoML continua pesquisando através do espaço de hiperparâmetros usando uma pesquisa aleatória.
A pesquisa termina quando os critérios de interrupção são atendidos. Os critérios de interrupção dependem da configuração do trabalho de treinamento previsto, mas alguns exemplos incluem limites de tempo, limites no número de tentativas de pesquisa a serem executadas e lógica de parada antecipada quando a métrica de validação não está melhorando.
Próximos passos
- Saiba como configurar o AutoML para treinar um modelo de previsão de séries temporais.
- Saiba mais sobre a metodologia de previsão no AutoML.
- Navegue pelas perguntas frequentes sobre previsão no AutoML.